I have an HTML file (from Newegg) and their HTML is organized like below. All of the data in their specifications table is ‘desc‘ while the titles of each section are in ‘name.‘ Below are two examples of data from Newegg pages.
<tr>
<td class="name">Brand</td>
<td class="desc">Intel</td>
</tr>
<tr>
<td class="name">Series</td>
<td class="desc">Core i5</td>
</tr>
<tr>
<td class="name">Cores</td>
<td class="desc">4</td>
</tr>
<tr>
<td class="name">Socket</td>
<td class="desc">LGA 1156</td>
<tr>
<td class="name">Brand</td>
<td class="desc">AMD</td>
</tr>
<tr>
<td class="name">Series</td>
<td class="desc">Phenom II X4</td>
</tr>
<tr>
<td class="name">Cores</td>
<td class="desc">4</td>
</tr>
<tr>
<td class="name">Socket</td>
<td class="desc">Socket AM3</td>
</tr>
In the end I would like to have a class for a CPU (which is already set up) that consists of a Brand, Series, Cores, and Socket type to store each of the data. This is the only way I can think of to go about doing this:
if(parsedDocument.xpath(tr/td[@class="name"])=='Brand'):
CPU.brand = parsedDocument.xpath(tr/td[@class="name"]/nextsibling?).text
And doing this for the rest of the values. How would I accomplish the nextsibling and is there an easier way of doing this?
Automation using selenium is a great experience. It provides many ways to identify an object or element on the web page.
But sometimes we face the problems of identifying the objects on a page which have same attributes. When we get more than
one element which are same in attribute and name like multiple checkboxes with the same name and same id. More than one button having same name and ids. There is no way to distinguishes those elements. In this case, we have problem to instruct selenium to identify a perticular
object on a web page.
I am giving you a simple example . In the below html source there are 6 checkboxes are there having same type and same name.
<html>
<body>
<input type=’checkbox’ name=’chk’>first
<br><input type=’checkbox’ name=’chk’>second
<br><input type=’checkbox’ name=’chk’>third
<br><input type=’checkbox’ name=’chk’>forth
<br><input type=’checkbox’ name=’chk’>fifth
<br><input type=’checkbox’ name=’chk’>sixth
</body>
</html>
Thare are some functions we can use in Xpath to identify the abject in above cases.
An XPath expression can return one of four basic XPath data types:
* String
* Number
* Boolean
* Node-set
XPath Type : Functions
Node set : last(), position(), count(), id(), local-name(), namespace-uri(), name()
String : string(), concat(), starts-with(), contains(), substring-before(), substring-after(), substring(), string-length(), normalize-space(), translate()
Boolean : boolean(), not(), true(), false(), lang()
Number : number(), sum(), floor(), ceiling(), round()
I will show you how we can use some of these above functions in xpath to identify the objects.
Node Set : last()
In the above html file there are six checkboxes and all are having same attributes (same type and name)
How we can select the last checkbox based on the position. We can use last() function to identify the last object among all similar objects.
Below code will check or uncheck the last checkbox.
selenium.click(“xpath=(//input[@type=’checkbox’])[last()]”);
How we can select the second last checkbox and third last checkbox. We can use last()- function to identify the last object among all similar objects.
Below code will check or uncheck the second last checkbox and third last checkbox respectively.
selenium.click(“xpath=(//input[@type=’submit’])[last()-1]”);
selenium.click(“xpath=(//input[@type=’submit’])[last()-2]”);
Node Set : position()
If you want to select any object based on their position using xpath then you can use position() function in xpath.
You want to select second checkbox and forth checkbox then use below command
selenium.click(“xpath=(//input[@type=’checkbox’])[position()=2]”);
selenium.click(“xpath=(//input[@type=’checkbox’])[position()=4]”);
above code will select second and forth checkbox respectively.
String : starts-with()
Many web sites create dynamic element on their web pages where Ids of the elements gets generated dynamically.
Each time id gets generated differently. So to handle this situation we use some JavaScript functions.
XPath: //button[starts-with(@id, ‘continue-‘)]
Sometimes an element gets identfied by a value that could be surrounded by other text, then contains function can be used.
To demonstrate, the element can be located based on the ‘suggest’ class without having
to couple it with the ‘top’ and ‘business’ classes using the following
XPath: //input[contains(@class, ‘suggest’)]
Preceding-sibling and following-sibling in xpath to find sibling nodes:-
Consider the following HTML syntax:-
<html>
<ul>
<li>Samsung Mobiles</li>
<li>Apple Mobiles</li>
<li>Nokia Mobiles</li>
<li>HTC Mobiles</li>
<li>Sony Mobile</li>
<li>Micromax Mobiles</li>
</ul>
</html>
How to get all the preceding siblings of Apple
Xpath: “//ul/li[contains(text(),’Apple Mobiles’)]/preceding-sibling::li“
This will give “Samsung Mobiles”
How to get all the following siblings of Apple
Xpath: “//ul/li[contains(text(),’Apple Mobiles’)]/following-sibling::li“
This will give all the preceding siblings ( Nokia Mobiles, HTC Mobiles, Sony Mobiles, Micromax mobiles)
There is a trick to use preceding-sibling and following-sibling. Place matters when you use this at beginning it will give you reverse result
When you use preceding-sibling at the beginning then it will give result ( Nokia Mobiles, HTC Mobiles, Sony Mobiles, Micromax mobiles) instead of Samsung mobiles.
Xpath : “//li[preceding-sibling::li=’Apple Mobiles’]”
This will give Samsung mobiles.
when you use following-sibling at the beginning then it will give reverse result. Instead of giving all below nodes of Apple mobile this will give Samsung Mobiles.
Xpath: “//li[following-sibling::li=’Apple Mobiles’]“
Now the question is how to get all the nodes between Apple Mobiles and Sony Mobiles.
Xpath : “//ul/li[preceding-sibling::li=’Apple Mobiles’ and following-sibling::li=’Sony Mobiles’]“
This will return Nokia Mobiles and HTC Mobiles.
or
Xpath : “//ul/li[preceding-sibling::li[.=’Apple Mobiles’] and following-sibling::li[.=’Sony Mobiles’]]“
Or You can use this in contains as well
Xpath: “//ul/li[preceding-sibling::li[contains(text(),’Apple Mobiles’)] and following-sibling::li[contains(text(),’Sony Mobiles’)]]“
i have a deeply nested structure (actually parsing out xhtml, so lots of nasty), like so:
<tr>
<td>
<font id="blah">
stuff
</font>
</td>
</tr>
<tr>
<td>
more stuff
</td>
</tr>
and this repeats in a long table. i need an xpath expression that will select the second font tag (or rather it’s text()). i was looking at the preceding-sibling axis, but something isn’t quite working right.
something along the lines of (and pardon me if this is ridiculous, my xpath is rusty)
//tr[preceding-sibling::tr/td/font]/td/text()
asked Dec 27, 2010 at 2:47
![]()
kolosykolosy
2,9903 gold badges29 silver badges48 bronze badges
1
Use:
(//tr/td[font])[2]/font/text()
This means:
Select all text-node children of all font elements that are children of the second td in the document that has a font child and is itself a child of some tr element.
As you can see, no preceeding axis is necessary.
answered Dec 27, 2010 at 4:28
![]()
Dimitre NovatchevDimitre Novatchev
240k26 gold badges292 silver badges429 bronze badges
1
You’ve got the right idea. It should work if you get rid of the /b in there.
answered Dec 27, 2010 at 2:57
![]()
John KugelmanJohn Kugelman
347k67 gold badges524 silver badges574 bronze badges
1

Introduction to XPath Sibling
Xpath Sibling is defined as a function for retrieving a web element that is a child of the parent element. The web element may be readily recognised or accessed using the sibling attribute of the Xpath expression if the parent element is known. In addition, a keyword called sibling can be used to retrieve a web element that is connected to another element.
Syntax of XPath Sibling
Given below is the syntax mentioned:
//node [attribute='value of attribute']//following-sibling:attributeExample:
Code:
//select[@id='fname']/following-sibling::*
//select[@id='fname']/following-sibling::select/Preceding-sibling syntax:
//select[@id='lname']/preceding-sibling::select/
//select[@id='lname']/preceding-sibling::*How does XPath Sibling Work?
If a simple XPath fails to locate a complex web element for our executable script, we must resort to the XPath 1.0 library’s functionalities. We may generate more specialised XPaths by combining the functions. One of such function is Sibling. The most important part of developing an automation script has always been locating a web element. The pain point of every automation test development process has always been finding the right, effective, and accurate locator.
Even the simple XPath solutions would not be very efficient because a simple XPath may return several elements in this scenario. Therefore, XPath in Selenium provides XPath functions that may construct effective XPaths to identify elements uniquely to overcome such problems. For example, the “XPath Axis” attributes in XPath leverage the relationship between multiple nodes to locate those nodes in the DOM structure.
Following and preceding siblings are just a few of the Axis that can be used in Selenium to discover elements on a web page using XPath. All siblings are referred to be the parent node’s children. So, we can use the following sibling if we’re referring to one of the children and want to browse to other children from the same parent who follow it.
1. following-sibling
The Xpath sibling axis is similar to the axis that comes after it. Only sibling nodes, i.e. nodes on the same level as the current node, are recognised by following-sibling. For example, in the figure below, both highlighted “divs” are on the same plane, i.e., they are siblings; meanwhile, the “div” just over them seems to be the parent. Assume we’ve found the label “Email,” which is represented by the <div> element.
Xpath Example:
We can use the XPath following sibling axis to find this.
So, for this scenario, the XPath expression will be.
Code:
//div[@class='col-md-3 col-sm-12']/following-sibling::divOutput:
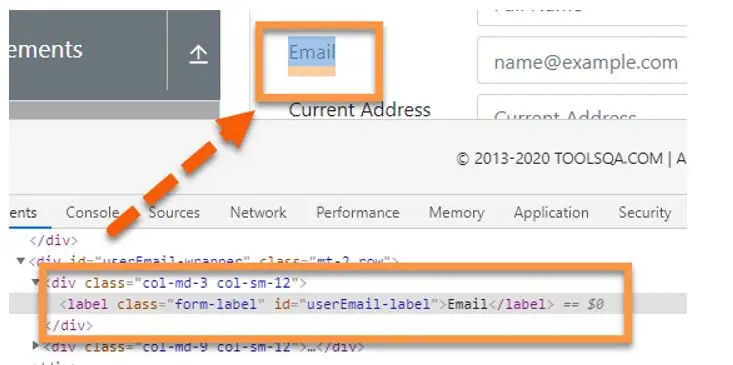
And we need to identify its sibling “div ” element, as shown below.
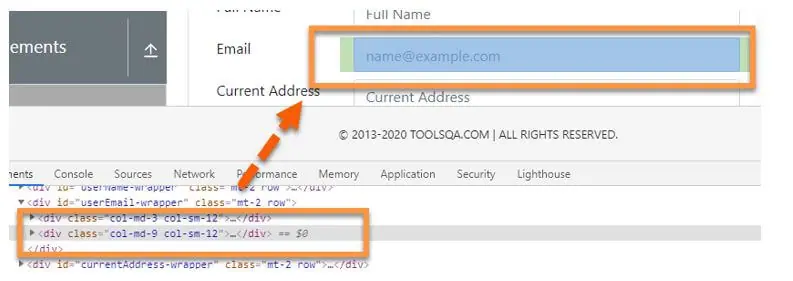
However, if numerous siblings have the same node, XPath will recognise all of the different elements.
Let’s take another case like:
For example, on the Facebook home page, the radio buttons for female and female text are siblings, as shown below. We can then simply discover the XPath of text “Female” at the same level by using the following-sibling axis.
Code:
//input[@id = ‘u_0_5’]//following-sibling::buttonUsing the “following-sibling” axis, the above formula identifies one input node.
2. preceding-sibling
The preceding-sibling axis shows all the nodes in the source document that have the same parent as the context node and occurs before it.
For the following test code:
Code:
<td>
<div class="btn-g">
<button class="btn ddd" title="withhold, Delete" name="delete" type="button">
<button class="btn ddd" title="cache" name="aaaa" type="button">
<button class="btn ddd" title=" Settings" name="bbb" type="button">
<button class="btn ddd" name="data" type="button">
<span class="class1"/>
Auro Water
</button>
</div>
</td>Examples of XPath Sibling
Below are the different examples of how the web driver takes sibling axes to find the exact XPath.
Example #1
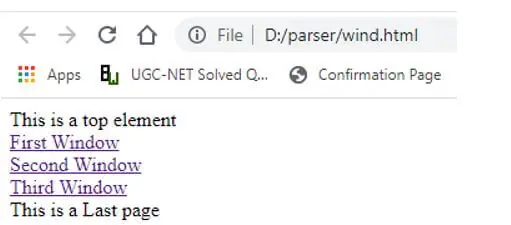
wind.html:
Code:
<html>
<head>
<title>Demo On Siblings -Xpath</title>
</head>
<body>
<form>
<header> This is a top element </header>
<div class="aab">
<a href="">First Window</a>
<div class="bbba">
<a href="">Second Window</a>
<div class="cca"> <a href="">Third Window</a> </div>
</div>
</div>
<footer> This is a Last page </footer>
</body>
</html>JavaScript:
Code:
List<WebElement>
sibElements = driver.findElements(By.xpath("//a[contains(text()," + "'Second Window.')]/parent::div//following-sibling::div[@class='cca']//a"));Here, the Firefox driver is invoked after the WebDriver API class ‘Firefox Driver’ is instantiated. The WebDriver object is then used to call and load the URL under test. We’re now utilising the WebDriver class’s’findElement’ method to find a list of web elements. We’re giving the XPath criteria to this procedure as input. As a result, we use the ‘following sibling function with the class ‘cca’ to choose the hyperlink with the tag ‘a’. This specific web element is listed in the list with the reference ‘sib Elements.’
Explanation:
- Three nested div blocks with the classes a, b, and c have been defined in the above HTML code.
- Each div block has a hyperlink and is labelled as “Inside div block 1,” “Inside div block 2,” or “Inside div block 3,” depending on which div block area it is contained in.
Output:
Example #2
Simple example using Selenium.
Following-sibling XPath example.
Select the following siblings of the context node.
Code:
//*[@class='col-md-6 text-left']/child::div[2]//*[@class='panel-body']//following-sibling::liOutput:
The output that can be seen after running the above test script is as follows.
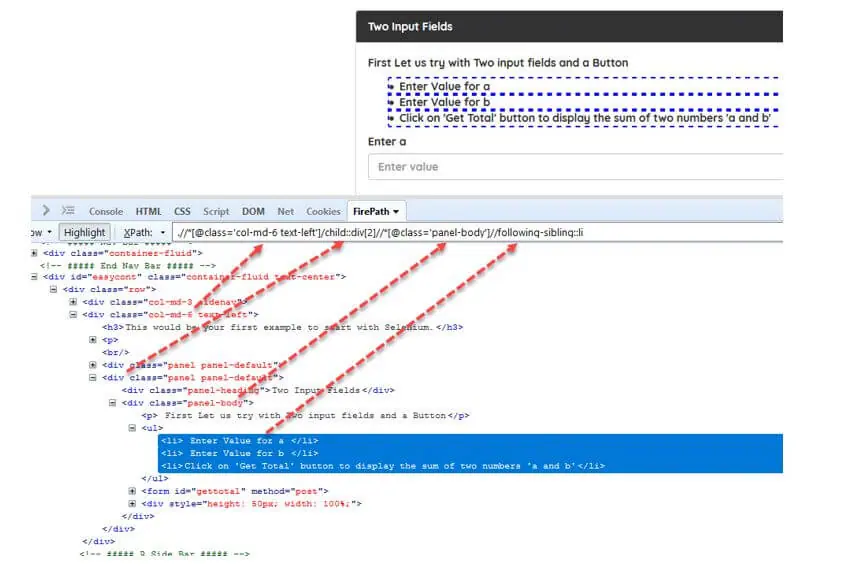
Example #3
Code:
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.testng.annotations.Test;
public class Ances{
@Test
public void testAncestorInXpath()
{
WebDriver driver = new FirefoxDriver();
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
driver.get("http://www.gmail.com/selenium/gmailhome/");
List<WebElement> dateBox = driver.findElements(By.xpath("//div[.//a[text()='SELENIUM']]/ancestor::div[@class='rt-grid-2 rt-omega']/following-sibling::div"));
for (WebElement webE : dateBox) {
System.out.println(webEl.getText());
} driver.quit();
}
}Explanation:
- Here the test is created to access the site Gmail. The sibling Div is specified using find elements, and the output is shown as.
Output:

Example #4
Code:
<ul class="right">
<li><a href="https://www.educba.com/feature">Home</a></li>
<li><a href="https://www.educba.com/Blogs">Automation</a></li> <li><a href="https://www.educba.com/product">Product</a></li>
<li><a href="https://www.educba.com/pricing">Pricing</a></li>
<li><a href="https://www.educba.com/support/">Support</a></li>
<li class="sign-out"><a href="https://accounts.educba.com/login">Login</a></li>
<li class="login"><a href="https://accounts.educba.com/login">Free Sign in</a>
</li>
</ul>XpathSib.java:
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class Xpathsib {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "path of chromeDriver");
WebDriver dr=new ChromeDriver();
dr.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
dr.get("https://www.educba.com/");
dr.manage().window().maximize();
dr.findElement(By.xpath("//li[@class='sign-up']//following-sibling::li")).click();
String cURL= dr.getCurrentUrl();
System.out.println(cURL);
driver.close();
}
}Explanation:
- One of the children has been mentioned in the DOM structure below, and we will travel to its siblings using the educba homepage links.
- Above is the code snippet incorporating Xpath in Selenium.
Output:
Conclusion
XPath Axes can be used to navigate the DOM tree and find dynamic web items. To write effective automation test scripts, Selenium Testers should understand each XPath axis and how to use it. Therefore, in this article, we have seen how to use sibling and their types in Xpath to give the desired result.
Recommended Articles
This is a guide to XPath Sibling. Here we discuss the introduction; how does XPath sibling work? and examples, respectively. You may also have a look at the following articles to learn more –
- XPath Expressions
- XPath Relative
- XPath Wildcard
- XPath Nodes
XPath axes in Selenium are methods to identify those dynamic elements which are not possible to find by normal XPath method such as ID, Classname, Name, etc.
Axes are so named because they tell about the axis on which elements are lying relative to an element.
Dynamic web elements are those elements on the webpage whose attributes dynamically change on refresh or any other operations.
The commonly useful XPath axes methods used in Selenium WebDriver are child, parent, ancestor, sibling, preceding, self, namespace, attribute, etc.
XPath axes help to find elements based on the element’s relationship with another element in an XML document.
XML documents contain one or more element nodes. They are considered as trees of nodes.
If an element contains content, whether it is other elements or text, then it must be declared a start tag and an end tag.
The text defined between the start tag and end tag is the element content.
The topmost element of the tree is called root element.
An example of a basic HTML page is shown below screenshot.
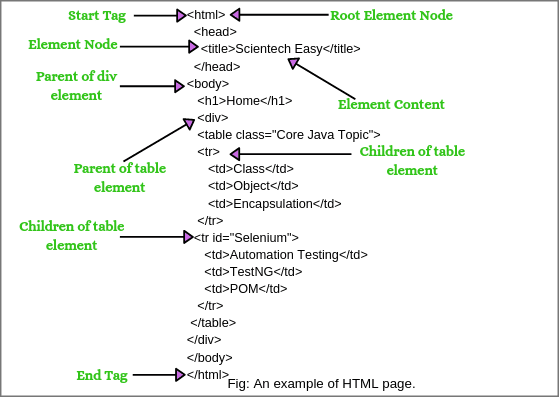
Let’s understand some basic XPath terminology before moving XPath axes.
XPath Terminology: Nodes, Atomic values, Parents, Children, Siblings
1. Nodes:
DOM represents trees of nodes. The topmost element of the tree is called root node. The example of nodes in the XML document above:
“html” is the root of element node, “title” is an element node. XPath contains seven kinds of nodes: element, attribute, text, namespace, processing-instruction, comment, and document nodes.
2. Atomic values:
The node which has no parents or children is called atomic values. For example, Automation Testing, TestNG, POM.
3. Parents:
Each element and attribute has one parent like father or mother. For example, “body” is the parent of div element. “div” is the parent of the table element.
4. Children:
Element nodes that may contain zero, one, or more children. For example, tr is children of table element, div is the children of body element, table is children of div element.
5. Siblings:
The node that has the same parent is called siblings. In the above XML document, title and body elements both are siblings.
XPath Axes Methods in Selenium
To navigate the hierarchical tree of nodes in an XML document, XPath uses the concept of axes. The XPath specification defines a total of 13 different axes that we will learn in this section.
A list of 13 XPath axes methods in Selenium WebDriver is as follows:
- Child Axis
- Parent Axis
- Self Axis
- Ancestor Axis
- Ancestor-or-self Axis
- Descendant Axis
- Descendant-or-self Axis
- Following Axis
- Following-sibling Axis
- Preceding Axis
- Preceding-sibling Axis
- Attribute Axis
- Namespace Axis
Each axis contains various nodes that depend on the current node. An XPath axis is a collection of nodes that satisfy the current navigation criteria.
Child Axis:
The child axis is one of the 13 XPath axes that contains all the child nodes of the current context. It selects all children elements of the current node.
The syntax of child axis is given below:
Syntax: //child::tagName
For example, open webpage https://www.yandex.com, right-click on Yandex.in and go to inspect option as shown below screenshot.
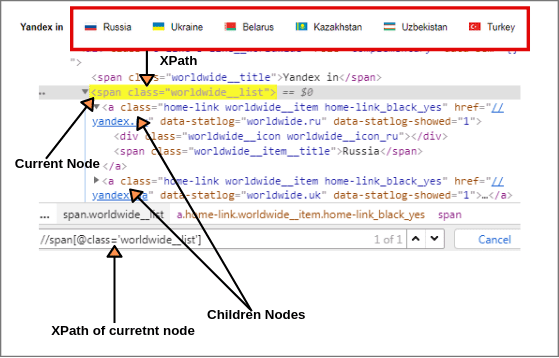
Select all children elements of the current node as shown in the above screen. First, we will find XPath of the current node.
XPath of current node: //span[@class = 'worldwide__list']
Now we will find out XPath of children elements of current node using child axis as shown in above figure.
XPath of all children elements: //span[@class = 'worldwide__list']//child::a (1 of 6 matched)
This expression identified six children nodes using the child axis. We can get the XPath of different children elements according to the requirement by putting [1],[2]…………and so on.
XPath(Russia): //span[@class = 'worldwide__list']//child::a[1] (1 of 1 matched) XPath(Ukraine): //span[@class = 'worldwide__list']//child::a[2] (1 of 1 matched) XPath(Belarus): //span[@class = 'worldwide__list']//child::a[3] and so on.
Parent Axis:
The parent axis selects the parent of the current node. The parent node may be either root node or element node. The root node has no parent.
Therefore, when the current node is root node, the parent axis is empty. For all other element nodes, the parent axis contains a maximum of one node.
The syntax of parent axis is given below:
Syntax: //parent::tagName
Let’s take a scenario for example.
Open the website yandex.com and right-click on the search box. We will find the parent of the current node. Choose a search input box as a current node and find XPath of the current node (Search box).
XPath(Current node): //input[@id = 'text'] (1 of 1 matched).
Now we will find the XPath of the parent element node of current node using parent syntax as shown below screenshot:
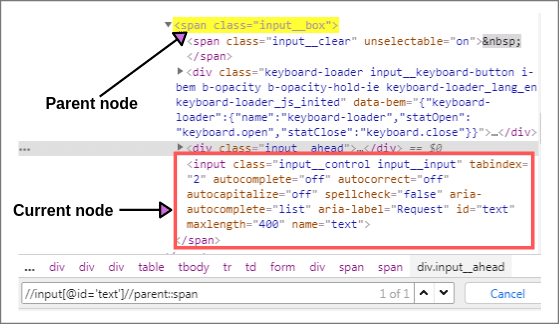
XPath(Parent node): //input[@id = 'text']//parent::span (1 of 1 matched)
It will select the parent node of the input tag of Id = ‘text’.
XPath(Parent node): //input[@id = 'text']//parent::* (1 of 1 matched)
Self Axis:
Self axis selects the element of the current node. It always finds only one node that represents self-element.
Syntax: //self::tagName
For example, we can also find XPath of the current element node using self axis as shown in the above screenshot.
XPath(Current node): //input[@id = 'text']//self::input (1 of 1 matched) or, XPath(Current node): //input[@id = 'text']//self::*
Ancestor Axis:
The ancestor axis selects all ancestor elements (parent, grandparent, great-grandparents, etc.) of the current node. This axis always contains the root node (unless the current node is the root node).
Syntax:
//ancestor::tagName
Let’s take an example to understand the concepts of ancestor axis.
Open www.facebook.com, right-click on the login button, and go to inspect option. You will see HTML code of login button as shown below screenshot:
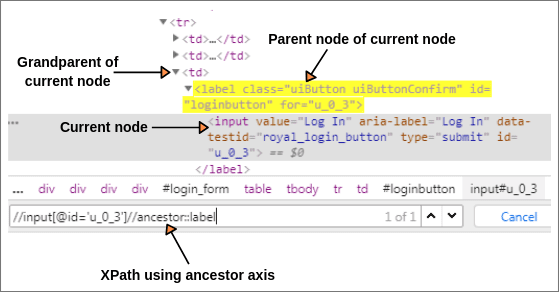
Let us consider the login button as current node. First, we will find the XPath of current node.
XPath(Current node): //input[@id = 'u_0_a']
Now, we will find XPath of parent and grandparent of current node.
XPath(Parent node): //input[@id = 'u_0_a']//ancestor::label XPath(Grandparent node): //input[@id = 'u_0_a']//ancestor::td
In both cases, 1 of 1 node is matched by using “ancestor” axis.
Ancestor-or-self Axis:
This axis selects all ancestor elements (parent, grandparent, great-grandparents, etc.) of the current node and the current node itself.
Let us find XPath of current node (login button) by using the ancestor-or-self axis.
XPath(login button): //input[@id = 'u_0_3']//ancestor-or-self::input
The above expression identified the current element node.
Descendant Axis:
The descendant axis selects all descendant elements (children, grandchildren, etc) of the current node. Let’s take an example to understand the concepts of the descendant axis.
Open webpage https://pixabay.com/accounts/register/?source=signup_button_header, right-click on Username element, and go to inspect option.
As shown in the below screenshot, let’s suppose “signup_form new” as a current node. You can bring the cursor to this node to see current node.

The XPath of current node will be as follow:
XPath(Current node): //div[@class = 'signup_form new']
Now using the descendant axis with above XPath, we can find easily all children, grandchildren elements, etc of current node.
XPath: //div[@class = 'signup_form new']//descendant::input (1 of 3)
The above XPath expression identified three elements like username, password, and email address. So, we can write XPath by putting 1, 2, and 3 in the above expression.
XPath(Username): //div[@class='signup_form new']//descendant::input[1] (1 of 1 matched) XPath(Email address): //div[@class = 'signup_form new']//descendant::input[2] XPath(Password): //div[@class = 'signup_form new']//descendant::input[3]
Descendant-or-self Axis:
The descendant-or-self axis selects all descendants (children, grandchildren, etc) of the current node and current node itself. In the above screenshot, div is the current node. We can select this current node using the descendant-or-self axis.
The XPath of current node is as follows:
XPath(Current node): //div[@class = 'signup_form new']//descendant-or-self::div
The above expression identified 1 node. If we change tagname in the above XPath expression from div to input then we can get node of username, email address, and password.
Let’s find the XPath of these nodes.
XPath(Username): //div[@class = 'signup_form new']//descendant-or-self::input[1] XPath(Email address): //div[@class = 'signup_form new']//descendant-or-self::input[2]
Following Axis:
The following axis selects all elements (nodes) in the document after closing tag of the current node. Let’s consider “First name” input box as current node in the Facebook webpage.
The XPath of the current node is as follows:
XPath(Current node): //input[@id = 'u_0_r']
Now we will find all elements like Surname, Mobile number, etc by using the following axis of the current node. The below syntax will select the immediate node following the current node.
XPath: //input[@id = 'u_0_r']//following::input (1 of 23)
The above expression has identified 23 nodes matching by using “following” axis-surname, mobile number, new password, etc.
If you want to focus on any particular element then you can change the XPath according to the requirement by putting [1],[2]…………and so on like this.
XPath(Surname): //input[@id = 'u_0_r']//following::input[1] (1 of 1 matched)
By putting “1” as input, the above expression finds the particular node that is ‘Surname’ input box element.
Similarly, on putting “2” as input,
XPath(Mobile number): //input[@id = 'u_0_r']//following::input[2] (1 of 1 matched).
The following-sibling selects all sibling nodes after the current node at the same level. i.e. It will find the element after the current node.
For example, the radio button of female and female text both are siblings on the Facebook home page as shown in the below screenshot.
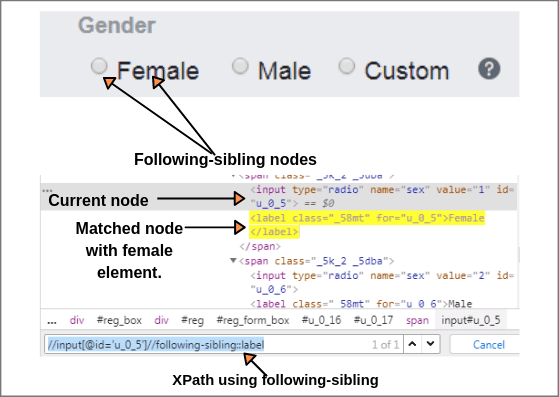
So, we will find XPath of current node i.e. XPath of the female radio button.
XPath(Radio button): //input[@id = 'u_0_5']
Using the following-sibling axis, we can easily find XPath of text “Female” at the same level.
XPath(Female): //input[@id = 'u_0_5']//following-sibling::label (1 of 1 matched).
The above expression identified one input nodes by using “following-sibling” axis.
Preceding Axis:
The preceding axis selects all nodes that come before the current node in the document, except ancestor, attribute nodes, and namespace nodes.
Let us consider the login button as current node on the Facebook web page as shown below screenshot.
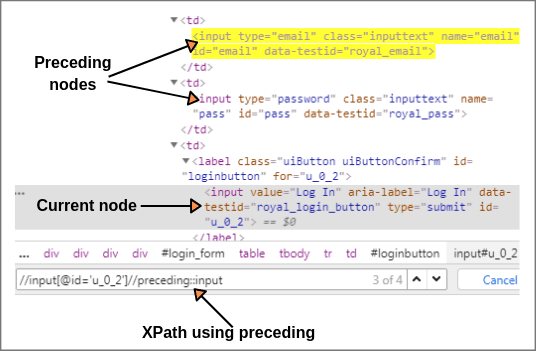
Let’s first, find the XPath of current node i.e XPath of login button.
XPath(Current node): //input[@id = 'u_0_2']
Now we will select all nodes by using the preceding axis in the document that comes before the current node.
XPath: //input[@id = 'u_0_2']//preceding::input (1 of 4 matched).
The above expression identified all the input elements before “login” button using the preceding axis. 2 of 4 matches nodes are matched with Email and Password input elements.
If you want to focus on any particular element like “Email” or “Password” then you can change the XPath according to the requirement by putting [1],[2]…………and so on. For example:
XPath(Email): //input[@id = 'u_0_2']//preceding::input[2] (1 of 1) XPath(Password): //input[@id = 'u_0_2']//preceding::input[1]
Preceding-sibling Axis:
The preceding-sibling axis selects all siblings before the current node. Let’s take an example to understand the concept of the preceding-sibling axis.
Open web page www.pixabay.com, right-click on videos link and go to inspect option.
Let’s consider videos link as current node as shown in below screenshot and find the XPath of current node by using text() method.

XPath(Current node): //a[text() = 'Videos']
Now we will find all nodes using preceding-sibling axis of the current node in the document.
XPath: //a[text() = 'Videos']//preceding-sibling::a (1 of 3)
The above expression identified three nodes before the current node (videos link) as shown in above screenshot.
Using this expression, we can easily find XPath of preceding-sibling elements like Photos, Illustrations, and Vectors like this:
XPath(Photos): //a[text() = 'Videos']//preceding-sibling::a[3] XPath(Illustrations): //a[text() = 'Videos']//preceding-sibling::a[2] XPath(Vectors): //a[text() = 'Videos']//preceding-sibling::a[1]
Attribute Axis:
This axis selects the element node on the basis of the attribute identifier (@) of the current node. If the current node is not an element node, this axis is empty. The expressions attribute::type and @type both are equivalent.
For example:
Open the webpage www.pixabay.com, right-click on the search input box, and go to inspect. We can write the XPath of search input box (current node) using the attribute axis.
XPath(Search box): //input[attribute::name = 'q']
Namespace Axis:
The namespace axis is one of 13 XPath axes that selects all namespace nodes associated with current node. If the current node is not an element node then this axis will be empty.
Hope that this tutorial has covered almost all important points related to 13 XPath axes methods with examples. I hope that you will have understood and enjoyed this topic and performed it in the chrome browser.
The XPath axes like child, parent, ancestor, following, and preceding are vary important for the Selenium technical test in any company.
Thanks for reading!!!
Next ⇒ isDisplayed, isSelected, isEnabled methods in Selenium⇐ PrevNext ⇒