Простая линейная регрессия — это статистический метод, который можно использовать для понимания связи между двумя переменными, x и y.
Одна переменная x известна как предикторная переменная. Другая переменная, y , известна как переменная ответа .
Например, предположим, что у нас есть следующий набор данных с весом и ростом семи человек:
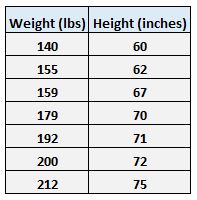
Пусть вес будет предикторной переменной, а рост — переменной отклика.
Если мы изобразим эти две переменные с помощью диаграммы рассеяния с весом по оси x и высотой по оси y, вот как это будет выглядеть:

На диаграмме рассеяния мы ясно видим, что по мере увеличения веса рост также имеет тенденцию к увеличению, но для фактической количественной оценки этой взаимосвязи между весом и ростом нам нужно использовать линейную регрессию.
Используя линейную регрессию, мы можем найти линию, которая лучше всего «соответствует» нашим данным:

Формула для этой линии наилучшего соответствия записывается так:
ŷ = б 0 + б 1 х
где ŷ — прогнозируемое значение переменной отклика, b 0 — точка пересечения с осью y, b 1 — коэффициент регрессии, а x — значение переменной-предиктора.
В этом примере линия наилучшего соответствия:
рост = 32,783 + 0,2001*(вес)
Как рассчитать остатки
Обратите внимание, что точки данных на нашей диаграмме рассеяния не всегда точно попадают на линию наилучшего соответствия:
Эта разница между точкой данных и линией называется остатком.Для каждой точки данных мы можем рассчитать остаток этой точки, взяв разницу между ее фактическим значением и прогнозируемым значением из линии наилучшего соответствия.
Пример 1: Расчет остатка
Например, вспомните вес и рост семи человек в нашем наборе данных:
Первая особь имеет вес 140 фунтов. и высотой 60 дюймов.
Чтобы узнать прогнозируемый рост для этого человека, мы можем подставить его вес в уравнение наилучшего соответствия:
рост = 32,783 + 0,2001*(вес)
Таким образом, прогнозируемый рост этого человека:
высота = 32,783 + 0,2001*(140)
высота = 60,797 дюйма
Таким образом, невязка для этой точки данных составляет 60 – 60,797 = -0,797 .
Пример 2: Расчет остатка
Мы можем использовать тот же самый процесс, который мы использовали выше, для вычисления невязки для каждой точки данных. Например, давайте рассчитаем остаток для второго человека в нашем наборе данных:
Второй человек имеет вес 155 фунтов. и высотой 62 дюйма.
Чтобы узнать прогнозируемый рост для этого человека, мы можем подставить его вес в уравнение наилучшего соответствия:
рост = 32,783 + 0,2001*(вес)
Таким образом, прогнозируемый рост этого человека:
высота = 32,783 + 0,2001*(155)
высота = 63,7985 дюйма
Таким образом, остаток для этой точки данных составляет 62 – 63,7985 = -1,7985 .
Вычисление всех остатков
Используя тот же метод, что и в предыдущих двух примерах, мы можем рассчитать остатки для каждой точки данных:

Обратите внимание, что некоторые остатки положительны, а некоторые отрицательны. Если мы сложим все остатки, они в сумме дадут ноль.
Это связано с тем, что линейная регрессия находит линию, которая минимизирует общие квадраты остатков, поэтому линия идеально проходит через данные, причем некоторые точки данных лежат над линией, а некоторые — под линией.
Визуализация остатков
Напомним, что невязка — это просто расстояние между фактическим значением данных и значением, предсказанным линией регрессии наилучшего соответствия. Вот как эти расстояния выглядят визуально на диаграмме рассеивания:

Обратите внимание, что некоторые остатки больше других. Кроме того, некоторые остатки положительны, а некоторые отрицательны, как мы упоминали ранее.
Создание остаточного графика
Весь смысл вычисления остатков состоит в том, чтобы увидеть, насколько хорошо линия регрессии соответствует данным.
Большие невязки указывают на то, что линия регрессии плохо соответствует данным, т. е. фактические точки данных не совпадают с линией регрессии.
Меньшие невязки указывают на то, что линия регрессии лучше соответствует данным, т. е. фактические точки данных располагаются близко к линии регрессии.
Одним из полезных типов графика для одновременной визуализации всех остатков является остаточный график. Остаточный график — это тип графика, который отображает прогнозируемые значения в сравнении с остаточными значениями для регрессионной модели.
Этот тип графика часто используется для оценки того, подходит ли модель линейной регрессии для данного набора данных, и для проверки гетероскедастичности остатков.
Ознакомьтесь с этим учебным пособием , чтобы узнать, как создать остаточный график для простой модели линейной регрессии в Excel.
Как найти остатки уравнения регрессии
Уважаемые посетители Портала Знаний, если Вы найдете ошибку в тексте, выделите, пожалуйста, ее мышью и нажмите Сtrl+Enter. Мы обязательно исправим текст!
Остатки регрессии
Остатки регрессии — это разности между наблюдаемыми значениями и значениями, предсказанными изучаемой регрессионной моделью.
Чем лучше регрессионная модель согласуется с данными, тем меньше величина остатков. i-ый остаток ( ) вычисляется как:
— соответствующее предсказанное значение.
В терминах матриц можно записать также:
Дисперсия остатков:
где — дисперсия ошибок модели
Дисперсия i-го остатка:
Стандартное отклонение i-го остатка:
Простая линейная регрессия
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных. [1]
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды. Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы — руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель — разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию — статистический метод, позволяющий предсказывать значения зависимой переменной Y по значениям независимой переменной X. В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y по значениям нескольких зависимых переменных (Х1, Х2, …, Xk). [2]
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Виды регрессионных моделей
В заметке Представление числовых данных в виде таблиц и диаграмм для иллюстрации зависимости между переменными X и Y использовалась диаграмма разброса. На ней значения переменной X откладывались по горизонтальной оси, а значения переменной Y — по вертикальной. Зависимость между двумя переменными может быть разной: от самой простой до крайне сложной. Пример простейшей (линейной) зависимости показан на рис. 1.

Рис. 1. Положительная линейная зависимость
Простая линейная регрессия:
где β0 — сдвиг (длина отрезка, отсекаемого на координатной оси прямой Y), β1 — наклон прямой Y, εi— случайная ошибка переменной Y в i-м наблюдении.
В этой модели наклон β1 представляет собой количество единиц измерения переменной Y, приходящихся на одну единицу измерения переменной X. Эта величина характеризует среднюю величину изменения переменной Y (положительного или отрицательного) на заданном отрезке оси X. Сдвиг β0 представляет собой среднее значение переменной Y, когда переменная X равна 0. Последний компонент модели εi является случайной ошибкой переменной Y в i-м наблюдении. Выбор подходящей математической модели зависит от распределения значений переменных X и Y на диаграмме разброса. Различные виды зависимости переменных показаны на рис. 2.
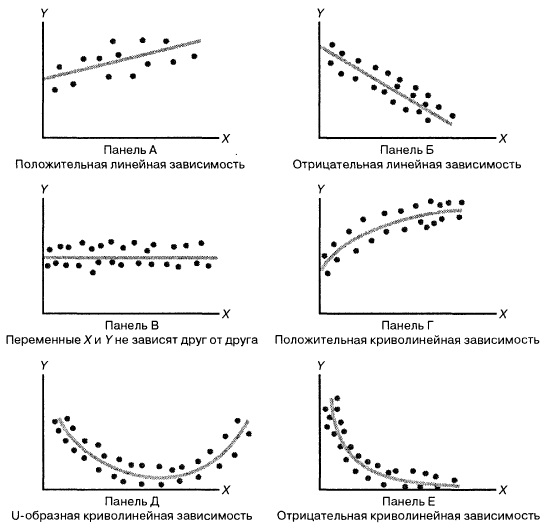
Рис. 2. Диаграммы разброса, иллюстрирующие разные виды зависимостей
На панели А значения переменной Y почти линейно возрастают с увеличением переменной X. Этот рисунок аналогичен рис. 1, иллюстрирующему положительную зависимость между размером магазина (в квадратных футах) и годовым объемом продаж. Панель Б является примером отрицательной линейной зависимости. Если переменная X возрастает, переменная Y в целом убывает. Примером этой зависимости является связь между стоимостью конкретного товара и объемом продаж. На панели В показан набор данных, в котором переменные X и Y практически не зависят друг от друга. Каждому значению переменной X соответствуют как большие, так и малые значения переменной Y. Данные, приведенные на панели Г, демонстрируют криволинейную зависимость между переменными X и Y. Значения переменной Y возрастают при увеличении переменной X, однако скорость роста после определенных значений переменной X падает. Примером положительной криволинейной зависимости является связь между возрастом и стоимостью обслуживания автомобилей. По мере старения машины стоимость ее обслуживания сначала резко возрастает, однако после определенного уровня стабилизируется. Панель Д демонстрирует параболическую U-образную форму зависимости между переменными X и Y. По мере увеличения значений переменной X значения переменной Y сначала убывают, а затем возрастают. Примером такой зависимости является связь между количеством ошибок, совершенных за час работы, и количеством отработанных часов. Сначала работник осваивается и делает много ошибок, потом привыкает, и количество ошибок уменьшается, однако после определенного момента он начинает чувствовать усталость, и число ошибок увеличивается. На панели Е показана экспоненциальная зависимость между переменными X и Y. В этом случае переменная Y сначала очень быстро убывает при возрастании переменной X, однако скорость этого убывания постепенно падает. Например, стоимость автомобиля при перепродаже экспоненциально зависит от его возраста. Если перепродавать автомобиль в течение первого года, его цена резко падает, однако впоследствии ее падение постепенно замедляется.
Мы кратко рассмотрели основные модели, которые позволяют формализовать зависимости между двумя переменными. Несмотря на то что диаграмма разброса чрезвычайно полезна при выборе математической модели зависимости, существуют более сложные и точные статистические процедуры, позволяющие описать отношения между переменными. В дальнейшем мы будем рассматривать лишь линейную зависимость.
Вывод уравнения простой линейной регрессии
Вернемся к сценарию, изложенному в начале главы. Наша цель — предсказать объем годовых продаж для всех новых магазинов, зная их размеры. Для оценки зависимости между размером магазина (в квадратных футах) и объемом его годовых продаж создадим выборки из 14 магазинов (рис. 3).

Рис. 3. Площади и годовые объемы продаж 14 магазинов сети Sunflowers: (а) исходные данные; (б) диаграмма разброса
Анализ рис. 3 показывает, что между площадью магазина X и годовым объемом продаж Y существует положительная зависимость. Если площадь магазина увеличивается, объем продаж возрастает почти линейно. Таким образом, наиболее подходящей для исследования является линейная модель. Остается лишь определить, какая из линейных моделей точнее остальных описывает зависимость между анализируемыми переменными.
Метод наименьших квадратов
Данные, представленные на рис. 1а, получены для случайной выборки магазинов. Если верны некоторые предположения (об этом чуть позже), в качестве оценки параметров генеральной совокупности (β0 и β1) можно использовать сдвиг b0 и наклон b1 прямой Y. Таким образом, уравнение простой линейной регрессии принимает следующий вид:

где  — предсказанное значение переменной Y для i-гo наблюдения, Xi — значение переменной X в i-м наблюдении.
— предсказанное значение переменной Y для i-гo наблюдения, Xi — значение переменной X в i-м наблюдении.
Для того чтобы предсказать значение переменной Y, в уравнении (2) необходимо определить два коэффициента регрессии — сдвиг b0 и наклон b1 прямой Y. Вычислив эти параметры, проведем прямую на диаграмме разброса. Затем исследователь может визуально оценить, насколько близка регрессионная прямая к точкам наблюдения. Простая линейная регрессия позволяет найти прямую линию, максимально приближенную к точкам наблюдения. Критерии соответствия можно задать разными способами. Возможно, проще всего минимизировать разности между фактическими значениями Yi, и предсказанными значениями . Однако, поскольку эти разности могут быть как положительными, так и отрицательными, следует минимизировать сумму их квадратов.
Поскольку = b0 + b1Xi, сумма квадратов принимает следующий вид:

Параметры b0 и b1 неизвестны. Таким образом, сумма квадратов разностей является функцией, зависящей от сдвига b0 и наклона b1 выборки Y. Для того чтобы найти значения параметров b0 и b1, минимизирующих сумму квадратов разностей, применяется метод наименьших квадратов. При любых других значениях сдвига b0 и наклона b1 сумма квадратов разностей между фактическими значениями переменной Y и ее наблюдаемыми значениями лишь увеличится.
До того, как Excel взял на себя всю рутинную работу, вычисления по методу наименьших квадратов были очень трудоемкими. Excel позволяет решать подобные задачи двумя способами. Во-первых, можно воспользоваться Пакетом анализа (строка Регрессия). Результаты представлены на рис. 4. Во-вторых, можно, выделив точки на графике (как на рис. 3б), кликнуть правой кнопкой мыши и выбрать Добавить линию тренда. Далее можно выбрать вид линии тренда (в нашем случае – Линейная), отформатировать линию, показать на графике уравнение и величину достоверности аппроксимации (R 2 ) (рис. 5).
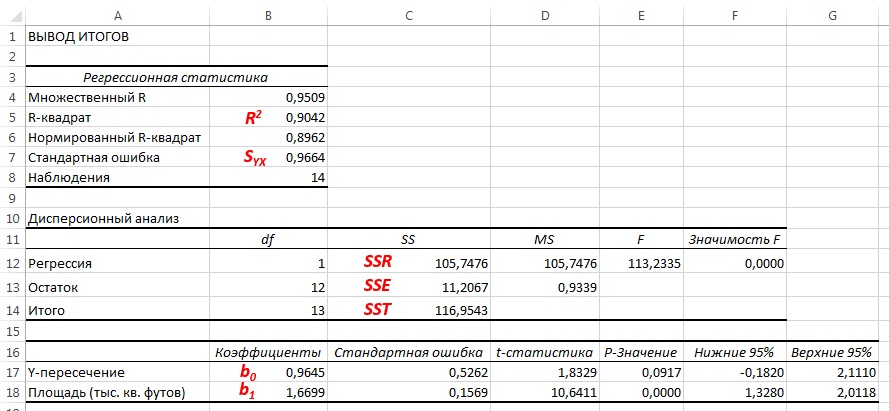
Рис. 4. Результаты решения задачи о зависимости между площадями и годовыми объемами продаж в магазинах сети Sunflower (получены с помощью Пакета анализа Excel)
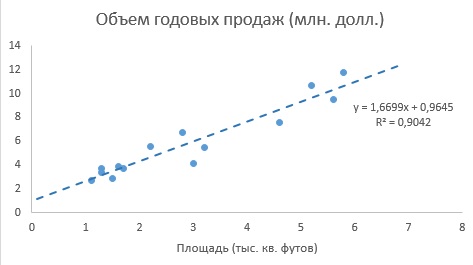
Рис. 5. Диаграмма разброса и линия регрессии (тренда) в задаче о выборе магазина
Как следует из рис. 4 и 5, b0 = 0,9645, а b1 = 1,6699. Таким образом, уравнение линейной регрессии для этих данных имеет следующий вид: = 0,9645 + 1,6699Xi. Вычисленный наклон b1 = +1,6699. Это означает, что при возрастании переменной X на единицу среднее значение переменной Y возрастает на 1,6699 единиц. Иначе говоря, увеличение площади магазина на один квадратный фут приводит к увеличению годового объема продаж на 1,67 тыс. долл. Таким образом, наклон представляет собой долю годового объема продаж, зависящую от размера магазина. Вычисленный сдвиг b0 = +0,9645 (млн. долл.). Эта величина представляет собой среднее значение переменной Y при X = 0. Поскольку площадь магазина не может равняться нулю, сдвиг можно считать долей годового дохода, зависящей от других факторов. Следует отметить, однако, что сдвиг переменной Y выходит за пределы диапазона переменной X. Следовательно, к интерпретации параметра b0 необходимо относиться внимательно.
Пример 1. Один экономист решил предсказать изменение индекса 500 наиболее активно покупаемых акций на Нью-Йоркской фондовой бирже, публикуемого агентством Standard and Poor, на основе показателей экономики США за 50 лет. В результате он получил следующее уравнение линейной регрессии: Ŷi = –5,0 + 7Хi. Какой смысл имеют параметры сдвига b0 и наклона b1.
Решение. Сдвиг регрессии b0 равен –5,0. Это значит, что если рост экономики США равен нулю, индекс акций за год снизится на 5%. Наклон b1 равен 7. Следовательно, при увеличении темпов роста экономики на 1% индекс акций возрастает на 7%.
Пример 2. Вернемся к сценарию, изложенному в начале заметки. Применим модель линейной регрессии для прогноза объема годовых продаж во всех новых магазинах в зависимости от их размеров. Предположим, что площадь магазина равна 4000 квадратных футов. Какой среднегодовой объем продаж можно прогнозировать?
Решение. Подставим значение X = 4 (тыс. кв. футов) в уравнение линейной регрессии: = 0,9645 + 1,6699Xi = 0,9645 + 1,6699*4 = 7,644 млн. долл. Итак, прогнозируемый среднегодовой объем продаж в магазине, площадь которого равна 4000 кв. футов, составляет 7 644 000 долл.
Прогнозирование в регрессионном анализе: интерполяция и экстраполяция
Применяя регрессионную модель для прогнозирования, необходимо учитывать лишь допустимые значения независимой переменной. В этот диапазон входят все значения переменной X, начиная с минимальной и заканчивая максимальной. Таким образом, предсказывая значение переменной Y при конкретном значении переменной X, исследователь выполняет интерполяцию между значениями переменной X в диапазоне возможных значений. Однако экстраполяция значений за пределы этого интервала не всегда релевантна. Например, пытаясь предсказать среднегодовой объем продаж в магазине, зная его площадь (рис. 3а), мы можем вычислять значение переменной Y лишь для значений X от 1,1 до 5,8 тыс. кв. футов. Следовательно, прогнозировать среднегодовой объем продаж можно лишь для магазинов, площадь которых не выходит за пределы указанного диапазона. Любая попытка экстраполяции означает, что мы предполагаем, будто линейная регрессия сохраняет свой характер за пределами допустимого диапазона.
Оценки изменчивости
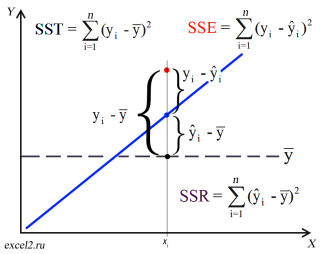
Вычисление сумм квадратов. Для того чтобы предсказать значение зависимой переменной по значениям независимой переменной в рамках избранной статистической модели, необходимо оценить изменчивость. Существует несколько способов оценки изменчивости. Первый способ использует общую сумму квадратов (total sum of squares — SST), позволяющую оценить колебания значений Yi вокруг среднего значения  . В регрессионном анализе полная вариация, представляющая собой полную сумму квадратов, разделяется на объяснимую вариацию, или сумму квадратов регрессии (regression sum of squares — SSR), и необъяснимую вариацию, или сумму квадратов ошибок (error sum of squares — SSE). Объяснимая вариация характеризует взаимосвязь между переменными X и Y, а необъяснимая зависит от других факторов (рис. 6).
. В регрессионном анализе полная вариация, представляющая собой полную сумму квадратов, разделяется на объяснимую вариацию, или сумму квадратов регрессии (regression sum of squares — SSR), и необъяснимую вариацию, или сумму квадратов ошибок (error sum of squares — SSE). Объяснимая вариация характеризует взаимосвязь между переменными X и Y, а необъяснимая зависит от других факторов (рис. 6).

Рис. 6. Оценки изменчивости в модели регрессии
Сумма квадратов регрессии (SSR) представляет собой сумму квадратов разностей между Ŷi (предсказанным значением переменной Y) и (средним значением переменной Y). Сумма квадратов ошибок (SSE) является частью вариации переменной Y, которую невозможно описать с помощью регрессионной модели. Эта величина зависит от разностей между наблюдаемыми и предсказанными значениями.
Полная сумма квадратов (SST) равна сумме квадратов регрессии плюс сумма квадратов ошибок:
(3) SST = SSR + SSE
Полная сумма квадратов (SST) равна сумме квадратов разностей между наблюдаемыми значениями переменной Y и ее средним значением:

Сумма квадратов регрессии (SSR) равна сумме квадратов разностей между предсказанными значениями переменной Y и ее средним значением:

Сумма квадратов ошибок (SSE) равна сумме квадратов разностей между наблюдаемыми и предсказанными значениями переменной Y:

Суммы квадратов, вычисленные с помощью программы Пакета анализа Excel при решении задачи о сети магазинов Sunflowers, представлены на рис. 4.
Полная сумма квадратов разностей равна SST = 116,9543. Эта величина состоит из суммы квадратов регрессии (SSR) равной 105,7476, и суммы квадратов ошибок (SSE), равной 11,2067.
Коэффициент смешанной корреляции. Величины SSR, SSE и SST не имеют очевидной интерпретации. Однако отношение суммы квадратов регрессии (SSR) к полной сумме квадратов (SST) представляет собой оценку полезности регрессионного уравнения. Это отношение называется коэффициентом смешанной корреляции r 2 :

Коэффициент смешанной корреляции оценивает долю вариации переменной Y, которая объясняется независимой переменной X в регрессионной модели. В задаче о сети магазинов Sunflowers SSR = 105,7476 и SST = 116,9543. Следовательно, r 2 = 105,7476 / 116,9543 = 0,904. Таким образом, 90,4% вариации годового объема продаж объясняется изменчивостью площади магазинов, измеренной в квадратных футах. Данная величина r 2 свидетельствует о сильной положительной линейной взаимосвязи между двумя переменными, поскольку применение регрессионной модели снижает изменчивость прогнозируемых годовых объемов продаж на 90,4%. Только 9,6% изменчивости годовых объемов продаж в выборке магазинов объясняются другими факторами, не учтенными в регрессионной модели.
Коэффициент смешанной корреляции в задаче о сети магазинов Sunflowers представлен в таблице Регрессионная статистика на рис. 4.
Среднеквадратичная ошибка оценки. Хотя метод наименьших квадратов позволяет вычислить линию, минимизирующую отклонение от наблюдаемых значений, наличие суммы квадратов ошибок (SSE) свидетельствует о том, что линейная регрессия не дает абсолютной точности прогноза, если, конечно, точки наблюдения не лежат на регрессионной прямой. Однако ожидать этого так же неестественно, как предполагать, что все выборочные значения точно равны их среднему арифметическому. Следовательно, необходима статистика, которая позволила бы оценить отклонение предсказанных значений переменной Y от ее реальных значений, аналогично тому, как стандартное отклонение, введенное ранее, позволяет оценить колебание данных вокруг их средней величины. Стандартное отклонение наблюдаемых значений переменной Y от ее регрессионной прямой называется среднеквадратичной ошибкой оценки. Отклонение реальных данных от регрессионной прямой в задаче о сети магазинов Sunflowers показано на рис. 5.
Среднеквадратичная ошибка оценки

где Yi — фактическое значение переменной Y при заданном значении Xi, Ŷi — предсказанное значение переменной Y при заданном значении Xi, SSE — сумма квадратов ошибок.
Поскольку SSE = 11,2067, по формуле (8) получаем:

Таким образом, среднеквадратичная ошибка оценки равна 0,9664 млн. долл. (т.е. 966 400 долл.). Этот параметр также рассчитывается Пакетом анализа (см. рис. 4). Среднеквадратичная ошибка оценки характеризует отклонение реальных данных от линии регрессии. Она измеряется в тех же единицах, что и переменная Y. По смыслу среднеквадратичная ошибка очень похожа на стандартное отклонение. В то время как стандартное отклонение характеризует разброс данных вокруг их среднего значения, среднеквадратичная ошибка позволяет оценить колебание точек наблюдения вокруг регрессионной прямой. Cреднеквадратичная ошибка оценки позволяет обнаружить статистически значимую зависимость, существующую между двумя переменными, и предсказать значения переменной Y.
Предположения
Обсуждая методы проверки гипотез и дисперсионного анализа, мы не раз подчеркивали важность условий, которые должны обеспечивать корректность сделанных выводов. Поскольку и регрессионный, и дисперсионный анализ используют линейную модель, условия их применения приблизительно одинаковы:
- Ошибка должна иметь нормальное распределение.
- Вариация данных вокруг линии регрессии должна быть постоянной.
- Ошибки должны быть независимыми.
Первое предположение, о нормальном распределении ошибок, требует, чтобы при каждом значении переменной X ошибки линейной регрессии имели нормальное распределение (рис. 7). Как и t— и F-критерий дисперсионного анализа, регрессионный анализ довольно устойчив к нарушениям этого условия. Если распределение ошибок относительно линии регрессии при каждом значении X не слишком сильно отличается от нормального, выводы относительно линии регрессии и коэффициентов регрессии изменяются незначительно.

Рис. 7. Предположение о нормальном распределении ошибок
Второе условие заключается в том, что вариация данных вокруг линии регрессии должна быть постоянной при любом значении переменной X. Это означает, что величина ошибки как при малых, так и при больших значениях переменной X должна изменяться в одном и том же интервале (см. рис. 7). Это свойство очень важно для метода наименьших квадратов, с помощью которого определяются коэффициенты регрессии. Если это условие нарушается, следует применять либо преобразование данных, либо метод наименьших квадратов с весами.
Третье предположение, о независимости ошибок, заключается в том, что ошибки регрессии не должны зависеть от значения переменной X. Это условие особенно важно, если данные собираются на протяжении определенного отрезка времени. В этих ситуациях ошибки, присущие конкретному отрезку времени, часто коррелируют с ошибками, характерными для предыдущего периода.
Анализ остатков
Чуть выше при решении задачи о сети магазинов Sunflowers мы использовали модель линейной регрессии. Рассмотрим теперь анализ ошибок — графический метод, позволяющий оценить точность регрессионной модели. Кроме того, с его помощью можно обнаружить потенциальные нарушения условий применения регрессионного анализа.
Оценка пригодности эмпирической модели. Остаток, или оценка ошибки еi, представляет собой разность между наблюдаемым (Yi) и предсказанным (Ŷi) значениями зависимой переменной при заданном значении Xi.
Для оценки пригодности эмпирической модели регрессии остатки откладываются по вертикальной оси, а значения Xi — по горизонтальной. Если эмпирическая модель пригодна, график не должен иметь ярко выраженной закономерности. Если же модель регрессии не пригодна, на рисунке проявится зависимость между значениями Xi и остатками еi.
Рассмотрим примеры (рис. 8). Панель А иллюстрирует возрастание переменной Y при увеличении переменной X. Однако зависимость между этими переменными носит нелинейный характер, поскольку скорость возрастания переменной Y падает при увеличении переменной X. Таким образом, для аппроксимации зависимости между этими переменными лучше подойдет квадратичная модель. Особенно ярко квадратичная зависимость между величинами Xi и ei проявляется на панели Б. Графическое изображение остатков позволяет отфильтровать или удалить линейную зависимость между переменными X и Y и выявить недостаточную точность модели простой линейной регрессии. Таким образом, в данной ситуации вместо простой линейной модели должна применяться квадратичная модель, обладающая более высокой точностью.

Рис. 8. Исследование эмпирической модели простой линейной регрессии
Вернемся к задаче о сети магазинов Sunflowers и посмотрим, хорошо ли подходит простая линейная регрессия для ее решения. Соответствующие данные и расчеты приведены на рис. 9а (формулы можно посмотреть в Excel-файле). Построим диаграмму разброса, откладывая по вертикальной оси остатки ei, а по горизонтальной — независимую переменную Xi (рис. 9б). Несмотря на большой разброс остатков, между ei и Хi нет ярко выраженной зависимости. Остатки одинаково часто принимают как положительные, так и отрицательные значения. Это позволяет сделать вывод, что модель линейной регрессии пригодна для решения задачи о сети магазинов Sunflowers.
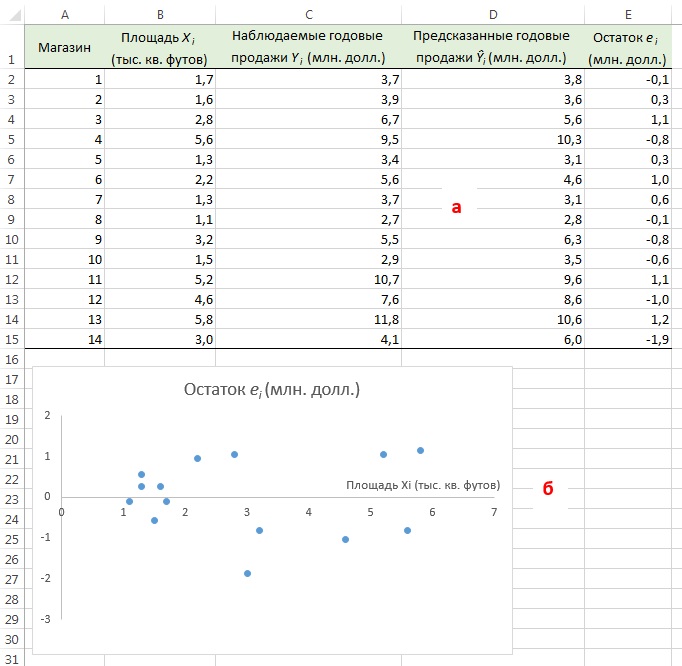
Рис. 9. Остатки ei, вычисленные при решении задачи о сети магазинов Sunflowers
Значения остатков (таблица на рис. 9а) и график остатков (аналог рис. 9б) можно получить непосредственно в процедуре Регрессия Пакета анализа. Просто поставьте соответствующие галки (рис. 10).

Рис. 10. Остатки ei и график остатков полученные с помощью Пакета анализа
Проверка условий. График остатков позволяет оценить вариации ошибок. На рис. 10 нет особых различий между ошибками, соответствующими разным значениям Xi. Следовательно, вариации ошибок при разных значениях Хi приблизительно одинаковы. Рассмотрим гипотетическую ситуацию, в которой это условие не выполняется (рис. 11). На этом рисунке изображен эффект веера: при возрастании значений Хi ошибки увеличиваются. Таким образом, изменчивость значений Yi при разных значениях Хi является непостоянной.

Рис. 11. Пример нарушения условия независимости вариаций ошибок от Xi
Нормальность. Чтобы проверить предположение о нормальном распределении ошибок, построим график нормального распределения на основе точечного графика, на вертикальной оси которого отложены значения остатков, а на горизонтальной оси — соответствующие квантили стандартизованного нормального распределения (подробнее см. Проверка гипотезы о нормальном распределении). Для построения такого графика значения остатков должны быть упорядочены по возрастанию (рис. 12). График нормального распределения может быть построен одним кликом с помощью Пакета анализа Excel – просто поставьте соответствующую галочку в окне Регрессия (см. рис. 10, самый низ окна Регрессия – опция График нормальной вероятности).

Рис. 12. График нормального распределения для остатков
Без визуализации данных (с помощью гистограммы, диаграммы «ствол и листья», блочной диаграммы или графика как на рис. 12) проверить предположение о нормальном распределении ошибок очень трудно. Данные, изображенные на рис. 12, не слишком сильно отличаются от нормального распределения. Устойчивость регрессионного анализа и небольшой объем выборки позволяют утверждать, что условие о нормальном распределении ошибок нарушается незначительно.
Независимость. Предположение о независимости ошибок также проверяется с помощью графика остатков. Данные, собранные на протяжении некоторого периода времени, иногда демонстрируют эффект автокорреляции между последовательными наблюдениями. В таких ситуациях остатки зависят от значений предыдущих остатков. Подобная связь между остатками нарушает предположение о независимости ошибок. Эффект автокорреляции хорошо выявляется на графике. Кроме того, его можно измерить с помощью процедуры Дурбина-Уотсона (см. ниже). Если данные о размерах магазинов и объемах продаж собирались в течение одного и того же периода времени, гипотезу об их независимости проверять не имеет смысла.
Измерение автокорреляции: статистика Дурбина–Уотсона
Одним из основных предположений о регрессионной модели является гипотеза о независимости ее ошибок. Если данные собираются в течение определенного отрезка времени, это условие часто нарушается, поскольку остаток в определенный момент времени может оказаться приблизительно равным предыдущим остаткам. Такое поведение остатков называется автокорреляцией. Если набор данных обладает свойством автокорреляции, корректность регрессионной модели становится весьма сомнительной.
Распознавание автокорреляции с помощью графика остатков. Для выявления автокорреляции необходимо упорядочить остатки по времени и построить их график. Если данные обладают положительной автокорреляцией, на графике возникнут кластеры остатков, имеющие одинаковый знак. В случае отрицательной автокорреляции остатки будут скачкообразно принимать то положительные, то отрицательные значения. Этот вид автокорреляции очень редко встречается в регрессионном анализе, поэтому мы рассмотрим лишь положительную автокорреляцию. Проиллюстрируем ее следующим примером. Предположим, что менеджер магазина, доставляющего товары на дом, пытается предсказать объем продаж по количеству клиентов, совершивших покупки в течение 15 недель (рис. 13).

Рис. 13. Количество клиентов и объемы продаж за 15 недель
Поскольку данные собирались на протяжении 15 последовательных недель в одном и том же магазине, необходимо определить, наблюдается ли эффект автокорреляции. Построим регрессию с использованием Пакета анализа; включим вывод Остатков, но не будем включать График остатков (рис. 14).
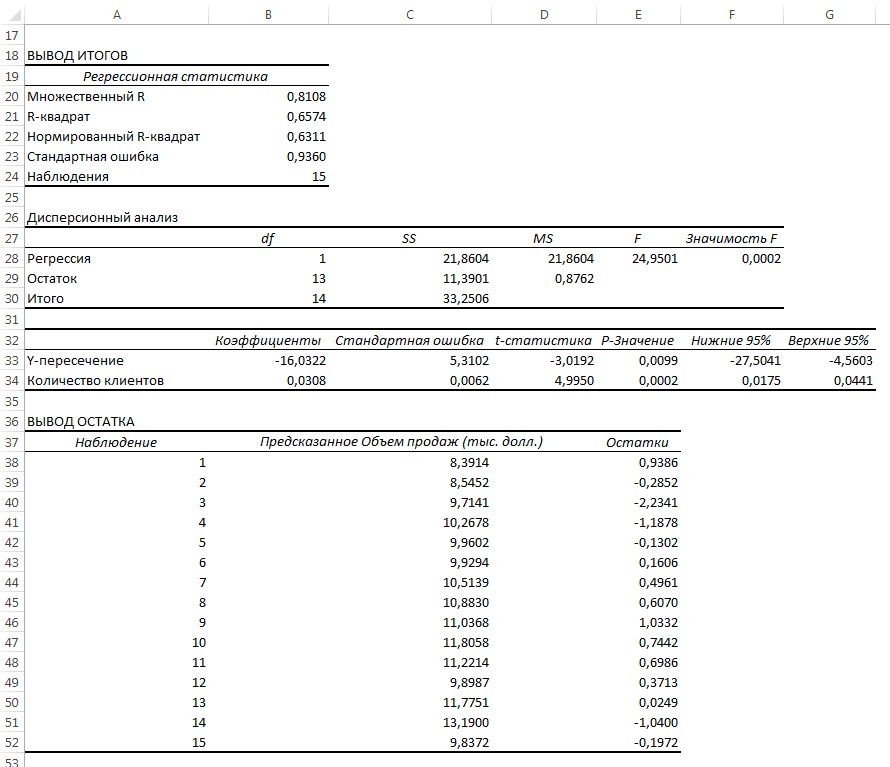
Рис. 14. Параметры линейной регрессии, полученные с использованием Пакета анализа
Анализ рис. 14 показывает, что r 2 = 0,657. Это значит, что 65,7% вариации объемов продаж объясняется изменчивостью количества клиентов. Кроме того, сдвиг b0 переменной Y равен –16,032, а наклон b1 = 0,0308. Однако, прежде чем применять эту модель, необходимо выполнить анализ остатков. Поскольку данные собирались на протяжении 15 последовательных недель, их следует отобразить на графике в том же порядке (рис. 15).

Рис. 15. Зависимость остатков от времени
Анализ рис. 15 показывает, что остатки циклически колеблются вверх и вниз. Эта цикличность является явным признаком автокорреляции. Следовательно, гипотезу о независимости остатков следует отклонить.
Статистика Дурбина-Уотсона. Автокорреляцию можно выявить и измерить с помощью статистики Дурбина-Уотсона. Эта статистика оценивает корреляцию между соседними остатками:

где еi — остаток, соответствующий i-му периоду времени.
Чтобы лучше понять статистику Дурбина-Уотсона, рассмотрим ее составные части. Числитель представляет собой сумму квадратов разностей между соседними остатками, начиная со второго и заканчивая n-м наблюдением. Знаменатель является суммой квадратов остатков. Вот, что по этому поводу написано в Википедии:

где ρ1 – коэффициент автокорреляции; если ρ1 = 0 (нет автокорреляции), D ≈ 2; если ρ1 ≈ 1 (положительная автокорреляции), D ≈ 0; если ρ1 = -1 (отрицательная автокорреляции), D ≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D с критическими теоретическими значениями dL и dU для заданного числа наблюдений n, числа независимых переменных модели k (для простой линейной регрессии k = 1) и уровня значимости α. Если D dU, гипотеза не отвергается (то есть автокорреляция отсутствует); если dL tU = 2,1788 (рис. 19), нулевая гипотеза Н0 отклоняется. С другой стороны, р-значение для Х = 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н0 снова отклоняется. Тот факт, что р-значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение F-критерия для наклона. Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F-критерия. Напомним, что F-критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. Однофакторный дисперсионный анализ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F-критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR, деленной на количество независимых переменных k), к дисперсии ошибок (MSE = SYX 2 ).
По определению F-статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F = MSR/MSE, где MSR = SSR / k, MSE = SSE/(n– k – 1), k – количество независимых переменных в регрессионной модели. Тестовая статистика F имеет F-распределение с k и n – k – 1 степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > FU, нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t-критерию F-критерий выводится в таблицу при использовании Пакета анализа (опция Регрессия). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к F-статистике – на рис. 21.

Рис. 21. Результаты применения F-критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р-значение близко к нулю (ячейка Значимость F). Если уровень значимости α равен 0,05, определить критическое значение F-распределения с одной и 12 степенями свободы можно по формуле FU =F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F = 113,23 > FU = 4,7472, причем р-значение близко к 0 0, r = – , если b1 2 = 0,904, а b1— +1,670 (см. рис. 4). Поскольку b1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t-статистику:
, если b1 2 = 0,904, а b1— +1,670 (см. рис. 4). Поскольку b1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t-статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t = 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y и предсказания индивидуальных значений Y при заданных значениях переменной X.
Построение доверительного интервала. В примере 2 (см. выше раздел Метод наименьших квадратов) регрессионное уравнение позволило предсказать значение переменной Y при заданном значении переменной X. В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. Ранее для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика при заданном значении переменной X:

где  , = b0 + b1Xi – предсказанное значение переменное Y при X = Xi, SYX – среднеквадратичная ошибка, n – объем выборки, Xi — заданное значение переменной X, µY|X=Xi – математическое ожидание переменной Y при Х = Хi, SSX =
, = b0 + b1Xi – предсказанное значение переменное Y при X = Xi, SYX – среднеквадратичная ошибка, n – объем выборки, Xi — заданное значение переменной X, µY|X=Xi – математическое ожидание переменной Y при Х = Хi, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений Xi. Если значение переменной Y предсказывается для величин X, близких к среднему значению  , доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
, доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения. Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X, часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика YX=Xi при конкретном значении переменной Xi определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел — вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа (кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, — набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х8 = 19, Y8 = 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.
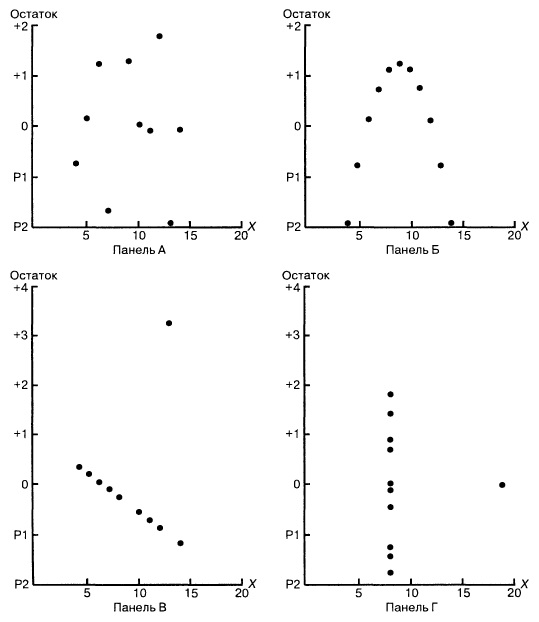
Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X и Y всегда начинайте с построения диаграммы разброса.
- Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме. Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t-критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.
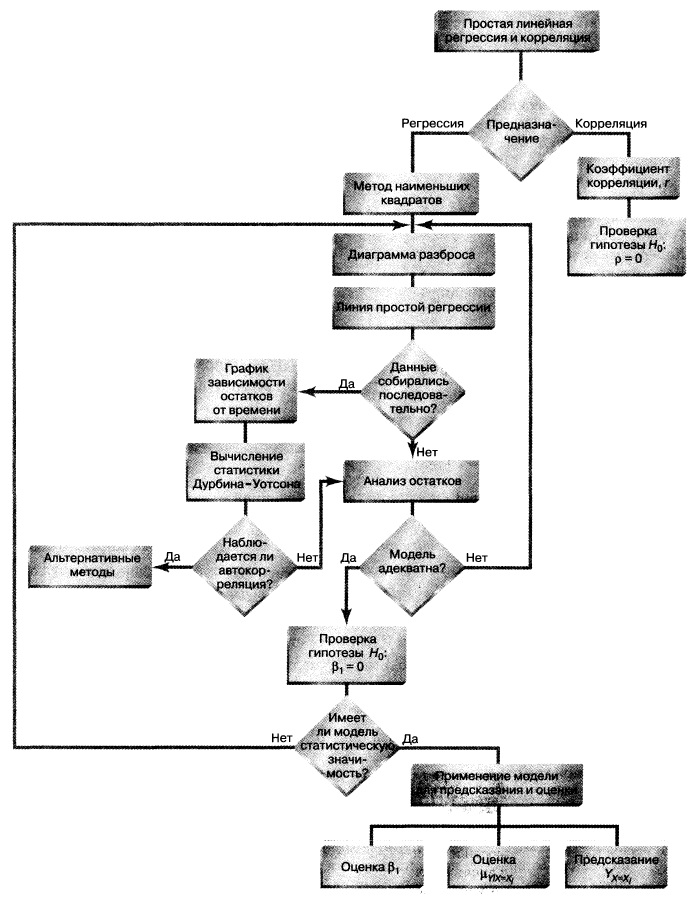
Рис. 27. Структурная схема заметки
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
[2] Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Простая линейная регрессия в EXCEL
history 26 января 2019 г.
-
Группы статей
- Статистический анализ
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В MS EXCEL имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Примечание : Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место множественная регрессия .
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части — оценке неизвестных параметров линейной модели .
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем прочность этого волокна (Y) зависит только от рабочей температуры процесса в реакторе (Х), которая задается оператором.
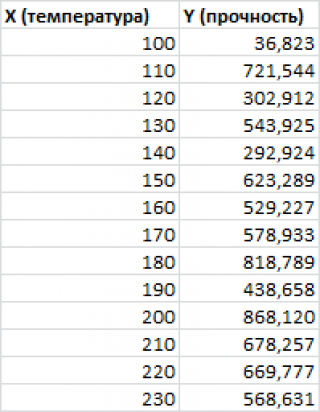
Построим диаграмму рассеяния (см. файл примера лист Линейный ), созданию которой посвящена отдельная статья . Вообще, построение диаграммы рассеяния для целей регрессионного анализа де-факто является стандартом.
СОВЕТ : Подробнее о построении различных типов диаграмм см. статьи Основы построения диаграмм и Основные типы диаграмм .
Приведенная выше диаграмма рассеяния свидетельствует о возможной линейной взаимосвязи между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание : Наличие даже такой очевидной линейной взаимосвязи не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие причинной взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание : Как известно, уравнение прямой линии имеет вид Y = m * X + k , где коэффициент m отвечает за наклон линии ( slope ), k – за сдвиг линии по вертикали ( intercept ), k равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х ( рабочую температуру процесса ) при некотором значении Х i и произвести несколько наблюдений переменной Y ( прочность нити ). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого значения . При увеличении количества измерений, среднее этих измерений, будет стремиться к математическому ожиданию случайной величины Y (при Х i ) равному μy(i)=Е(Y i ).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела Проверка статистических гипотез . В статье о проверке гипотезы о среднем значении генеральной совокупности в качестве нулевой гипотезы предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае простой линейной регрессии в качестве нулевой гипотезы предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ y(i) =α* Х i +β. Уравнение μ y(i) =α* Х i +β можно переписать в обобщенном виде (для всех Х и μ y ) как μ y =α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
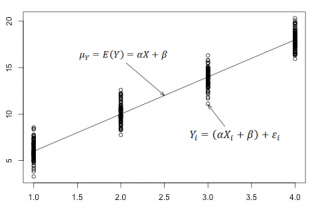
Данная линия называется регрессионной линией генеральной совокупности (population regression line), параметры которой ( наклон a и сдвиг β ) нам не известны (по аналогии с гипотезой о среднем значении генеральной совокупности , где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х + β , к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют линейной регрессионной моделью . Часто Х еще называют независимой переменной (еще предиктором и регрессором , английский термин predictor , regressor ), а Y – зависимой (или объясняемой , response variable ). Так как регрессор у нас один, то такая модель называется простой линейной регрессионной моделью ( simple linear regression model ). α часто называют коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε i была адекватной — требуется:
- Ошибки ε i должны быть независимыми переменными;
- При каждом значении Xi ошибки ε i должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε i ]=0);
- При каждом значении Xi ошибки ε i должны иметь равные дисперсии (обозначим ее σ 2 ).
Примечание : Последнее условие называется гомоскедастичность — стабильность, гомогенность дисперсии случайной ошибки e. Т.е. дисперсия ошибки σ 2 не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε i ]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε i ]= Е[a*Xi+β]+ Е[ε i ]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия случайной переменной Y равна дисперсии ошибки ε, т.е. VAR(Y)= VAR(ε)=σ 2 . Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε i ).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует регрессионная линия генеральной совокупности , т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений .
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно a и b . Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Первая задача регрессионного анализа – оценка неизвестных параметров ( estimation of the unknown parameters ). Подробнее см. раздел Оценки неизвестных параметров модели .
Вторая задача регрессионного анализа – Проверка адекватности модели ( model adequacy checking ).
Примечание : Оценки параметров модели обычно вычисляются методом наименьших квадратов (МНК), которому посвящена отдельная статья .
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры простой линейной регрессионной модели Y=a*X+β+ε оценим с помощью метода наименьших квадратов (в статье про МНК подробно описано этот метод ).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
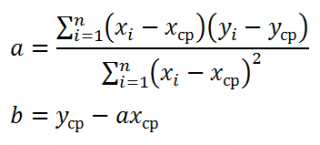
Таким образом, мы получим уравнение прямой линии Y= a *X+ b , которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание : В статье про метод наименьших квадратов рассмотрены случаи аппроксимации линейной и квадратичной функцией , а также степенной , логарифмической и экспоненциальной функцией .
Оценку параметров в MS EXCEL можно выполнить различными способами:
Сначала рассмотрим функции НАКЛОН() , ОТРЕЗОК() и ЛИНЕЙН() .
Пусть значения Х и Y находятся соответственно в диапазонах C 23: C 83 и B 23: B 83 (см. файл примера внизу статьи).
Примечание : Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью Генерация данных для линейной регрессии в MS EXCEL ).
В MS EXCEL наклон прямой линии а ( оценку коэффициента регрессии ), можно найти по методу МНК с помощью функции НАКЛОН() , а сдвиг b ( оценку постоянного члена или константы регрессии ), с помощью функции ОТРЕЗОК() . В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции ЛИНЕЙН() , английская версия LINEST (см. статью об этой функции ).
Формула =ЛИНЕЙН(C23:C83;B23:B83) вернет наклон а . А формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) — сдвиг b . Здесь требуются пояснения.
Функция ЛИНЕЙН() имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент статистика имеет значение ЛОЖЬ или опущен, то функция ЛИНЕЙН() возвращает только оценки параметров модели: a и b .
Примечание : Остальные значения, возвращаемые функцией ЛИНЕЙН() , нам потребуются при вычислении стандартных ошибок и для проверки значимости регрессии . В этом случае аргумент статистика должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
- ввести формулу в Строке формул
- нажать CTRL+SHIFT+ENTER (см. статью про формулы массива ).
Если в Строке формул выделить формулу = ЛИНЕЙН(C23:C83;B23:B83) и нажать клавишу F9 , то мы увидим что-то типа <3,01279389265416;154,240057900613>. Это как раз значения a и b . Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу = ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83)) . При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция ТРАНСП() транспонировала строку в столбец ).
Чтобы разобраться в этом подробнее необходимо ознакомиться с формулами массива .
Чтобы не связываться с вводом формул массива , можно использовать функцию ИНДЕКС() . Формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1) или просто ЛИНЕЙН(C23:C83;B23:B83) вернет параметр, отвечающий за наклон линии, т.е. а . Формула =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) вернет параметр b .
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент а , можно также вычислить через коэффициент корреляции и стандартные отклонения выборок :
= КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению ковариации выборок Х и Y и дисперсии выборки Х:
И, наконец, запишем еще одну формулу для нахождения сдвига b . Воспользуемся тем фактом, что линия регрессии проходит через точку средних значений переменных Х и Y.
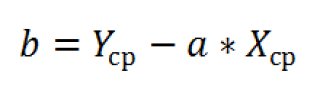
Вычислив средние значения и подставив в формулу ранее найденный наклон а , получим сдвиг b .
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры линии регрессии можно найти в матричной форме (см. файл примера лист Матричная форма ).
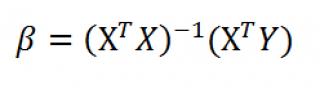
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг b ), β1 (наклон a ).
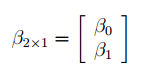
Матрица Х равна:
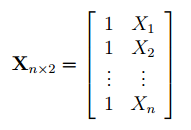
Матрица Х называется регрессионной матрицей или матрицей плана . Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица Х T – это транспонированная матрица Х . Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом Y обозначен столбец значений переменной Y.
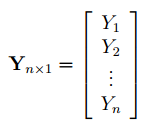
Чтобы перемножить матрицы используйте функцию МУМНОЖ() . Чтобы найти обратную матрицу используйте функцию МОБР() .
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
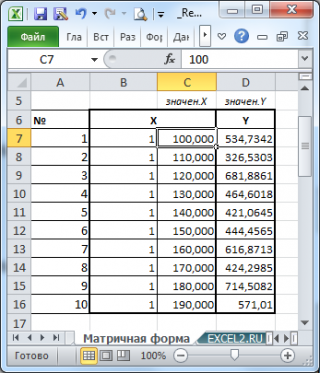
Слева от него достроим столбец с 1 для матрицы Х.
и введя ее как формулу массива в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае множественной регрессии .
Построение линии регрессии
Для отображения линии регрессии построим сначала диаграмму рассеяния , на которой отобразим все точки (см. начало статьи ).
Для построения прямой линии используйте вычисленные выше оценки параметров модели a и b (т.е. вычислите у по формуле y = a * x + b ) или функцию ТЕНДЕНЦИЯ() .
Формула = ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23) возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца В2 .
Примечание : Линию регрессии можно также построить с помощью функции ПРЕДСКАЗ() . Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции ТЕНДЕНЦИЯ() работает только в случае одного регрессора. Функция ТЕНДЕНЦИЯ() может быть использована и в случае множественной регрессии (в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
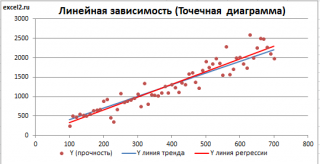
Как видно из диаграммы выше линия тренда и линия регрессии не обязательно совпадают: отклонения точек от линии тренда случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента Линия тренда. Для этого выделите диаграмму, в меню выберите вкладку Макет , в группе Анализ нажмите Линия тренда , затем Линейное приближение. В диалоговом окне установите галочку Показывать уравнение на диаграмме (подробнее см. в статье про МНК ).
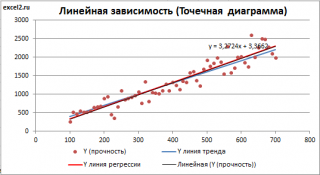
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами линией регрессии, а параметры уравнения a и b должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание: Для того, чтобы вычисленные параметры уравнения a и b совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был Точечная, а не График , т.к. тип диаграммы График не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; . Именно эти значения и берутся при расчете параметров линии тренда . Убедиться в этом можно если построить диаграмму График (см. файл примера ), а значения Хнач и Хшаг установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с a и b .
Коэффициент детерминации R 2
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения регрессионной модели ). Очевидно, что лучшей оценкой для yi будет среднее значение ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание : Далее будет использована терминология и обозначения дисперсионного анализа .
После построения регрессионной модели для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
Очевидно, что используя регрессионную модель мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
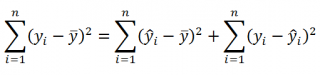
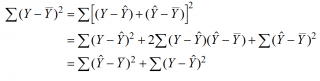
или в других, общепринятых в зарубежной литературе, обозначениях:
Total Sum of Squares = Regression Sum of Squares + Error Sum of Squares
Примечание : SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность дисперсии (вариации) и соответственно описывают разброс (изменчивость): Общую изменчивость (Total variation), Изменчивость объясненную моделью (Explained variation) и Необъясненную изменчивость (Unexplained variation).
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью / Общая изменчивость.
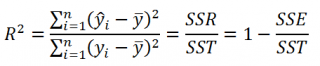
Этот показатель равен квадрату коэффициента корреляции и в MS EXCEL его можно вычислить с помощью функции КВПИРСОН() или ЛИНЕЙН() :
R 2 принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии ( Standard Error of a regression ) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение линейной регрессионной модели Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со средним значением μ и дисперсией σ 2 .
Оценив значение дисперсии σ 2 и вычислив из нее квадратный корень – получим Стандартную ошибку регрессии. Чем точки наблюдений на диаграмме рассеяния ближе находятся к прямой линии, тем меньше Стандартная ошибка.
Примечание : Вспомним , что при построении модели предполагается, что среднее значение ошибки ε равно 0, т.е. E[ε]=0.
Оценим дисперсию σ 2 . Помимо вычисления Стандартной ошибки регрессии эта оценка нам потребуется в дальнейшем еще и при построении доверительных интервалов для оценки параметров регрессии a и b .
Для оценки дисперсии ошибки ε используем остатки регрессии — разности между имеющимися значениями yi и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки дисперсии σ 2 используют следующую формулу:
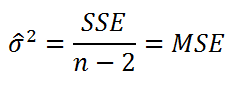
где SSE – сумма квадратов значений ошибок модели ε i =yi — ŷi ( Sum of Squared Errors ).
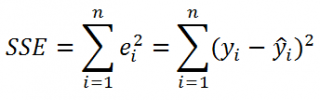
SSE часто обозначают и как SSres – сумма квадратов остатков ( Sum of Squared residuals ).
Оценка дисперсии s 2 также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов ошибок или MSRES (Mean Square of Residuals), т.е. среднее квадратов остатков . Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание : Напомним, что когда мы использовали МНК для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на линии регрессии.
Математическое ожидание случайной величины MSE равно дисперсии ошибки ε, т.е. σ 2 .
Чтобы понять почему SSE выбрана в качестве основы для оценки дисперсии ошибки ε, вспомним, что σ 2 является также дисперсией случайной величины Y (относительно среднего значения μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi = a * Хi + b (значение уравнения регрессии при Х= Хi), то логично использовать именно SSE в качестве основы для оценки дисперсии σ 2 . Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае простой линейной регрессии число степеней свободы равно n-2, т.к. при построении линии регрессии было оценено 2 параметра модели (на это было «потрачено» 2 степени свободы ).
Итак, как сказано было выше, квадратный корень из s 2 имеет специальное название Стандартная ошибка регрессии ( Standard Error of a regression ) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см. этот раздел ). Если ошибки предсказания ε имеют нормальное распределение , то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от линии регрессии . SEy имеет размерность переменной Y и откладывается по вертикали. Часто на диаграмме рассеяния строят границы предсказания соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
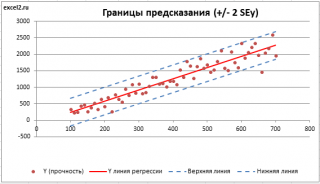
В MS EXCEL стандартную ошибку SEy можно вычислить непосредственно по формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
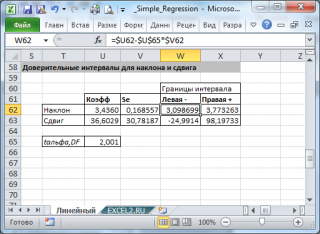
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе Оценка неизвестных параметров линейной модели мы получили точечные оценки наклона а и сдвига b . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ).
Стандартная ошибка коэффициента регрессии a вычисляется на основании стандартной ошибки регрессии по следующей формуле:
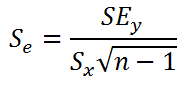
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
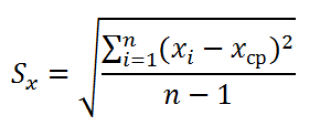
где Sey – стандартная ошибка регрессии, т.е. ошибка предсказания значения переменой Y ( см. выше ).
В MS EXCEL стандартную ошибку коэффициента регрессии Se можно вычислить впрямую по вышеуказанной формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции ЛИНЕЙН() :
Формулы приведены в файле примера на листе Линейный в разделе Регрессионная статистика .
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
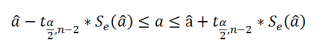
где — квантиль распределения Стьюдента с n-2 степенями свободы. Величина а с «крышкой» является другим обозначением наклона а .
Например для уровня значимости альфа=0,05, можно вычислить с помощью формулы =СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
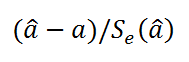
является t-распределением Стьюдента с n-2 степенью свободы (то же справедливо и для наклона b ).
Примечание : Подробнее о построении доверительных интервалов в MS EXCEL можно прочитать в этой статье Доверительные интервалы в MS EXCEL .
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии. Здесь мы считаем, что коэффициент регрессии a имеет распределение Стьюдента с n-2 степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Примечание : Подробнее о построении доверительных интервалов с использованием t-распределения см. статью про построение доверительных интервалов для среднего .
Стандартная ошибка сдвига b вычисляется по следующей формуле:
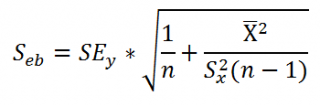
В MS EXCEL стандартную ошибку сдвига Seb можно вычислить с помощью функции ЛИНЕЙН() :
При построении двухстороннего доверительного интервала для сдвига его границы определяются аналогичным образом как для наклона : b +/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда коэффициент регрессии a равен 0.
Чтобы убедиться, что вычисленная нами оценка наклона прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
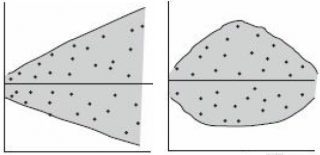
Ниже на рисунках показаны 2 ситуации, когда нулевую гипотезу Н 0 не удается отвергнуть.
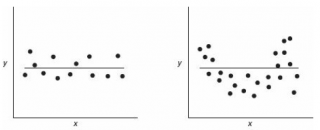
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом коэффициент линейной корреляции равен 0.
Ниже — 2 ситуации, когда нулевая гипотеза Н 0 отвергается.
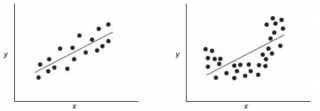
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
- Установить уровень значимости , пусть альфа=0,05;
- Рассчитать с помощью функции ЛИНЕЙН() стандартное отклонение Se для коэффициента регрессии (см. предыдущий раздел );
- Рассчитать число степеней свободы: DF=n-2 или по формуле = ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
- Вычислить значение тестовой статистики t 0 =a/S e , которая имеет распределение Стьюдента с числом степеней свободы DF=n-2;
- Сравнить значение тестовой статистики |t0| с пороговым значением t альфа ,n-2. Если значение тестовой статистики больше порогового значения, то нулевая гипотеза отвергается ( наклон не может быть объяснен лишь случайностью при заданном уровне альфа) либо
- вычислить p-значение и сравнить его с уровнем значимости .
В файле примера приведен пример проверки гипотезы:
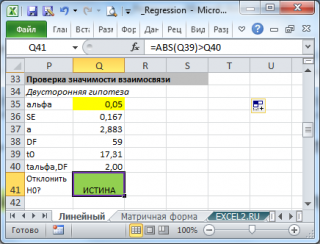
Изменяя наклон тренда k (ячейка В8 ) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание : Проверка значимости взаимосвязи эквивалентна проверке статистической значимости коэффициента корреляции . В файле примера показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью процедуры F-тест .
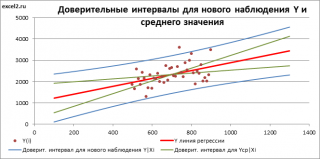
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры простой линейной регрессионной модели Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ= a * Хi + b
Ŷ также является точечной оценкой для среднего значения Yi при заданном Хi. Но, при построении доверительных интервалов используются различные стандартные ошибки .
Стандартная ошибка нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
- неопределенность связанную со случайностью оценок параметров модели a и b ;
- случайность ошибки модели ε.
Учет этих неопределенностей приводит к стандартной ошибке S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
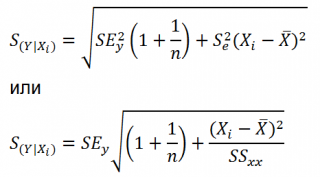
где SS xx – сумма квадратов отклонений от среднего значений переменной Х:
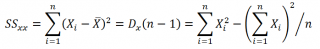
В MS EXCEL 2010 нет функции, которая бы рассчитывала эту стандартную ошибку , поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал или Интервал предсказания для нового наблюдения (Prediction Interval for a New Observation) построим по схеме показанной в разделе Проверка значимости взаимосвязи переменных (см. файл примера лист Интервалы ). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х ср ), то интервал будет постепенно расширяться при удалении от Х ср .
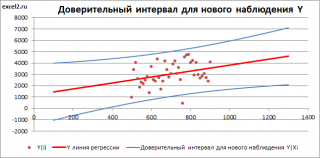
Границы доверительного интервала для нового наблюдения рассчитываются по формуле:
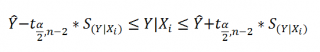
Аналогичным образом построим доверительный интервал для среднего значения Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае доверительный интервал будет уже, т.к. средние значения имеют меньшую изменчивость по сравнению с отдельными наблюдениями ( средние значения, в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
Стандартная ошибка S(Yср|Xi) вычисляется по практически аналогичным формулам как и стандартная ошибка для нового наблюдения:
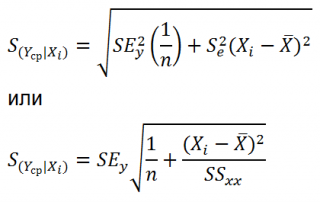
Как видно из формул, стандартная ошибка S(Yср|Xi) меньше стандартной ошибки S(Y|Xi) для индивидуального значения .
Границы доверительного интервала для среднего значения рассчитываются по формуле:
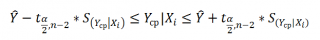
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел Предположения линейной регрессионной модели ).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках простой линейной модели n остатков имеют только n-2 связанных с ними степеней свободы . Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о нормальности распределения ошибок строят график проверки на нормальность (Normal probability Plot).
В файле примера на листе Адекватность построен график проверки на нормальность . В случае нормального распределения значения остатков должны быть близки к прямой линии.
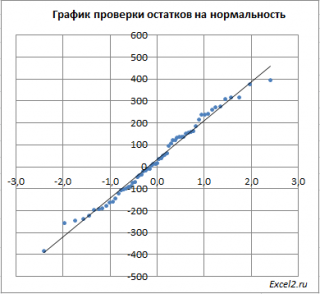
Так как значения переменной Y мы генерировали с помощью тренда , вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
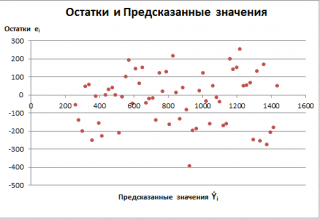
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор о нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе Стандартная ошибка регрессии оценкой стандартного отклонения ошибок является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
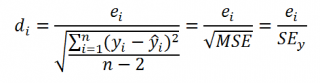
SEy можно вычислить с помощью функции ЛИНЕЙН() :
Иногда нормирование остатков производится на величину стандартного отклонения остатков (это мы увидим в статье об инструменте Регрессия , доступного в надстройке MS EXCEL Пакет анализа ), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
http://excel2.ru/articles/prostaya-lineynaya-regressiya-v-ms-excel
From Wikipedia, the free encyclopedia
In statistics and optimization, errors and residuals are two closely related and easily confused measures of the deviation of an observed value of an element of a statistical sample from its «true value» (not necessarily observable). The error of an observation is the deviation of the observed value from the true value of a quantity of interest (for example, a population mean). The residual is the difference between the observed value and the estimated value of the quantity of interest (for example, a sample mean). The distinction is most important in regression analysis, where the concepts are sometimes called the regression errors and regression residuals and where they lead to the concept of studentized residuals.
In econometrics, «errors» are also called disturbances.[1][2][3]
Introduction[edit]
Suppose there is a series of observations from a univariate distribution and we want to estimate the mean of that distribution (the so-called location model). In this case, the errors are the deviations of the observations from the population mean, while the residuals are the deviations of the observations from the sample mean.
A statistical error (or disturbance) is the amount by which an observation differs from its expected value, the latter being based on the whole population from which the statistical unit was chosen randomly. For example, if the mean height in a population of 21-year-old men is 1.75 meters, and one randomly chosen man is 1.80 meters tall, then the «error» is 0.05 meters; if the randomly chosen man is 1.70 meters tall, then the «error» is −0.05 meters. The expected value, being the mean of the entire population, is typically unobservable, and hence the statistical error cannot be observed either.
A residual (or fitting deviation), on the other hand, is an observable estimate of the unobservable statistical error. Consider the previous example with men’s heights and suppose we have a random sample of n people. The sample mean could serve as a good estimator of the population mean. Then we have:
- The difference between the height of each man in the sample and the unobservable population mean is a statistical error, whereas
- The difference between the height of each man in the sample and the observable sample mean is a residual.
Note that, because of the definition of the sample mean, the sum of the residuals within a random sample is necessarily zero, and thus the residuals are necessarily not independent. The statistical errors, on the other hand, are independent, and their sum within the random sample is almost surely not zero.
One can standardize statistical errors (especially of a normal distribution) in a z-score (or «standard score»), and standardize residuals in a t-statistic, or more generally studentized residuals.
In univariate distributions[edit]
If we assume a normally distributed population with mean μ and standard deviation σ, and choose individuals independently, then we have

and the sample mean

is a random variable distributed such that:

The statistical errors are then

with expected values of zero,[4] whereas the residuals are

The sum of squares of the statistical errors, divided by σ2, has a chi-squared distribution with n degrees of freedom:

However, this quantity is not observable as the population mean is unknown. The sum of squares of the residuals, on the other hand, is observable. The quotient of that sum by σ2 has a chi-squared distribution with only n − 1 degrees of freedom:

This difference between n and n − 1 degrees of freedom results in Bessel’s correction for the estimation of sample variance of a population with unknown mean and unknown variance. No correction is necessary if the population mean is known.
[edit]
It is remarkable that the sum of squares of the residuals and the sample mean can be shown to be independent of each other, using, e.g. Basu’s theorem. That fact, and the normal and chi-squared distributions given above form the basis of calculations involving the t-statistic:

where  represents the errors,
represents the errors,  represents the sample standard deviation for a sample of size n, and unknown σ, and the denominator term
represents the sample standard deviation for a sample of size n, and unknown σ, and the denominator term  accounts for the standard deviation of the errors according to:[5]
accounts for the standard deviation of the errors according to:[5]

The probability distributions of the numerator and the denominator separately depend on the value of the unobservable population standard deviation σ, but σ appears in both the numerator and the denominator and cancels. That is fortunate because it means that even though we do not know σ, we know the probability distribution of this quotient: it has a Student’s t-distribution with n − 1 degrees of freedom. We can therefore use this quotient to find a confidence interval for μ. This t-statistic can be interpreted as «the number of standard errors away from the regression line.»[6]
Regressions[edit]
In regression analysis, the distinction between errors and residuals is subtle and important, and leads to the concept of studentized residuals. Given an unobservable function that relates the independent variable to the dependent variable – say, a line – the deviations of the dependent variable observations from this function are the unobservable errors. If one runs a regression on some data, then the deviations of the dependent variable observations from the fitted function are the residuals. If the linear model is applicable, a scatterplot of residuals plotted against the independent variable should be random about zero with no trend to the residuals.[5] If the data exhibit a trend, the regression model is likely incorrect; for example, the true function may be a quadratic or higher order polynomial. If they are random, or have no trend, but «fan out» — they exhibit a phenomenon called heteroscedasticity. If all of the residuals are equal, or do not fan out, they exhibit homoscedasticity.
However, a terminological difference arises in the expression mean squared error (MSE). The mean squared error of a regression is a number computed from the sum of squares of the computed residuals, and not of the unobservable errors. If that sum of squares is divided by n, the number of observations, the result is the mean of the squared residuals. Since this is a biased estimate of the variance of the unobserved errors, the bias is removed by dividing the sum of the squared residuals by df = n − p − 1, instead of n, where df is the number of degrees of freedom (n minus the number of parameters (excluding the intercept) p being estimated — 1). This forms an unbiased estimate of the variance of the unobserved errors, and is called the mean squared error.[7]
Another method to calculate the mean square of error when analyzing the variance of linear regression using a technique like that used in ANOVA (they are the same because ANOVA is a type of regression), the sum of squares of the residuals (aka sum of squares of the error) is divided by the degrees of freedom (where the degrees of freedom equal n − p − 1, where p is the number of parameters estimated in the model (one for each variable in the regression equation, not including the intercept)). One can then also calculate the mean square of the model by dividing the sum of squares of the model minus the degrees of freedom, which is just the number of parameters. Then the F value can be calculated by dividing the mean square of the model by the mean square of the error, and we can then determine significance (which is why you want the mean squares to begin with.).[8]
However, because of the behavior of the process of regression, the distributions of residuals at different data points (of the input variable) may vary even if the errors themselves are identically distributed. Concretely, in a linear regression where the errors are identically distributed, the variability of residuals of inputs in the middle of the domain will be higher than the variability of residuals at the ends of the domain:[9] linear regressions fit endpoints better than the middle. This is also reflected in the influence functions of various data points on the regression coefficients: endpoints have more influence.
Thus to compare residuals at different inputs, one needs to adjust the residuals by the expected variability of residuals, which is called studentizing. This is particularly important in the case of detecting outliers, where the case in question is somehow different from the others in a dataset. For example, a large residual may be expected in the middle of the domain, but considered an outlier at the end of the domain.
Other uses of the word «error» in statistics[edit]
The use of the term «error» as discussed in the sections above is in the sense of a deviation of a value from a hypothetical unobserved value. At least two other uses also occur in statistics, both referring to observable prediction errors:
The mean squared error (MSE) refers to the amount by which the values predicted by an estimator differ from the quantities being estimated (typically outside the sample from which the model was estimated).
The root mean square error (RMSE) is the square-root of MSE.
The sum of squares of errors (SSE) is the MSE multiplied by the sample size.
Sum of squares of residuals (SSR) is the sum of the squares of the deviations of the actual values from the predicted values, within the sample used for estimation. This is the basis for the least squares estimate, where the regression coefficients are chosen such that the SSR is minimal (i.e. its derivative is zero).
Likewise, the sum of absolute errors (SAE) is the sum of the absolute values of the residuals, which is minimized in the least absolute deviations approach to regression.
The mean error (ME) is the bias.
The mean residual (MR) is always zero for least-squares estimators.
See also[edit]
- Absolute deviation
- Consensus forecasts
- Error detection and correction
- Explained sum of squares
- Innovation (signal processing)
- Lack-of-fit sum of squares
- Margin of error
- Mean absolute error
- Observational error
- Propagation of error
- Probable error
- Random and systematic errors
- Reduced chi-squared statistic
- Regression dilution
- Root mean square deviation
- Sampling error
- Standard error
- Studentized residual
- Type I and type II errors
References[edit]
- ^ Kennedy, P. (2008). A Guide to Econometrics. Wiley. p. 576. ISBN 978-1-4051-8257-7. Retrieved 2022-05-13.
- ^ Wooldridge, J.M. (2019). Introductory Econometrics: A Modern Approach. Cengage Learning. p. 57. ISBN 978-1-337-67133-0. Retrieved 2022-05-13.
- ^ Das, P. (2019). Econometrics in Theory and Practice: Analysis of Cross Section, Time Series and Panel Data with Stata 15.1. Springer Singapore. p. 7. ISBN 978-981-329-019-8. Retrieved 2022-05-13.
- ^ Wetherill, G. Barrie. (1981). Intermediate statistical methods. London: Chapman and Hall. ISBN 0-412-16440-X. OCLC 7779780.
- ^ a b A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Bruce, Peter C., 1953- (2017-05-10). Practical statistics for data scientists : 50 essential concepts. Bruce, Andrew, 1958- (First ed.). Sebastopol, CA. ISBN 978-1-4919-5293-1. OCLC 987251007.
{{cite book}}: CS1 maint: multiple names: authors list (link) - ^ Steel, Robert G. D.; Torrie, James H. (1960). Principles and Procedures of Statistics, with Special Reference to Biological Sciences. McGraw-Hill. p. 288.
- ^ Zelterman, Daniel (2010). Applied linear models with SAS ([Online-Ausg.]. ed.). Cambridge: Cambridge University Press. ISBN 9780521761598.
- ^ «7.3: Types of Outliers in Linear Regression». Statistics LibreTexts. 2013-11-21. Retrieved 2019-11-22.
- Cook, R. Dennis; Weisberg, Sanford (1982). Residuals and Influence in Regression (Repr. ed.). New York: Chapman and Hall. ISBN 041224280X. Retrieved 23 February 2013.
- Cox, David R.; Snell, E. Joyce (1968). «A general definition of residuals». Journal of the Royal Statistical Society, Series B. 30 (2): 248–275. JSTOR 2984505.
- Weisberg, Sanford (1985). Applied Linear Regression (2nd ed.). New York: Wiley. ISBN 9780471879572. Retrieved 23 February 2013.
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
External links[edit]
 Media related to Errors and residuals at Wikimedia Commons
Media related to Errors and residuals at Wikimedia Commons
Все курсы > Оптимизация > Занятие 4 (часть 1)
Прежде чем обратиться к теме множественной линейной регрессии, давайте вспомним, что было сделано до сих пор. Возможно, будет полезно посмотреть эти уроки, чтобы освежить знания.
- В рамках вводного курса мы узнали про моделирование взаимосвязи переменных и минимизацию ошибки при обучении алгоритма, а также научились строить несложные модели линейной регрессии с помощью библиотеки sklearn.
- При изучении объектно-ориентированного программирования мы создали класс простой линейной регрессии. Сегодня эти знания пригодятся при создании классов более сложных моделей.
- Также рекомендую вспомнить умножение векторов и матриц.
- Кроме того, в рамках текущего курса по оптимизации мы познакомились с понятием производной и методом градиентного спуска, а также построили модель простой линейной регрессии (использовав метод наименьших квадратов и градиент).
- Наконец, на прошлом занятии мы вновь поговорили про взаимосвязь переменных.
В рамках сегодняшнего занятия мы с нуля построим несколько алгоритмов множественной линейной регрессии.
Регрессионный анализ
Прежде чем обратиться к практике, обсудим некоторые теоретические вопросы регрессионного анализа.
Генеральная совокупность и выборка
Как мы уже знаем, множество всех имеющихся наблюдений принято считать генеральной совокупностью (population). И эти наблюдения, если в них есть взаимосвязи, можно теоретически аппроксимировать, например, линией регрессии. При этом важно понимать, что это некоторая идеальная модель, которую мы никогда не сможем построить.
Единственное, что мы можем сделать, взять выборку (sample) и на ней построить нашу модель, предполагая, что если выборка достаточно велика, она сможет достоверно описать генсовокупность.

Отклонение прогнозного значения от фактического для «идеальной» линии принято называть ошибкой (error или true error).
$$ varepsilon = y-hat{y} $$
Отклонение прогноза от факта для выборочной модели (которую мы и строим) называют остатками (residuals или residual error).
$$ varepsilon = y-f(x) $$
В этом смысле среднеквадратическую ошибку (mean squared error, MSE) корректнее называть средними квадратичными остатками (mean squared residuals).
На практике ошибку и остатки нередко используют как взаимозаменяемые термины.
Уравнение множественной линейной регрессии
Посмотрим на уравнение множественной линейной регрессии.
$$ y = theta_0 + theta_1x_1 + theta_2x_2 + … + theta_jx_j + varepsilon $$
В отличие от простой линейной регрессии в данном случае у нас несколько признаков x (независимых переменных) и несколько коэффициентов $ theta $ («тета»).
Интерпретация результатов модели
Коэффициент $ theta_0 $ задает некоторый базовый уровень (baseline) при условии, что остальные коэффициенты равны нулю и зачастую не имеет смысла с точки зрения интерпретации модели (нужен лишь для того, что поднять линию на нужный уровень).
Параметры $ theta_1, theta_2, …, theta_n $ показывают изменение зависимой переменной при условии «неподвижности» остальных коэффициентов. Например, каждая дополнительная комната может увеличивать цену дома в 1.3 раза.
Переменная $ varepsilon $ (ошибка) представляет собой отклонение фактических данных от прогнозных. В этой переменной могут быть заложены две составляющие. Во-первых, она может включать вариативность целевой переменной, описанную другими (не включенными в нашу модель) признаками. Во-вторых, «улавливать» случайный шум, случайные колебания.
Категориальные признаки
Модель линейной регрессии может включать категориальные признаки. Продолжая пример с квартирой, предположим, что мы строим модель, в которой цена зависит от того, находится ли квартира в центре города или в спальном районе.
Перед этим переменную необходимо закодировать, создав, например, через Label Encoder признак «центр», который примет значение 1, если квартира в центре, и 0, если она находится в спальном районе.
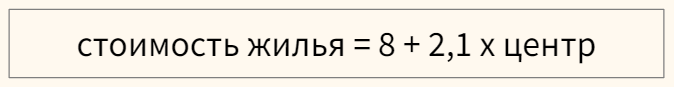
В модели, представленной выше, если квартира находится в центре (переменная «центр» равна единице), ее стоимость составит 10,1 миллиона рублей, если на окраине (переменная «центр» равна нулю) — лишь восемь.
Для категориального признака с множеством классов можно использовать one-hot encoding, если между классами признака отсутствует иерархия,
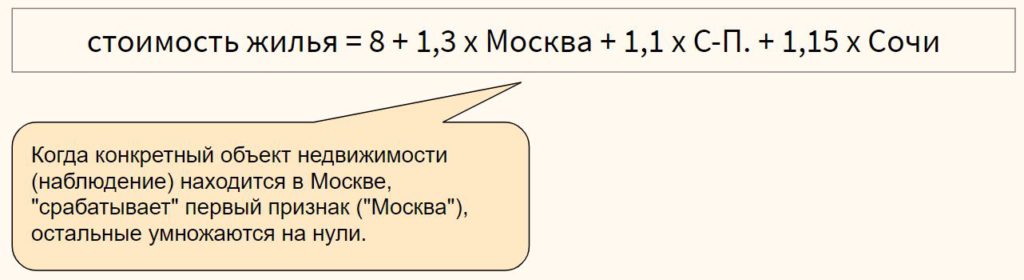
или, например, ordinal encoding в случае наличия иерархии классов в признаке

Выбросы в линейной регрессии
Как и коэффициент корреляции Пирсона, модель линейной регрессии чувствительна к выбросам (outliers), то есть наблюдениям, серьезно выпадающим из общей совокупности. Сравните рисунки ниже.

При наличии выброса (слева), линия регрессии имеет наклон и может использоваться для построения прогноза. Удалив это наблюдение (справа), линия регрессии становится горизонтальной и построение прогноза теряет смысл.
При этом различают два типа выбросов:
- горизонтальные выбросы или влиятельные точки (leverage points) — они сильно отклоняются от среднего по оси x; и
- вертикальные выбросы или просто выбросы (influential points) — отклоняются от среднего по оси y
Ключевое отличие заключается в том, что вертикальные выбросы влияют на наклон модели (изменяют ее коэффициенты), а горизонтальные — нет.
Сравним два графика.

На левом графике черная точка (leverage point) сильно отличается от остальных наблюдений, но наклон прямой линии регрессии с ее появлением не изменился. На правом графике, напротив, появление выброса (influential point) существенно изменяет наклон прямой.
На практике нас конечно больше интересуют influential points, потому что именно они существенно влияют на качество модели.
Если в простой линейной регрессии мы можем оценить leverage и influence наблюдения графически⧉, в многомерной модели это сделать сложнее. Можно использовать график остатков (об этом ниже) или применить один из уже известных нам методов выявления выбросов.
Про выявление leverage и infuential points можно почитать здесь⧉.
Допущения модели регрессии
Применение алгоритма линейной регрессии предполагает несколько допущений (assumptions) или условий, при выполнении которых мы можем говорить о качественно построенной модели.
1. Правильный выбор модели
Вначале важно убедиться, что данные можно аппроксимировать с помощью линейной модели (correct model specification).
Оценить распределение данных можно через график остатков (residuals plot), где по оси x отложен прогноз модели, а на оси y — сами остатки.

В отличие от простой линейной регрессии мы не используем точечную диаграмму X vs. y, потому что хотим оценить зависимость целевой переменной от всех признаков сразу.
Остатки модели относительно ее прогнозных значений должны быть распределены случайным образом без систематической составляющей (residuals do not follow a pattern).
- Если вы попробовали применить линейную модель с коэффициентами первой степени ($x_n^1$) и выявили некоторый паттерн в данных, можно попробовать полиномиальную или какую-либо еще функцию (об этом ниже).
- Кроме того, количественные признаки можно попробовать преобразовать таким образом, чтобы их можно было аппроксимировать прямой линией.
- Если ни то, ни другое не помогло, вероятно данные не стоит моделировать линейной регрессией.
Также замечу, что график остатков показывает выбросы в данных.

2. Нормальность распределения остатков
Среднее значение остатков должно быть равно нулю. Если это не так, и среднее значение меньше нуля (скажем –5), то это значит, что модель регулярно недооценивает (underestimates) фактические значения. В противном случае, если среднее больше нуля, переоценивает (overestimated).

Кроме того, предполагается, что остатки следуют нормальному распределению.
$$ varepsilon sim N(0, sigma) $$
Проверить нормальность остатков можно визуально с помощью гистограммы или рассмотренных ранее критериев нормальности распределения.
Если остатки не распределены нормально, мы не сможем провести статистические тесты на значимость коэффициентов или построить доверительные интервалы. Иначе говоря, мы не сможем сделать статистически значимый вывод о надежности нашей модели.
Причинами могут быть (1) выбросы в данных или (2) неверный выбор модели. Решением может быть, соответственно, исследование выбросов, выбор новой модели и преобразование как признаков, так и целевой переменной.
3. Гомоскедастичность остатков
Гомоскедастичность (homoscedasticity) или одинаковая изменчивость остатков предполагают, что дисперсия остатков не изменяется для различных наблюдений. Противоположное и нежелательное явление называется гетероскедастичностью (heteroscedasticity) или разной изменчивостью.

Гетероскедастичность остатков показывает, что модель ошибается сильнее при более высоких или более низких значениях признаков. Как следствие, если для разных прогнозов у нас разная погрешность, модель нельзя назвать надежной (robust).
Как правило, гетероскедастичность бывает изначально заложена в данные. Ее можно попробовать исправить через преобразование целевой переменной (например, логарифмирование)
4. Отсутствие мультиколлинеарности
Еще одним важным допущением является отсутствие мультиколлинеарности. Мультиколлинеарность (multicollinearity) — это корреляция между зависимыми переменными. Например, если мы предсказываем стоимость жилья по квадратным метрам и количеству комнат, то метры и комнаты логичным образом также будут коррелировать между собой.
Почему плохо, если такая корреляция существует? Базовое предположение линейной регрессии — каждый коэффициент $theta$ оказывает влияние на конечный результат при условии, что остальные коэффициенты постоянны. При мультиколлинеарности на целевую переменную оказывают эффект сразу несколько признаков, и мы не можем с точностью интерпретировать каждый из них.
Также говорят о том, что нужно стремиться к экономной (parsimonious) модели то есть такой модели, которая при наименьшем количестве признаков в наибольшей степени объясняет поведение целевой переменной.
Variance inflation factor
Расчет коэффициента
Variance inflation factor (VIF) или коэффициент увеличения дисперсии позволяет выявить корреляцию между признаками модели.
Принцип расчета VIF заключается в том, чтобы поочередно делать каждый из признаков целевой переменной и строить модель линейной регрессии на основе оставшихся независимых переменных. Например, если у нас есть три признака $x_1, x_2, x_3$, мы поочередно построим три модели линейной регрессии: $x_1 sim x_2 + x_3, x_2 sim x_1 + x_3$ и $x_3 sim x_1 + x_3$.
Обратите внимание на новый для нас формат записи целевой и зависимых переменных модели через символ $sim$.
Затем для каждой модели (то есть для каждого признака $x_1, x_2, x_3$) мы рассчитаем коэффициент детерминации $R^2$. Если он велик, значит данный признак можно объяснить с помощью других независимых переменных и имеется мультиколлинеарность. Если $R^2$ мал, то нельзя и мультиколлинеарность отсутствует.
Теперь рассчитаем VIF на основе $R^2$:
$$ VIF = frac{1}{1-R^2} $$
При таком способе расчета большой (близкий к единице) $R^2$ уменьшит знаменатель и существенно увеличит VIF, при небольшом коэффициенте детерминации коэффициент увеличения дисперсии наоборот уменьшится.
Замечу, что $1-R^2$ принято называть tolerance.
Другие способы выявления мультиколлинеарности
Для выявления корреляции между независимыми переменными можно использовать точечные диаграммы или корреляционные матрицы. При этом важно понимать, что в данном случае мы выявляем зависимость лишь между двумя признаками. Корреляцию множества признаков выявляет только коэффициент увеличения дисперсии.
Интерпретация VIF
VIF находится в диапазон от единицы до плюс бесконечности. Как правило, при интерпретации показателей variance inflation factor придерживаются следующих принципов:
- VIF = 1, между признаками отсутствует корреляция
- 1 < VIF $leq$ 5 — умеренная корреляция
- 5 < VIF $leq$ 10 — высокая корреляция
- Более 10 — очень высокая
После расчета VIF можно по одному удалять признаки с наибольшей корреляцией и смотреть как изменится этот показатель для оставшихся независимых переменных.
5. Отсутствие автокорреляции остатков
На занятии по временным рядам (time series), мы сказали, что автокорреляция (autocorrelation) — это корреляция между значениями одной и той же переменной в разные моменты времени.
Применительно к модели линейной регрессии автокорреляция целевой переменной (для простой линейной регрессии) и автокорреляция остатков, residuals autocorrelation (для модели множественной регрессии) означает, что результат или прогноз зависят не от признаков, а от самой этой целевой переменной. В такой ситуации признаки теряют свою значимость и применение модели регрессии становится нецелесообразным.
Причины автокорреляции остатков
Существует несколько возможных причин:
- Прогнозирование целевой переменной с высокой автокорреляцией (например, если мы моделируем цену акций с помощью других переменных, то можем ожидать высокую автокорреляцию остатков, поскольку цена акций как правило сильно зависит от времени)
- Удаление значимых признаков
- Другие причины
Автокорреляция первого порядка
Дадим формальное определение автокорреляции первого порядка (first order correlation), то есть автокорреляции с лагом 1.
$$ varepsilon_t = pvarepsilon_{t-1} + u_t $$
где $u_t$ — некоррелированная при различных t одинаково распределенная случайная величина (independent and identically distributed (i.i.d.) random variable), а $p$ — коэффициент автокорреляции, который находится в диапазоне $-1 < p < 1$. Чем он ближе к нулю, тем меньше зависимость остатка $varepsilon_t$ от остатка предыдущего периода $varepsilon_{t-1}$.
Такое уравнение также называется схемой Маркова первого порядка (Markov first-order scheme).
Обратите внимание, что для модели автокорреляции первого порядка коэффициент автокорреляции $p$ совпадает с коэффициентом авторегрессии AR(1) $varphi$.
$$ y_t = c + varphi cdot y_{t-1} $$
Разумеется, мы можем построить модель автокорреляции, например, третьего порядка.
$$ varepsilon_t = p_1varepsilon_{t-1} + p_2varepsilon_{t-2} + p_3varepsilon_{t-3} + u_t $$
Выявление автокорреляции остатков
Для выявления автокорреляции остатков можно использовать график последовательности и график остатков с лагом 1, график автокорреляционной функции или критерий Дарбина-Уотсона.
График последовательности и график остатков с лагом 1
На графике последовательности (sequence plot) по оси x откладывается время (или порядковый номер наблюдения), а по оси y — остатки модели. Кроме того, на графике остатков с лагом 1 (lag-1 plot) остатки (ось y) можно сравнить с этими же значениями, взятыми с лагом 1 (ось x).
Рассмотрим вариант положительной автокорреляции (positive autocorrelation) на графиках остатков типа (а) и (б).
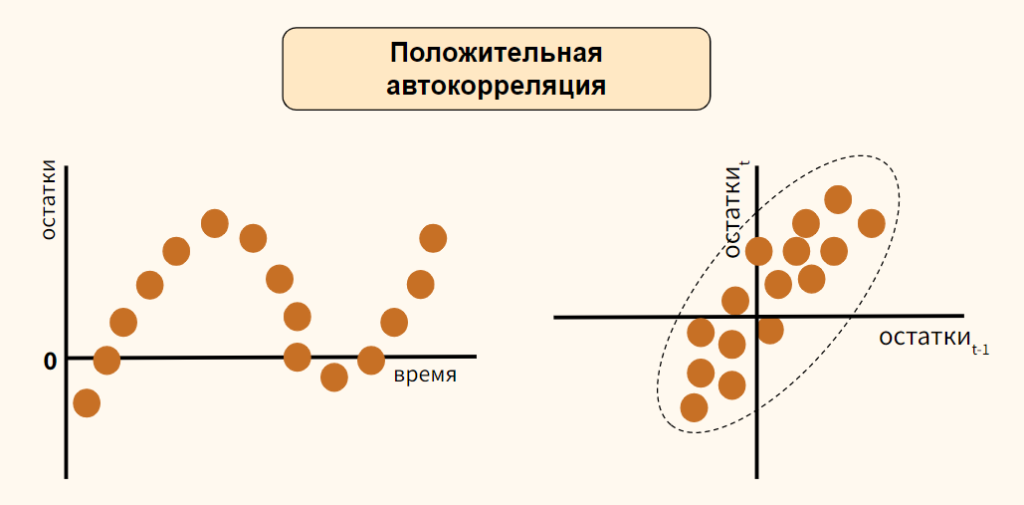
Как вы видите, при положительной автокорреляции в большинстве случаев, если одно наблюдение демонстрирует рост по отношению к предыдущему значению, то и последующее будет демонстрировать рост, и наоборот.
Теперь обратимся к отрицательной автокорреляции (negative autocorrelation).
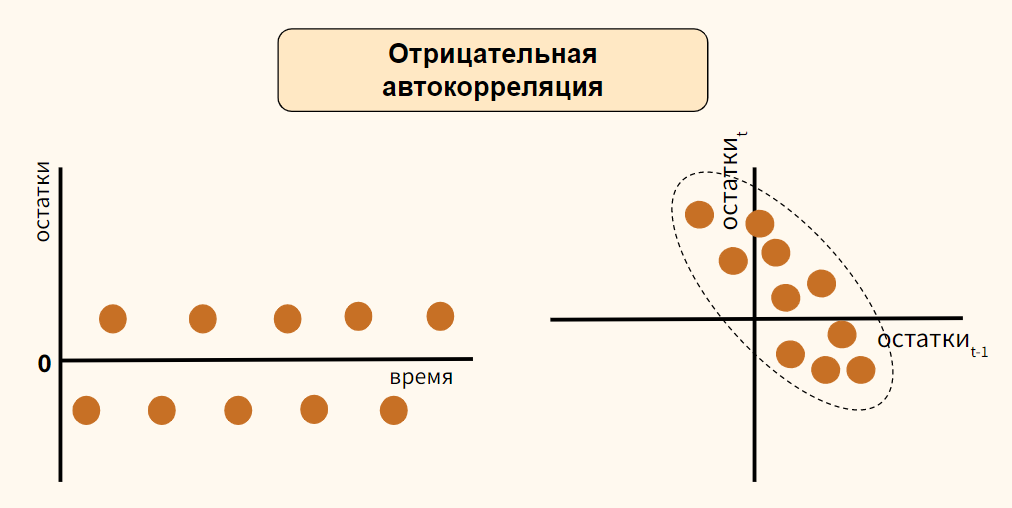
Здесь наоборот, если одно наблюдение демонстрирует рост показателя по отношению к предыдущему значению, то последующее наблюдение будет наоборот снижением. Опять же справедливо и обратное утверждение.
В случае отсутствия автокорреляции мы не должны увидеть на графиках какого-либо паттерна.

График автокорреляционной функции
Еще один способ выявить автокорреляцию — построить график автокорреляционной функции (autocorrelation function, ACF).

Напомню, такой график показывает автокорреляцию данных с этими же данными, взятыми с первым, вторым и последующими лагами.
Критерий Дарбина-Уотсона
Количественным выражением автокорреляции является критерий Дарбина-Уотсона (Durbin-Watson test). Этот критерий выявляет только автокорреляцию первого порядка.
- Нулевая гипотеза утверждает, что такая автокорреляция отсутствует ($p=0$),
- Альтернативная гипотеза соответственно утверждает, что присутствует
- Положительная ($p approx -1$) или
- Отрицательная ($p approx 1$) автокорреляция
Значение теста находится в диапазоне от 0 до 4.
- При показателе близком к двум можно говорить об отсутствии автокорреляции
- Приближение к четырем говорит о положительной автокорреляции
- К нулю, об отрицательной
Как избавиться от автокорреляции
Автокорреляцию можно преодолеть, добавив значимый признак в модель, выбрав иной тип модели (например, полиномиальную регрессию) или в целом перейдя к моделированию и прогнозированию временного ряда.
Рассмотрение этих методов находится за рамками сегодняшнего занятия. Перейдем к практике.
АКТУАЛЬНОСТЬ ТЕМЫ
Общие положения
Про регрессионный анализ вообще, и его применение в DataScience написано очень много. Есть множество учебников, монографий, справочников и статей по прикладной статистике, огромное количество информации в интернете, примеров расчетов. Можно найти множество кейсов, реализованных с использованием средств Python. Казалось бы — что тут еще можно добавить?
Однако, как всегда, есть нюансы:
1. Регрессионный анализ — это прежде всего процесс, набор действий исследователя по определенному алгоритму: «подготовка исходных данных — построение модели — анализ модели — прогнозирование с помощью модели». Это ключевая особенность. Не представляет особой сложности сформировать DataFrame исходных данных и построить модель, запустить процедуру из библиотеки statsmodels. Однако подготовка исходных данных и последующий анализ модели требуют гораздо больших затрат человеко-часов специалиста и строк программного кода, чем, собственно, построение модели. На этих этапах часто приходится возвращаться назад, корректировать модель или исходные данные. Этому, к сожалению, во многих источниках, не удаляется достойного внимания, а иногда — и совсем не уделяется внимания, что приводит к превратному представлению о регрессионном анализе.
2. Далеко не во всех источниках уделяется должное внимание интерпретации промежуточных и финальных результатов. Специалист должен уметь интерпретировать каждую цифру, полученную в ходе работы над моделью.
3. Далеко не все процедуры на этапах подготовки исходных данных или анализа модели в источниках разобраны подробно. Например, про проверку значимости коэффициента детерминации найти информацию не представляет труда, а вот про проверку адекватности модели, построение доверительных интервалов регрессии или про специфические процедуры (например, тест Уайта на гетероскедастичность) информации гораздо меньше.
4. Своеобразная сложность может возникнуть с проверкой статистических гипотез: для отечественной литературы по прикладной статистике больше характерно проверять гипотезы путем сравнения расчетного значения критерия с табличным, а в иностранных источниках чаще определяется расчетный уровень значимости и сравнивается с заданным (чаще всего 0.05 = 1-0.95). В разных источниках информации реализованы разные подходы. Инструменты python (прежде всего библиотеки scipy и statsmodels) также в основном оперируют с расчетным уровнем значимости.
5. Ну и, наконец, нельзя не отметить, что техническая документация библиотеки statsmodels составлена, на мой взгляд, далеко не идеально: информация излагается путано, изобилует повторами и пропусками, описание классов, функций и свойств выполнено фрагментарно и количество примеров расчетов — явно недостаточно.
Поэтому я решил написать ряд обзоров по регрессионному анализу средствами Python, в которых акцент будет сделан на практических примерах, алгоритме действий исследователя, интерпретации всех полученных результатов, конкретных методических рекомендациях. Буду стараться по возможности избегать теории (хотя совсем без нее получится) — все-таки предполагается, что специалист DataScience должен знать теорию вероятностей и математическую статистику, хотя бы в рамках курса высшей математики для технического или экономического вуза.
В данном статье остановимся на самои простом, классическом, стереотипном случае — простой линейной регрессии (simple linear regression), или как ее еще принято называть — парной линейной регрессионной модели (ПЛРМ) — в ситуации, когда исследователя не подстерегают никакие подводные камни и каверзы — исходные данные подчиняются нормальному закону, в выборке отсутствуют аномальные значения, отсутствует ложная корреляция. Более сложные случаи рассмотрим в дальнейшем.
Для построение регрессионной модели будем пользоваться библиотекой statsmodels.
В данной статье мы рассмотрим по возможности полный набор статистических процедур. Некоторые из них (например, дескриптивная статистика или дисперсионный анализ регрессионной модели) могут показаться избыточными. Все так, но эти процедуры улучшают наше представление о процессе и об исходных данных, поэтому в разбор я их включил, а каждый исследователь сам вправе для себя определить, потребуются ему эти процедуры или нет.
Краткий обзор источников
Источников информации по корреляционному и регрессионному анализу огромное количество, в них можно просто утонуть. Поэтому позволю себе просто порекомендовать ряд источников, на мой взгляд, наиболее полезных:
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. — М.: ФИЗМАТЛИТ, 2006. — 816 с.
-
Львовский Е.Н. Статистические методы построения эмпирических формул. — М.: Высшая школа, 1988. — 239 с.
-
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. — М.: Финансы и статистика, 1983. — 302 с.
-
Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ / пер с англ. — М.: Мир, 1982. — 488 с.
-
Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Книга 1 / пер.с англ. — М.: Финансы и статистика, 1986. — 366 с.
-
Айвазян С.А. и др. Прикладная статистика: Исследование зависимостей. — М.: Финансы и статистика, 1985. — 487 с.
-
Прикладная статистика. Основы эконометрики: В 2 т. 2-е изд., испр. — Т.2: Айвазян С.А. Основы эконометрики. — М.: ЮНИТИ-ДАНА, 2001. — 432 с.
-
Магнус Я.Р. и др. Эконометрика. Начальный курс — М.: Дело, 2004. — 576 с.
-
Носко В.П. Эконометрика. Книга 1. — М.: Издательский дом «Дело» РАНХиГС, 2011. — 672 с.
-
Брюс П. Практическая статистика для специалистов Data Science / пер. с англ. — СПб.: БХВ-Петербург, 2018. — 304 с.
-
Уатт Дж. и др. Машинное обучение: основы, алгоритмы и практика применения / пер. с англ. — СПб.: БХВ-Петербург, 2022. — 640 с.
Прежде всего следует упомянуть справочник Кобзаря А.И. [1] — это безусловно выдающийся труд. Ничего подобного даже близко не издавалось. Всем рекомендую иметь под рукой.
Есть очень хорошее практическое пособие [2] — для начинающих и практиков.>
Добротная работа немецких авторов [3]. Все разобрано подробно, обстоятельно, с примерами — очень хорошая книга. Примеры приведены из области экономики.
Еще одна добротная работа — [4], с примерами медико-биологического характера.
Работа [5] считается одним из наиболее полных изложений прикладного регрессионного анализа.
Более сложные работы — [6] (классика жанра), [7], [8], [9] — выдержаны на достаточно высоком математическом уровне, примеры из экономической области.
Свежие работы [10] (с примерами на языке R) и [11] (с примерами на python).
Cтатьи
Статей про регрессионный анализ в DataScience очень много, обращаю внимание на некоторые весьма полезные из них.
Серия статей «Python, корреляция и регрессия», охватывающая весь процесс регрессионного анализа:
-
первичная обработка данных, визуализация и корреляционный анализ;
-
регрессия;
-
теория матриц в регрессионном анализе, проверка адекватности, мультиколлинеарность;
-
прогнозирование с помощью регрессионных моделей.
Очень хороший обзор «Интерпретация summary из statsmodels для линейной регрессии». В этой статье даны очень полезные ссылки:
-
Statistical Models
-
Interpreting Linear Regression Through statsmodels .summary()
Статья «Регрессионные модели в Python».
Основные предпосылки (гипотезы) регрессионного анализа
Очень кратко — об этом написано тысячи страниц в учебниках — но все же вспомним некоторые основы теории.
Проверка исходных предпосылок является очень важным моментом при статистическом анализе регрессионной модели. Если мы рассматриваем классическую линейную регрессионную модель вида:
![]()
то основными предпосылками при использовании обычного метода наименьших квадратов (МНК) для оценки ее параметров являются:
-
Среднее значение (математическое ожидание) случайной составляющей равно нулю:
![]()
-
Дисперсия случайной составляющей является постоянной:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением гетероскедастичности.
-
Значения случайной составляющей статистически независимы (некоррелированы) между собой:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением автокорреляции.
-
Условие существования обратной матрицы
![]()
что эквивалентно одному из двух следующих условий:
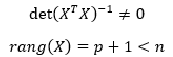
то есть число наблюдений должно превышать число параметров.
-
Значения случайной составляющей некоррелированы со значениями независимых переменных:
![]()
-
Случайная составляющая имеет нормальный закон распределения (с математическим ожиданием равным нулю — следует из условия 1):
![]()
Более подробно — см.: [3, с.90], [4, с.147], [5, с.122], [6, с.208], [7, с.49], [8, с.68], [9, с.88].
Кроме гетероскедастичности и автокорреляции возможно возникновение и других статистических аномалий — мультиколлинеарности, ложной корреляции и т.д.
Доказано, что оценки параметров, полученные с помощью МНК, обладают наилучшими свойствами (несмещенность, состоятельность, эффективность) при соблюдении ряда условий:
-
выполнение приведенных выше исходных предпосылок регрессионного анализа;
-
число наблюдений на одну независимую переменную должно быть не менее 5-6;
-
должны отсутствовать аномальные значения (выбросы).
Кроме обычного МНК существуют и другие его разновидности (взвешенный МНК, обобщенный МНК), которые применяются при наличии статистических аномалий. Кроме МНК применяются и другие методы оценки параметров моделей. В этом обзоре мы эти вопросы рассматривать не будем.
Алгоритм проведения регрессионного анализа
Алгоритм действий исследователя при построении регрессионной модели (полевые работы мы, по понятным причинам, не рассматриваем — считаем, что исходные данные уже получены):
-
Подготовительный этап — постановка целей и задач исследования.
-
Первичная обработка исходных данных — об этом много написано в учебниках и пособиях по DataScience, сюда могут относится:
-
выявление нерелевантных признаков (признаков, которые не несут полезной информации), нетипичных данных (выбросов), неинформативных признаков (имеющих большое количество одинаковых значений) и работа с ними (удаление/преобразование);
-
выделение категориальных признаков;
-
работа с пропущенными значениями;
-
преобразование признаков-дат в формат datetime и т.д.
-
Визуализация исходных данных — предварительный графический анализ.
-
Дескриптивная (описательная) статистика — расчет выборочных характеристик и предварительные выводы о свойствах исходных данных.
-
Исследование закона распределения исходных данных и, при необходимости, преобразование исходных данных к нормальному закону распределения.
-
Выявление статистически аномальных значений (выбросов), принятие решения об их исключении.
Этапы 4, 5 и 6 могут быть при необходимости объединены.
-
Корреляционный анализ — исследование корреляционных связей между исходными данными; это разведка перед проведением регрессионного анализа.
-
Построение регрессионной модели:
-
выбор моделей;
-
выбор методов;
-
оценка параметров модели.
-
Статистический анализ регрессионной модели:
-
оценка ошибок аппроксимации (error metrics);
-
анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков);
-
проверка адекватности модели;
-
проверка значимости коэффициента детерминации;
-
проверка значимости коэффициентов регрессии;
-
проверка мультиколлинеарности (для множественных регрессионных моделей; вообще мультиколлинеарные переменные выявляются еще на стадии корреляционного анализа);
-
проверка автокорреляции;
-
проверка гетероскедастичности.
Этапы 8 и 9 могут быть при необходимости повторяться несколько раз.
-
Сравнительный анализ нескольких регрессионных моделей, выбор наилучшей (при необходимости).
-
Прогнозирование с помощью регрессионной модели и оценка качества прогноза.
-
Выводы и рекомендации.
Само собой, этот алгоритм не есть истина в последней инстанции — в зависимости от особенностей исходных данных и вида модели могут возникать дополнительные задачи.
Применение пользовательских функций
Далее в обзоре мной будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub. Лично мне так удобнее работать, хотя каждый исследователь сам формирует себе инструменты по душе — особенно в части визуализации. Желающие могут пользоваться этими функциями, либо создать свои.
Итак, вот перечень данных функций:
-
graph_scatterplot_sns — функция позволяет построить точечную диаграмму средствами seaborn и сохранить график в виде png-файла;
-
graph_hist_boxplot_probplot_XY_sns — функция позволяет визуализировать исходные данные для простой линейной регрессии путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика (для переменных X и Y) средствами seaborn и сохранить график в виде png-файла; имеется возможность выбирать, какие графики строить (h — hist, b — boxplot, p — probplot);
-
descriptive_characteristics — функция возвращает в виде DataFrame набор статистических характеристики выборки, их ошибок и доверительных интервалов;
-
detecting_outliers_mad_test — функция выполняет проверку наличия аномальных значений (выбросов) по критерию наибольшего абсолютного отклонения (более подробно — см.[1, с.547]);
-
norm_distr_check — проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов;
-
corr_coef_check — функция выполняет расчет коэффициента линейной корреляции Пирсона, проверку его значимости и расчет доверительных интервалов; об этой функции я писал в своей статье.
-
graph_regression_plot_sns — — функция позволяет построить график регрессионной модели.
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включены в пользовательский модуль my_module__stat.py):
-
regression_error_metrics — расчет ошибок аппроксимации регрессионной модели;
-
ANOVA_table_regression_model — вывод таблицы дисперсионного анализа регрессионной модели;
-
regression_model_adequacy_check — проверка адекватности регрессионной модели по критерию Фишера;
-
determination_coef_check — проверка значимости коэффициента детерминации по критерию Фишера;
-
regression_coef_check — проверка значимости коэффициентов регрессии по критеирю Стьюдента;
-
Goldfeld_Quandt_test, Breush_Pagan_test, White_test — проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
-
regression_pair_predict — функция для прогнозирования с помощью парной регрессионной модели: рассчитывает прогнозируемое значение переменной Y по заданной модели, а также доверительные интервалы среднего и индивидуального значения для полученного прогнозируемого значения Y;
-
graph_regression_pair_predict_plot_sns — прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X.
ПОСТАНОВКА ЗАДАЧИ
В качестве примера рассмотрим практическую задачу из области экспертизы промышленной безопасности — калибровку ультразвукового прибора для определения прочности бетона.
Итак, суть задачи: при обследовании несущих конструкций зданий и сооружений эксперт определяет прочность бетона с использованием ультразвукового прибора «ПУЛЬСАР-2.1», для которого необходимо предварительно построить градуировочную зависимость. Заключается это в следующем — производятся замеры с фиксацией следующих показателей:
-
X — показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с)
-
Y — результаты замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03.
Предполагается, что между показателями X и Y имеется линейная регрессионная зависимость, которая позволит прогнозировать прочность бетона на основании измерений, проведенных прибором «ПУЛЬСАР-2.1».
Были выполнены замеры фактической прочности бетона конструкций для бетонов одного вида с одним типом крупного заполнителя, с единой технологией производства. Для построения были выбраны 14 участков (не менее 12), включая участки, в которых значение косвенного показателя максимальное, минимальное и имеет промежуточные значения.
Настройка заголовков отчета:
# Общий заголовок проекта
Task_Project = 'Калибровка ультразвукового прибора "ПУЛЬСАР-2.1" nдля определения прочности бетона'
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}n{AsOfTheDate}"
# Наименования переменных
Variable_Name_X = "Скорость УЗК (м/с)"
Variable_Name_Y = "Прочность бетона (МПа)"
# Константы
INCH = 25.4 # мм/дюйм
DecPlace = 5 # number of decimal places - число знаков после запятой
# Доверительная вероятность и уровень значимости:
p_level = 0.95
a_level = 1 - p_level Подключение модулей и библиотек:
# Стандартные модули и библиотеки
import os # загрузка модуля для работы с операционной системой
import sys
import platform
print('{:<35}{:^0}'.format("Текущая версия Python: ", platform.python_version()), 'n')
import math
from math import * # подключаем все содержимое модуля math, используем без псевдонимов
import numpy as np
#print ("Текущая версия модуля numpy: ", np.__version__)
print('{:<35}{:^0}'.format("Текущая версия модуля numpy: ", np.__version__))
from numpy import nan
import scipy as sci
print('{:<35}{:^0}'.format("Текущая версия модуля scipy: ", sci.__version__))
import scipy.stats as sps
import pandas as pd
print('{:<35}{:^0}'.format("Текущая версия модуля pandas: ", pd.__version__))
import matplotlib as mpl
print('{:<35}{:^0}'.format("Текущая версия модуля matplotlib: ", mpl.__version__))
import matplotlib.pyplot as plt
import seaborn as sns
print('{:<35}{:^0}'.format("Текущая версия модуля seaborn: ", sns.__version__))
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import statsmodels.stats.api as sms
from statsmodels.compat import lzip
print('{:<35}{:^0}'.format("Текущая версия модуля statsmodels: ", sm.__version__))
import statistics as stat # module 'statistics' has no attribute '__version__'
import sympy as sym
print('{:<35}{:^0}'.format("Текущая версия модуля sympy: ", sym.__version__))
# Настройки numpy
np.set_printoptions(precision = 4, floatmode='fixed')
# Настройки Pandas
pd.set_option('display.max_colwidth', None) # текст в ячейке отражался полностью вне зависимости от длины
pd.set_option('display.float_format', lambda x: '%.4f' % x)
# Настройки seaborn
sns.set_style("darkgrid")
sns.set_context(context='paper', font_scale=1, rc=None) # 'paper', 'notebook', 'talk', 'poster', None
# Настройки Mathplotlib
f_size = 8 # пользовательская переменная для задания базового размера шрифта
plt.rcParams['figure.titlesize'] = f_size + 12 # шрифт заголовка
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['axes.labelsize'] = f_size + 6 # шрифт подписей осей
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
# Пользовательские модули и библиотеки
Text1 = os.getcwd() # вывод пути к текущему каталогу
#print(f"Текущий каталог: {Text1}")
sys.path.insert(1, "D:REPOSITORYMyModulePython")
from my_module__stat import *ФОРМИРОВАНИЕ ИСХОДНЫХ ДАННЫХ
Показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с):
X = np.array([
4416, 4211, 4113, 4110, 4122,
4427, 4535, 4311, 4511, 4475,
3980, 4490, 4007, 4426
])Результаты замера прочности бетона (методом отрыва со скалыванием) прибором ИПС-МГ4.03:
Y = np.array([
34.2, 35.1, 31.5, 30.8, 30.0,
34.0, 35.4, 35.8, 38.0, 37.7,
30.0, 37.8, 31.0, 35.2
])Запишем данные в DataFrame:
calibrarion_df = pd.DataFrame({
'X': X,
'Y': Y})
display(calibrarion_df)
calibrarion_df.info()Сохраняем данные в csv-файл:
calibrarion_df.to_csv(
path_or_buf='data/calibrarion_df.csv',
mode='w+',
sep=';')Cоздаем копию исходной таблицы для работы:
dataset_df = calibrarion_df.copy()ВИЗУАЛИЗАЦИЯ ДАННЫХ
Границы значений переменных (при построении графиков):
(Xmin_graph, Xmax_graph) = (3800, 4800)
(Ymin_graph, Ymax_graph) = (25, 45)# Пользовательская функция
graph_scatterplot_sns(
X, Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
color='orange',
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
s=100,
file_name='graph/scatterplot_XY_sns.png')
Существует универсальный набор графиков — гистограмма, коробчатая диаграмма, вероятностный график — которые позволяют исследователю сделать предварительные выводы о свойствах исходных данных.
Так как объем выборки невелик (n=14), строить гистограммы распределения переменных X и Y не имеет смысла, поэтому ограничимся построением коробчатых диаграмм и вероятностных графиков:
# Пользовательская функция
graph_hist_boxplot_probplot_XY_sns(
data_X=X, data_Y=Y,
data_X_min=Xmin_graph, data_X_max=Xmax_graph,
data_Y_min=Ymin_graph, data_Y_max=Ymax_graph,
graph_inclusion='bp', # выбираем для построения виды графиков: b - boxplot, p - probplot)
data_X_label=Variable_Name_X,
data_Y_label=Variable_Name_Y,
title_figure=Task_Project,
file_name='graph/hist_boxplot_probplot_XY_sns.png') 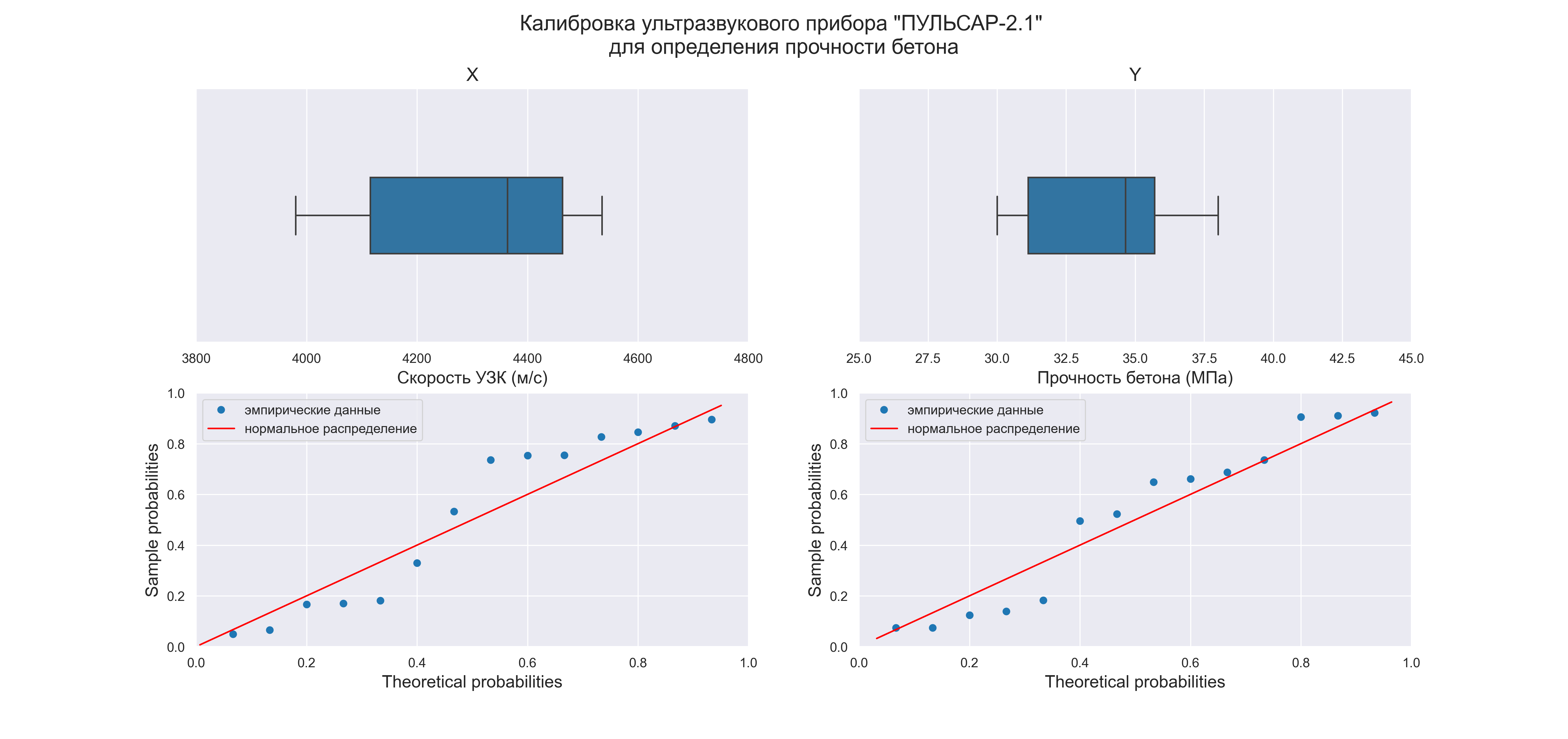
Для сравнения характера распределений переменных X и Y возможно также построить совмещенную коробчатую диаграмму по стандартизованным данным:
# стандартизуем исходные данные
standardize_df = lambda X: ((X - np.mean(X))/np.std(X))
dataset_df_standardize = dataset_df.copy()
dataset_df_standardize = dataset_df_standardize.apply(standardize_df)
display(dataset_df_standardize)
# построим график
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/2))
axes.set_title("Распределение стандартизованных переменных X и Y", fontsize = 16)
sns.boxplot(
data=dataset_df_standardize,
orient='h',
width=0.5,
ax=axes)
plt.show()
Графический анализ позволяет сделать следующие выводы:
-
Отсутствие выбросов на коробчатых диаграммах свидетельствует об однородности распределения переменных.
-
Смещение медианы вправо на коробчатых диаграммах свидетельствует о левосторонней асимметрии распределения.
ДЕСКРИПТИВНАЯ (ОПИСАТЕЛЬНАЯ СТАТИСТИКА)
Собственно говоря, данный этап требуется проводить далеко не всегда, однако с помощью статистических характеристик выборки мы тоже можем сделать полезные выводы.
Описательная статистика исходных данных средствами библиотеки Pandas — самый простой вариант:
dataset_df.describe()
Описательная статистика исходных данных средствами библиотеки statsmodels — более развернутый вариант, с большим количеством показателей:
from statsmodels.stats.descriptivestats import Description
result = Description(
dataset_df,
stats=["nobs", "missing", "mean", "std_err", "ci", "ci", "std", "iqr", "mad", "coef_var", "range", "max", "min", "skew", "kurtosis", "mode",
"median", "percentiles", "distinct", "top", "freq"],
alpha=a_level,
use_t=True)
display(result.summary())
Описательная статистика исходных данных с помощью пользовательской функции descriptive_characteristics:
# Пользовательская функция
descriptive_characteristics(X)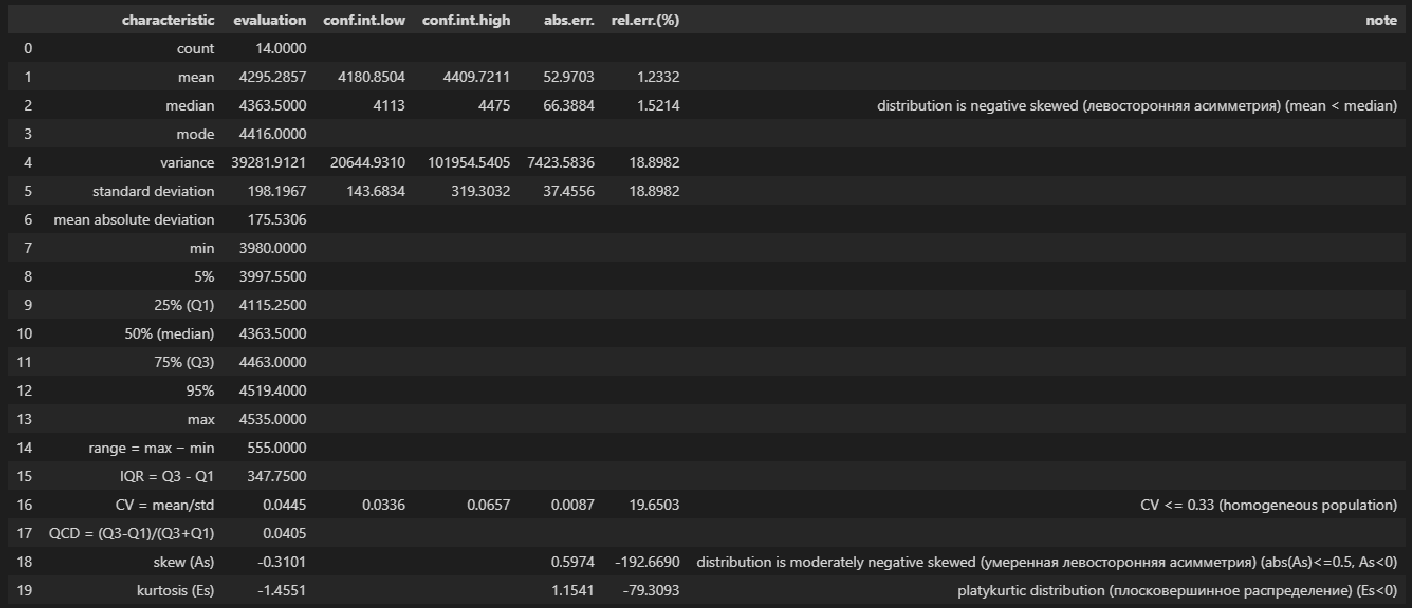
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0445 и доверительный интервал для него 0.0336 ≤ CV ≤ 0.0657 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.3101 свидетельствует об умеренной левосторонней асимметрии распределении (т.к. |As| ≤ 0.5, As < 0).
-
Значение показателя эксцесса kurtosis (Es) = -1.4551 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
# Пользовательская функция
descriptive_characteristics(Y)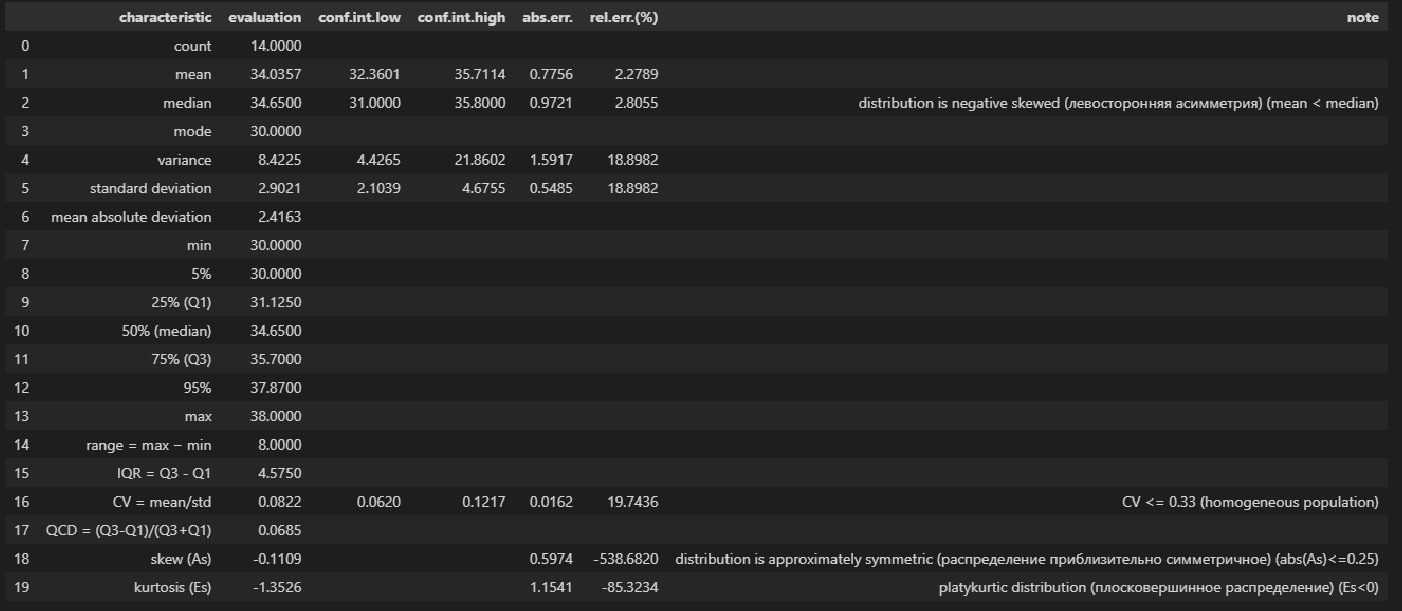
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0822 и доверительный интервал для него 0.06202 ≤ CV ≤ 0.1217 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.1109 свидетельствует о приблизительно симметричном распределении (т.к. |As| ≤ 0.25).
-
Значение показателя эксцесса kurtosis (Es) = -1.3526 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности распределения использована пользовательская функция norm_distr_check, которая объединяет в себе набор стандартных статистических тестов проверки нормальности. Все тесты относятся к стандартному инструментарию Pyton (библиотека scipy, модуль stats), за исключением теста Эппса-Палли (Epps-Pulley test); о том, как реализовать этот тест средствами Pyton я писал в своей статье https://habr.com/ru/post/685582/.
Примечание: для использования функции norm_distr_check в каталог с ipynb-файлом необходимо поместить папку table c файлом Tep_table.csv, который содержит табличные значения статистики критерия Эппса-Палли.
# пользовательская функция
norm_distr_check(X)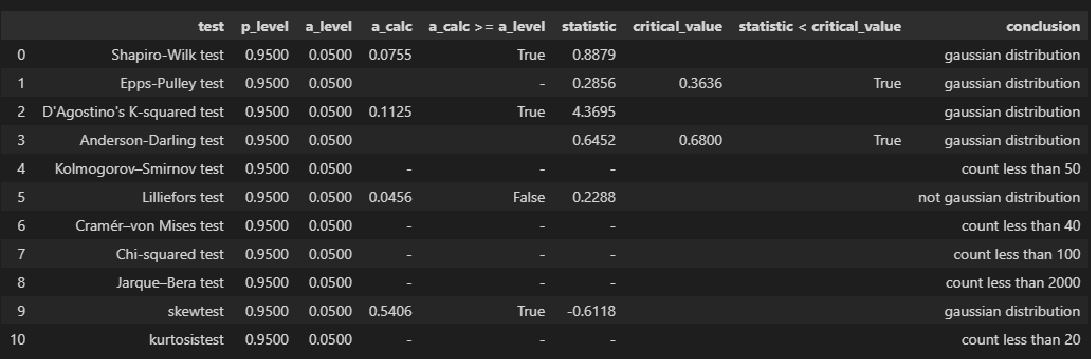
# Пользовательская функция
norm_distr_check (Y)
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения переменных X и Y.
ПРОВЕРКА АНОМАЛЬНЫХ ЗНАЧЕНИЙ (ВЫБРОСОВ)
Статистическую проверку аномальных значений (выбросов) не стоит путать с проверкой выбросов, которая проводится на этапе первичной обработки результатов наблюдений. Последняя проводится с целью отсеять явные ошибочные данные (например, в результате неправильно поставленной запятой величина показателя может увеличиться/уменьшиться на порядок); здесь же мы говорим о статистической проверке данных, которые уже прошли этап первичной обработки.
Имеется довольно много критериев для проверки аномальных значений (подробнее см.[1]); вообще данная процедура довольно неоднозначная:
-
критерии зависят от вида распределения;
-
мало данных о сравнительной мощности этих критериев;
-
даже в случае принятии гипотезы о нормальном распределении в выборке могут быть обнаружены аномальные значения и пр.
Кроме существует дилемма: если какие-то значения в выборке признаны выбросами — стоит или не стоит исследователю исключать их? Ведь каждое значение несет в себе информацию, причем иногда весьма ценную, а сильно отклоняющиеся от основного массива данные (которые не являются выбросами в смысле первичной обработки, но являются статистическим значимыми аномальными значениями) могут кардинально изменить статистический вывод.
В общем, о задаче выявления аномальных значений (выбросов) можно написать отдельно, а пока, в данном разборе, ограничимся проверкой аномальных значений по критерию наибольшего максимального отклонения (см.[1, с.547]) с помощью пользовательской функции detecting_outliers_mad_test. Данные функция возвращает DataFrame, которые включает список аномальных значений со следующими признаками:
-
value — проверяемое значение из выборки;
-
mad_calc и mad_table — расчетное и табличное значение статистики критерия;
-
outlier_conclusion — вывод (выброс или нет).
Обращаю внимание, что критерий наибольшего максимального отклонения можно использовать только для нормально распределенных данных.
# пользовательская функция
print("Проверка наличия выбросов переменной X:n")
result = detecting_outliers_mad_test(X)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
# пользовательская функция
print("Проверка наличия выбросов переменной Y:n")
result = detecting_outliers_mad_test(Y)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
Вывод: в случае обеих переменных X и Y список пуст, следовательно, аномальных значений (выбросов) не выявлено.
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционный анализ — это разведка перед построением регрессионной модели.
Выполним расчет коэффициента линейной корреляции Пирсона, проверку его значимости и построение доверительных интервалов с помощью пользовательской функции corr_coef_check (про эту функцию более подробно написано в моей статье https://habr.com/ru/post/683442/):
# пользовательская функция
display(corr_coef_check(X, Y, scale='Evans'))
Выводы:
-
Значение коэффициента корреляции coef_value = 0.8900 свидетельствует о весьма сильной корреляционной связи (по шкале Эванса).
-
Коэффициент корреляции значим по критерию Стьюдента: t_calc ≥ t_table, a_calc ≤ a_level.
-
Доверительный интервал для коэффициента корреляции: 0.6621 ≤ coef_value ≤ 0.9625.
РЕГРЕССИОННЫЙ АНАЛИЗ
Предварительная визуализация
python позволяет выполнить предварительную визуализацию, например, с помощью функции jointplot библиотеки seaborn:
fig = plt.figure(figsize=(297/INCH, 210/INCH))
axes = sns.jointplot(
x=X, y=Y,
kind='reg',
ci=95)
plt.show()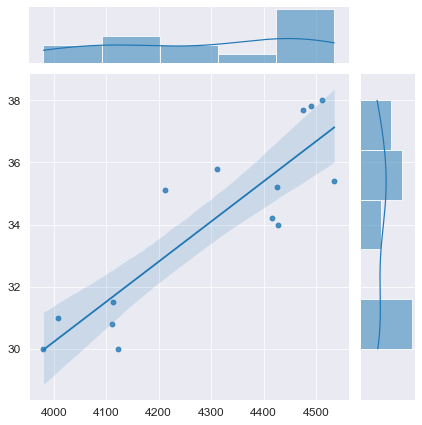
Построение модели
Выполним оценку параметров и анализ простой линейной регрессии (simple linear regression), используя библиотеку statsmodels (https://www.statsmodels.org/) и входящий в нее модуль линейной регрессии Linear Regression (https://www.statsmodels.org/stable/regression.html).
Данный модуль включает в себя классы, реализующие различные методы оценки параметров моделей линейной регрессии, в том числе:
-
класс OLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.OLS.html#statsmodels.regression.linear_model.OLS) — Ordinary Least Squares (обычный метод наименьших квадратов).
-
класс WLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.WLS.html#statsmodels.regression.linear_model.WLS) — Weighted Least Squares (метод взвешенных наименьших квадратов) (https://en.wikipedia.org/wiki/Weighted_least_squares), применяется, если имеет место гетероскедастичность данных (https://ru.wikipedia.org/wiki/Гетероскедастичность).
-
класс GLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLS.html#statsmodels.regression.linear_model.GLS) — Generalized Least Squares (обобщенный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Generalized_least_squares), применяется, если существует определенная степень корреляции между остатками в модели регрессии.
-
класс GLSAR (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLSAR.html#statsmodels.regression.linear_model.GLSAR) — Generalized Least Squares with AR covariance structure (обобщенный метод наименьших квадратов, ковариационная структура с автокорреляцией — экспериментальный метод)
-
класс RecurciveLS (https://www.statsmodels.org/stable/examples/notebooks/generated/recursive_ls.html) — Recursive least squares (рекурсивный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Recursive_least_squares_filter)
-
классы RollingOLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingOLS.html#statsmodels.regression.rolling.RollingOLS) и RollingWLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingWLS.html#statsmodels.regression.rolling.RollingWLS) — скользящая регрессия (https://www.statsmodels.org/stable/examples/notebooks/generated/rolling_ls.html, https://help.fsight.ru/ru/mergedProjects/lib/01_regression_models/rolling_regression.htm)
и т.д.
Так как исходные данные подчиняются нормальному закону распределения и аномальные значения (выбросы) отсутствуют, воспользуемся для оценки параметров обычным методом наименьших квадратов (класс OLS):
model_linear_ols = smf.ols(formula='Y ~ X', data=dataset_df)
result_linear_ols = model_linear_ols.fit()
print(result_linear_ols.summary())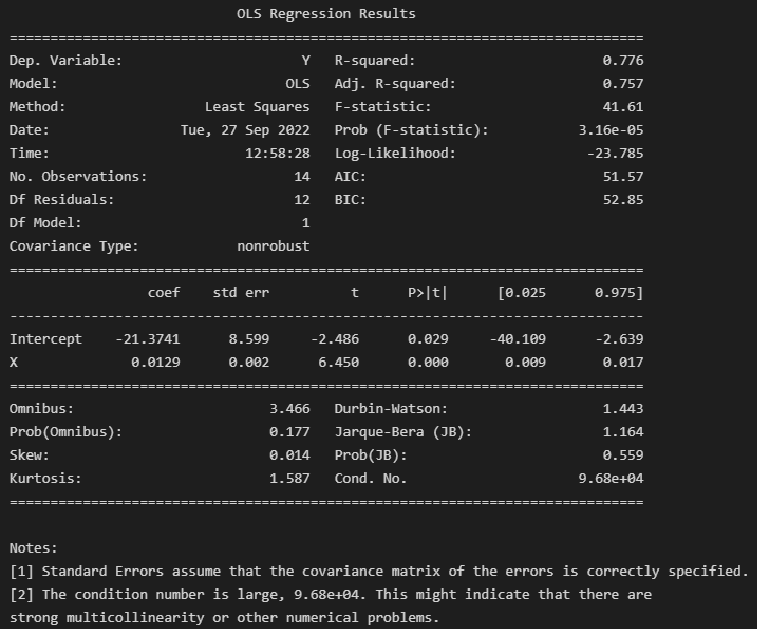
Альтернативная форма выдачи результатов:
print(result_linear_ols.summary2())
Результаты построения модели мы получаем как класс statsmodels.regression.linear_model.RegressionResults (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults).
Экспресс-выводы, которые мы можем сразу сделать из результатов построения модели:
-
Коэффициенты регрессии модели Y = b0 + b1∙X:
-
Intercept = b0 = -21.3741
-
b1 = 0.0129
-
-
Коэффициент детерминации R-squared = 0.776, его скорректированная оценка Adj. R-squared = 0.757 — это означает, что регрессионная модуль объясняет 75.75% вариации переменной Y.
-
Проверка значимости коэффициента детерминации:
-
расчетное значение статистики критерия Фишера: F-statistic = 41.61
-
расчетный уровень значимости Prob (F-statistic) = 3.16e-05
-
так как значение Prob (F-statistic) < 0.05, то нулевая гипотеза R-squared = 0 НЕ ПРИНИМАЕТСЯ, т.е. коэффициент детерминации ЗНАЧИМ
-
-
Проверка значимости коэффициентов регрессии:
-
расчетный уровень значимости P>|t| не превышает 0.05 — это означает, что оба коэффициента регрессии значимы
-
об этом же свидетельствует то, что доверительный интервал для обоих коэффициентов регрессии ([0.025; 0.975]) не включает в себя точку 0
Также в таблице результатов содержится прочая информация по коэффициентам регрессии: стандартная ошибка Std.Err. расчетное значение статистики критерия Стьюдента t для проверки гипотезы о значимости.
-
-
Анализ остатков модели:
-
Тест Omnibus — про этот тест подробно написано в https://en.wikipedia.org/wiki/Omnibus_test, https://medium.com/swlh/interpreting-linear-regression-through-statsmodels-summary-4796d359035a, http://work.thaslwanter.at/Stats/html/statsModels.html.
Расчетное значение статистики критерия Omnibus = 3.466 — по сути расчетное значение F-критерия (см. https://en.wikipedia.org/wiki/Omnibus_test).
Prob(Omnibus) = 0.177 — показывает вероятность нормального распределения остатков (значение 1 указывает на совершенно нормальное распределение).
Учитывая, что в дальнейшем мы проверим нормальность распределения остатков по совокупности различных тестов, в том числе с достаточно высокой мощностью, и все тесты позволят принять гипотезу о нормальном распределении — в данном случае к тесту Omnibus возникают вопросы. С этим тестом нужно разбираться отдельно.
-
Skew = 0.014 и Kurtosis = 1.587 — показатели асимметрии и эксцесса остатков свидетельствуют, что распределение остатков практически симметричное, островершинное.
-
проверка нормальности распределения остатков по критерию Харке-Бера: расчетное значение статистики критерия Jarque-Bera (JB) = 1.164 и расчетный уровень значимости Prob(JB) = 0.559. К данным результатам также возникают вопросы, особенно, если учесть, что критерий Харке-Бера является асимптотическим, расчетное значение имеет распределение хи-квадрат, поэтому данный критерий рекомендуют применять только для больших выборок (см. https://en.wikipedia.org/wiki/Jarque–Bera_test). Проверку нормальности распределения остатков модели лучше проводить с использованием набора стандартных статистических тестов python (см. далее).
-
-
Проверка автокорреляции по критерию Дарбина-Уотсона: Durbin-Watson = 1.443.
Мы не будем здесь разбирать данный критерий, так как явление автокорреляции больше характерно для данных, выражаемых в виде временных рядов. Однако, для грубой оценки считается, что при расчетном значении статистики криетрия Дарбина=Уотсона а интервале [1; 2] автокорреляция отсутствует (см.https://en.wikipedia.org/wiki/Durbin–Watson_statistic).
Более подробно про критерий Дарбина-Уотсона — см. [1, с.659].
Прочая информация, которую можно извлечь из результатов построения модели:
-
Covariance Type — тип ковариации, подробнее см. https://habr.com/ru/post/681218/, https://towardsdatascience.com/simple-explanation-of-statsmodel-linear-regression-model-summary-35961919868b#:~:text=Covariance type is typically nonrobust,with respect to each other.
-
Scale — масштабный коэффициент для ковариационной матрицы (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.scale.html#statsmodels.regression.linear_model.RegressionResults.scale), равен величине Mean squared error (MSE) (cреднеквадратической ошибке), об подробнее см. далее, в разделе про ошибки аппроксимации моделей.
-
Показатели сравнения качества различных моделей:
-
Log-Likelihood — логарифмическая функция правдоподобия, подробнее см. https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood, https://habr.com/ru/post/433804/
-
AIC — информационный критерий Акаике (Akaike information criterion), подробнее см. https://en.wikipedia.org/wiki/Akaike_information_criterion
-
BIC — информационный критерий Байеса (Bayesian information criterion), подробнее см. https://en.wikipedia.org/wiki/Bayesian_information_criterion
В данной статье мы эти показатели рассматривать не будем, так как задача выбора одной модели из нескольких перед нами не стоит.
-
-
Число обусловленности Cond. No = 96792 используется для проверки мультиколлинеарности (считается, что мультиколлинеарность есть, если значение Cond. No > 30) (см. http://work.thaslwanter.at/Stats/html/statsModels.html). В нашем случае парной регрессионной модели о мультиколлинеарности речь не идет.
Далее будем извлекать данные из стандартного набора выдачи результатов и анализировать их более подробно. Последующие этапы вовсе не обязательно проводить в полном объеме при решении задач, но здесь мы рассмотрим их подробно.
Параметры и уравнение регрессионной модели
Извлечем параметры полученной модели — как свойство params модели:
print('Параметры модели: n', result_linear_ols.params, type(result_linear_ols.params))
Имея параметры модели, можем формализовать уравнение модели Y = b0 + b1*X:
b0 = result_linear_ols.params['Intercept']
b1 = result_linear_ols.params['X']
Y_calc = lambda x: b0 + b1*xГрафик регрессионной модели
Для построения графиков регрессионных моделей можно воспользоваться стандартными возможностями библиотек statsmodels, seaborn, либо создать пользовательскую функцию — на усмотрение исследователя:
1. Построение графиков регрессионных моделей с использованием библиотеки statsmodels
С помощью функции statsmodels.graphics.plot_fit (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_fit.html#statsmodels.graphics.regressionplots.plot_fit) — отображается график Y and Fitted vs.X (фактические и расчетные значения Y с доверительным интервалом для каждого значения Y):
fig, ax = plt.subplots(figsize=(297/INCH, 210/INCH))
fig = sm.graphics.plot_fit(
result_linear_ols, 'X',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax)
ax.set_ylabel(Variable_Name_Y)
ax.set_xlabel(Variable_Name_X)
ax.set_title(Task_Project)
plt.show()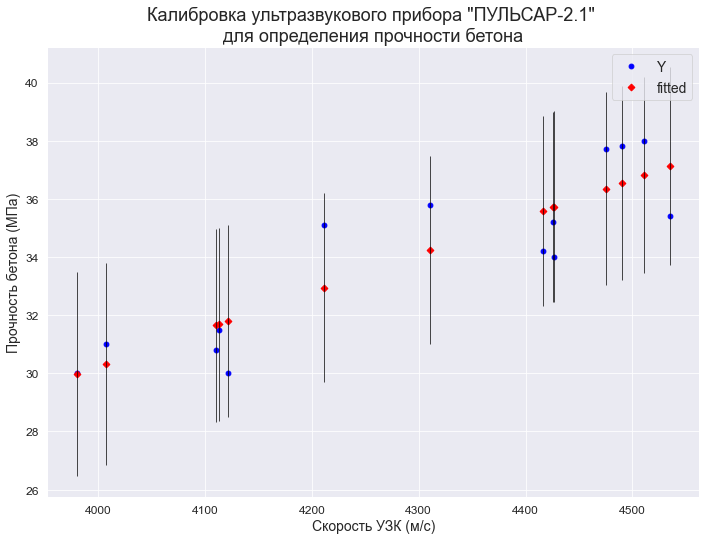
С помощью функции statsmodels.graphics.plot_regress_exog (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_regress_exog.html#statsmodels.graphics.regressionplots.plot_regress_exog) — отображается область 2х2, которая содержит:
-
предыдущий график Y and Fitted vs.X;
-
график остатков Residuals versus X;
-
график Partial regression plot — график частичной регрессии, пытается показать эффект добавления другой переменной в модель, которая уже имеет одну или несколько независимых переменных (более подробно см. https://en.wikipedia.org/wiki/Partial_regression_plot);
-
график CCPR Plot (Component-Component plus Residual Plot) — еще один способ оценить влияние одной независимой переменной на переменную отклика, принимая во внимание влияние других независимых переменных (более подробно — см. https://towardsdatascience.com/calculating-price-elasticity-of-demand-statistical-modeling-with-python-6adb2fa7824d, https://www.kirenz.com/post/2021-11-14-linear-regression-diagnostics-in-python/linear-regression-diagnostics-in-python/).
fig = plt.figure(figsize=(297/INCH, 210/INCH))
sm.graphics.plot_regress_exog(result_linear_ols, 'X', fig=fig)
plt.show()
2. Построение графиков регрессионных моделей с использованием библиотеки seaborn
Воспользуемся модулем regplot библиотеки seaborn (https://seaborn.pydata.org/generated/seaborn.regplot.html). Данный модуль позволяет визуализировать различные виды регрессии:
-
линейную
-
полиномиальную
-
логистическую
-
взвешенную локальную регрессию (LOWESS — Locally Weighted Scatterplot Smoothing) (см. http://www.machinelearning.ru/wiki/index.php?title=Алгоритм_LOWESS, https://www.statsmodels.org/stable/generated/statsmodels.nonparametric.smoothers_lowess.lowess.html)
Более подробно про модуль regplot можно прочитать в статье: https://pyprog.pro/sns/sns_8_regression_models.html.
Есть более совершенный модуль lmplot (https://seaborn.pydata.org/generated/seaborn.lmplot.html), который объединяет в себе regplot и FacetGrid, но мы его здесь рассматривать не будем.
# создание рисунка (Figure) и области рисования (Axes)
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 18)
# заголовок области рисования (Axes)
title_axes_1 = 'Линейная регрессионная модель'
ax1.set_title(title_axes_1, fontsize = 16)
# график регрессионной модели
order_mod = 1 # порядок модели
#label_legend_regr_model = 'фактические данные'
sns.regplot(
#data=dataset_df,
x=X, y=Y,
#x_estimator=np.mean,
order=order_mod,
logistic=False,
lowess=False,
robust=False,
logx=False,
ci=95,
scatter_kws={'s': 30, 'color': 'red'},
line_kws={'color': 'blue'},
#label=label_legend_regr_model,
ax=ax1)
ax1.set_ylabel(Variable_Name_Y)
ax1.legend()
# график остатков
title_axes_2 = 'График остатков'
ax2.set_title(title_axes_2, fontsize = 16)
sns.residplot(
#data=dataset_df,
x=X, y=Y,
order=order_mod,
lowess=False,
robust=False,
scatter_kws={'s': 30, 'color': 'darkorange'},
ax=ax2)
ax2.set_xlabel(Variable_Name_X)
plt.show()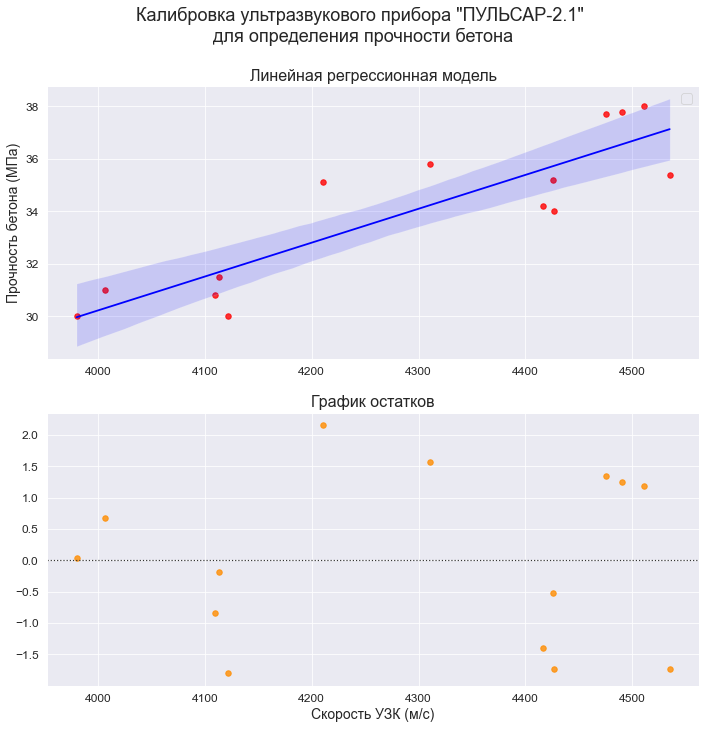
3. Построение графиков регрессионных моделей с помощью пользовательской функции
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=Y_calc,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=80,
file_name='graph/regression_plot_lin.png')
Статистический анализ регрессионной модели
1. Расчет ошибки аппроксимации (Error Metrics)
Ошибки аппроксимации (Error Metrics) позволяют получить общее представление о качестве модели, а также позволяют сравнивать между собой различные модели.
Создадим пользовательскую функцию, которая рассчитывает основные ошибки аппроксимации для заданной модели:
-
Mean squared error (MSE) или Mean squared deviation (MSD) — среднеквадратическая ошибка (https://en.wikipedia.org/wiki/Mean_squared_error):
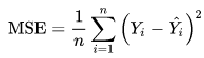
-
Root mean square error (RMSE) или Root mean square deviation (RMSD) — квадратный корень из MSE (https://en.wikipedia.org/wiki/Root-mean-square_deviation):
![]()
-
Mean absolute error (MAE) — средняя абсолютная ошибка (https://en.wikipedia.org/wiki/Mean_absolute_error):

-
Mean squared prediction error (MSPE) — среднеквадратическая ошибка прогноза (среднеквадратическая ошибка в процентах) (https://en.wikipedia.org/wiki/Mean_squared_prediction_error):
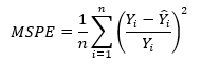
-
Mean absolute percentage error (MAPE) — средняя абсолютная ошибка в процентах (https://en.wikipedia.org/wiki/Mean_absolute_percentage_error):
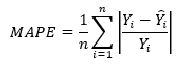
Про выбор метрики см. также https://machinelearningmastery.ru/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-2-regression-metrics-d4a1a9ba3d74/.
# Пользовательская функция
def regression_error_metrics(model, model_name=''):
model_fit = model.fit()
Ycalc = model_fit.predict()
n_fit = model_fit.nobs
Y = model.endog
MSE = (1/n_fit) * np.sum((Y-Ycalc)**2)
RMSE = sqrt(MSE)
MAE = (1/n_fit) * np.sum(abs(Y-Ycalc))
MSPE = (1/n_fit) * np.sum(((Y-Ycalc)/Y)**2)
MAPE = (1/n_fit) * np.sum(abs((Y-Ycalc)/Y))
model_error_metrics = {
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': MSPE,
'MAPE': MAPE}
result = pd.DataFrame({
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': "{:.3%}".format(MSPE),
'MAPE': "{:.3%}".format(MAPE)},
index=[model_name])
return model_error_metrics, result
(model_error_metrics, result) = regression_error_metrics(model_linear_ols, model_name='linear_ols')
display(result)
В литературе по прикладной статистике нет единого мнения о допустимом размере относительных ошибок аппроксимации: в одних источниках допустимой считается ошибка 5-7%, в других она может быть увеличена до 8-10%, и даже до 15%.
Вывод: модель хорошо аппроксимирует фактические данные (относительная ошибка аппроксимации MAPE = 3.405% < 10%).
2. Дисперсионный анализ регрессионной модели (ДАРМ)
ДАРМ не входит в стандартную форму выдачи результатов Regression Results, однако я решил написать здесь о нем по двум причинам:
-
Именно анализ дисперсии регрессионной модели, разложение этой дисперсии на составляющие дает фундаментальное представление о сути регрессии, а термины, используемые при ДАРМ, применяются на последующих этапах анализа.
-
С терминами ДАРМ в литературе по прикладной статистике имеется некоторая путаница, в разных источниках они могут именоваться по-разному (см., например, [8, с.52]), поэтому, чтобы двигаться дальше, необходимо определиться с понятиями.
При ДАРМ общую вариацию результативного признака (Y) принято разделять на две составляющие — вариация, обусловленная регрессией и вариация, обусловленная отклонениями от регрессии (остаток), при этом в разных источниках эти термины могут именоваться и обозначаться по-разному, например:
-
Вариация, обусловленная регрессией — может называться Explained sum of squares (ESS), Sum of Squared Regression (SSR) (https://en.wikipedia.org/wiki/Explained_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684), Sum of squared deviations (SSD).
-
Вариация, обусловленная отклонениями от регрессии (остаток) — может называться Residual sum of squares (RSS), Sum of squared residuals (SSR), Squared estimate of errors, Sum of Squared Error (SSE) (https://en.wikipedia.org/wiki/Residual_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684); в отчественной практике также применяется термин остаточная дисперсия.
-
Общая (полная) вариация — может называться Total sum of squares (TSS), Sum of Squared Total (SST) (https://en.wikipedia.org/wiki/Partition_of_sums_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684).
Как видим, путаница знатная:
-
в разных источниках под SSR могут подразумеваться различные показатели;
-
легко перепутать показатели ESS и SSE;
-
в библиотеке statsmodel также есть смешение терминов: для показателя Explained sum of squares используется свойство ess, а для показателя Sum of squared (whitened) residuals — свойство ssr.
Мы будем пользоваться системой обозначений, принятой в большинстве источников — SSR (Sum of Squared Regression), SSE (Sum of Squared Error), SST (Sum of Squared Total). Стандартная таблица ДАРМ в этом случае имеет вид:

Примечания:
-
Здесь приведена таблица ДАРМ для множественной линейной регрессионной модели (МЛРМ), в нашем случае при ПЛРМ мы имеем частный случай p=1.
-
Показатели Fcalc-ad и Fcalc-det — расчетные значения статистики критерия Фишера при проверке адекватности модели и значимости коэффициента детерминации (об этом — см.далее).
Более подробно про дисперсионный анализ регрессионной модели — см.[4, глава 3].
Класс statsmodels.regression.linear_model.RegressionResults позволяет нам получить данные для ANOVA (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults) как свойства класса:
-
Сумма квадратов, обусловленная регрессией / SSR (Sum of Squared Regression) — свойство ess.
-
Сумма квадратов, обусловленная отклонением от регрессии / SSE (Sum of Squared Error) — свойство ssr.
-
Общая (полная) сумма квадратов / SST (Sum of Squared Total) — свойство centered_tss.
-
Кол-во наблюдений / Number of observations — свойство nobs.
-
Число степеней свободы модели / Model degrees of freedom — равно числу переменных модели (за исключением константы, если она присутствует — свойство df_model.
-
Среднеквадратичная ошибка модели / Mean squared error the model — сумма квадратов, объясненная регрессией, деленная на число степеней свободы регрессии — свойство mse_model.
-
Среднеквадратичная ошибка остатков / Mean squared error of the residuals — сумма квадратов остатков, деленная на остаточные степени свободы — свойство mse_resid.
-
Общая среднеквадратичная ошибка / Total mean squared error — общая сумма квадратов, деленная на количество наблюдений — свойство mse_total.
Также имеется модуль statsmodels.stats.anova.anova_lm, который позволяет получить результаты ДАРМ (нескольких типов — 1, 2, 3):
# тип 1
print('The type of Anova test: 1')
display(sm.stats.anova_lm(result_linear_ols, typ=1))
# тип 2
print('The type of Anova test: 2')
display(sm.stats.anova_lm(result_linear_ols, typ=2))
# тип 3
print('The type of Anova test: 3')
display(sm.stats.anova_lm(result_linear_ols, typ=3))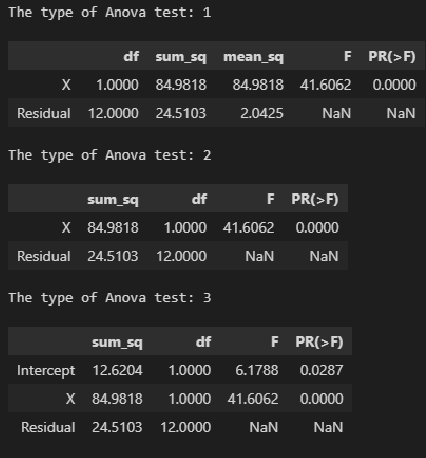
На мой взгляд, форма таблица результатов statsmodels.stats.anova.anova_lm не вполне удобна, поэтому сформируем ее самостоятельно, для чего создадим пользовательскую функцию ANOVA_table_regression_model:
# Пользовательская функция
def ANOVA_table_regression_model(model_fit):
n = int(model_fit.nobs)
p = int(model_fit.df_model)
SSR = model_fit.ess
SSE = model_fit.ssr
SST = model_fit.centered_tss
result = pd.DataFrame({
'sources_of_variation': ('regression (SSR)', 'deviation from regression (SSE)', 'total (SST)'),
'sum_of_squares': (SSR, SSE, SST),
'degrees_of_freedom': (p, n-p-1, n-1)})
result['squared_error'] = result['sum_of_squares'] / result['degrees_of_freedom']
R2 = 1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']
F_calc_adequacy = result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']
F_calc_determ_check = result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']
result['F-ratio'] = (F_calc_determ_check, F_calc_adequacy, '')
return result
result = ANOVA_table_regression_model(result_linear_ols)
display(result)
print(f"R2 = 1 - SSE/SST = {1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']}")
print(f"F_calc_adequacy = MST / MSE = {result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']}")
print(f"F_calc_determ_check = MSR / MSE = {result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']}")
ДАРМ позволяет визуализировать вариацию:
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/1.5))
axes.pie(
(result.loc[0, 'sum_of_squares'], result.loc[1, 'sum_of_squares']),
labels=(result.loc[0, 'sources_of_variation'], result.loc[1, 'sources_of_variation']),
autopct='%.1f%%',
startangle=60)
plt.show()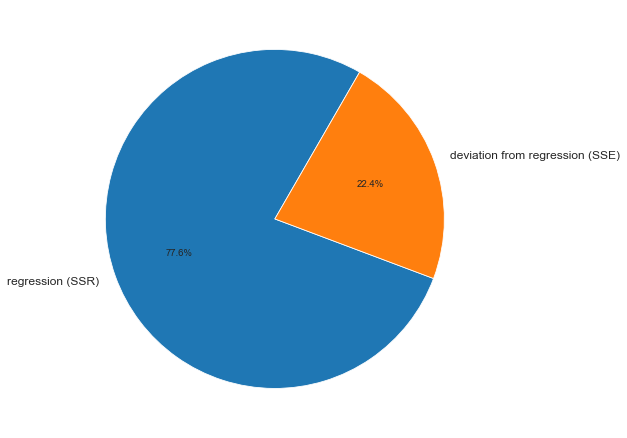
На основании данных ДАРМ мы рассчитали ряд показателей (R2, Fcalc-ad и Fcalc-det), которые будут использоваться в дальнейшем.
3. Анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков)
Проверка нормальности распределения остатков — один их важнейших этапов анализа регрессионной модели. Требование нормальности распределения остатков не требуется для отыскания параметров модели, но необходимо в дальнейшем для проверки статистических гипотез с использованием критериев Фишера и Стьюдента (проверка адекватности модели, значимости коэффициента детерминации, значимости коэффициентов регрессии) и построения доверительных интервалов [5, с.122].
Остатки регрессионной модели:
print('Остатки регрессионной модели:n', result_linear_ols.resid, type(result_linear_ols.resid))
res_Y = np.array(result_linear_ols.resid)statsmodels может выдавать различные преобразованные виды остатков (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.resid_pearson.html, https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.wresid.html).
График остатков:
# Пользовательская функция
graph_scatterplot_sns(
X, res_Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=-3.0, Ymax=3.0,
color='red',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=18,
x_label=Variable_Name_X,
y_label='ΔY = Y - Ycalc',
s=75,
file_name='graph/residuals_plot_sns.png')
Проверка нормальности распределения остатков:
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y,
data_min=-2.5, data_max=2.5,
graph_inclusion='bp',
data_label='ΔY = Y - Ycalc',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png') 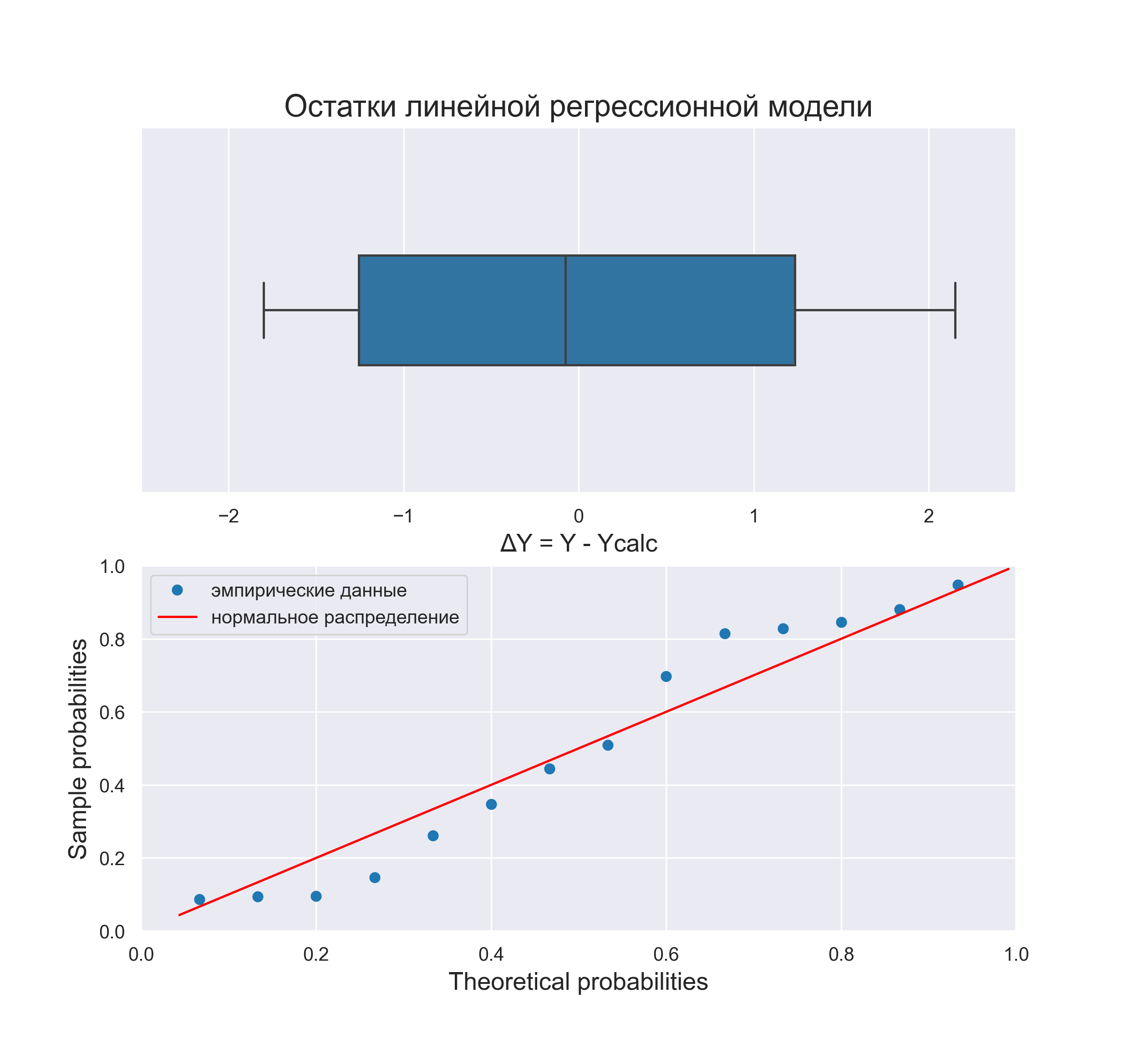
norm_distr_check(res_Y)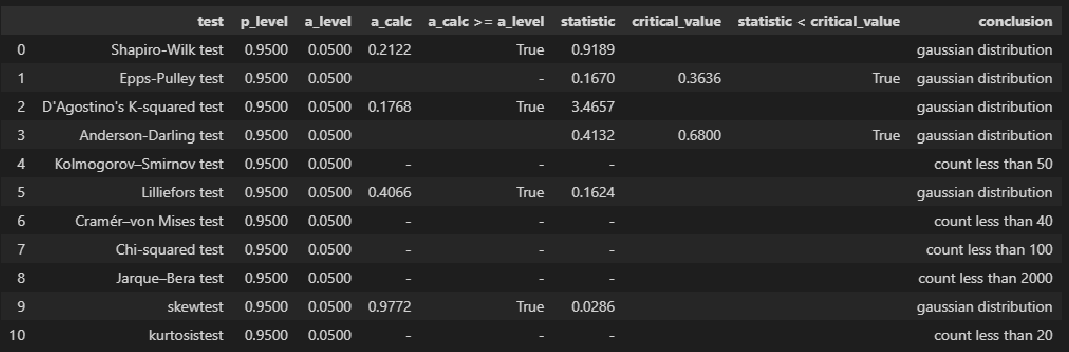
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения остатков.
Проверка гипотезы о равенстве нулю среднего значения остатков — так как остатки имеют нормальное распределение, воспользуемся критерием Стьюдента (функция scipy.stats.ttest_1samp, https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html):
sps.ttest_1samp(res_Y, popmean=0)![]()
Вывод: так как расчетный уровень значимости превышает заданный (0.05), то нулевая гипотеза о равенстве нулю остатков ПРИНИМАЕТСЯ.
4. Проверка адекватности модели
Суть проверки адекватности регрессионной модели заключается в сравнении полной дисперсии MST и остаточной дисперсии MSE — проверяется гипотеза о равенстве этих дисперсий по критерию Фишера. Если дисперсии различаются значимо, то модель считается адекватной. Более подробно про проверку адекватности регрессионной — см.[1, с.658], [2, с.49], [4, с.154].
Для проверки адекватности регрессионной модели создадим пользовательскую функцию regression_model_adequacy_check:
def regression_model_adequacy_check(
model_fit,
p_level: float=0.95,
model_name=''):
n = int(model_fit.nobs)
p = int(model_fit.df_model) # Число степеней свободы регрессии, равно числу переменных модели (за исключением константы, если она присутствует)
SST = model_fit.centered_tss # SST (Sum of Squared Total)
dfT = n-1
MST = SST / dfT
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE
F_calc = MST / MSE
F_table = sci.stats.f.ppf(p_level, dfT, dfE, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, dfT, dfE, loc=0, scale=1)
conclusion_model_adequacy_check = 'adequacy' if F_calc >= F_table else 'adequacy'
# формируем результат
result = pd.DataFrame({
'SST': (SST),
'SSE': (SSE),
'dfT': (dfT),
'dfE': (dfE),
'MST': (MST),
'MSE': (MSE),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'adequacy_check': (conclusion_model_adequacy_check),
},
index=[model_name]
)
return result
regression_model_adequacy_check(result_linear_ols, p_level=0.95, model_name='linear_ols')
Вывод: модель является АДЕКВАТНОЙ.
5. Коэффициент детерминации и проверка его значимости
Различают несколько видов коэффициента детерминации:
-
Собственно обычный коэффициент детерминации:

Его значение может быть получено как свойство rsquared модели.
-
Скорректированный (adjusted) коэффициент детерминации — используется для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику R2, при его расчете используются несмещённые оценки дисперсий:

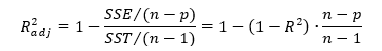
Его значение может быть получено как свойство rsquared_adj модели.
-
Обобщённый (extended) коэффициент детерминации — используется для сравнения моделей регрессии со свободным членом и без него, а также для сравнения между собой регрессий, построенных с помощью различных методов: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК). В данном разборе ПЛРМ рассматривать этот коэффициент мы не будем.
Более подробно с теорией вопроса можно ознакомиться, например: http://www.machinelearning.ru/wiki/index.php?title=Коэффициент_детерминации), а также в [7].
Значения коэффициента детерминации и скорректированного коэффициента детерминации, извлеченные с помощью свойств rsquared и rsquared_adj модели.
print('R2 =', result_linear_ols.rsquared)
print('R2_adj =', result_linear_ols.rsquared_adj)
Значимость коэффициента детерминации можно проверить по критерию Фишера [3, с.201-203; 8, с.83].
Расчетное значение статистики критерия Фишера может быть получено с помощью свойства fvalue модели:
print(f"result_linear_ols.fvalue = {result_linear_ols.fvalue}")![]()
Расчетный уровень значимости при проверке гипотезы по критерию Фишера может быть получено с помощью свойства f_pvalue модели:
print(f"result_linear_ols.f_pvalue = {result_linear_ols.f_pvalue}")![]()
Можно рассчитать уровень значимости самостоятельно (так сказать, для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Фишера scipy.stats.f, свойством cdf (функция распределения):
df1 = int(result_linear_ols.df_model)
df2 = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
F_calc = result_linear_ols.fvalue
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
print(a_calc)![]()
Как видим, результаты совпадают.
Табличное значение статистики критерия Фишера получить с помощью Regression Results нельзя. Рассчитаем его самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.f, свойством ppf (процентные точки):
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
print(F_table)![]()
Для удобства создадим пользовательскую функцию determination_coef_check для проверки значимости коэффициента детерминации, которая объединяет все вышеперечисленные расчеты:
# Пользовательская функция
def determination_coef_check(
model_fit,
p_level: float=0.95):
a_level = 1 - p_level
R2 = model_fit.rsquared
R2_adj = model_fit.rsquared_adj
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
F_calc = R2 / (1 - R2) * (n-p-1)/p
df1 = int(p)
df2 = int(n-p-1)
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
conclusion_determ_coef_sign = 'significance' if F_calc >= F_table else 'not significance'
# формируем результат
result = pd.DataFrame({
'notation': ('R2'),
'coef_value (R)': (sqrt(R2)),
'coef_value_squared (R2)': (R2),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'df1': (df1),
'df2': (df2),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_determ_coef_sign),
'conf_int_low': (''),
'conf_int_high': ('')
},
index=['Coef. of determination'])
return result
determination_coef_check(
result_linear_ols,
p_level=0.95)
Вывод: коэффициент детерминации ЗНАЧИМ.
6. Коэффициенты регрессии и проверка их значимости
Ранее мы уже извлекли коэффициенты регрессии как параметры модели b0 и b1 (как свойство params модели). Также можно получить их значения, как свойство bse модели:
print(b0, b1)
print(result_linear_ols.bse, type(result_linear_ols.bse))
Значимость коэффициентов регрессии можно проверить по критерию Стьюдента [3, с.203-212; 8, с.78].
Расчетные значения статистики критерия Стьюдента могут быть получены с помощью свойства tvalues модели:
print(f"result_linear_ols.tvalues = n{result_linear_ols.tvalues}")
Расчетные значения уровня значимости при проверке гипотезы по критерию Стьюдента могут быть получены с помощью свойства pvalues модели:
print(f"result_linear_ols.pvalues = n{result_linear_ols.pvalues}")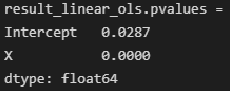
Доверительные интервалы для коэффициентов регрессии могут быть получены с помощью свойства conf_int модели:
print(result_linear_ols.conf_int(), 'n')
Можно рассчитать уровень значимости самостоятельно (как ранее для критерия Фишера — для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством cdf (функция распределения):
t_calc = result_linear_ols.tvalues
df = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
a_calc = 2*(1-sci.stats.t.cdf(abs(t_calc), df, loc=0, scale=1))
print(a_calc)![]()
Как видим, результаты совпадают.
Табличные значения статистики критерия Стьюдента получить с помощью Regression Results нельзя. Рассчитаем их самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством ppf (процентные точки):
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
print(t_table)![]()
Для удобства создадим пользовательскую функцию regression_coef_check для проверки значимости коэффициентов регрессии, которая объединяет все вышеперечисленные расчеты:
def regression_coef_check(
model_fit,
notation_coef: list='',
p_level: float=0.95):
a_level = 1 - p_level
# параметры модели (коэффициенты регрессии)
model_params = model_fit.params
# стандартные ошибки коэффициентов регрессии
model_bse = model_fit.bse
# проверка гипотезы о значимости регрессии
t_calc = abs(model_params) / model_bse
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
df = int(n - p - 1)
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
a_calc = 2*(1-sci.stats.t.cdf(t_calc, df, loc=0, scale=1))
conclusion_ = ['significance' if elem else 'not significance' for elem in (t_calc >= t_table).values]
# доверительный интервал коэффициента регрессии
conf_int_low = model_params - t_table*model_bse
conf_int_high = model_params + t_table*model_bse
# формируем результат
result = pd.DataFrame({
'notation': (notation_coef),
'coef_value': (model_params),
'std_err': (model_bse),
'p_level': (p_level),
'a_level': (a_level),
't_calc': (t_calc),
'df': (df),
't_table': (t_table),
't_calc >= t_table': (t_calc >= t_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_),
'conf_int_low': (conf_int_low),
'conf_int_high': (conf_int_high),
})
return result
regression_coef_check(
result_linear_ols,
notation_coef=['b0', 'b1'],
p_level=0.95)
Вывод: коэффициенты регрессии b0 и b1 ЗНАЧИМЫ.
7. Проверка гетероскедастичности
Для проверка гетероскедастичности statsmodels предлагает нам следующие инструменты:
-
тест Голдфелда-Квандта (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_goldfeldquandt.html#statsmodels.stats.diagnostic.het_goldfeldquandt) — теорию см. [8, с.178], также https://ru.wikipedia.org/wiki/Тест_Голдфелда_—_Куандта.
-
тест Бриша-Пэгана (Breush-Pagan test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_breuschpagan.html#statsmodels.stats.diagnostic.het_breuschpagan) — теорию см.[8, с.179], также https://en.wikipedia.org/wiki/Breusch–Pagan_test.
-
тест Уайта (White test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_white.html#statsmodels.stats.diagnostic.het_white) — теорию см.[8, с.177], а также https://ru.wikipedia.org/wiki/Тест_Уайта.
Тест Голдфелда-Квандта (Goldfeld–Quandt test)
# тест Голдфелда-Квандта (Goldfeld–Quandt test)
test = sms.het_goldfeldquandt(result_linear_ols.resid, result_linear_ols.model.exog)
test_result = lzip(['F_calc', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_calc = F_calc_tuple[1]
print(f"Расчетное значение статистики F-критерия: F_calc = {round(F_calc, DecPlace)}")
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
print(f"Расчетное значение доверительной вероятности: p_calc = {round(p_calc, DecPlace)}")
#a_calc = 1 - p_value
#print(f"Расчетное значение уровня значимости: a_calc = 1 - p_value = {round(a_calc, DecPlace)}")
# вывод
if p_calc < a_level:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются значимо, т.е. гипотеза о наличии гетероскедастичности ПРИНИМАЕТСЯ"
else:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются незначимо, т.е. гипотеза о наличии гетероскедастичности ОТВЕРГАЕТСЯ"
print(conclusion_GQ_test)
Для удобства создадим пользовательскую функцию Goldfeld_Quandt_test:
def Goldfeld_Quandt_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_goldfeldquandt(model_fit.resid, model_fit.model.exog)
test_result = lzip(['F_statistic', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Goldfeld–Quandt test'),
'p_level': (p_level),
'a_level': (a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Бриша-Пэгана (Breush-Pagan test)
# тест Бриша-Пэгана (Breush-Pagan test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_breuschpagan(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)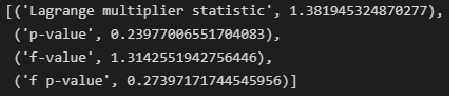
Для удобства создадим пользовательскую функцию Breush_Pagan_test:
def Breush_Pagan_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_breuschpagan(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Breush-Pagan test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Уайта (White test)
# тест Уайта (White test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_white(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)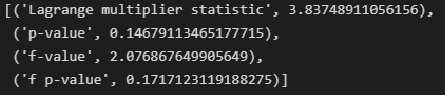
Для удобства создадим пользовательскую функцию White_test:
def White_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_white(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('White test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Объединим результаты всех тестов гетероскедастичность в один DataFrame:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Выводы
Итак, мы провели статистический анализ регрессионной модели и установили:
-
исходные данные имеют нормальное распределение;
-
между переменными имеется весьма сильная корреляционная связь;
-
регрессионная модель хорошо аппроксимирует фактические данные;
-
остатки модели имеют нормальное распределение;
-
регрессионная модель адекватна по критерию Фишера;
-
коэффициент детерминации значим по критеию Фишера;
-
коэффициенты регрессии значимы по критерию Стьюдента;
-
гетероскедастичность отсутствует.
Применительно к рассматриваемой задаче выполнять проверку автокорреляции не имеет особого смысла из-за особенностей исходных данных (результаты замеров прочности бетона на разных участках здания).
Про статистический анализ регрессионных моделей с помощью statsmodels— см. еще https://www.statsmodels.org/stable/examples/notebooks/generated/regression_diagnostics.html.
Доверительные интервалы регрессионной модели
Для регрессионных моделей определяют доверительные интервалы двух видов [3, с.184-192; 4, с.172; 8, с.205-209]:
-
Доверительный интервал средних значений переменной Y.
-
Доверительный интервал индивидуальных значений переменной Y.
При этом размер доверительного интервала для индивидуальных значений больше, чем для средних значений.
Доверительные интервалы регрессионных моделей (ДИРМ) могут быть найдены разными способами:
-
непосредственно путем расчетов по формулам (см., например, https://habr.com/ru/post/558158/);
-
с использованием инструментария библиотеки statsmodels (см., например, https://www.stackfinder.ru/questions/17559408/confidence-and-prediction-intervals-with-statsmodels).
Разбререм более подробно способ с использованием библиотеки statsmodels. Прежде всего, с помощью свойства summary_table класса statsmodels.stats.outliers_influence.OLSInfluence (https://www.statsmodels.org/stable/generated/statsmodels.stats.outliers_influence.OLSInfluence.html?highlight=olsinfluence) мы можем получить таблицу данных, содержащую необходимую нам информацию:
-
Dep Var Population — фактические значения переменной Y;
-
Predicted Value — предсказанные значения переменной Y по по регрессионной модели;
-
Std Error Mean Predict — среднеквадратическая ошибка предсказанного среднего;
-
Mean ci 95% low и Mean ci 95% upp — границы доверительного интервала средних значений переменной Y;
-
Predict ci 95% low и Predict ci 95% upp — границы доверительного интервала индивидуальных значений переменной Y;
-
Residual — остатки регрессионной модели;
-
Std Error Residual — среднеквадратическая ошибка остатков;
-
Student Residual — стьюдентизированные остатки (подробнее см. http://statistica.ru/glossary/general/studentizirovannie-ostatki/);
-
Cook’s D — Расстояние Кука (Cook’s distance) — оценивает эффект от удаления одного (рассматриваемого) наблюдения; наблюдение считается выбросом, если Di > 4/n (более подробно — см.https://translated.turbopages.org/proxy_u/en-ru.ru.f584ceb5-63296427-aded8f31-74722d776562/https/en.wikipedia.org/wiki/Cook’s_distance, http://www.machinelearning.ru/wiki/index.php?title=Расстояние_Кука).
from statsmodels.stats.outliers_influence import summary_table
st, data, ss2 = summary_table(result_linear_ols, alpha=0.05)
print(st, 'n', type(st))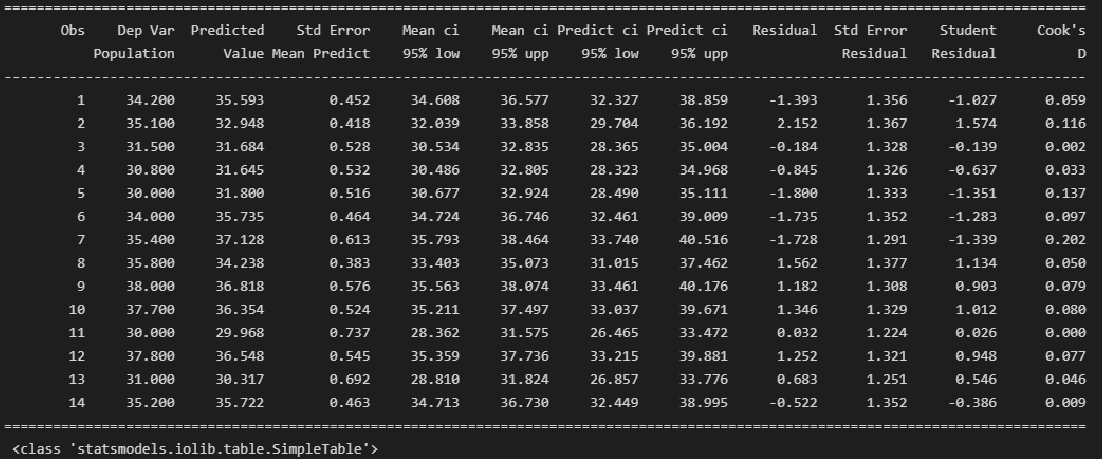
В нашем случае критическое значение расстояния Кука равно:
print(f'D_crit = 4/n = {4/result_linear_ols.nobs}')![]()
то есть выбросов, смещающих оценки коэффициентов регрессии, не наблюдается.
Мы получили данные как класс statsmodels.iolib.table.SimpleTable. Свойство data преобразует данные в список. Далее для удобства работы преобразуем данные в DataFrame:
st_data_df = pd.DataFrame(st.data)Будем использовать данный DataFrame в дальнейшем, несколько преобразуем его:
-
изменим наименование столбцов (с цифр на названия показателей из таблицы summary_table)
-
удалим строки с текстовыми значениями
-
изменим индекс
-
добавим новый столбец — значения переменной X
-
отсортируем по возрастанию значений переменной X (это необходимо, чтобы графики границ доверительных интервалов выглядели как линии)
st_df = st_data_df.copy()
# изменим наименования столбцов
str = st_df.iloc[0,0:] + ' ' + st_df.iloc[1,0:]
st_df = st_df.rename(str, axis='columns')
# удалим строки 0, 1
st_df = st_df.drop([0,1])
# изменим индекс
st_df = st_df.set_index(np.arange(0, result_linear_ols.nobs))
# добавим новый столбец - значения переменной X
st_df.insert(1, 'X', X)
# отсортируем по возрастанию значений переменной X
st_df = st_df.sort_values(by='X')
display(st_df)
С помощью полученных данных мы можем построить график регрессионной модели с доверительными интервалами:
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 16)
# заголовок области рисования (Axes)
title_axes = 'Линейная регрессионная модель'
axes.set_title(title_axes, fontsize = 14)
# фактические данные
sns.scatterplot(
x=st_df['X'], y=st_df['Dep Var Population'],
label='фактические данные',
s=50,
color='red',
ax=axes)
# график регрессионной модели
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X'
sns.lineplot(
x=st_df['X'], y=st_df['Predicted Value'],
label=label_legend_regr_model,
color='blue',
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = st_df['Mean ci 95% low']
plt.plot(
st_df['X'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = st_df['Mean ci 95% upp']
plt.plot(
st_df['X'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = st_df['Predict ci 95% low']
plt.plot(
st_df['X'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = st_df['Predict ci 95% upp']
plt.plot(
st_df['X'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlabel(Variable_Name_X)
axes.set_ylabel(Variable_Name_Y)
axes.legend(prop={'size': 12})
plt.show()
Однако, мы получили данные о границах доверительных интервалов регрессионной модели только в пределах области фактических значений переменной X. Как быть, если мы хотим распространить прогноз за пределы этой области?
Прогнозирование
Под прогнозированием мы в данном случае будем понимать определение значений переменной Y и доверительных интервалов для ее средних и индивидуальных значений при заданном X. По сути, нам предстоит построить аналог рассмотренной выше таблицы summary_table, только с другими значениями X, причем эти значения могут выходить за пределы тех значений, которые использовались нами для построения регрессии.
Методика расчета доверительных интервалов регрессионных моделей разобрана в статье «Python, корреляция и регрессия: часть 4» (https://habr.com/ru/post/558158/), всем рекомендую ознакомиться.
Найти прогнозные значения Y не представляет труда, так как ранее мы уже формализовали модель в виде лямбда-функции, а вот для построения доверительных интервалов придется выполнить расчеты по формулам. Для этого создадим пользовательскую функцию regression_pair_predict, которая в случае парной регрессии (pair regression) для заданного значения X возвращает:
-
прогнозируемое по регрессионной модели значение y_calc
-
доверительный интервал [y_calc_mean_ci_low, y_calc_mean_ci_upp] средних значений переменной Y
-
доверительный интервал [y_calc_predict_ci_low, y_calc_predict_ci_upp] индивидуальных значений переменной Y
Алгоритм расчета доверительных интервалов для множественной регрессии (multiple regression) отличается и в данном обзоре не рассматривается (рассмотрим в дальнейшем).
Про прогнозирование с помощью регрессионных моделей — см.также:
-
https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.predict.html?highlight=predict#statsmodels.regression.linear_model.RegressionResults.predict
-
How to Make Predictions Using Regression Model in Statsmodels
-
https://www.statsmodels.org/stable/examples/notebooks/generated/predict.html
def regression_pair_predict(
x_in,
model_fit,
regression_model,
p_level: float=0.95):
a_level = 1 - p_level
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
# вспомогательные величины
n = int(result_linear_ols.nobs)
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE # остаточная дисперсия
Xmean = np.mean(X)
SST_X = np.sum([(X[i] - Xmean)**2 for i in range(0, n)])
t_table = sci.stats.t.ppf((1 + p_level)/2 , dfE)
S2_y_calc_mean = MSE * (1/n + (x_in - Xmean)**2 / SST_X)
S2_y_calc_predict = MSE * (1 + 1/n + (x_in - Xmean)**2 / SST_X)
# прогнозируемое значение переменной Y
y_calc=regression_model(x_in)
# доверительный интервал средних значений переменной Y
y_calc_mean_ci_low = y_calc - t_table*sqrt(S2_y_calc_mean)
y_calc_mean_ci_upp = y_calc + t_table*sqrt(S2_y_calc_mean)
# доверительный интервал индивидуальных значений переменной Y
y_calc_predict_ci_low = y_calc - t_table*sqrt(S2_y_calc_predict)
y_calc_predict_ci_upp = y_calc + t_table*sqrt(S2_y_calc_predict)
result = y_calc, y_calc_mean_ci_low, y_calc_mean_ci_upp, y_calc_predict_ci_low, y_calc_predict_ci_upp
return resultСравним результаты расчета доверительных интервалов разными способами — с использованием функции regression_pair_predict и средствами statsmodels, для этого сформируем DaraFrame с новыми данными:
regression_pair_predict_df = pd.DataFrame(
[regression_pair_predict(elem, result_linear_ols, regression_model=Y_calc) for elem in st_df['X'].values],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
regression_pair_predict_df.insert(0, 'X', st_df['X'].values)
display(regression_pair_predict_df)
Видим, что результаты расчетов идентичны, следовательно мы можем использовать функцию regression_pair_predict для прогнозирования.
def graph_regression_pair_predict_plot_sns(
model_fit,
regression_model_in,
Xmin=None, Xmax=None, Nx=10,
Ymin_graph=None, Ymax_graph=None,
title_figure=None, title_figure_fontsize=18,
title_axes=None, title_axes_fontsize=16,
x_label=None,
y_label=None,
label_fontsize=14, tick_fontsize=12,
label_legend_regr_model='', label_legend_fontsize=12,
s=50, linewidth_regr_model=2,
graph_size=(297/INCH, 210/INCH),
result_output=True,
file_name=None):
# фактические данные
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
X = np.array(X)
Y = np.array(Y)
# границы
if not(Xmin) and not(Xmax):
Xmin=min(X)
Xmax=max(X)
Xmin_graph=min(X)*0.99
Xmax_graph=max(X)*1.01
else:
Xmin_graph=Xmin
Xmax_graph=Xmax
if not(Ymin_graph) and not(Ymax_graph):
Ymin_graph=min(Y)*0.99
Ymax_graph=max(Y)*1.01
# формируем DataFrame данных
Xcalc = np.linspace(Xmin, Xmax, num=Nx)
Ycalc = regression_model_in(Xcalc)
result_df = pd.DataFrame(
[regression_pair_predict(elem, model_fit, regression_model=regression_model_in) for elem in Xcalc],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
result_df.insert(0, 'x_calc', Xcalc)
# заголовки графика
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=s,
color='red',
ax=axes)
# график регрессионной модели
sns.lineplot(
x=Xcalc, y=Ycalc,
color='blue',
linewidth=linewidth_regr_model,
legend=True,
label=label_legend_regr_model,
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = result_df['y_calc_mean_ci_low']
plt.plot(
result_df['x_calc'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = result_df['y_calc_mean_ci_upp']
plt.plot(
result_df['x_calc'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = result_df['y_calc_predict_ci_low']
plt.plot(
result_df['x_calc'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = result_df['y_calc_predict_ci_upp']
plt.plot(
result_df['x_calc'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlim(Xmin_graph, Xmax_graph)
axes.set_ylim(Ymin_graph, Ymax_graph)
axes.set_xlabel(x_label, fontsize = label_fontsize)
axes.set_ylabel(y_label, fontsize = label_fontsize)
axes.tick_params(labelsize = tick_fontsize)
#axes.tick_params(labelsize = tick_fontsize)
axes.legend(prop={'size': label_legend_fontsize})
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
if result_output:
return result_df
else:
return
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols,
regression_model_in=Y_calc,
Xmin=Xmin_graph-300, Xmax=Xmax_graph+200, Nx=25,
Ymin_graph=Ymin_graph-5, Ymax_graph=Ymax_graph+5,
title_figure=Task_Project, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=True,
file_name='graph/regression_plot_lin.png')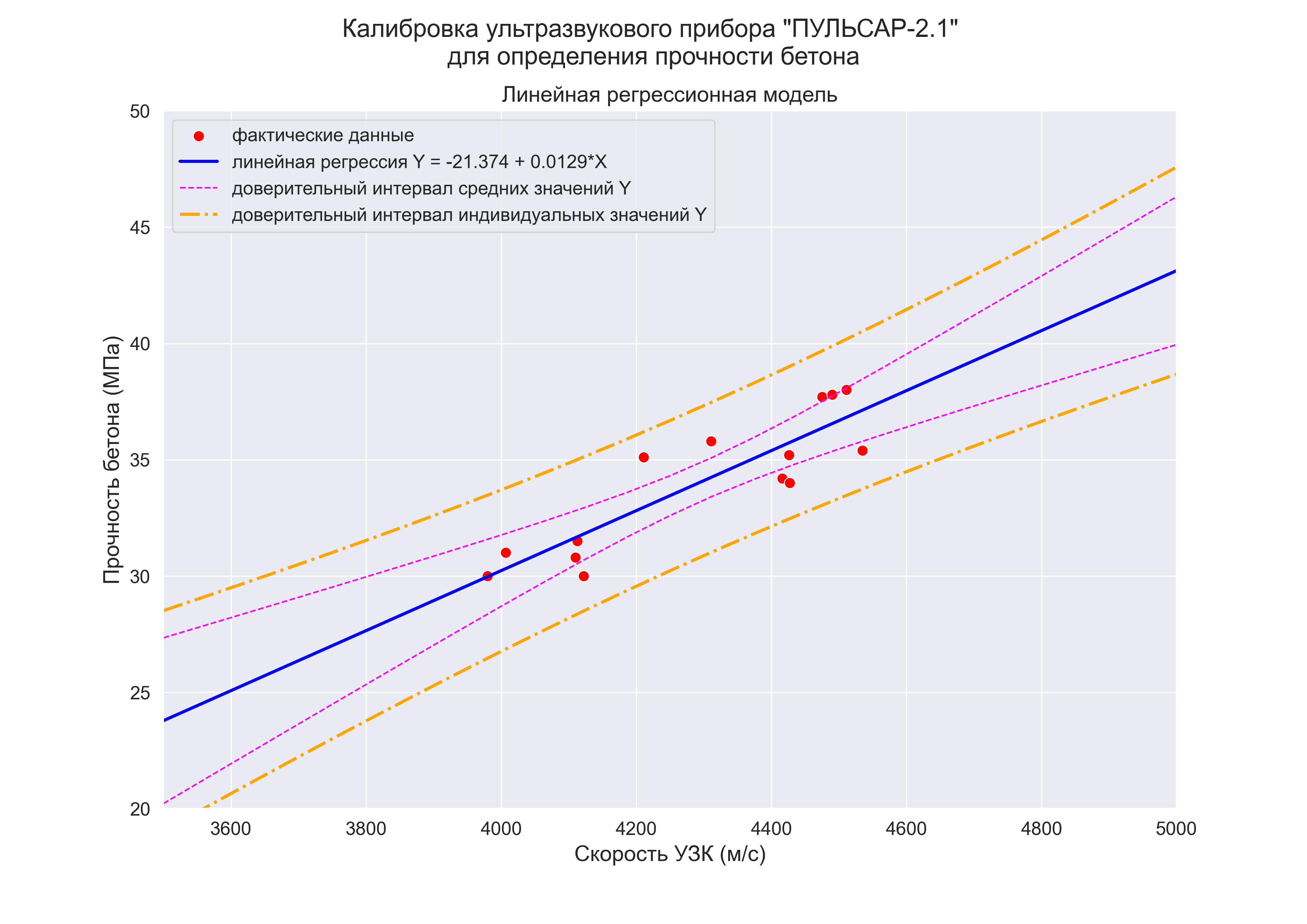
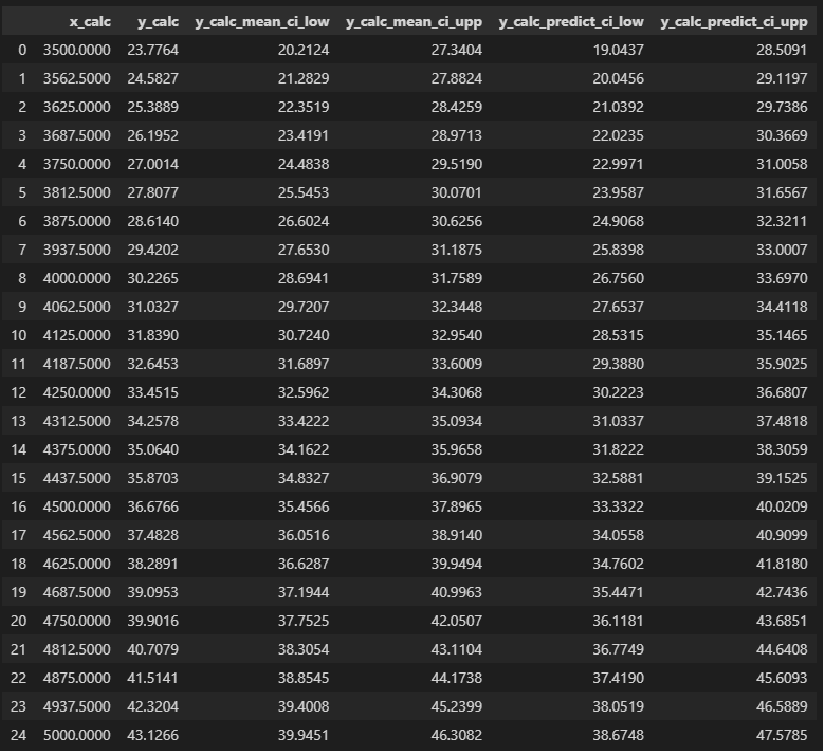
Выводы и рекомендации
Исследована зависимость показаний ультразвукового прибора «ПУЛЬСАР-2.1» (X) и результатов замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03 (Y).
Между переменными имеется весьма сильная линейная корреляционная связь. Получена регрессионная модель:
Y = b0 + b1∙X = -21.3741 + 0.0129∙X
Модель хорошо аппроксимирует фактические данные, является адекватной, значимой и может использоваться для предсказания прочности бетона.
Также построен график прогноза с доверительными интервалами.
ИТОГИ
Итак, мы рассмотрели все этапы регрессионного анализа в случае простой линейной регрессии (simple linear regression) с использованием библиотеки statsmodels на конкретном практическом примере; подробно остановились на статистическом анализа модели с проверкой гипотез; также предложен ряд пользовательских функций, облегчающих работу исследователя и уменьшающих размер программного кода.
Конечно, мы разобрали далеко не все вопросы анализа регрессионных моделей и возможности библиотеки statsmodels применительно к simple linear regression, в частности статистики влияния (Influence Statistics), инструмент Leverage, анализ стьюдентизированных остатков и пр. — это темы для отдельных обзоров.
Исходный код находится в моем репозитории на GitHub.
Надеюсь, данный обзор поможет специалистам DataScience в работе.