- ознакомиться с технологией построения логической модели в ERWin,
- изучить методы определения ключевых атрибутов сущностей,
- освоить метод проверки адекватности логической модели,
- изучить типы связей между сущностями.
Первым шагом при создании логической модели БД является построение диаграммы ERD (Entity Relationship Diagram). ERD-диаграммы состоят из трех частей: сущностей, атрибутов и взаимосвязей. Сущностями являются существительные, атрибуты — прилагательными или модификаторами, взаимосвязи — глаголами.
ERD-диаграмма позволяет рассмотреть систему целиком и выяснить требования, необходимые для ее разработки, касающиеся хранения информации.
ERD-диаграммы можно подразделить на отдельные куски, соответствующие отдельным задачам, решаемым проектируемой системой. Это позволяет рассматривать систему с точки зрения функциональных возможностей, делая процесс проектирования управляемым.
ERD-диаграммы
Как известно основным компонентом реляционных БД является таблица. Таблица используется для структуризации и хранения информации. В реляционных БД каждая ячейка таблицы содержит одно значение. Кроме того, внутри одной БД существуют взаимосвязи между таблицами, каждая из которых задает совместное пользование данными таблицы.
ERD-диаграмма графически представляет структуру данных проектируемой информационной системы. Сущности отображаются при помощи прямоугольников, содержащих имя. Имена принято выражать существительными в единственном числе, взаимосвязи — при помощи линий, соединяющих отдельные сущности. Взаимосвязь показывает, что данные одной сущности ссылаются или связаны с данными другой.
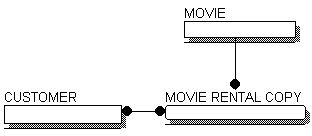
Рис. 6.1. Пример ERD-диаграммы,
Определение сущностей и атрибутов
Сущность — это субъект, место, вещь, событие или понятие, содержащие информацию. Точнее, сущность — это набор (объединение) объектов, называемых экземплярами. В приведенном на рис. 6.1 примере сущность CUSTOMER (клиент) представляет всех возможных клиентов. Каждый экземпляр сущности обладает набором характеристик. Так, каждый клиент может иметь имя, адрес, телефон и т. д. В логической модели все эти характеристики называются атрибутами сущности.
На рис. 6.2 показана ERD-диаграмма, включающая в себя атрибуты сущностей.
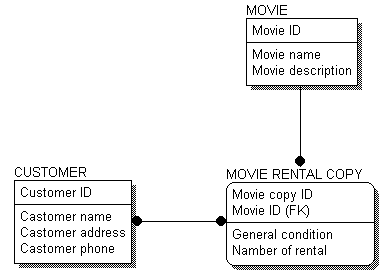
Рис. 6.2. ERD-диаграмма с атрибутами
Логические взаимосвязи
Логические взаимосвязи представляют собой связи между сущностями. Они определяются глаголами, показывающими, как одна сущность относится к другой.
Некоторые примеры взаимосвязей:
- команда включает много игроков,
- самолет перевозит много пассажиров,
- продавец продает много продуктов.
Во всех этих случаях взаимосвязи отражают взаимодействие между двумя сущностями, называемое «один-ко-многим». Это означает, что один экземпляр первой сущности взаимодействует с несколькими экземплярами другой сущности. Взаимосвязи отображаются линиями, соединяющими две сущности с точкой на одном конце и глаголом, располагаемым над линией.
Кроме взаимосвязи «один-ко-многим» существует еще один тип — это «многие-ко-многим». Этот тип связи описывает ситуацию, при которой экземпляры сущностей могут взаимодействовать с несколькими экземплярами других сущностей. Связь «многие-ко-многим» используют на первоначальных стадиях проектирования. Этот тип взаимосвязи отображается сплошной линией с точками на обоих концах.
Связь «многие-ко-многим» может не учитывать определенные ограничения системы, поэтому может быть заменена на «один-ко-многим» при последующем пересмотре проекта.
Проверка адекватности логической модели
Если взаимосвязи между сущностями были правильно установлены, то можно составить предложения, их описывающие. Например, по модели, показанной на рис. 6.3, можно составить следующие предложения:
Самолет перевозит пассажиров. Много пассажиров перевозятся одним самолетом.
Составление таких предложений позволяет проверить соответствие полученной модели требованиям и ограничениям создаваемой системы.
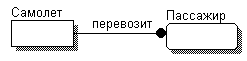
Рис. 6.3. Пример логической модели со взаимосвязью
Модель данных, основанная на ключах
Каждая сущность содержит горизонтальную линию, разделяющую атрибуты на две группы. Атрибуты, расположенные над линией, называются первичным ключом. Первичный ключ предназначен для уникальной идентификации экземпляра сущности.
Выбор первичного ключа
При создании сущности необходимо выделить группу атрибутов, которые потенциально могут стать первичным ключом (потенциальные ключи), затем произвести отбор атрибутов для включения в состав первичного ключа, следуя следующим рекомендациям:
Первичный ключ должен быть подобран таким образом, чтобы по значениям атрибутов, в него включенных, можно было точно идентифицировать экземпляр сущности. Никакой из атрибутов первичного ключа не должен иметь нулевое значение. Значения атрибутов первичного ключа не должны меняться. Если значение изменилось, значит, это уже другой экземпляр сущности.
При выборе первичного ключа можно внести в сущность дополнительный атрибут и сделать его ключом. Так, для определения первичного ключа часто используют уникальные номера, которые могут автоматически генерироваться системой при добавлении экземпляра сущности в БД. Применение уникальных номеров облегчает процесс индексации и поиска в БД.
Первичный ключ, выбранный при создании логической модели, может быть неудачным для осуществления эффективного доступа к БД и должен быть изменен при проектировании физической модели.
Потенциальный ключ, не ставший первичным, называется альтернативным ключом (Alternate Key). ERWin позволяет выделить атрибуты альтернативных ключей, и по умолчанию в дальнейшем при генерации схемы БД по этим атрибутам будет генерироваться уникальный индекс. При создании альтернативного ключа на диаграмме рядом с атрибутом появляются символы (АК).
Атрибуты, участвующие в неуникальных индексах, называются инверсионными входами (Inversion Entries). Инверсионные входы — это атрибут или группа атрибутов, которые не определяют экземпляр уникальным образом, но часто используются для обращения к экземплярам сущности. ERWin генерирует неуникальный индекс для каждого инверсионного входа.
При проведении связи между двумя сущностями в дочерней сущности автоматически образуются внешние ключи (foreign key). Связь образует ссылку на атрибуты первичного ключа в дочерней сущности, и эти атрибуты образуют внешний ключ в дочерней сущности. Атрибуты внешнего ключа обозначаются символами (FK) после своего имени.
Пример
Рассмотрим процесс построения логической модели на примере БД студентов системы «Служба занятости в рамках вуза». Первым этапом является определение сущностей и атрибутов. В БД будут храниться записи о студентах, следовательно, сущностью будет студент.
Таблица 6.1. Атрибуты сущности «Студент»
| Атрибут | Описание |
| Номер | Уникальный номер для идентификации пользователя |
| Ф.И.О. | Фамилия, имя и отчество пользователя |
| Пароль | Пароль для доступа в систему |
| Возраст | Возраст студента |
| Пол | Пол студента |
| Характеристика | Memo-поле с общей характеристикой пользователя |
| Адреса электронной почты | |
| Телефон | Номера телефонов студента (домашний, рабочий) |
| Опыт работы | Специальности и опыт работы студента по каждой из них |
| Специальность | Специальность, получаемая студентом при окончании учебного заведения |
| Специализация | Направление специальности, по которому обучается студент |
| Иностранный язык | Список иностранных языков и уровень владения ими |
| Тестирование | Список тестов и отметки о их прохождении |
| Экспертная оценка | Список предметов с экспертными оценками по каждому из них |
| Оценки по экзаменам | Список сданных предметов с оценками |
В полученном списке существуют атрибуты, которые нельзя определить в виде одного поля БД. Такие атрибуты требуют дополнительных определений и должны рассматриваться как сущности, состоящие, в свою очередь, из атрибутов. К таковым относятся: опыт работы, иностранный язык, тестирование, экспертная оценка, оценки по экзаменам. Определим их атрибуты.
Таблица 6.2. Атрибуты сущности «Опыт работы»
|
Атрибут |
Описание |
| Специальность | Название специальности, по которой у студента есть опыт работы |
| Опыт | Опыт работы по данной специальности в годах |
| Место работы | Наименование предприятия, где приобретался опыт |
Таблица 6.3. Атрибуты сущности «Иностранный язык»
| Атрибут | Описание |
| Язык | Название иностранного языка, которым владеет студент |
| Уровень владения | Численная оценка уровня владения иностранным языком |
Таблица 6.4. Атрибуты сущности «Тестирование»
| Атрибут | Описание |
| Название | Название теста, который прошел студент |
| Описание | Содержит краткое описание теста |
| Оценка | Оценка, которую получил студент в результате прохождения теста |
Таблица 6.5. Атрибуты сущности «Экспертная оценка»
| Атрибут | Описание |
| Дисциплина | Наименование дисциплины, по которой оценивался студент |
| Ф.И.О. преподавателя | Ф.И.О. преподавателя, который оценивал студента |
| Оценка | Экспертная оценку преподавателя |
| Атрибут | Описание |
| Предмет | Название предмета, экзамен по которому сдавался |
| Оценка | Полученная оценка |
Составим ERD-диаграмму, определяя типы атрибутов и проставляя связи между сущностями (рис. 6.4). Все сущности будут зависимыми от сущности «Студент». Связи будут типа «один-ко-многим».
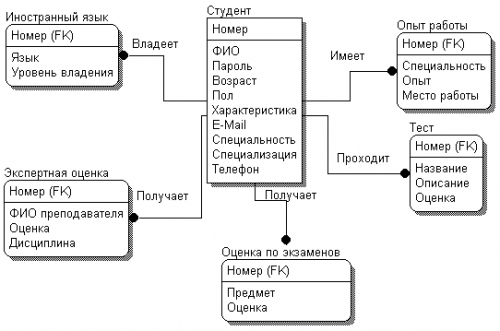
Рис. 6.4. ERD-диаграмма БД студентов
На полученной диаграмме рядом со связью отражается ее имя, показывающее соотношение между сущностями. При проведении связи между сущностями первичный ключ мигрирует в дочернюю сущность.
Следующим этапом при построении логической модели является определение ключевых атрибутов и типов атрибутов.
Таблица 6.7. Типы атрибутов
| Атрибут | Тип |
|
Номер |
Number |
|
Ф.И.О. |
String |
|
Пароль |
String |
|
Возраст |
Number |
|
Атрибут |
Тип |
|
Пол |
String |
|
Характеристика |
String |
|
|
String |
|
Специальность |
String |
|
Специализация |
String |
|
Опыт |
Number |
|
Место работы |
String |
|
Язык |
String |
|
Уровень владения |
Number |
|
Название |
String |
|
Описание |
String |
|
Оценка |
Number |
|
Дисциплина |
String |
|
Ф.И.О. преподавателя |
String |
|
Предмет |
String |
Выберем для каждой сущности ключевые атрибуты, однозначно определяющие сущность. Для сущности «Студент» это будет уникальный номер, для сущности «Опыт работы» все поля являются ключевыми, так как по разным специальностям студент может иметь разный опыт работы в разных фирмах. Сущность «Тест» определяется названием, так как студент по одному тесту может иметь только одну оценку. Оценка по экзамену определяется только названием предмета, экспертная оценка зависит от преподавателя, который ее составил, поэтому в качестве ключевых атрибутов выберем «Дисциплину» и «Ф.И.О. преподавателя». У сущности «Иностранный язык» уровень владения зависит только от наименования языка, следовательно, это и будет являться ключевым атрибутом.
Получим новую диаграмму, изображенную на рис. 6.5, где все ключевые атрибуты будут находиться над горизонтальной чертой внутри рамки, изображающей сущность.
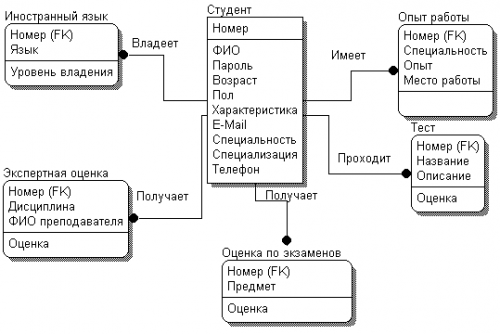
Рис. 6.5. ERD-диаграмма БД студентов с ключевыми атрибутами
Контрольные вопросы
- Назовите основные части ERD-диаграммы.
- Цель ERD-диаграммы.
- Что является основным компонентом реляционных БД?
- Что называется сущностью?
- Сформулируйте принцип именования сущностей.
- Что показывает взаимосвязь между сущностями?
- Назовите типы логических взаимосвязей.
- Каким образом отображаются логические взаимосвязи?
- Опишите механизм проверки адекватности логической модели.
- Что называется первичным ключом?
- Назовите принципы, согласно которым формируется первичный ключ.
- Что называется альтернативным ключом?
- Что называется инверсионным входом?
- В каком случае образуются внешние ключи?
Содержание отчета
- Тема, цель работы.
- ERD-диаграмма БД Служба занятости с атрибутами и ключами.
- Выводы по работе
Моделирование данных: обзор
Время на прочтение
5 мин
Количество просмотров 46K
В работе мы с коллегами часто видим как компании сталкиваются с проблемой управления данными – когда таблиц и запросов становится сильно много и управлять всем этим очень сложно. В таких ситуациях мы рекомендуем моделировать данные. Чтобы разобраться, что это такое – я перевела статью-обзор про моделирование данных от Towards Data Science, в которой кроме основных терминов и понятий можно найти наглядный пример использования моделирования данных в ритейле. Вперед под кат!
Если вы посмотрите на любое программное приложение, то увидите, что на фундаментальном уровне оно занимается организацией, обработкой и представлением данных для выполнения бизнес-требований.
Модель данных — это концептуальное представление для выражения и передачи бизнес-требований. Она наглядно показывает характер данных, бизнес-правила, управляющие данными, и то, как данные будут организованы в базе данных.
Моделирование данных можно сравнить со строительством дома. Допустим, компании ABC необходимо построить дом для гостей (база данных). Компания вызывает архитектора (разработчик моделей данных) и объясняет требования к зданию (бизнес-требования). Архитектор (модельер данных) разрабатывает план (модель данных) и передает его компании ABC. Наконец, компания ABC вызывает инженеров-строителей (администраторов баз данных и разработчиков баз данных) для строительства дома.
Ключевые термины в моделировании данных
Сущности и атрибуты. Сущности — это «вещи» в бизнес-среде, о которых мы хотим хранить данные, например, продукты, клиенты, заказы и т.д. Атрибуты используются для организации и структурирования данных. Например, нам необходимо хранить определенную информацию о продаваемых нами продуктах, такую как отпускная цена или доступное количество. Эти фрагменты данных являются атрибутами сущности Product. Сущности обычно представляют собой таблицы базы данных, а атрибуты — столбцы этих таблиц.
Взаимосвязь. Взаимосвязь между сущностями описывает, как одна сущность связана с другой. В модели данных сущности могут быть связаны как: «один к одному», «многие к одному» или «многие ко многим».
Сущность пересечения. Если между сущностями есть связь типа «многие ко многим», то можно использовать сущность пересечения, чтобы декомпозировать эту связь и привести ее к типу «многие к одному» и «один ко многим».
Простой пример: есть 2 сущности — телешоу и человек. Каждое телешоу может смотреть один или несколько человек, в то время как человек может смотреть одно или несколько телешоу.

Эту проблему можно решить, введя новую пересекающуюся сущность «Просмотр записи»:

ER диаграмма показывает сущности и отношения между ними. ER-диаграмма может принимать форму концептуальной модели данных, логической модели данных или физической модели данных.
Концептуальная модель данных включает в себя все основные сущности и связи, не содержит подробных сведений об атрибутах и часто используется на начальном этапе планирования. Пример:

Логическая модель данных — это расширение концептуальной модели данных. Она включает в себя все сущности, атрибуты, ключи и взаимосвязи, которые представляют бизнес-информацию и определяют бизнес-правила. Пример:

Физическая модель данных включает в себя все необходимые таблицы, столбцы, связи, свойства базы данных для физической реализации баз данных. Производительность базы данных, стратегия индексации, физическое хранилище и денормализация — важные параметры физической модели. Пример:

Основные этапы моделирования данных:

Реляционное vs размерное моделирование
В зависимости от бизнес-требований ваша модель данных может быть реляционной или размерной. Реляционная модель — это метод проектирования, направленный на устранение избыточности данных. Данные делятся на множество дискретных сущностей, каждая из которых становится таблицей в реляционной базе данных. Таблицы обычно нормализованы до 3-й нормальной формы. В OLTP приложениях используется эта методология.
В размерной модели данные денормализованы для повышения производительности. Здесь данные разделены на измерения и факты и упорядочены таким образом, чтобы пользователю было легче извлекать информацию и создавать отчеты.
Кейс
Компания ABC имеет 200 продуктовых магазинов в восьми городах. В каждом магазине есть разные отделы, такие как «Товары повседневного спроса», «Косметика», «Замороженные продукты», «Молочные продукты» и т.д. В каждом магазине на полках находится около 20 000 отдельных товаров. Отдельные продукты называются складскими единицами (SKU). Около 6 000 артикулов поступают от сторонних производителей и имеют штрих-коды, нанесенные на упаковку продукта. Эти штрих-коды называются универсальными кодами продукта (UPC). Данные собираются POS-системой в 2 местах: у входной двери для покупателей, и у задней двери, где поставщики осуществляют доставку.
В продуктовом магазине менеджмент занимается логистикой заказа, хранением и продажами продуктов. Также продолжают расти рекламные активности, такие как временные скидки, реклама в газетах и т.д.
Разработайте модель данных для анализа операций этой продуктовой сети.
Решение
Шаг 1. Сбор бизнес-требований
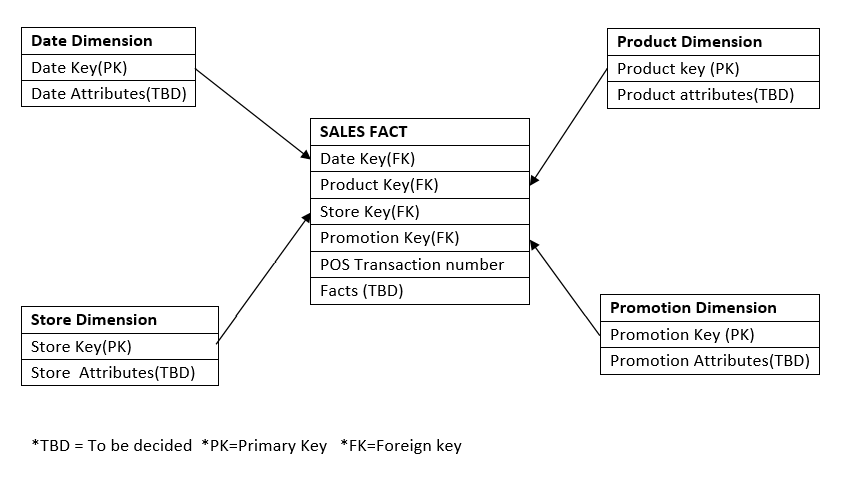
Руководство хочет лучше понимать покупки клиентов, фиксируемые POS-системой. Модель должна позволять анализировать, какие товары продаются, в каких магазинах, в какие дни и по каким акционным условиям. Кроме того, это складская среда, поэтому необходима размерная модель.
Шаг 2: Идентификация сущностей
В случае размерной модели нам необходимо идентифицировать наши факты и измерения. Перед разработкой модели необходимо уточнить объем требуемых данных. Согласно требованию, нам нужно видеть данные о конкретном продукте в определенном магазине в определенный день по определенной схеме продвижения. Это дает нам представление о необходимых сущностях:
-
Date Dimension
-
Product Dimension
-
Store Dimension
-
Promotion Dimension
Количество, которое необходимо рассчитать (например, объем продаж, прибыль и т.д), будет отражено в таблице с фактическими продажами.
Шаг 3: Концептуальная модель данных
Предварительная модель данных будет создана на основе информации, собранной о сущностях. В нашем случае она будет выглядеть так:
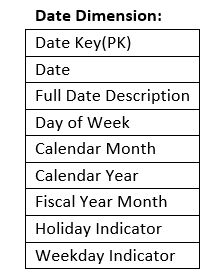
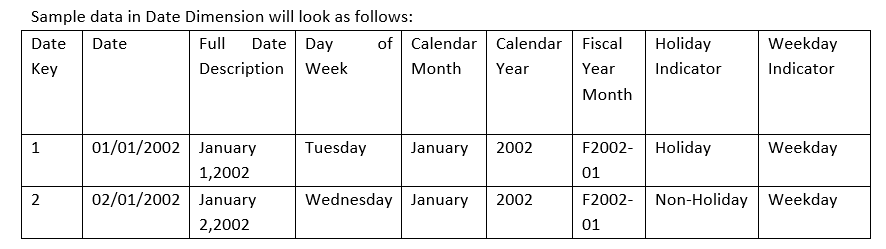
Шаг 4: Доработка атрибутов и создание логической модели данных
Теперь необходимо завершить работу над атрибутами для сущностей. В нашем случае дорабатываются следующие атрибуты:
Date Dimension:
Product:

Store:

Promotion:

Sales Fact:
-
Номер транзакции.
-
Объем продаж (например, количество банок овощного супа с лапшой).
-
Сумма продаж в долларах: количество продаж * цена за единицу.
-
Стоимость в долларах: стоимость продукта, взимаемая поставщиком.
-
Сумма валовой прибыли в долларах: доход от продаж — затраты.
Логическая модель данных будет выглядеть так:

Шаг 5: Создание физических таблиц в базе данных
С помощью инструмента моделирования данных или с помощью кастомных скриптов теперь можно создавать физические таблицы в базе данных.
Думаю, теперь стало достаточно очевидно, что моделирование данных — одна из важнейших задач при разработке программного приложения. И оно закладывает основу для организации, хранения, извлечения и представления данных.
Постановка задачи
Результатом выполнения лабораторной работы должен быть файл содержащий
следующие основные части:
-
Описание предметной области.
-
Инфологическая (Концептуальная) модель базы данных для выбранной
предметной области. -
Логическая модель базы данных для выбранной предметной области.
Построение концептуальной модели базы данных
В качестве предметной области для примера выберем объекты киноиндустрии.
Основные сущности это произведение киноиндустрии(фильм, сериал и т.д.) и
деятель киноиндустрии (актер, режиссер, директор). В качестве основных
атрибутов произведения можем выделить:
-
titleID — буквенно-цифровой уникальный идентификатор заголовка.
-
titleType – формат заголовка (например, фильм, короткометражка,
сериал, твизод, видео и т.д.). -
primaryTitle – более популярное название / название,
используемое создателями фильма в рекламных материалах
на момент выпуска. -
originalTitle — оригинальное название, на языке оригинала.
-
isAdult — запрещено к просмотру лицам не достигшим
совершеннолетия. -
startYear – год выпуска.
-
runtimeMinutes – длительность произведения в минутах.
-
posterURL — URL постера.
-
plot — сюжет.
Введем cущностью рейтинг произведения со следующими атрибутами:
-
ratingID — буквенно-цифровой уникальный идентификатор рейтинга
-
averageRating — средний рейтинг произведения.
-
numVotes — количество голосов которые получил фильм.
-
ratingType — тип рейтинга (IMDB, Metacritic и т.д.)
Каждое произведение имеет 1 ко многим связь с сущностью рейтинг. Так как
у одного произведения может быть множество рейтингов.
Каждое произведение имеет 1 ко многим связь с сущностью жанр со
следующими атрибутами:
-
genreID — буквенно-цифровой уникальный идентификатор жанра
-
genreType — тип жанра (драма, комедия и т.д.)
Если произведение киноинудстрии является сериалом имеет смысл ввести
сущность эпизод. Имеющую следующие атрибуты:
-
titleID — идентификатор серии сериала.
-
parentTitleID — буквенно-цифровой идентификатор сериала к
которому относится эпизод. -
seasonNumber — номер сезона.
-
episodeNumber — номер серии в сезоне.
Связь произведения с сущностью эпизод будет 1 ко многим. Так как у
одного сериала может быть множество эпизодов.
Перейдем к сущности деятеля киноидустрии. В качестве основых атрибутов
можем выделить:
-
nameID — буквенно-цифровой уникальный идентификатор деятеля
киноинудстрии. -
primaryName — имя, под которым деятель упоминается в
произведениях. -
birthYear — дата рождения.
-
deathYear — дата смерти.
У каждого деятеля киноидустрии есть список профессий (режиссер,
директор, актер и т.д.) вынесем это в отдельную сущность
профессия имеющую атрибуты:
-
professionID — буквенно-цифровой уникальный идентификатор
профессии. -
jobType — тип профессии (режиссер, директор, актер и т.д.).
Связь между деятелем киноидустрии и профессией будет один ко многим. Так
как у одного деятеля киноиндустрии может быть множество профессий. И
наоборот может быть множество деятелей киноиндустрии с одинаковой
профессией.
Для связи между произведением киноидустрии, деятелем киноидустрии и
профессией введем дополнительную сущность участник съемочной
группы.
Связь между произведением киноиндустрии и участником съемочной группы
будет 1 ко многим, так как у произведения киноиндустрии может быть
множество участников съемочной группы.
Связь между деятелем киноиндустрии и участником съемочной группы будет 1
ко многим, так как деятель киноиндустрии мог принимать участние в
нескольких произведениях.
Связь между профессией и участником съемочной группы будет 1 ко многим,
так как одну и ту же должность занимали множество участников съемочной
группы.

Логическая модель базы данных
При построение логичекой модели данных связи многие ко многим
реализуются при помощи промежуточной(связывающей) таблицы.
Для разрещения связей многие ко многим между сущностями произведение
киноиндустрии и участник съемочной группы введем промежуточную
таблицу KnownForTitle.
Для разрешение связей многие ко многим между профессией и деятелем
киноидустрии введем промежуточную таблицу NameProfessions.

Используемые источники
-
https://habr.com/ru/post/254773/ (Статья про нормализацию)
-
https://www.intuit.ru/studies/courses/1095/191/lecture/4983?page=5
(Промежуточная таблица для связи многие ко многим)
Лабораторная работа № 2. Логическая
модель базы данных
Логическая модель –
графическое представление структуры
базы данных с учетом принимаемой модели
данных (иерархической, сетевой, реляционной
и т.д.), независимое от конечной реализации
базы данных и аппаратной платформы.
Иными словами, она показывает,
ЧТО хранится в базе данных (объекты
предметной области, их атрибуты и связи
между ними), но не отвечает
на вопрос КАК (рис. 1).
Описание предметной
области:
Оптовый заводской
склад
На склад поставляются детали, выполненные
из определенных материалов
(литые), от заданного круга поставщиков
(постоянных или случайных) из различных
городов.
В качестве поставщиков могут выступать
юридические лица и индивидуальные
предприниматели, причем эти группы
описываются своим набором характеризующих
атрибутов; юридические лица – номер и
дата гос. регистрации, наименование,
юридический адрес, форма собственности;
предприниматели – ИНН, ФИО, страховой
полис, номер паспорта, дата рождения.
При оформлении поставки учитываются
дата, количество и стоимость, вид упаковки
и способ доставки (автотранспорт, ж/д
транспорт, самовывоз), причем одна
поставка может включать несколько видов
деталей.
Поставщики переходят в разряд постоянных,
если они совершили поставок на сумму
свыше 1 000 000
рублей в год.
Осуществляется отпуск деталей в цеха
завода с учетом даты, количества и номера
цеха. Поддерживается актуальное
количество товаров на складе.
|
Таблица |
|
|
Роль |
Функции |
|
Менеджер |
Ведение базы |
|
Инженер завода |
Просмотр |
|
Бухгалтер |
Оплата поставок |
|
Учетчик |
Оформление |
|
Логист |
Управление |
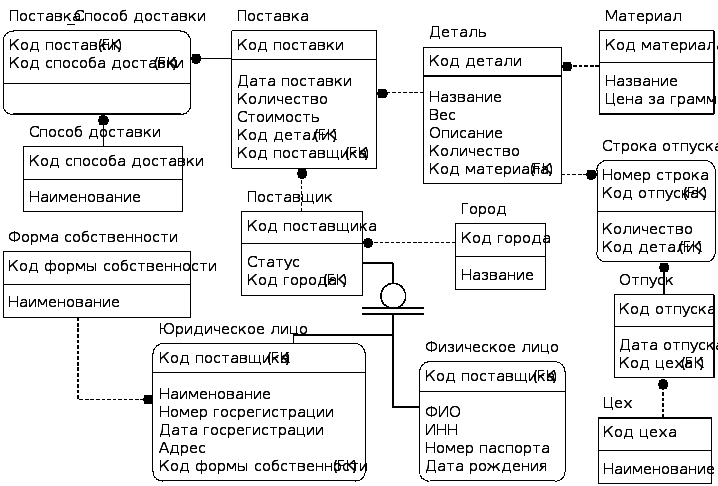
Рис.
1. Логическая модель базы данных в нотации
IDEF1X
Методология IDEF1X
– один из подходов к моделированию
данных, основанный на концепции «сущность
– связь» (Entity – Relationship),
предложенной Питером Ченом в 1976 г.
|
Таблица |
|
|
Сущность (Entity) |
Графическое |
|
Независимая |
Наименование Уникальный Атрибуты
|
|
Зависимая сущность |
Наименование Ссылка Атрибуты
|
|
Связь (Relationship) |
Графическое |
|
Неидентифицирующая |
|
|
Идентифицирующая |
Независ. |
|
Связь «Многие ко |
|
|
Наследование
П
Н |
Родительск. -й
|








 олное
олное


 еполное
еполное


Независимая
сущность –
это сущность, уникальный идентификатор
которой не наследуется из других
сущностей. Изображается
в виде прямоугольника с прямыми краями.
Зависимая сущность
–
это сущность, уникальный идентификатор
которой включает по меньшей мере одну
связь с другой сущностью.
Например, строка документа не может
существовать без самого документа
(зависит от него). Изображается
в виде прямоугольника с закругленными
краями.
Методология
IDEF1X
ориентирована на проектирование
реляционных моделей баз данных. В
основе реляционной модели лежит понятие
нормализованного
отношения (таблицы).
При
этом сущности предметной области
отображаются в таблицы базы данных
(рис. 2), обладающие
следующими свойствами:
-
нет
одинаковых кортежей (строк), они
различаются по уникальному идентификатору
– первичному ключу; -
кортежи
(строки / записи) не упорядочены сверху
вниз; -
атрибуты
(столбцы) не упорядочены слева направо;
в операциях с таблицей ее строки и
столбцы могут просматриваться в любой
последовательности безотносительно
их содержания и смысла; -
в
 се
се
значения атрибутов – скаляры и имеют
одинаковую природу (построены на одном
домене).
 се
се
Рис.

2.
Таблица
реляционной
базы данных
Ключ
— столбец
или группа
столбцов, значения которых однозначно
идентифицируют каждую
строку.
В
одной таблице может
быть несколько ключей: один первичный,
посредством которого осуществляется
связывание отношений, а другие –
альтернативные. Свойства ключа:
-
уникальность
(не может быть строк с одинаковым
ключом); -
неизбыточность
(удаление любого атрибута из ключа
лишает его свойства уникальности).
Реляционная база
данных − это
множество
связанных между собой отношений.
Связи
задаются с помощью вторичных ключей
(Foreign
key
– FK),
т.е. атрибутов, которые в других отношениях
являются первичными ключами
(Primary
key
– PK).
Основные ограничения
целостности реляционной модели:
-
атрибуты
из первичного ключа не могут принимать
неопределенное значение (целостность
объектов); -
вторичные
ключи не могут принимать значения,
которых нет среди значений первичных
ключей связанной таблицы: если отношение
R2 имеет среди своих атрибутов какой-то
внешний ключ (FK), который соответствует
первичному ключу (PK) отношения R1, то
каждое значение FK должно быть равно
одному из значений PK.
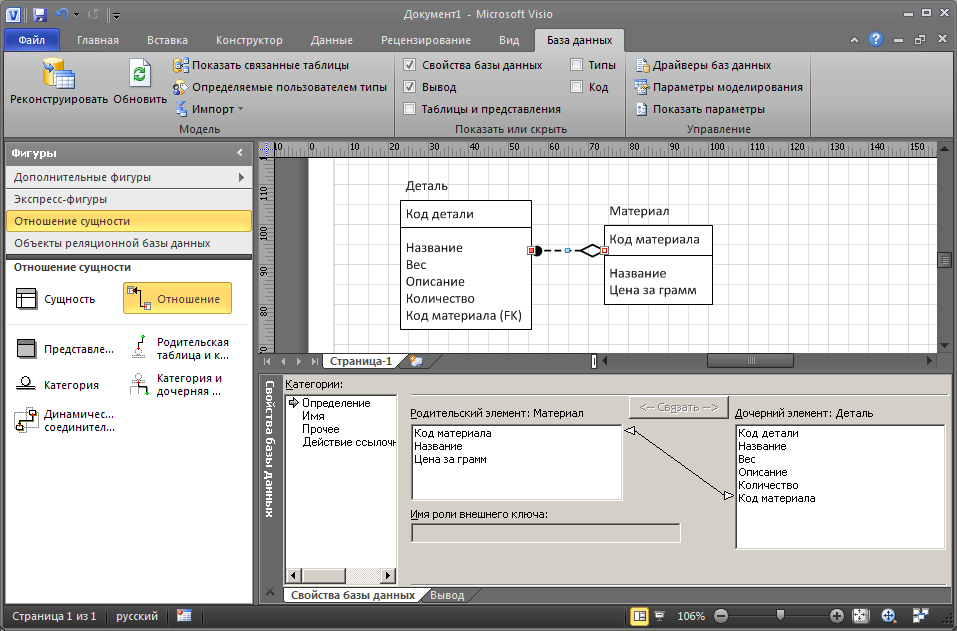
Создание Логической модели БД в Visio
|
Чтобы |
Рис. 2.3. Шаблон |
|
Прежде, |
Рис. 2.4. |
|
Рис. 2.6. |
Рис. 2.5. |
|
Чтобы |
Рис. 2.7. |
|
Задайте |
Рис. |
|
Затем |
Рис. |
|
Аналогично Незакрашенный |
Рис. 2.10. |

Задание: постройте логическую
модель базы данных в соответствии с
описанием предметной области из вашего
варианта задания.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Анализ данных
• 17 мая 2023 • 5 мин чтения
Перед разработкой ПО нужно определить, с какими данными предстоит работать и как они связаны между собой. Для этого системные аналитики строят модели данных и создают ER-диаграммы.
- Что такое ER‑диаграмма
- Типы ER‑моделей
- Применение ER-диаграмм
- Символы и нотации ER‑диаграмм
- Примеры ER‑диаграмм
- Как создать простую ER‑диаграмму
- Совет эксперта
Что такое ER‑диаграмма
Системный аналитик начинает работу над новым проектом с изучения его предметной области и терминов, которые в ней используют. Например, нужно создать систему для бронирования билетов на самолёт. Аэропорт, авиакомпания, дата, рейс, пассажир, пункты прибытия и назначения, багаж — термины проекта. Их ещё называют понятиями или сущностями.
В системе сущность представлена в виде экземпляров. Например, экземпляры сущности «Аэропорт» ― аэропорты «Домодедово», «Пулково», «Воронеж».
У сущностей есть атрибуты — характеристики, которые их описывают. Например, атрибутами сущности «Аэропорт» будут код, адрес, номер телефона. Атрибуты есть у каждого экземпляра сущности, но у них разные значения. У аэропортов «Домодедово» и «Воронеж» есть одинаковый атрибут «Адрес», но у каждого из них разное значение этого атрибута.
Собрав все сущности будущего проекта, системный аналитик выясняет, как они связаны между собой, и составляет ER-модель (сокр. от entity–relationship модель или модель «сущность-связь»). В модели есть три типа связей:
● «Один-к-одному» — один экземпляр сущности связан только с одним экземпляром другой сущности. Например, пассажир рейса и его место в самолете.
● «Один-ко-многим» — один экземпляр сущности связан со множеством экземпляров другой сущности. Например, у одного пассажира может быть несколько единиц багажа, при этом каждая единица багажа может быть связана только с одним пассажиром.
● «Многие-ко-многим» — множество экземпляров одной сущности связаны со множеством экземпляров другой сущности. Например, аэропорт обслуживает несколько авиакомпаний. При этом каждая авиакомпания может обслуживаться в нескольких аэропортах.
Системный аналитик создаёт ER-диаграмму модели данных. Это схема, которая показывает, с какими данными нужно будет работать для реализации проекта и как эти данные связаны между собой. Например, ER-диаграмма проиллюстрирует, что багаж связан с номером рейса, но не связан со временем окончания посадки пассажиров на него.
Чтобы создать ER-модель, не нужны специальные инструменты. Её можно построить вручную в любом графическом редакторе: для диаграмм используют простые символы вроде квадратов, стрелок и линий.
На курсе «Системный аналитик» студенты на реальных проектах учатся моделировать данные, строить ER-диаграммы и составлять требования для разработки ПО.
Спрос на системных аналитиков продолжает расти
Обучайтесь на реальных рабочих задачах, освойте новые инструменты за 8 месяцев и получите 5 проектов в портфолио к концу курса «Системный аналитик». Начните с бесплатной вводной части.

Типы ER‑моделей
ER-модели создают разные специалисты, а сами модели отличаются друг от друга детализацией: насколько подробно в них описывают данные. Есть три уровня ER-моделей:
1. Концептуальный уровень
Первая верхнеуровневая модель для представления новой предметной области будущего проекта: что в ней есть и с чем нужно работать. Например, в ПО для транспортной компании будут сущности «Транспорт», «Груз», «Маршрут», «Накладная».
ER-модель концептуального уровня нужна системному аналитику и заказчику, чтобы проверить, все ли термины учтены. Поэтому системный аналитик, как правило, создаёт её самостоятельно и не привлекает технических специалистов из команды разработки.
2. Логический уровень
На этом уровне детализируют данные из концептуальной модели: к сущностям добавляют характеристики — атрибуты. Например, на логическом уровне описывают характеристики сущности «Транспорт»: марка и модель автомобиля, количество лошадиных сил, пробег, грузоподъёмность.
Модель логического уровня тоже составляет системный аналитик, но уже не в одиночку. К работе подключают технических специалистов ― разработчика или архитектора баз данных. Готовую логическую ER-модель нужно презентовать команде разработки. Разработчики проверяют, чтобы аналитик ничего не упустил, и согласовывают модель.
3. Физический уровень
На этом уровне описывают, как будет организована работа с данными: выбирают тип базы, её содержание и где данные будут хранить. Например, выбирают реляционный тип базы данных и СУБД для работы с ней, перечисляют таблицы в базе и определяют, что она будет храниться на внутреннем сервере компании.
Над ER-моделью физического уровня в большей степени работают архитектор баз данных и разработчики, а системный аналитик только помогает в процессе.
Применение ER-диаграмм
Модели «сущность-связь» традиционно используют для разработки программного обеспечения. При этом для метода нет конкретной области разработки: для создания любого ПО нужно работать с данными и транслировать их пользователям. Поэтому ER-модели строят и для интернет-магазина, и для корпоративного портала компании.
Обычно ER-модель создают в двух случаях:
● когда перед началом проекта ещё не понятно, с какими данными предстоит работать;
● когда нужно создать новую базу данных или добавить таблицу в уже существующую.
Чем больше в системе сущностей и связей, тем важнее построить ER-модель до начала разработки ПО.
На практике над простыми системами можно работать без концептуальной ER-модели. Например, программа для выдачи талонов электронной очереди — простая система, в которой всего две сущности — номер окна и номер очереди.
Символы и нотации ER‑диаграмм
ER-модель — это общее представление данных, ER-диаграмма — представление модели, а нотация — графический язык для представления модели.
Объясним на примере анатомии человека. Устройство человеческого организма — это модель. Её можно описать текстом, изобразить на картинке, перечислить все органы в таблице. Всё это разные представления одной и той же модели. Символы, с помощью которых описывают модель, — это нотации.
Для того чтобы построить ER-диаграмму, можно использовать разные нотации. Три самые известные из них:
1. Нотация IDEF1X. Её относят к фундаментальным, но на практике давно не используют, потому что есть более удобные варианты.
2. Нотация Чена. Классическая нотация, которая состоит из простых символов — прямоугольников, овалов и линий. Из-за этого нотацию часто используют для концептуальных моделей, которые презентуют заказчику. Человеку, который далёк от аналитики данных, проще разобраться в понятных диаграммах со знакомыми символами.
3. Нотация Мартина. Её ещё называют «воронья лапка» (от англ. Crow’s Foot). Она компактнее нотации Чена, поэтому её используют для построения ER-моделей логического уровня, когда нужно описать в модели все атрибуты сущностей.
В нотациях Чена и Мартина есть одинаковые элементы: сущности, атрибуты и связи. Но эти элементы обозначают разными символами.

В нотации Чена название сущностей, атрибутов и связей вписывают внутрь прямоугольника, овала или ромба
Элементы ER-диаграммы в нотации Чена соединяют линиями. Если линия соединяет две сущности, сверху обозначают тип связи:
● 1:1 — «один-к-одному»;
● 1:N — «один-ко-многим»;
● M:N — «многие-ко-многим».

В одной компании работает много сотрудников. Тип связи между сущностями «компания» и «сотрудник» — «один-ко-многим»
В нотации Мартина сущность также вписывают в прямоугольник, а атрибуты и связи обозначают по-другому:
● атрибуты перечисляют прямо под сущностью,
● связи рисуют разными соединительными линиями.
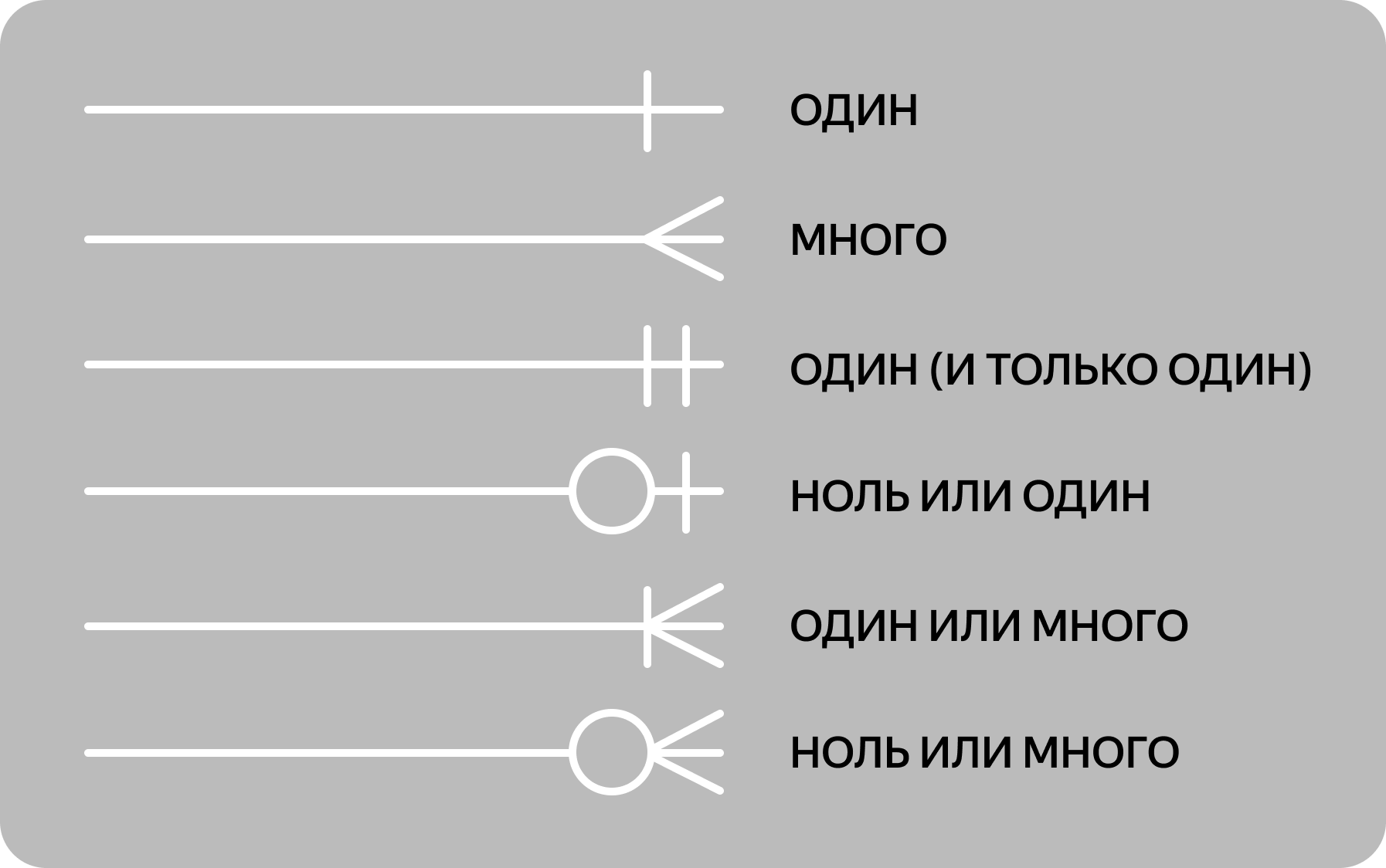
В нотации Мартина используют несколько видов соединительных линий для иллюстрации типа связи между сущностями.
Для того чтобы изобразить три типа связи в нотации Мартина, можно использовать разные комбинации. Например, связь «многие-ко-многим» можно изобразить так:
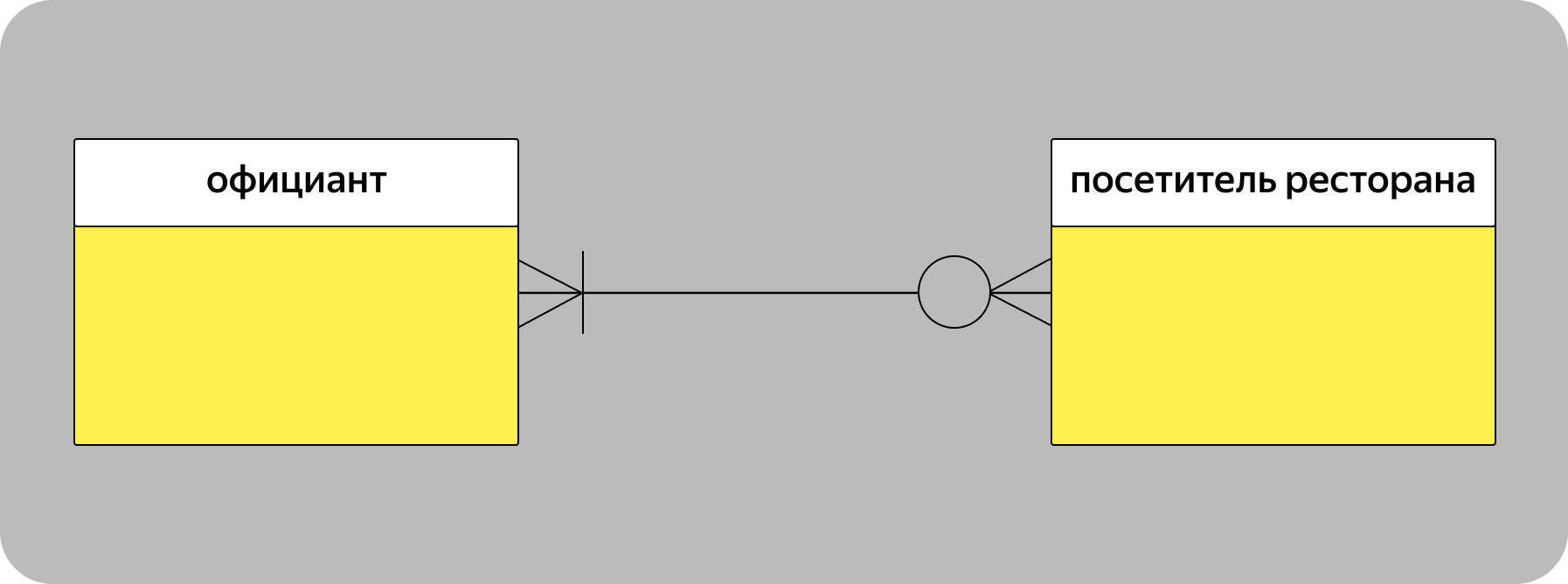
Официант может обслуживать от нуля до множества посетителей ресторана. При этом одного посетителя ресторана должен обслуживать хотя бы один официант, а могут и несколько
А связь «один-ко-многим» может выглядеть так:

За каждым столиком в ресторане закреплён только один официант. При этом за каждым официантом может быть закреплено несколько столиков
Примеры ER‑диаграмм
На примере сервиса по бронированию номеров в сети гостиниц рассмотрим, как выглядит одна и та же ER-модель в разных нотациях.
Сначала нужно выделить сущности ER-модели:
● гость,
● гостиница,
● номер.
У каждой сущности есть основные атрибуты, например у сущности «гость» это ФИО и номер паспорта, у «гостиницы» — её номер в сети и адрес, у «номера» — его порядковый номер в гостинице и категория.
Затем нужно установить связи между сущностями.
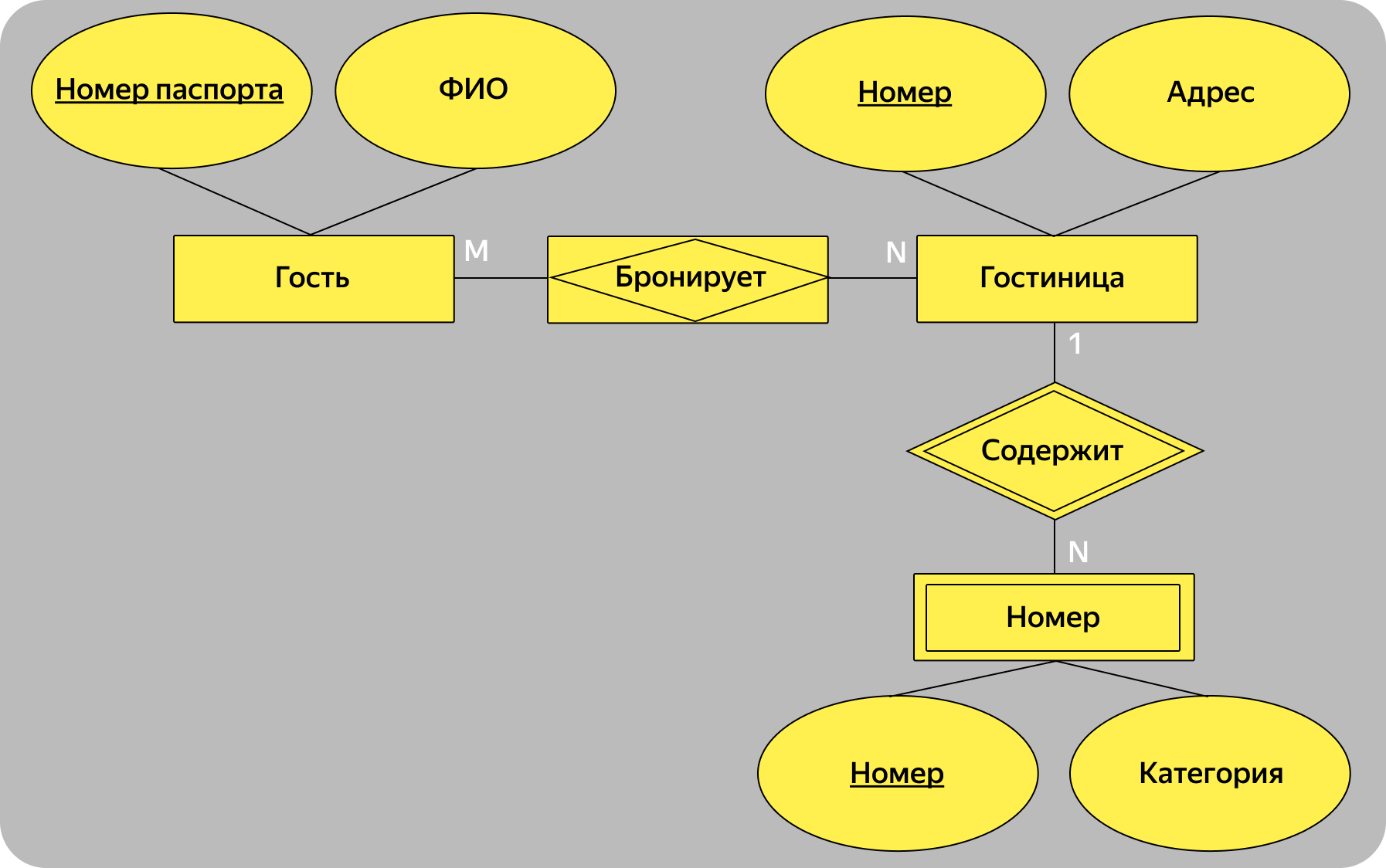
ER-модель концептуального уровня в нотации Чена содержит прямоугольники с сущностями, овалы с атрибутами, ромбы со связями. Сущность в подчинении у другой сущности называют дочерней и помещают в прямоугольник с двойной рамкой. Ромб со связью между ними тоже обводят двойной рамкой
Между сущностями «Гость» и «Гостиница» установлена связь «многие-ко-многим» — много гостей могут бронировать много гостиниц. В нотации Чена такая связь становится самостоятельной сущностью, которую называют ассоциативной и обозначают ромбом внутри прямоугольника. Ассоциативная сущность между «Гостем» и «Гостиницей» — «Бронирование». На следующих уровнях ER-модели у неё появятся атрибуты, например дата и номер бронирования.
Если строить ER-модель логического уровня в нотации Чена, она может сильно разрастись из-за большого количества атрибутов. Поэтому на следующем уровне можно построить модель в нотации Мартина.
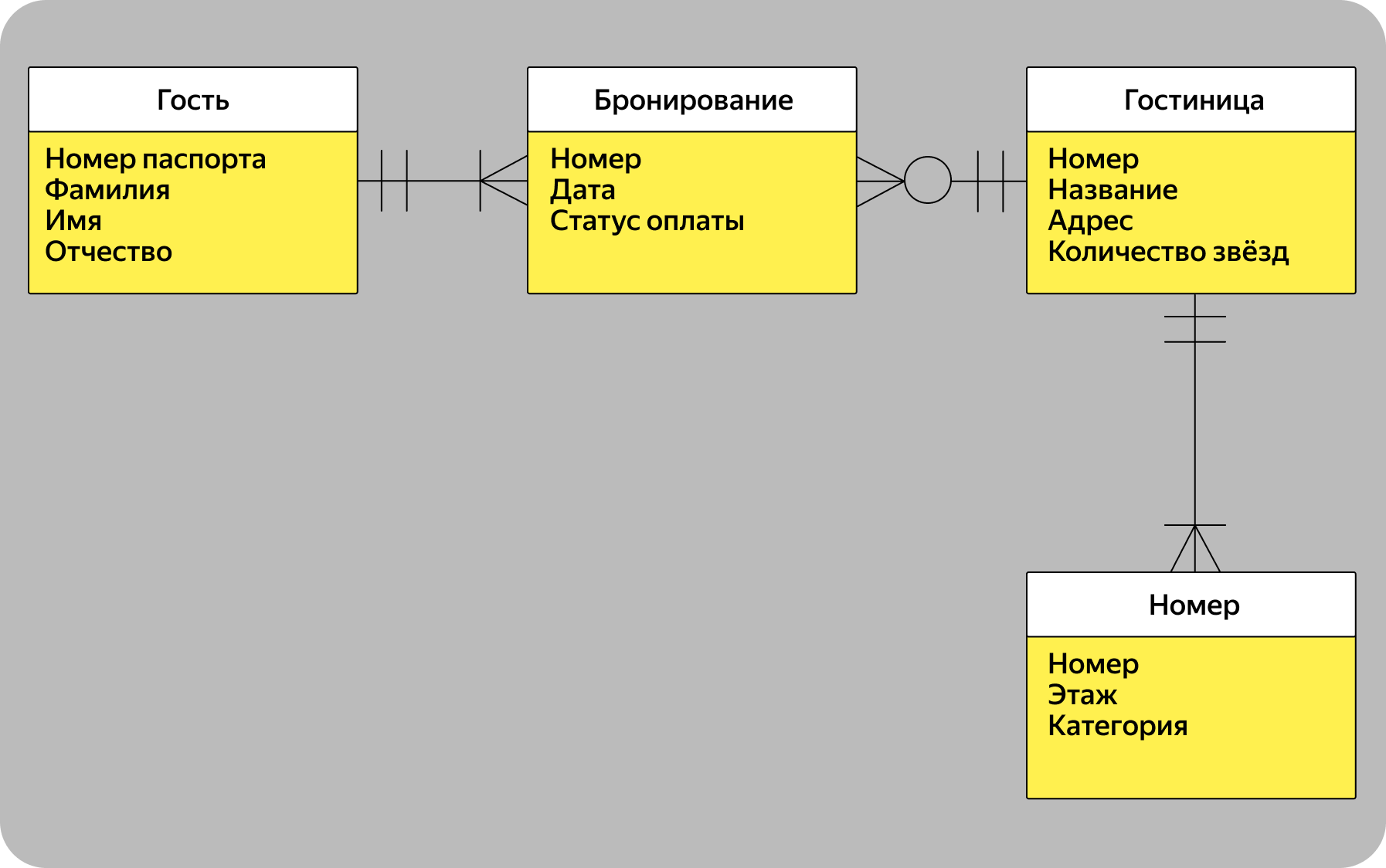
В ER-модели в нотации Мартина атрибуты сущностей перечисляют в полях под ними. За счёт этого модель занимает меньше места и её структура менее запутана
Как создать простую ER‑диаграмму
Вот пошаговый алгоритм для создания простой ER-диаграммы:
1. Определить сущности
Чтобы собрать все сущности будущего проекта, системные аналитики общаются с заказчиком и будущими пользователями ПО: сотрудниками или клиентами компании. Например, если нужно разработать ПО для ветеринарной клиники, системный аналитик проведёт интервью с руководителем клиники, сотрудниками, врачами и клиентами, которые будут записываться на приём.
На этом этапе обычно создают концептуальную модель и согласовывают её с заказчиком.
2. Определить атрибуты
Системный аналитик детализирует информацию, собранную во время интервью, и описывает характеристики сущностей. Если данных не хватает, нужно повторно опросить заинтересованных лиц.
3. Определить связи между сущностями
На этом этапе выясняют, какие сущности связаны между собой. Например, пациенты и медицинская карта, филиал клиники и врачи, которые ведут приём.
4. Определить типы и характеристики связей
Например, пациенты и медицинская карта — это связь «один-к-одному», врач и день приёма — «один-ко-многим».
Затем ищут идентифицирующие связи между сущностями и определяют, какая из сущностей родительская. Допустим, у клиники есть филиалы — A, B и C. В каждом филиале есть кабинеты под номерами от 1 до 5. Это значит, что нельзя использовать номер кабинета без уточнения, в каком филиале он находится. Филиал — родительская сущность, а связь между филиалом и кабинетом — идентифицирующая.
5. Проверить ER-модель
После завершения работы над ER-моделью системный аналитик проверяет, нет ли в ней лишних сущностей, дубликатов данных и косвенных связей между данными в одной таблице. Такую проверку называют нормализацией данных.
Если модель данных не соответствует нормальным формам, её нужно скорректировать.
Совет эксперта
Маргарита Нижельская
Хотя ER-модели создают для разработки ПО, на самом деле область их применения значительно шире. Модели данных концептуального уровня используют для структурирования информации. Например, чтобы определить организационную структуру в компании или создать контент-план. Такое структурирование данных часто сопровождает любой процесс планирования.

Яндекс Практикум
Автор курса «Системный аналитик», специалист по системному и бизнес-анализу

Яндекс Практикум
Редактор

Яндекс Практикум
Иллюстратор

На каком языке рисуют схемы: что такое UML и почему его понимают во всём мире

Что читать аналитику данных: 7 современных книг для начинающих специалистов