Поможем решить контрольную, написать реферат, курсовую и диплом от 800р
Узнать стоимость
Статистическое распределение выборки
Содержание:
- Примеры использования формул и таблиц для решения практических задач
- Статистический интервальный ряд распределения
Предположим случай, когда из генеральной совокупности извлекается некоторая выборка, при этом каждому значению соответствует некоторый параметр, означающий количество раз, когда появлялось данное значение. Здесь $x_1$ было зафиксировано $n_1$ раз, $x_2$ было обнаружено $n_2$$x_k$ выявлено $n_k$. При этом
$sum_{i=1}^{k}n_i=n$
Где n — объём рассматриваемой выборки.
Определение 1
Используется следующая терминология: $x_k$ носят наименование вариантов, а последовательность таких вариантов, зафиксированный по возрастанию именуется вариационным рядом. Количество наблюдений каждого из вариантов носят название частот. При этом частное частот и выборки называют относительными частотами.
Определение 2
Статистическое распределение —это название всего набора вариантов и частот, которые с ними соотносятся. Чаще всего задаётся с помощью специальной таблицы, где представлены частоты, а также интервалы им соответствующие.
| $x_1$ | $x_2$ | … | $x_k$ |
| $n_1$ | $n_2$ | … | $n_k$ |
| $frac{n_1}{n}$ | $frac{n_2}{n}$ | $frac{n_k}{n}$ |
Здесь в первой строке представлены варианты, во второй частоты, в третьеq взяты относительные частоты.
Для определения размера интервала используется следующее выражение:
$d=frac{x_{max}- x_{min}}{1+3,332cdot lg n}$
Здесь $x_{max}$, $x_{min}$ наибольшее и наименьшее значения ряда вариантов, а n характеризуем объём выборки.
Примеры использования формул и таблиц для решения практических задач
Пример 1
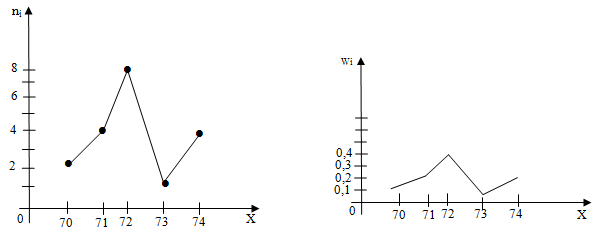
В ходе проведения измерений в однородных группах, были определены следующие значения выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74. Необходимо использовать данные значения, что определить ряд распределения частот и ряд распределения относительных частот.
Решение.
1) Составим статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Рассчитаем суммарный размер выборки: n=2+4+8+2+4=20. Определим относительные частоты, для этого используем формулы: ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Теперь зафиксируем в таблице распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контрольная сумма должна равняться единице: 0,1+0,2+0,4+0,1+0,2=1.
Полигон частот
Название «полигоном частот» применяют для обозначения ломаной линии, каждый отрезок, которой соединяют точки $(х_1,n_1),(х_2,n_2),…,(х_k,n_k)$. Для построения на графике полигона частот по оси абсцисс отмечают варианты $х_2$, при этом на оси ординат отсчитывают– соответствующие частоты $n_i$. Когда полученные точки $(х_i,n_i)$ соединяются с помощью отрезков, то автоматически получают полигон частот.
Статистический интервальный ряд распределения.
Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются, если число различающихся вариант в полученной выборке не слишком большое. Также применение возможно, когда дискретность имеет важное значение для экспериментатора. В тех случаях, когда важный для задачи признак генеральной совокупности Х распределяется непрерывным образом, либо его дискретность нет возможности учесть, то варианты предпочтительнее всего группировать, чтобы получить интервалы.
Статистическое распределение допустимо задавать в том числе в качестве последовательности интервалов и частот, соответствующих этим интервалам. При это за частоту какого-либо интервала принимается сумма всех частот, вошедших в данный интервал.
Особенно следует отметить ,что $h_i-h_{i-1}=h$ при всех i, т.е. группировка проводится с равным шагом h. Также в вопросе группировки можно ориентироваться на ряд полученных опытным путём рекомендацийу, касающихся таких параметров, как а, k и $h_i$:
1. $Rраз_{мах}=X_{max}-X_{min}$
2. $h=R/k$; k-число групп
3.$ kgeq 1+3.321lgn$ (формула Стерджеса)
4. $a=x_{min}, b=x_{max}$
5.$ h=a+h_i, i=0,1…k$
Определённую в ходе решения задачи группировку удобнее всего скомпоновать и перевести в вид специальной таблицы, которая также может именоваться — «статистический интервальный ряд распределения»:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Таблицу подобного вида можно сделать, поменяв частоты $n_i$ на относительные частоты:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |

236
проверенных автора готовы помочь в написании работы любой сложности
Мы помогли уже 4 430 ученикам и студентам сдать работы от решения задач до дипломных на отлично! Узнай стоимость своей работы за 15 минут!
Пример 2
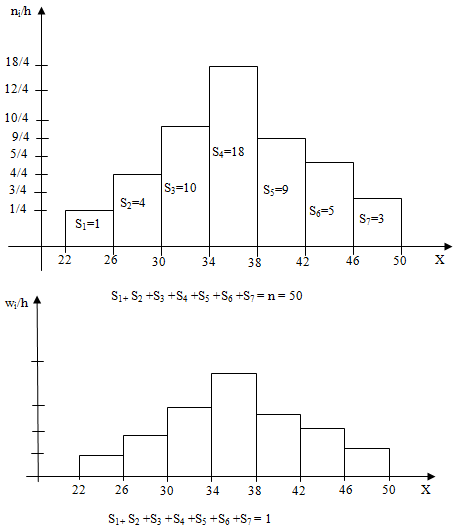
На склад пришла крупная партия деталей. Из них методом случайного отбора взято 50 экземпляров. Рассматривая изделия по одному, особенно интересующему признаку — размеру, определённому с точностью до 1 см, получим следующий вариационный ряд: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Требуется произвести расчёт и определить статистический интервальный ряд распределения.
Решение
Найдём параметры выборки используя сведения из условия задачи.
$k geq1+3,321cdot lg50=1+3.32lg(5cdot10)=1+3.32(lg5+lg10)=6.6$
Получили a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн. частоты | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Не получается написать работу самому?
Доверь это кандидату наук!
При систематизации данных выборочных обследований используются статистические дискретные и интервальные ряды распределения.
1. Статистическое дискретное распределение. Полигон.
Пусть из генеральной совокупности извлечена выборка, причем х1 наблюдалось n1 раз, х2 – n2 раз, хk – nk раз и ∑ni=n — объем выборки. Наблюдаемые значения х1 называют вариантами, а последовательность вариант, записанных в возрастающем порядке – вариационным рядом. Число наблюдений варианты называют частотой, а ее отношение к объему выборки — относительной частотой ni/n=wi
ОПРЕДЕЛЕНИЕ. Статистическим (эмпирическим) законом распределения выборки, или просто статистическим распределением выборки называют последовательность вариант хi и соответствующих им частот ni или относительных частот wi.
Статистическое распределение выборки удобно представлять в форме таблицы распределения частот, называемой статистическим дискретным рядом распределения:
| x1 | x2 | … | xm |
| n1 | n2 | … | nm |
(сумма всех частот равна объему выборки ∑ni=n)
или в виде таблицы распределения относительных частот:
| x1 | x2 | … | xm |
| w1 | w2 | … | wm |
(сумма всех относительных частот равна единице ∑wi=1)
Пример 1. При измерениях в однородных группах обследуемых получены следующие выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74 (частота пульса). Составить по этим результатам статистический ряд распределения частот и относительных частот.
Решение. 1) Статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Объем выборки: n=2+4+8+2+4=20. Найдем относительные частоты, для чего разделим частоты на объем выборки ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Напишем распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контроль: 0,1+0,2+0,4+0,1+0,2=1.
Полигоном частот называют ломаную, отрезки, которой соединяют точки (х1,n1),(х2,n2),…,(хk,nk). Для построения полигона частот на оси абсцисс откладывают варианты х2, а на оси ординат – соответствующие им частоты ni. Точки (хi,ni) соединяют отрезками и получают полигон частот.
Полигоном относительных частот называют ломаную, отрезки, которой соединяют точки (х1,w1),(х2,w2),…,(хk,wk). Для построения полигона относительных частот на оси абсцисс откладывают варианты хi, а на оси ординат соответствующие им частоты wi. Точки (хi,wi) соединяют отрезками и получают полигон относительных частот.
Пример 2. Постройте полигон частот и относительных частот по данным примера 1.
Решение: Используя дискретный статистический ряд распределения, составленный в примере 1 построим полигон частот и полигон относительных частот:
2. Статистический интервальный ряд распределения. Гистограмма. Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются в том случае, когда отличных друг от друга вариант в выборке не слишком много, или тогда, когда дискретность по тем или иным причинам существенна для исследователя. Если же интересующий нас признак генеральной совокупности Х распределен непрерывно или его дискретность нецелесообразно ( или невозможно) учитывать, то варианты группируются в интервалы.
Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (в качестве частоты, соответствующей интервалу, принимают сумму частот, попавших в этот интервал).
Замечание. Часто hi-hi-1=h при всех i, т.е. группировку осуществляют с равным шагом h. В этой ситуации можно руководствоваться следующими эмперическими рекомендациями по выборке а, k и hi:
1. Rразмах=Xmax-Xmin
2. h=R/k; k-число групп
3. k≥1+3.321lgn (формула Стерджеса)
4. a=xmin, b=xmax
5. h=a+ih, i=0,1…k
Полученную группировку удобно представить в форме частотной таблицы, которая носит название статистический интервальный ряд распределения:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Аналогическую таблицу можно образовать, заменяя частоты ni относительными частотами:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |
Пример 3. Из очень большой партии деталей извлечена случайная выборка объема 50 интересующий нас признак Х-размеры деталей, измеренные с точностью до 1см, представлен следующим вариоционным рядом: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Найти статистический интервальный ряд распределения.
Решение. Определим характеристики группировки с помощью замечания.
k≥1+3.321lg50=1+3.32lg(5•10)=1+3.32(lg5+lg10)=6.6
Имеем, a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты ni | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн.частоты wi | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Наиболее информативной графической формой частот является специальный график, называемы гистограммой частот.
Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиною h, а высоты равны отношению ni/h (плотность частоты).
Для построения гистограммы частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии ni/h. Площадь i-го частичного прямоугольника равна h•ni/h=ni — сумме частот вариант i-го интервала; следовательно, площадь гистограммы частот равна сумме всех частот, т.е. объему выборки.
Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиною h, а высоты равны отношению wi/h (плотность относительной частоты).
Для построения гистограммы относительных частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии wi/h. Площадь i-го частичного прямоугольника равна h•wi/h=wi — относительной частоте вариант, попавших в i-й интервал. Следовательно, площадь гистограммы относительных частот равна сумме всех относительных частот, т.е. единице.
Пример 4. Постройте гистограмму частот и относительных частот по данным примера 3.
Выборочная медиана – это середина вариационного ряда, значение, расположенное на одинаковом расстоянии от левой и правой границы выборки.
Выборочная мода – это наиболее вероятное, т.е. чаще всего встречающееся, значение в выборке.
Добавлять комментарии могут только зарегистрированные пользователи.
Регистрация Вход
Пусть
для изучения количественного (дискретного
или непрерывного) признака Х из генеральной
совокупности извлечена выборка, причем
значение x1
наблюдалось n1
раз, значение x2
наблюдалось n2
раз, …, значение xk
наблюдалось nk
раз.
Наблюдаемые
значения xi
(i
= 1, 2, …, n)
признака Х называют вариантами, а
последовательность всех вариант,
записанных в возрастающем порядке, –
вариационным
рядом.
Числа наблюдений ni
называют частотами,
их сумма
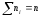 ─объем
─объем
выборки.
Отношения частот к объему выборки
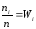 ─относительными
─относительными
частотами.
Статистическим
распределением выборки
называют перечень вариант xi
вариационного ряда и соответствующих
им частот ni
(сумма всех частот равна объему выборки
n)
или относительных частот Wi
(сумма всех относительных частот равна
единице). Статистическое распределение
можно задать также в виде последовательности
интервалов и соответствующих им частот
(в качестве частоты, соответствующей
интервалу, принимают сумму частот,
попавших в этот интервал).
Заметим,
что в теории вероятностей под распределением
понимают соответствие между возможными
значениями случайной величины и их
вероятностями, а в математической
статистике – соответствие между
наблюдаемыми вариантами и их частотами
(или относительными частотами).
Пример.
Задано распределение частот выборки
объема n
= 20:
|
|
2 |
6 |
12 |
|
|
3 |
10 |
7 |
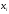
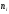
В
данной выборке получены следующие
варианты x1
= 2; x2
= 6; x3
= 12,
соответствующие
частоты n1
= 3; n2
= 10; n3
= 7.
Напишем
распределение относительных частот.
Решение.
Найдем относительные частоты, для чего
разделим частоты на объем выборки
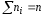 = 3 + 10 + 7 = 20.
= 3 + 10 + 7 = 20.
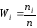
─ относительные
частоты:
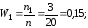
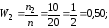

Напишем распределение
относительных частот:
|
|
2 |
6 |
12 |
|
|
0,15 |
0,50 |
0,35 |
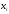
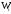
Контроль:
сумма всех относительных частот
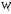 равна единице:
равна единице:
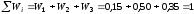 .
.
§14. Эмпирическая функция распределения
Пусть
известно статистическое распределение
частот количественного признака Х.
Введем обозначения:
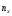 ─
─
число наблюдений, при которых наблюдалось
значение признака, меньше х; n
– общее число наблюдений (объем выборки).
Ясно, что относительная частота события
Х<х равна
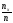 .
.
Если х изменяется, то, вообще говоря,
изменится и относительная частота, то
есть относительная частота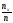 есть функция от х. Так как эта функция
есть функция от х. Так как эта функция
находится эмпирическим (опытным) путем,
то ее называют эмпирической.
Определение.
Эмпирическая
функция распределения
(функция распределения выборки) –
функция F*(x),
определяющая для каждого значения х
относительную частоту события X<x.
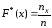 ,
,
где
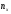 ─ число вариант, меньших х;n
─ число вариант, меньших х;n
– объем выборки.
Например,
для того чтобы найти F*(x2),
надо число вариант, меньших x2,
разделить на объем выборки:
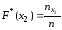 .
.
В
отличие от эмпирической функции
распределения выборки функцию
распределения F(x)
генеральной совокупности называют
теоретической
функцией распределения.
Различие между эмпирической и теоретической
функциями состоит в том, что теоретическая
функция F(x)
определяет вероятность события X<x,
а эмпирическая функция F*(x)
определяет относительную частоту этого
же события.
Из
теоремы Бернулли следует, что относительная
частота события X<x,
то есть F*(x),
стремится по вероятности к вероятности
этого события, то есть к значению F(x).
Другими словами, при больших значениях
n
числа F*(x)
и F(x)
мало отличаются одно от другого в том
смысле, что
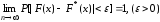 .
.
Уже отсюда следует целесообразность
использования эмпирической функции
распределения выборки для приближенного
представления теоретической (интегральной)
функции распределения генеральной
совокупности. Такое заключение
подтверждается и тем, что F*(x)
обладает всеми свойствами F(x).
Из
определения функции F*(x)
вытекают следующие ее свойства:
-
Значения
эмпирической функции принадлежит
отрезку [0; 1]; -
F*(x)
– неубывающая функция; -
Если
x1
─ наименьшая варианта, то F*(x)
= 0 при х < х1;
если
хk
─ наибольшая варианта, то F*(x)
= 1 при х > xk.
Итак,
эмпирическая функция распределения
выборки служит для оценки теоретической
функции распределения генеральной
совокупности.
Пример.
Построить эмпирическую функцию по
данному распределению выборки:
|
Варианты |
2 |
6 |
10 |
|
Частоты |
12 |
18 |
30 |
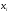
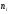
Решение.
Найдем объем выборки (сумма всех частот
ni):
n
= n1
+ n1
+ n1
= 12 + 18 + 30 = 60.
Наименьшая
варианта равна 2 (x1
= 2), следовательно, F*(x)
= 0 при х ≤ 2 (по свойству 3 функции F*(x));
значения,
меньшие 6 (х<6), а именно x1
= 2, наблюдались n1
= 12 раз, следовательно,
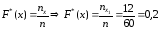 при 2<x≤6;
при 2<x≤6;
значения
х<10, а именно x1
= 2, x1
= 2 наблюдались n1
+ n2
= 12 + 18 = 30 раз, следовательно
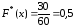 при 6<х≤10.
при 6<х≤10.
Так
как х =10 – наибольшая варианта, то F*(x)
= 1 при х>10 (по свойству 4 функции F*(x)).
Искомая
эмпирическая функция имеет вид:

Ниже приведен график
полученной эмпирической функции.
На графике на
соответствующих осях откладывают
значения функции F*(x)
и интервалы вариант
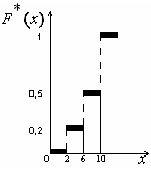
Рис.
5. График эмпирической функции.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание:
- Интервальное статистическое распределение выборки и его числовые характеристики
- Двумерное статистическое распределение выборки и его числовые характеристики
- Условное статистическое распределение и их числовые характеристики
- Корреляционный момент, выборочный коэффициент корреляции
- Четное статистическое распределения выборки и его числовые характеристики
Количественные характеристики элементов генеральной совокупности могут быть одномерными и многомерными, дискретными и непрерывными.
Когда реализуется выборка, количественный признак, например  приобретает конкретное числовое значение
приобретает конкретное числовое значение  которое называют вариантой.
которое называют вариантой.
Возрастающий числовой ряд вариант называют вариационным.
Каждая варианта выборки может быть наблюденной  если
если  число
число  частотой варианты
частотой варианты  .
.
При этом

где  — количество вариант, что отличаются числовым значением;
— количество вариант, что отличаются числовым значением;  — объем выборки.
— объем выборки.
Соотношение частоты варианты  к объему выборки называют ее относительной частотой и обозначают через
к объему выборки называют ее относительной частотой и обозначают через  то есть
то есть

Для каждой выборки выполняется равенство

если исследуется признак генеральной совокупности  которая будет непрерывной, то вариант будет много. В этом случае, вариационный ряд — это определенное количество равных или неравных частичных интервалов или групп вариант со своими частотами.
которая будет непрерывной, то вариант будет много. В этом случае, вариационный ряд — это определенное количество равных или неравных частичных интервалов или групп вариант со своими частотами.
Такие частичные интервалы вариант, которые размещены в возрастающей последовательности, образуют интервальный вариационный ряд.
На практике для удобства, как правило, рассматривают интервальные вариационные ряды, в которых интервалы являются равными между собой.
2. Дискретное статистическое распределение выборки и ее числовые характеристики.
Перечень вариант вариационного ряда и соответственных им частот, или относительных частот, называют дискретным статистическим распределением выборки.
В табличной форме можно представить так:

Дискретное статистическое распределение выборки можно представить эмпирической функцией  .
.
Эмпирическая функция  и ее свойства. Функция аргумента
и ее свойства. Функция аргумента  что обозначает относительную частоту события
что обозначает относительную частоту события  то есть
то есть

называется эмпирической.
Тут  — объем выборки;
— объем выборки;  — количество вариант статистического распределения выборки значения которых меньше фиксированной варианты
— количество вариант статистического распределения выборки значения которых меньше фиксированной варианты 
— называют еще функцией накопления относительных частот.
Свойства 

 где
где  является наименьшей вариантой вариационного ряда;
является наименьшей вариантой вариационного ряда;
 где
где  является наименьшей вариантой вариационного ряда;
является наименьшей вариантой вариационного ряда;
 является не спадающей функцией аргумента
является не спадающей функцией аргумента  а именно:
а именно:  при
при 
Полигон частот и относительных частот. Дискретное статистическое распределения выборки можно изобразить графически в виде ломанной линии, отрезки которой образуют координаты точек  или
или 
В первом случае ломанную линию называют полигоном частот, а во втором — полигоном относительных частот.
Пример. По заданному дискретному статистическому распределению выборки

нужно:
1. Построить  и изобразить ее графически;
и изобразить ее графически;
2. Начертить полигоны частот и относительных частот.
Решение. Согласно с определением и свойствам  имеет такой вид:
имеет такой вид:

Графическое изображение предоставлено на рис. 106.

Полигоны частот и относительных частот изображены на рис. 107, 108.


Числовые характеристики:
1) выборочная средняя величина  Величину, которая обозначается формулой
Величину, которая обозначается формулой

называют выборочной средней величиной дискретного статического распределения выборки.
Тут  — варианта вариационного ряда выборки;
— варианта вариационного ряда выборки;
 — частота этой выборки
— частота этой выборки
 — объем выборки
— объем выборки 
Если все варианты выявляются в выборке только по одному разу, то есть  то
то

2) отклонение вариант. Разницу  называют отклонением этих вариант.
называют отклонением этих вариант.
При этом

Следует, сумма отклонений всех вариант вариационного ряда выборки всегда равна нулю;
3) мода  Модой дискретного статистического распределения выборки называют варианту, что имеет наибольшую частоту появления.
Модой дискретного статистического распределения выборки называют варианту, что имеет наибольшую частоту появления.
Мод может быть несколько. Когда дискретное статистическое распределение имеет одну моду, то оно называется одномодальным. если имеет две моды — двумодальным и так далее.
4) медиана  Модой дискретного статистического распределения выборки называют варианту, которая делит вариационный ряд на две части, равные количеством вариант:
Модой дискретного статистического распределения выборки называют варианту, которая делит вариационный ряд на две части, равные количеством вариант:
5) дисперсия. Для измерения рассеивания вариант выборки относительно  выбирается дисперсия.
выбирается дисперсия.
Дисперсия выборки — это среднее арифметическое квадратов отклонений вариант относительно , которое вычисляется по формуле

или

6) среднее квадратичное отклонение выборки  При вычислении
При вычислении  отклонения приводиться к квадрату, а следует, изменяется единица измерения признака
отклонения приводиться к квадрату, а следует, изменяется единица измерения признака  потому на основании дисперсии приводится среднее квадратичное отклонение
потому на основании дисперсии приводится среднее квадратичное отклонение

которое измеряет рассеивание вариант выборки относительно  то в тех же единицах, в которых изменяется признак
то в тех же единицах, в которых изменяется признак 
7) размах  Для четкой оценки рассеивания вариант относительно
Для четкой оценки рассеивания вариант относительно  используется величина, которая равна разнице между наибольшей
используется величина, которая равна разнице между наибольшей  и наименьшей
и наименьшей  вариантами вариационного ряда. Эта величина называется размахом
вариантами вариационного ряда. Эта величина называется размахом

 коэффициенты вариации
коэффициенты вариации  Для сравнения оценок вариаций статистических рядов с разными значениями
Для сравнения оценок вариаций статистических рядов с разными значениями  которые не равны нулю, приводится коэффициент вариации, который вычисляется по формуле
которые не равны нулю, приводится коэффициент вариации, который вычисляется по формуле

Пример. По заданному статистическому распределению выборки

нужно:
1) вычислить 
2) найти 
3) 
Решение. Поскольку  то согласно с формулами (354), (357), (358) получим:
то согласно с формулами (354), (357), (358) получим:

Для вычисления  обозначается
обозначается

Тогда

Следует, приведенное статистическое распределение выборки будет двумодальным.  поскольку варианта
поскольку варианта  делит вариационный ряд
делит вариационный ряд  на две части:
на две части:  и
и  которые имеют одинаковое количество вариант
которые имеют одинаковое количество вариант

Интервальное статистическое распределение выборки и его числовые характеристики
Перечень долевых интервалов и соответственных им частот, или относительных частот называют интервальным статистическим распределением выборки
В табличной форме это распределение имеет такой вид:

Тут  является длиной частичного
является длиной частичного  — нного интервала. Как правило, этот интервал берется одинаковым.
— нного интервала. Как правило, этот интервал берется одинаковым.
Интервальное статистическое распределение выборки можно преподать графически в виде гистограмм частот или относительных частот, а также, как и для дискретного статистического распределения, эмпирической функцией 
Гистограмма частот и относительных частот. Гистограмма частот — фигура, которая складывается из прямоугольников, каждый из которых имеет основу  и высоту
и высоту 
Гистограмма относительных частот — фигура, которая складывается из прямоугольников, каждый из которых имеет основу длиной и высоту. что равен 
Пример. По заданному интервальному статистическому распределению выборки

нужно построить гистограмму частот и относительных частот
Решение. Гистограммы частот и относительных частот приведены на 

Площадь гистограммы частот 

Площадь гистограммы относительных частот

Эмпирическая функция  . При постройке кумуляты
. При постройке кумуляты  для интервального статистического распределения выборки за основу берется предположение, что признак на каждом частичном интервале имеет равномерную плотность вероятностей. Потому кумулята имеет вид ломанной линии, которая возрастает на каждом частичном интервале и приближается к единице.
для интервального статистического распределения выборки за основу берется предположение, что признак на каждом частичном интервале имеет равномерную плотность вероятностей. Потому кумулята имеет вид ломанной линии, которая возрастает на каждом частичном интервале и приближается к единице.
Пример. По заданному интервальному статистическому распределению выборки

построить  и предоставить ее графически.
и предоставить ее графически.
Решение

график изображен на рис. 111.

Аналогом эмпирической функции в теории вероятностей будет интегральная функция 
Медана. Для обозначения медианы интервального статистического распределения выборки необходимо обозначить медианный частичны интервал. Если, например, на  — нном интервале
— нном интервале  и
и  то обратим внимание, что исследование признака
то обратим внимание, что исследование признака  является непрерывной и при этом является не спадающей функцией, на середине интервала
является непрерывной и при этом является не спадающей функцией, на середине интервала  обязательно существует такое значение
обязательно существует такое значение  где
где 

Из признаков подобности треугольников  и
и  изображенных на рис. 112, получим:
изображенных на рис. 112, получим:

где  называют шагом.
называют шагом.
Мода. Для определения моды интервального статистического распределения необходимо найти модальный интервал, то есть такой частичный интервал, что имеет наибольшую частоту появления.
Используя линейную интерполяцию, моду вычислим по формуле

где  — начало модального интервала;
— начало модального интервала;
 — длина или шаг частичного интервала;
— длина или шаг частичного интервала;
 — частота модального интервала;
— частота модального интервала;
 — частота домодального интервала;
— частота домодального интервала;
 частота послемодального интервала;
частота послемодального интервала;
Пример. По заданному интервальному статистическому распределению выборки

построить гистограмму частот и 
Обозначим 
Решение. Гистограмма частот изображена на рис. 113.

График  изображен на рис. 114
изображен на рис. 114
 Из рис. 113 обозначается модальный интервал, который равен
Из рис. 113 обозначается модальный интервал, который равен  Используя
Используя  и обратив на внимание, что
и обратив на внимание, что 
 получим
получим

Следует, 
Из графика  обозначается медианный интеграл, который равен
обозначается медианный интеграл, который равен 
Обратим внимание, что  и используя (361), получим:
и используя (361), получим:

Следует, 
 для интервального статистического распределения выборки. Для обозначения
для интервального статистического распределения выборки. Для обозначения  перейдем от интервального распределение к дискретному, вариантами которого будет середина частичных интервалов
перейдем от интервального распределение к дискретному, вариантами которого будет середина частичных интервалов  и который имеет вид:
и который имеет вид:

Тогда вычисляется по формуле:

Пример. По заданному интервальному статистическому распределению выборки, в котором приведено распределение массы новорожденных 

вычислить 
Решение. Построим дискретное статистическое распределение к заданным интервальным. Поскольку  то получим:
то получим:

Обращая внимание на  и то, что
и то, что  получим:
получим:

Следует, 

Следует, 
Двумерное статистическое распределение выборки и его числовые характеристики
Перечень вариант  и соответственных им частот
и соответственных им частот  совместного их появления образуют двумерное статистическое распределение выборки, что реализована из генеральной совокупности, элементам этой выборки присущие количественные признаки
совместного их появления образуют двумерное статистическое распределение выборки, что реализована из генеральной совокупности, элементам этой выборки присущие количественные признаки  и
и 
В табличной форме это распределение имеет такой вид:

Тут  — частота совместного появления вариант
— частота совместного появления вариант

Общие числовые характеристики признака 
общая средняя величина признака 

общая дисперсия признака

общие среднее квадратичное отклонение признака

Общие числовые характеристики признака 
общая средняя величина признака  :
:

общая дисперсия признака :

общее среднее квадратичное отклонение признака :

Условное статистическое распределение и их числовые характеристики
Условным статистическим распределением признака при фиксированном значении  называют пересечение вариант признака и соответственных им частот, взятых при фиксированном значении .
называют пересечение вариант признака и соответственных им частот, взятых при фиксированном значении .


Тут 
Числовые характеристики для такого статистического распределения называют условными. К ним принадлежат: условный средний признак

условная дисперсия признака

условное среднее квадратичное отклонение признака :

 измеряют рассеивание вариант признака относительно средней величины
измеряют рассеивание вариант признака относительно средней величины 
Условным статистическим распределением признака  при
при  называют пересечение вариант
называют пересечение вариант  и соответственных им частот, взятых при фиксированном значении признака
и соответственных им частот, взятых при фиксированном значении признака

Тут 
Условные числовые характеристики для этого распределения: условная средняя величина признака 

условная дисперсия признака

условное среднее квадратичное отклонение признака

При известных значениях условных средних  общие средние признаки и вычислить по формулам:
общие средние признаки и вычислить по формулам:

Корреляционный момент, выборочный коэффициент корреляции
Во время исследования двумерного статистического распределения выборки предстает потребность использовать наглядность связи между признаками и , какой в статистике называют корреляционным. Для этого вычисляется эмпирический корреляционный момент  по формуле
по формуле

Если  то корреляционная связь между признаками и нет. Если же
то корреляционная связь между признаками и нет. Если же  то эта связь существует.
то эта связь существует.
Следует, корреляционный момент дает только ответ на вопросы: существует связь между признаками и или нет.
Для измерения тесноты корреляционной связи вычисляется выборочный коэффициент корреляции  по формуле
по формуле

как и в теории вероятностей 
Пример. По заданному двумерному статистическому распределению выборки признаки и

нужно:
1) вычислить 
2) построить условно статистические распределения 
 и вычислить условные числовые характеристики.
и вычислить условные числовые характеристики.
Решение. 1) Чтобы вычислить обозначим 
Поскольку  то
то

Следует, 

Следует, 

для обозначения  вычисляют
вычисляют

Тогда

Следует,  а это свидетельствует о том, что между признаками и существует отрицательная корреляционная связь.
а это свидетельствует о том, что между признаками и существует отрицательная корреляционная связь.
Для измерения тесноты этой связи вычислим выборочный коэффициент корреляции

Следует,  то есть теснота корреляционной связи между признаками и является слабой.
то есть теснота корреляционной связи между признаками и является слабой.
Условное статистическое распределение  имеет такой вид:
имеет такой вид:

Вычисляют условные числовые характеристики для этого распределения:
Условная средняя величина

Условная дисперсия и среднее квадратичное отклонение
 Следует,
Следует, 
Условное статистическое распределение  имеет такой вид:
имеет такой вид:

Вычисляются условные числовые характеристики.
Условная средняя величина

Следует, 
Условная дисперсия и среднее квадратичное отклонение

Следует, 
Четное статистическое распределения выборки и его числовые характеристики
Если частота общего появления признака и  для всех вариант, то в этом случае двумерное статистическое распределение приобретает такой вид:
для всех вариант, то в этом случае двумерное статистическое распределение приобретает такой вид:

его называют четным статистическим распределением выборки. Тут каждая пара значений признаков и выявляется только один раз.
Объем выборки в этом случае равен количеству пар, то есть 
Числовые характеристики признака :
средняя величина

дисперсия

среднее квадратичное отклонение

Числовые характеристики признака :
средняя величина

дисперсия

среднее квадратичное отклонение

эмпирический корреляционный момент

выборочный коэффициент корреляции

Пример. Зависимость количества масла  что использует определенная особь за месяц, от ее прибыли в рублях
что использует определенная особь за месяц, от ее прибыли в рублях  приведена в таблице
приведена в таблице

Нужно вычислить 
Решение. Поскольку объем выборки  то получим:
то получим:

Следует 


Поскольку значение  близко к единице, то отсюда получается, что зависимость между количеством масла, использованного определенной особой, и ее месячной прибылью почти функциональная.
близко к единице, то отсюда получается, что зависимость между количеством масла, использованного определенной особой, и ее месячной прибылью почти функциональная.
6. Эмпирические моменты
Начальные эмпирические моменты. Среднее взвешенное значение вариант в степени  называют начальным эмпирическим моментом
называют начальным эмпирическим моментом  — ого порядка
— ого порядка  который вычисляется по формуле
который вычисляется по формуле

При  получим начальный момент первого порядка:
получим начальный момент первого порядка:

При  вычислим начальный момент второго порядка:
вычислим начальный момент второго порядка:

Следует, дисперсию выборки можно преподать через начальные моменты первого и второго порядков, а именно:

Центральный эмпирический момент  — ого порядка. Среднее взвешенное отклонение вариант в степени
— ого порядка. Среднее взвешенное отклонение вариант в степени  называют центральным эмпирическом моментом
называют центральным эмпирическом моментом  — ого порядка
— ого порядка

При получим:

При получим:

На практике чаще используются центральные эмпирические моменты третьего и четвертого порядков, что вычисляются по формулам:

Преподнося к третьему и четвертому степени отклонения вариант, придадим  и
и  через соответственные начальные моменты:
через соответственные начальные моменты:

Коэффициент асимметрии  Центральный эмпирический момент третьего порядка используется для вычисления коэффициента асимметрии:
Центральный эмпирический момент третьего порядка используется для вычисления коэффициента асимметрии:

Если варианты статистического распределения выборки симметрично распределены относительно  то в этом случае
то в этом случае  поскольку
поскольку 
При  варианты статистического распределения
варианты статистического распределения  преобладают варианты
преобладают варианты  Такую асимметрию называют отрицательной. При
Такую асимметрию называют отрицательной. При  статистического распределения
статистического распределения  преобладают варианты
преобладают варианты  и такую асимметрию называют положительной.
и такую асимметрию называют положительной.
Эксцесс. Центральный эмпиричный момент четвертого порядка используется для вычисления эксцесса:

 как правило, используется при исследовании непрерывности признаков генеральных совокупностей, поскольку он оценивает крутизну закона распределения непрерывной случайной величины уравнена с нормальным. Для нормального закона распределения, как известно,
как правило, используется при исследовании непрерывности признаков генеральных совокупностей, поскольку он оценивает крутизну закона распределения непрерывной случайной величины уравнена с нормальным. Для нормального закона распределения, как известно, 
Пример. Оценить в баллах  полученные абитуриенты на вступительных испытаниях по математике, приведены в таблице дискретного распределения:
полученные абитуриенты на вступительных испытаниях по математике, приведены в таблице дискретного распределения:

Вычислить 
Решение. Используя приведенные выше формулы и учитывая, что  вычислим
вычислим

Откуда 

Следует, получим: 
поскольку  сравнительно малый, то статистическое распределение ближе к симметричному.
сравнительно малый, то статистическое распределение ближе к симметричному.
Пример. Длина заготовок  изготовленных работником за смену, и частоты этих длин
изготовленных работником за смену, и частоты этих длин  приведены в виде статистического распределения:
приведены в виде статистического распределения:

обозначить 
Решение. Вычисляются значения  Поскольку
Поскольку  то получим:
то получим:

Следует, 

Вычислим центральный эмпирический момент четвертого порядка.

Поскольку  то вершина закона распределения случайной величины, заданного плотностью вероятностей, будет плоской, то есть так называемое туповершинное распределение.
то вершина закона распределения случайной величины, заданного плотностью вероятностей, будет плоской, то есть так называемое туповершинное распределение.
Лекции:
- Статистические оценки
- Статистические гипотезы
- Корреляционный и регрессионный анализ
- Комбинаторика основные понятия и формулы с примерами
- Число перестановок
- Непосредственное вычисление вероятностей примеры с решением
- Действия над событиями. Теоремы сложения и умножения вероятностей примеры с решением
- Примеры решения задач на тему: Случайные величины
- Примеры решения задач на тему: основные законы распределения
- Примеры решения задач на тему: совместный закон распределения двух случайных величин
Пусть из генеральной совокупности объема N произведена выборка объема n и пусть изучаемый признак X принял значения x1, x2, …, xn. Наблюдаемые значения xi (i=![]() ) признака X называют вариантами, а последовательность упорядоченных вариант, записанных в неубывающем порядке, называют вариационным рядом. Варианты и вариационный ряд дают одну и ту же информацию об изучаемой случайной величине X, но вариационный ряд упорядочен и по нему легче производить обработку экспериментального материала. Может оказаться, что варианты встречаются по несколько раз: x1 – n1 раз; x2 – n2 раз; …; xk – nk раз. Числа n1, n2, …, nk называют частотами.
) признака X называют вариантами, а последовательность упорядоченных вариант, записанных в неубывающем порядке, называют вариационным рядом. Варианты и вариационный ряд дают одну и ту же информацию об изучаемой случайной величине X, но вариационный ряд упорядочен и по нему легче производить обработку экспериментального материала. Может оказаться, что варианты встречаются по несколько раз: x1 – n1 раз; x2 – n2 раз; …; xk – nk раз. Числа n1, n2, …, nk называют частотами.
Статистическим распределением выборки называется перечень вариант с указанием соответствующих им частот. Статистическое распределение частот выборки записывается в виде таблицы, первая строка которой содержит элементы xi, а вторая – их частоты:
Отношение частоты ni к объему выборки называется относительной частотой или частостью . Частоты и частости называются весами.
Для наглядного представления статистического распределения пользуются графическим изображением (полигоном). Полигоном частот называется ломаная линия, отрезки которой соединяют точки с координатами (xi, ni). Полигоном относительных частот называется ломаная линия, отрезки которой соединяют точки с координатами (xi, wi).
Вариационный ряд называется дискретным, если любые его варианты отличаются на постоянную величину, и – непрерывным (интервальным), если его варианты могут отличаться одна от другой на сколь угодно малую величину. Если объем выборки велик или изучается непрерывный признак X, то интервал, содержащий все варианты выборки, разбивается на k частичных непересекающихся интервалов. Вычисления значительно упрощаются, если частичные интервалы имеют одинаковую длину h (во всем дальнейшем изложении рассматривается именно этот случай). В этом случае статистическое распределение выборки представляется в виде последовательности интервалов и соответствующих им частот
|
интервалы |
x1 – x2 |
x2 – x3 |
… |
xk – xk-1 |
|
частоты |
n1 |
n2 |
… |
nk |
где ni – сумма частот вариант попавших в i-й частичный интервал. Число частичных интервалов m нельзя брать большим, т. к. это значительно усложняет вычисления и нельзя брать малым, т. к. при этом могут быть потеряны индивидуальные свойства изучаемого признака X. Оптимальное число интервалов определяется по формуле Серджеса:
m = 1 + 3.322 lg n ,
где n – объем выборки.
Длина интервала определяется по формуле:
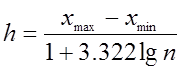 ,
,
где R = xmax – xmin – размах вариации.
За начало первого интервала рекомендуется брать величину
xнач = xmin – ![]() h.
h.
Гистограммой частот (относительных частот) называется ступенчатая фигура состоящая из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высоты равны отношению ![]() — плотность частоты (
— плотность частоты ( ![]() — плотность относительной частоты).
— плотность относительной частоты).
Площадь гистограммы частот равна объему выборки. Площадь гистограммы относительных частот равна единице.
Часто для характеристики вариационного ряда используют накопленные частоты: υi = n1 + n2 + … + ni. Накопленные частоты показывают, сколько единиц совокупности не превышают заданного значения xi признака X. Отношение накопленной частоты к общему числу наблюдений (объему выборки) называется относительной накопленной частотой ![]() или накопленной частостью.
или накопленной частостью.
Кумулятивной кривой (кумулятой) называется ломаная линия, отрезки которой соединяют точки с координатами (xi, ![]() ). Кумулятивной кривой относительных накопленных частот называется ломаная линия, отрезки которой соединяют точки с координатами (xi,
). Кумулятивной кривой относительных накопленных частот называется ломаная линия, отрезки которой соединяют точки с координатами (xi,![]() ).
).
Огивой называется ломаная линия, отрезки которой соединяют точки с координатами (![]() , xi).
, xi).
Выборочной квантилью порядка p называется абсцисса xp точки, лежащей на кумулятивной кривой и имеющей ординату p. Порядок квантили p определяет долю общего числа наблюдений в выборке, результаты которых не превосходят xp. Значения порядка часто задают в процентах.
Эмпирической функцией распределения (функцией распределения выборки) называется функция F*(x), которая для каждого значения x признака X определяет относительную частоту события X < x:
F*(x) = ![]() ,
,
где nx – число вариант, меньших x; n – объем выборки.
В отличие от эмпирической функции распределения выборки F*(x) функция распределения F(x) генеральной совокупности называется теоретической функцией распределения.
При большом объеме выборки числа F*(x) и F(x) принимают близкие значения. Эмпирическая функция распределения обладает всеми свойствами функции F(x):
1) Значения эмпирической функции распределения принадлежат отрезку [0;1];
2) F*(x) – неубывающая функция;
3) Если x1 – наименьшая варианта, а xk — наибольшая, то:
при х ≤ x1, F*(x)=0,
при х > xk, F*(x)=1.
Эмпирическая функция распределения выборки служит для оценки теоретической функции распределения генеральной совокупности.
Пример 1.
Записать в виде вариационного и статистического рядов выборку:
5, 3, 7, 10, 5, 5, 2, 10, 7, 2, 7, 7, 4, 2, 4.
Определить размах вариации. Построить полигон частот, полигон относительных частот.
Решение.
Объем выборки n = 15. Составим вариационный ряд:
2, 2, 2, 3, 4, 4, 5, 5, 5, 7, 7, 7, 7, 10, 10
Запишем статистическое распределение выборки (статистический ряд):
|
xi |
2 |
3 |
4 |
5 |
7 |
10 |
|
ni |
3 |
1 |
2 |
3 |
4 |
2 |
Контроль: Σ ni = 15.
Размах вариации: R = xmax – xmin = 10 – 2 = 8. Построим полигон частот:
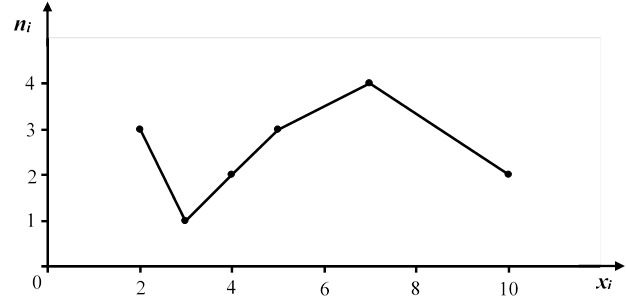 |
Для построения полигона относительных частот составим статистическое распределение относительных частот выборки
|
xi |
2 |
3 |
4 |
5 |
7 |
10 |
|
Wi |
|
|
|
|
|
|
Построим полигон относительных частот:
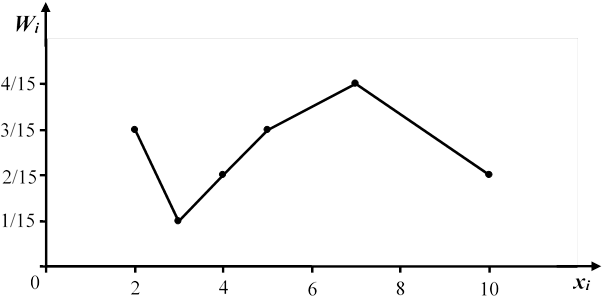 |
Пример 2.
Измерение емкости затвор – сток 80 полевых транзисторов дали следующие результаты:
1,9 3,1 1,3 0,7 3,2 1,1 2,9 2,7 2,7 4,0
1,7 3,2 0,9 0,8 3,1 1,2 2,6 1,9 2,3 3,2
4,1 1,3 2,4 4,5 2,5 0,9 1,4 1,6 2,2 3,1
1,5 1,1 2,3 4,3 2,1 0,7 1,2 1,5 1,8 2,9
0,8 0,9 1,7 4,1 4,3 2,6 0,9 0,8 1,2 2,1
3,2 2,9 1,1 3,2 4,5 2,1 3,1 5,1 1,1 1,9
0,9 3,1 0,9 3,1 3,3 2,8 2,5 4,0 4,3 1,1
2,1 3,8 4,6 3,8 2,3 3,9 2,4 4,1 4,2 0,9
Построить:
1) интервальное распределение частот признака Х;
2) гистограмму частот и относительных частот;
3) полигон частот;
4) кумуляту и огиву;
5) график F*(x).
Решение.
Найдем оптимальное число интервалов:
m = 1 + 3.322∙ lg n = 1 + 3.322∙lg 80 ≈ 1 + 3.322 ∙ 1, 90308 = 7, 31 ≈ 7
Найдем длину частичного интервала:
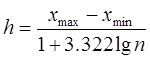 =
= 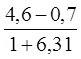 ≈ 0,6 (h = 0.6)
≈ 0,6 (h = 0.6)
Найдем начальную варианту первого частичного интервала:
xнач = xmin – 0,5∙h = 0.7 – 0.5∙0.6 = 0.4.
Составим интервальное статистическое распределение частот выборки, определив предварительную сумму частот вариант в каждом частичном интервале (условимся частоты вариант, расположенные на правом конце частичных интервалов относить в левый интервал). Составим расчетную таблицу, поместив туда плотность частоты ![]() , относительную частоту , плотность относительной частоты
, относительную частоту , плотность относительной частоты ![]() :
:
|
Частичные интервалы |
0,4 – 1,0 |
1,0 – 1,6 |
1,6 – 2,2 |
2,2 – 2,8 |
2,8 – 3,4 |
3,4 – 4,0 |
4,0 –4,6 |
|
Сумма частот |
12 |
14 |
12 |
12 |
14 |
5 |
11 |
|
Плотность частоты |
|
|
|
|
|
|
|
|
Относительная частота
|
|
|
|
|
|
|
|
|
Плотность относительной частоты |
|
|
|
|
|
|
|
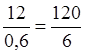
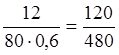
Построим гистограмму частот и гистограмму относительных частот (ось справа):
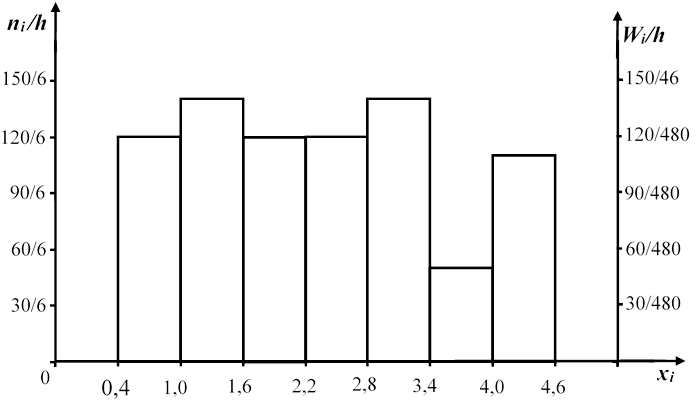 |
Для построения полигона частот (относительных частот) запишем статистическое распределение частот (относительных частот) выборки, для чего возьмем середины частичных интервалов
|
xi |
0,7 |
1,3 |
1,9 |
2,5 |
3,1 |
3,7 |
4,3 |
|
ni |
12 |
14 |
12 |
12 |
14 |
5 |
11 |
|
|
|
|
|
|
|
|
|
Полигон частот и полигон относительных частот (ось справа)
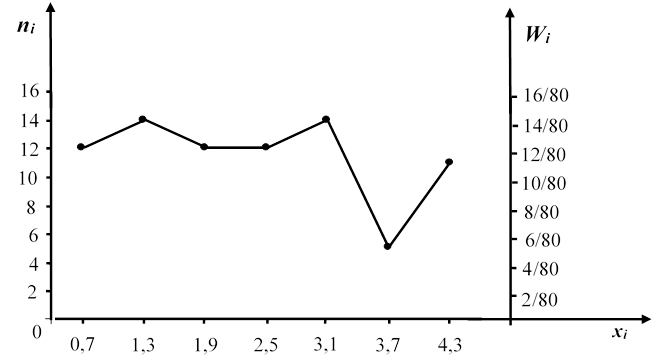
Запишем статистическое распределение накопленных частот υi и относительных накопленных частот ![]() (кумулятивный ряд):
(кумулятивный ряд):
|
xi |
0,7 |
1,3 |
1,9 |
2,5 |
3,1 |
3,7 |
4,3 |
|
υi |
12 |
26 |
38 |
50 |
64 |
69 |
80 |
|
|
|
|
|
|
|
|
|
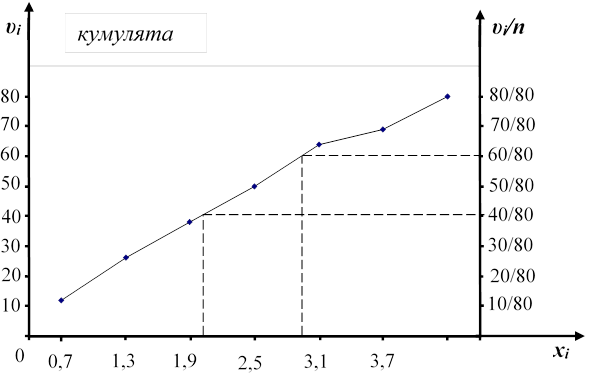
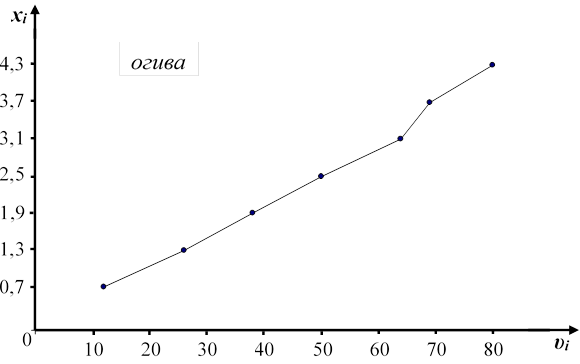 Кумулята и кумулятивная кривая накопленных относительных частот (ось справа)
Кумулята и кумулятивная кривая накопленных относительных частот (ось справа)
Найдем по кумулятивной кривой относительных накопленных частот квантиль порядка 0,5 и 0,75:
x0.5 ≈ 1,92; x0,75 ≈ 2,85.
Найдем эмпирическую функцию распределения F*(x):
1. x ≤ 0,7; F*(x) = ![]() =
= ![]() = 0;
= 0;
2. 0,7 < x ≤1,3; F*(x) = ![]() =
= ![]() ;
;
3. 1,3 < x ≤1,9; F*(x) = ![]() =
= ![]() ;
;
4. 1,9 < x ≤ 2,5; F*(x) = ![]() =
= ![]() ;
;
5. 2,5 < x ≤ 3,1; F*(x) = ![]() =
= ![]() ;
;
6. 3,1 < x ≤ 3,7; F*(x) = ![]() =
= ![]() ;
;
7. 3,7 < x ≤ 4,3; F*(x) = ![]() =
= ![]() ;
;
8. x > 4,3; F*(x) = ![]() = 1
= 1
F*(x)=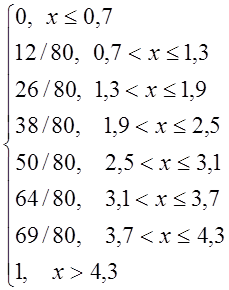
 |
График эмпирической функции распределения
Числовые выборочные характеристики
Пусть изучается дискретная генеральная совокупность относительно количественного признака X объема N.
Если все значения ![]() признака генеральной совокупности объема N различны, то
признака генеральной совокупности объема N различны, то
Определение 1. Генеральной средней ![]() называется среднее арифметическое значений признака генеральной совокупности
называется среднее арифметическое значений признака генеральной совокупности 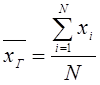 .
.
Если значение признака встречается с некоторой частотой Ni, то 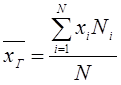 , где N – объем генеральной совокупности.
, где N – объем генеральной совокупности.
Определение 2. Выборочной средней называется среднее арифметическое значений признака X выборочной совокупности (если все значения n различны) или (если значение признака встречается с частотой ni), где n – объем выборочной совокупности.
При увеличении n выборочная средняя сходится по вероятности к генеральной средней: 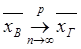 .
.
Определение 3. Групповой средней называется среднее арифметическое значений признака, принадлежащих группе j.
Определение 4. Общей средней называется среднее арифметическое значений признака, принадлежащих всей совокупности, или общая средняя, равная средней арифметической групповых средних, взвешенной по объемам групп.
Определение 5. Генеральной дисперсией называется среднее арифметическое квадратов отклонений значений признака генеральной совокупности от среднего значения (генеральной средней):
или .
Определение 6. Генеральным средним квадратическим отклонением (стандартным) называется корень квадратный из генеральной дисперсии .
Определение 7. Выборочной дисперсией называется среднее арифметическое квадратов отклонений наблюдаемых значений признака от их среднего выборочного значения .