A covariance matrix is a type of matrix used to describe the covariance values between two items in a random vector. It is also known as the variance-covariance matrix because the variance of each element is represented along the matrix’s major diagonal and the covariance is represented among the non-diagonal elements. A covariance matrix is usually a square matrix. It is also positive semi-definite and symmetric. This matrix comes in handy when it comes to stochastic modeling and Principal component analysis.
What is Covariance Matrix?
The variance-covariance matrix is a square matrix with diagonal elements which represent the variance and the non-diagonal components that express covariance. The covariance of a variable can take any real value- positive, negative, or zero. A positive covariance suggests that the two variables have a positive relationship, whereas a negative covariance indicates that they do not. If two elements do not vary together, they have a zero covariance.
Covariance Matrix Example
Say there are 2 data sets X = [10, 5] and Y = [3, 9]. The variance of Set X = 12.5 and the variance of set Y = 18. The covariance between both variables is -15. The covariance matrix is as follows:

Covariance Matrix Formula
The general form of a covariance matrix is given as follows:

where,
How to find the Covariance Matrix?
The dimensions of a covariance matrix are determined by the number of variables in a given data set. If there are only two variables in a set, then the covariance matrix would have two rows and two columns. Similarly, if a data set has three variables, then its covariance matrix would have three rows and three columns.
The data pertains to marks scored by Anna, Caroline, and Laura in Psychology and History. Make a covariance matrix.
| Student | Psychology(X) | History(Y) |
|---|---|---|
| Anna | 80 | 70 |
| Caroline | 63 | 20 |
| Laura | 100 | 50 |
The following steps have to be followed:
Step 1: Find the mean of variable X. Sum up all the observations in variable X and divide the sum obtained with the number of terms. Thus, (80 + 63 + 100)/3 = 81.
Step 2: Subtract the mean from all observations. (80 – 81), (63 – 81), (100 – 81).
Step 3: Take the squares of the differences obtained above and then add them up. Thus, (80 – 81)2 + (63 – 81)2 + (100 – 81)2.
Step 4: Find the variance of X by dividing the value obtained in Step 3 by 1 less than the total number of observations. var(X) = [(80 – 81)2 + (63 – 81)2 + (100 – 81)2] / (3 – 1) = 343.
Step 5: Similarly, repeat steps 1 to 4 to calculate the variance of Y. Var(Y) = 633.
Step 6: Choose a pair of variables.
Step 7: Subtract the mean of the first variable (X) from all observations; (80 – 81), (63 – 81), (100 – 81).
Step 8: Repeat the same for variable Y; (70 – 47), (20 – 47), (50 – 47).
Step 9: Multiply the corresponding terms: (80 – 81)(70 – 47), (63 – 81)(20 – 47), (100 – 81)(50 – 47).
Step 10: Find the covariance by adding these values and dividing them by (n – 1). Cov(X, Y) = (80 – 81)(70 – 47) + (63 – 81)(20 – 47) + (100 – 81)(50 – 47)/3-1 = 481.
Step 11: Use the general formula for the covariance matrix to arrange the terms. The matrix becomes: 
Properties of Covariance Matrix
- A covariance matrix is always square, implying that the number of rows in a covariance matrix is always equal to the number of columns in it.
- A covariance matrix is always symmetric, implying that the transpose of a covariance matrix is always equal to the original matrix.
- A covariance matrix is always positive and semi-definite.
- The eigenvalues of a covariance matrix are always real and non-negative.
Solved Examples on Covariance Matrix
Example 1: The marks scored by 3 students in Physics and Biology are given below:
| Student | Physics(X) | Biology(Y) |
|---|---|---|
| A | 92 | 80 |
| B | 60 | 30 |
| C | 100 | 70 |
Prepare the sample covariance matrix from the above data.
Solution:
Sample covariance matrix is given by
.
Here, μx = 84, n = 3
var(x) = [(92 – 84)2 + (60 – 84)2 + (100 – 84)2] / (3 – 1) = 448
Also, μy = 60, n = 3
var(y) = [(80 – 60)2 + (30 – 60)2 + (70 – 60)2] / (3 – 1) = 700
Now, cov(x, y) = cov(y, x) = [(92 – 84)(80 – 60) + (60 – 84)(30 – 60) + (100 – 84)(70 – 60)] / (3 – 1) = 520.
The population covariance matrix is given as:
 .
.
Example 2. Prepare the population covariance matrix from the following table:
| Age | Number of People |
|---|---|
| 29 | 68 |
| 26 | 60 |
| 30 | 58 |
| 35 | 40 |
Solution:
Population variance is given by
.
Here, μx = 56.5, n = 4
var(x) = [(68 – 56.5)2 + (60 – 56.5)2 + (58 – 56.5)2 + (40 – 56.5)2 ] / 4 = 104.75
Also, μy = 30, n = 4
var(y) = [(29 – 30)2 + (26 – 30)2 + (30 – 30)2 + (35 – 30)2] / 4 = 10. 5
Now, cov(x, y) =
cov(x, y) = -27
The population covariance matrix is given as:
 .
.

Example 3. Interpret the following covariance matrix:

Solution:
- The diagonal elements 60, 30, and 80 indicate the variance in data sets X, Y, and Z respectively. Y shows the lowest variance whereas Z displays the highest variance.
- The covariance for X and Y is 32. As this is a positive number it means that when X increases (or decreases) Y also increases (or decreases)
- The covariance for X and Z is -4. As it is a negative number it implies that when X increases Z decreases and vice-versa.
- The covariance for Y and Z is 0. This means that there is no predictable relationship between the two data sets.
Example 4. Find the sample covariance matrix for the following data:
| X | Y | Z |
|---|---|---|
| 75 | 10.5 | 45 |
| 65 | 12.8 | 65 |
| 22 | 7.3 | 74 |
| 15 | 2.1 | 76 |
| 18 | 9.2 | 56 |
Solution:
Sample covariance matrix is given by
n = 5, μx = 22.4, var(X) = 321.2 / (5 – 1) = 80.3
μy = 12.58, var(Y) = 132.148 / 4 = 33.037
μz = 64, var(Z) = 570 / 4 = 142.5
cov(X, Y) =
cov(X, Z) =
cov(Y, Z) =
The covariance matrix is given as:




FAQs on Covariance Matrix
Question 1: What is a covariance matrix?
Answer:
A covariance matrix is a type of matrix used to describe the covariance values between two items in a random vector.
Question 2: What is the general form of a 2 x 2 covariance matrix?
Answer:
The general form of a covariance matrix is given as follows:
Question 3: Is the Variance Covariance Matrix Symmetric?
Answer:
Yes, the variance-covariance matrix is symmetric. It means that the transposition of a covariance matrix will result in the original matrix. In other words, MT = M, where M is the covariance matrix.
Question 4: What are the Applications of the Covariance Matrix?
Answer:
The covariance matrix is commonly used in economics, financial engineering, and machine learning. The Cholesky decomposition performs a Monte Carlo simulation using the covariance matrix. This simulation is used to develop a variety of mathematical models.
Related Resources
- Chance and Probability
- Pie Chart
- Graphical Representation of Data
Last Updated :
09 Jan, 2023
Like Article
Save Article
17 авг. 2022 г.
читать 3 мин
Ковариация — это мера того, как изменения одной переменной связаны с изменениями второй переменной. В частности, это мера степени линейной связи двух переменных.
Формула для расчета ковариации между двумя переменными, X и Y :
COV( X , Y ) = Σ(x- x )(y -y )/n
Ковариационная матрица представляет собой квадратную матрицу, которая показывает ковариацию между множеством различных переменных. Это может быть простым и полезным способом понять, как различные переменные связаны в наборе данных.
В следующем примере показано, как создать ковариационную матрицу в Excel с использованием простого набора данных.
Как создать ковариационную матрицу в Excel
Предположим, у нас есть следующий набор данных, который показывает результаты тестов 10 разных учащихся по трем предметам: математике, естественным наукам и истории.

Чтобы создать ковариационную матрицу для этого набора данных, щелкните параметр « Анализ данных» в правом верхнем углу Excel на вкладке « Данные ».

Примечание. Если вы не видите параметр «Анализ данных», вам необходимо сначала загрузить пакет инструментов анализа данных .
После того, как вы нажмете эту опцию, появится новое окно. Щелкните Ковариация .

В поле « Входной диапазон » введите «$A$1:$C$11», так как это диапазон ячеек, в котором находится наш набор данных. Установите флажок « Метки в первой строке », чтобы указать Excel, что метки для наших переменных расположены в первой строке. Затем в поле Выходной диапазон введите любую ячейку, в которой вы хотите разместить ковариационную матрицу. Я выбрал ячейку $E$2. Затем нажмите ОК .

Ковариационная матрица генерируется автоматически и появляется в ячейке $E$2:

### Как интерпретировать ковариационную матрицу
Когда у нас есть ковариационная матрица, довольно просто интерпретировать значения в матрице.
Значения по диагоналям матрицы — это просто отклонения каждого субъекта. Например:
- Дисперсия оценок по математике составляет 64,96.
- Дисперсия баллов по естественным наукам составляет 56,4.
- Дисперсия оценок по истории составляет 75,56.

Другие значения в матрице представляют собой ковариации между различными субъектами. Например:
- Ковариация между оценками по математике и естественным наукам составляет 33,2.
- Ковариация между оценками по математике и истории составляет -24,44.
- Ковариация между оценками по науке и истории составляет -24,1.

Положительное число для ковариации указывает на то, что две переменные имеют тенденцию увеличиваться или уменьшаться в тандеме. Например, математика и естествознание имеют положительную ковариацию (33,2), что указывает на то, что учащиеся, получившие высокие баллы по математике, также, как правило, получают высокие баллы по естественным наукам. Точно так же учащиеся с низкими баллами по математике, как правило, также имеют низкие баллы по естественным наукам.
Отрицательное число для ковариации указывает на то, что по мере увеличения одной переменной вторая переменная имеет тенденцию к уменьшению. Например, математика и история имеют отрицательную ковариацию (-24,44), что указывает на то, что учащиеся с высокими баллами по математике, как правило, имеют низкие баллы по истории. Точно так же учащиеся с низкими баллами по математике, как правило, получают высокие баллы по истории.
Двумерной называют случайную величину
, возможные значения
которой есть пары чисел
. Составляющие
и
, рассматриваемые
одновременно, образуют систему двух случайных величин. Двумерную величину
геометрически можно истолковать как случайную точку
на плоскости
либо как случайный вектор
.
Дискретной называют двумерную величину, составляющие которой дискретны.
Закон распределения дискретной двумерной СВ.
Безусловные и условные законы распределения составляющих
Законом распределения вероятностей двумерной случайной величины называют соответствие
между возможными значениями и их вероятностями.
Закон
распределения дискретной двумерной случайной величины может быть задан:
а) в
виде таблицы с двойными входом, содержащей возможные значения и их вероятности;
б) аналитически, например в виде функции распределения.
Зная
закон распределения двумерной дискретной случайной величины, можно найти законы
каждой из составляющих. В общем случае, для того чтобы найти вероятность
, надо просуммировать
вероятности столбца
. Аналогично сложив
вероятности строки
получим вероятность
.
Пусть
составляющие
и
дискретны и имеют соответственно следующие
возможные значения:
;
.
Условным распределением составляющей
при
(j сохраняет одно и то же
значение при всех возможных значениях
) называют совокупность
условных вероятностей:
Аналогично
определяется условное распределение
.
Условные
вероятности составляющих
и
вычисляют соответственно по формулам:
Для
контроля вычислений целесообразно убедиться, что сумма вероятностей условного
распределения равна единице.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Ковариация (корреляционный момент)
Ковариация двух случайных величин характеризует степень зависимости случайных величин, так
и их рассеяние вокруг точки
.
Ковариацию
(корреляционный момент) можно найти по формуле:
Свойства ковариации
Свойство 1.
Ковариация двух независимых случайных величин равна нулю.
Свойство 2.
Ковариация двух случайных величин равна математическому ожиданию их
произведение математических ожиданий.
Свойство 3.
Ковариация двухмерной случайной величины по абсолютной случайной величине не
превосходит среднеквадратических отклонений своих компонентов.
Коэффициент корреляции
Коэффициент корреляции – отношение ковариации двухмерной случайной
величины к произведению среднеквадратических отклонений.
Формула коэффициента корреляции:
Две
случайные величины
и
называют коррелированными, если их коэффициент
корреляции отличен от нуля.
и
называют некоррелированными величинами, если
их коэффициент корреляции равен нулю
Свойства коэффициента корреляции
Свойство 1.
Коэффициент корреляции двух независимых случайных величин равен нулю. Отметим,
что обратное утверждение неверно.
Свойство 2.
Коэффициент корреляции двух случайных величин не превосходит по абсолютной
величине единицы.
Свойство 3.
Коэффициент корреляции двух случайных величин равен по модулю единице тогда и
только тогда, когда между величинами существует линейная функциональная
зависимость.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Линейная регрессия
Рассмотрим
двумерную случайную величину
, где
и
– зависимые случайные величины. Представим
одну из величины как функцию другой. Ограничимся приближенным представлением
величины
в виде линейной функции величины
:
где
и
– параметры, подлежащие определению. Это можно
сделать различными способами и наиболее употребительный из них – метод
наименьших квадратов.
Линейная
средняя квадратическая регрессия
на
имеет вид:
Коэффициент
называют
коэффициентом регрессии
на
, а прямую
называют
прямой среднеквадратической регрессии
на
.
Аналогично
можно получить прямую среднеквадратической регрессии
на
:
Смежные темы решебника:
- Двумерная непрерывная случайная величина
- Линейный выборочный коэффициент корреляции
- Парная линейная регрессия и метод наименьших квадратов
Задача 1
Закон
распределения дискретной двумерной случайной величины (X,Y) задан таблицей.
Требуется:
—
определить одномерные законы распределения случайных величин X и Y;
— найти
условные плотности распределения вероятностей величин;
—
вычислить математические ожидания mx и my;
—
вычислить дисперсии σx и σy;
—
вычислить ковариацию μxy;
—
вычислить коэффициент корреляции rxy.
| xy | 3 | 5 | 8 | 10 | 12 |
| -1 | 0.04 | 0.04 | 0.03 | 0.03 | 0.01 |
| 1 | 0.04 | 0.07 | 0.06 | 0.05 | 0.03 |
| 3 | 0.05 | 0.08 | 0.09 | 0.08 | 0.05 |
| 6 | 0.03 | 0.04 | 0.04 | 0.06 | 0.08 |
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 2
Задана
дискретная двумерная случайная величина (X,Y).
а) найти
безусловные законы распределения составляющих; б) построить регрессию случайной
величины Y на X; в) построить регрессию случайной величины X на Y; г) найти коэффициент ковариации; д) найти
коэффициент корреляции.
| Y | X | ||||
| 1 | 2 | 3 | 4 | 5 | |
| 30 | 0.05 | 0.03 | 0.02 | 0.01 | 0.01 |
| 40 | 0.03 | 0.02 | 0.02 | 0.04 | 0.01 |
| 50 | 0.05 | 0.03 | 0.02 | 0.02 | 0.01 |
| 70 | 0.1 | 0.03 | 0.04 | 0.03 | 0.01 |
| 90 | 0.1 | 0.04 | 0.01 | 0.07 | 0.2 |
Задача 3
Двумерная случайная величина (X,Y) задана
таблицей распределения. Найти законы распределения X и Y, условные
законы, регрессию и линейную регрессию Y на X.
|
x y |
1 | 2 | 3 |
| 1.5 | 0.03 | 0.02 | 0.02 |
| 2.9 | 0.06 | 0.13 | 0.03 |
| 4.1 | 0.4 | 0.07 | 0.02 |
| 5.6 | 0.15 | 0.06 | 0.01 |
Задача 4
Двумерная
случайная величина (X,Y) распределена по закону
| XY | 1 | 2 |
| -3 | 0,1 | 0,2 |
| 0 | 0,2 | 0,3 |
| -3 | 0 | 0,2 |
Найти
законы распределения случайных величины X и Y, условный закон
распределения Y при X=0 и вычислить ковариацию.
Исследовать зависимость случайной величины X и Y.
Задача 5
Случайные
величины ξ и η имеют следующий совместный закон распределения:
P(ξ=1,η=1)=0.14
P(ξ=1,η=2)=0.18
P(ξ=1,η=3)=0.16
P(ξ=2,η=1)=0.11
P(ξ=2,η=2)=0.2
P(ξ=2,η=3)=0.21
1)
Выписать одномерные законы распределения случайных величин ξ и η, вычислить
математические ожидания Mξ, Mη и дисперсии Dξ, Dη.
2) Найти
ковариацию cov(ξ,η) и коэффициент корреляции ρ(ξ,η).
3)
Выяснить, зависимы или нет события {η=1} и {ξ≥η}
4)
Составить условный закон распределения случайной величины γ=(ξ|η≥2) и найти Mγ и
Dγ.
Задача 6
Дан закон
распределения двумерной случайной величины (ξ,η):
| ξ=-1 | ξ=0 | ξ=2 | |
| η=1 | 0,1 | 0,1 | 0,1 |
| η=2 | 0,1 | 0,2 | 0,1 |
| η=3 | 0,1 | 0,1 | 0,1 |
1) Выписать одномерные законы
распределения случайных величин ξ и η, вычислить математические ожидания Mξ,
Mη и дисперсии Dξ, Dη
2) Найти ковариацию cov(ξ,η) и
коэффициент корреляции ρ(ξ,η).
3) Являются ли случайные события |ξ>0|
и |η> ξ | зависимыми?
4) Составить условный закон
распределения случайной величины γ=(ξ|η>0) и найти Mγ и Dγ.
Задача 7
Дано
распределение случайного вектора (X,Y). Найти ковариацию X и Y.
| XY | 1 | 2 | 4 |
| -2 | 0,25 | 0 | 0,25 |
| 1 | 0 | 0,25 | 0 |
| 3 | 0 | 0,25 | 0 |
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 8
Случайные
приращения цен акций двух компаний за день имеют совместное распределение,
заданное таблицей. Найти ковариацию этих случайных величин.
| YX | -1 | 1 |
| -1 | 0,4 | 0,1 |
| 1 | 0,2 | 0,3 |
Задача 9
Найдите
ковариацию Cov(X,Y) для случайного дискретного вектора (X,Y),
распределенного по закону:
| X=-3 | X=0 | X=1 | |
| Y=-2 | 0,3 | ? | 0,1 |
| Y=1 | 0,1 | 0,1 | 0,2 |
Задача 10
Совместный
закон распределения пары
задан таблицей:
| xh | -1 | 0 | 1 |
| -1 | 1/12 | 1/4 | 1/6 |
| 1 | 1/4 | 1/12 | 1/6 |
Найти
закон распределения вероятностей случайной величины xh и вычислить cov(2x-3h,x+2h).
Исследовать вопрос о зависимости случайных величин x и h.
Задача 11
Составить двумерный закон распределения случайной
величины (X,Y), если известны законы независимых составляющих. Чему равен коэффициент
корреляции rxy?
| X | 20 | 25 | 30 | 35 |
| P | 0.1 | 0.1 | 0.4 | 0.4 |
и
Задача 12
Задано
распределение вероятностей дискретной двумерной случайной величины (X,Y):
| XY | 0 | 1 | 2 |
| -1 | ? | 0,1 | 0,2 |
| 1 | 0,1 | 0,2 | 0,3 |
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 13
Совместное
распределение двух дискретных случайных величин ξ и η задано таблицей:
| ξη | -1 | 1 | 2 |
| 0 | 1/7 | 2/7 | 1/7 |
| 1 | 1/7 | 1/7 | 1/7 |
Вычислить
ковариацию cov(ξ-η,η+5ξ). Зависимы ли ξ и η?
Задача 14
Рассчитать
коэффициенты ковариации и корреляции на основе заданного закона распределения
двумерной случайной величины и сделать выводы о тесноте связи между X и Y.
| XY | 2,3 | 2,9 | 3,1 | 3,4 |
| 0,2 | 0,15 | 0,15 | 0 | 0 |
| 2,8 | 0 | 0,25 | 0,05 | 0,01 |
| 3,3 | 0 | 0,09 | 0,2 | 0,1 |
Задача 15
Задан
закон распределения случайного вектора (ξ,η). Найдите ковариацию (ξ,η)
и коэффициент корреляции случайных величин.
| xy | 1 | 4 |
| -10 | 0,1 | 0,2 |
| 0 | 0,3 | 0,1 |
| 20 | 0,2 | 0,1 |
Задача 16
Для
случайных величин, совместное распределение которых задано таблицей
распределения. Найти:
а) законы
распределения ее компонент и их числовые характеристики;
b) условные законы распределения СВ X при условии Y=b и СВ Y при
условии X=a, где a и b – наименьшие значения X и Y.
с)
ковариацию и коэффициент корреляции случайных величин X и Y;
d) составить матрицу ковариаций и матрицу корреляций;
e) вероятность попадания в область, ограниченную линиями y=16-x2 и y=0.
f) установить, являются ли случайные величины X и Y зависимыми;
коррелированными.
| XY | -1 | 0 | 1 | 2 |
| -1 | 0 | 1/6 | 0 | 1/12 |
| 0 | 1/18 | 1/9 | 1/12 | 1/9 |
| 2 | 1/6 | 0 | 1/9 | 1/9 |
Задача 17
Совместный
закон распределения случайных величин X и Y задан таблицей:
|
XY |
0 |
1 |
3 |
|
0 |
0,15 |
0,05 |
0,3 |
|
-1 |
0 |
0,15 |
0,1 |
|
-2 |
0,15 |
0 |
0,1 |
Найдите:
а) закон
распределения случайной величины X и закон распределения
случайной величины Y;
б) EX, EY, DX, DY, cov(2X+3Y, X-Y), а
также математическое ожидание и дисперсию случайной величины V=6X-8Y+3.
Задача 18
Известен
закон распределения двумерной случайной величины (X,Y).
а) найти
законы распределения составляющих и их числовые характеристики (M[X],D[X],M[Y],D[Y]);
б)
составить условные законы распределения составляющих и вычислить
соответствующие мат. ожидания;
в)
построить поле распределения и линию регрессии Y по X и X по Y;
г)
вычислить корреляционный момент (коэффициент ковариации) μxy и
коэффициент корреляции rxy.
|
|
5 | 20 | 35 |
| 100 | — | — | 0.05 |
| 115 | — | 0.2 | 0.15 |
| 130 | 0.15 | 0.35 | — |
| 145 | 0.1 | — | —- |
1. Основные понятия статистики
Основными понятиями в статистике являются выборочное среднее, дисперсия и стандартное отклонение. Сначала приведем набор из n выборок, формулы которых приведены ниже:
Жадный:
Среднеквадратичное отклонение:
разница:
Среднее значение описывает среднюю точку выборочного набора, которая говорит нам, что информация ограничена, а стандартное отклонение описывает среднее расстояние между каждой точкой выборки выборочного набора и средним значением.
Возьмите эти два набора в качестве примера, [0, 8, 12, 20] и [8, 9, 11, 12], среднее значение обоих наборов равно 10, но, очевидно, разница между этими двумя наборами очень большая, расчет Стандартное отклонение для обоих составляет 8,3, а для последнего — 1,8. Очевидно, что последнее является более концентрированным, поэтому стандартное отклонение меньше. Стандартное отклонение описывает это «распределение». Причина деления на n-1 вместо n состоит в том, что это позволяет нам лучше аппроксимировать стандартное отклонение совокупности с меньшим набором выборок, что является так называемой «несмещенной оценкой» в статистике. Дисперсия — это просто квадрат стандартного отклонения.
Во-вторых, зачем вам ковариация
Стандартное отклонение и дисперсия обычно используются для описания одномерных данных, но в реальной жизни мы часто сталкиваемся с наборами данных, содержащими многомерные данные.Простейшая вещь заключается в том, что когда вы идете в школу, вы должны подсчитывать результаты тестов по нескольким предметам. Столкнувшись с таким набором данных, мы, конечно, можем рассчитать дисперсию независимо для каждого измерения, но обычно мы все же хотим знать больше, например, существует ли какая-то связь между развратностью мальчика и его популярностью среди девочек. Ковариация — это такая статистика, которая используется для измерения взаимосвязи между двумя случайными переменными. Мы можем следовать определению дисперсии:
![clip_image002[6]](https://russianblogs.com/images/615/2d22383e83f115d17d9f5e3c5bc5a177.gif)
Чтобы измерить степень отклонения каждого измерения от его среднего значения, ковариация может быть определена следующим образом:
![clip_image002[8]](https://russianblogs.com/images/258/41449e4ac011d6b95976b7a46ded53a2.gif)
Какое значение имеет результат ковариации? Если результат положительный, это означает, что они положительно коррелированы (ковариация может привести к определению «коэффициента корреляции»), то есть, чем более неряшлив человек, тем популярнее девушка. Если результат отрицательный, это означает, что оба отрицательно коррелируют, и чем более непослушная девушка, тем больше раздражает. Если оно равно 0. Между этими двумя нет никакой связи. Нет никакой связи между распутством и симпатиями или неприязнью девушек, которые статистически «независимы».
Мы также можем увидеть некоторые очевидные свойства из определения ковариации, такие как:
![clip_image002[10]](https://russianblogs.com/images/457/eaf909466bfc5e18aa11e0433af8fe91.gif)
![clip_image002[12]](https://russianblogs.com/images/650/24cb41e6b44ec547e8b6db12dfc29e22.gif)
В-третьих, ковариационная матрица
Вышеупомянутые неразрешимые и популярные проблемы являются типичными двумерными задачами, и ковариация может иметь дело только с двумерными задачами. Если имеется больше измерений, естественно рассчитать множественные ковариации. расчет![clip_image002[16]](https://russianblogs.com/images/794/807cad4effa93ef031f4126e330c9192.gif) Ковариантность, тогда, естественно, мы подумаем об использовании матрицы для организации этих данных. Дайте определение ковариационной матрицы:
Ковариантность, тогда, естественно, мы подумаем об использовании матрицы для организации этих данных. Дайте определение ковариационной матрицы:
![clip_image002[18]](https://russianblogs.com/images/573/135d22cd01f811d8e7fba2c247360575.gif)
Это определение все еще легко понять. Мы можем привести трехмерный пример. Предполагая, что набор данных имеет три измерения, ковариационная матрица имеет вид:
![clip_image002[20]](https://russianblogs.com/images/461/75ddda1de35874d3ce3d224ab217785d.gif)
Можно видеть, что ковариационная матрица является симметричной матрицей, а диагональ — дисперсией каждого измерения.
В-четвертых, фактическая ковариация Matlab
Должно быть понятно, что ковариационная матрица рассчитывает ковариацию между разными измерениями, а не между разными выборками. Следующая демонстрация будет использовать Matlab. Чтобы объяснить принцип вычисления, функция cov Matlab не вызывается напрямую:
Во-первых, случайным образом сгенерируйте целочисленную матрицу размером 10 * 3 в качестве набора выборок, 10 — это количество выборок, а 3 — это размерность выборки.

Рисунок 1 Использование Matlab для генерации набора образцов
В соответствии с формулой для расчета ковариации требуется вычисление среднего значения. Ранее было подчеркнуто, что ковариационная матрица предназначена для расчета ковариации между различными измерениями. Всегда помните об этом. Каждая строка матрицы образца — это образец, а каждый столбец — это измерение, поэтому мы должны вычислить среднее значение по столбцу. Для удобства описания мы сначала назначаем данные трех измерений:

Рисунок 2 Назначение данных в трех измерениях
Рассчитаем ковариацию dim1 и dim2, dim1 и dim3, dim2 и dim3:

Рисунок 3 Расчет трех ковариаций
Элементами на диагонали ковариационной матрицы являются дисперсии каждого измерения, ниже мы рассмотрим эти дисперсии по очереди:

Рисунок 4 Расчет дисперсии по диагонали
Таким образом, у нас есть все данные, необходимые для вычисления ковариационной матрицы, мы можем вызвать функцию cov Matlab, чтобы получить ковариационную матрицу напрямую:

Рис. 5. Использование функции cov в Matlab для непосредственного расчета ковариационной матрицы образца
Результат расчета в точности совпадает с результатом после заполнения предыдущих данных в матрице.
V. Резюме
Ключом к пониманию ковариационной матрицы является помнить, что ее расчет — это ковариация между различными измерениями, а не между различными выборками. Когда вы получаете образец матрицы, первое, что вам нужно знать, является ли строка образцом или измерением. Я в глубине души знаю, что весь процесс вычислений будет течь вниз по течению, так что я не буду смущен.
Шесть, код
clear;
clc;
% Чтобы объяснить принцип вычисления, функция Ковла Matlab не вызывается напрямую:
% Случайно генерирует 10 * 3-мерную целочисленную матрицу в качестве набора выборок, 10 - это количество выборок, а 3 - это количество выборок.
MySample=fix(rand(10,3)*50);
dim1=MySample(:,1);
dim2=MySample(:,2);
dim3=MySample(:,3);
% Рассчитайте ковариацию dim1 и dim2, dim1 и dim3, dim2 и dim3:
cov12 = sum((dim1-mean(dim1)).*(dim2-mean(dim2)))/(size(MySample,1)-1);
cov13 = sum((dim1-mean(dim1)).*(dim3-mean(dim3)))/(size(MySample,1)-1);
cov23 = sum((dim2-mean(dim2)).*(dim3-mean(dim3)))/(size(MySample,1)-1);
% Дисперсии (диагональ)
var1=std(dim1)^2;
var2=std(dim2)^2;
var3=std(dim3)^2;
% Непосредственно с использованием ковариационной матрицы функции Ков
covValue = cov(MySample);
Вариации
оценок параметров будут, в конечном
счете, определять точность уравнения
множественной регрессии. Для их измерения
в многомерном регрессионном анализе
рассматривают так называемую
ковариационную
матрицу К,
являющуюся
матричным аналогом дисперсии одной
переменной:
 .
.
где
элементы
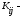 ковариации
ковариации
(или
корреляционные
моменты) оценок
параметров
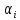 и
и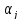
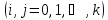 .
.
Ковариация
двух переменных определяется как
математическое ожидание произведения
отклонений этих переменных от их
математических ожиданий [Ссылка]. Поэтому
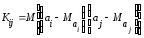 , (13.28)
, (13.28)
где
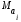 и
и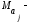 математические
математические
ожидания соответственно для параметров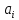
и
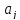 .
.
Ковариация
характеризует как степень рассеяния
значений двух переменных относительно
их математических ожиданий, так и
взаимосвязь этих переменных.
В
силу того, что оценки
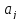 ,
,
полученные методом наименьших квадратов,
являются несмещенными оценками параметров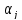 ,
,
т.е.
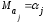 ,
,
выражение(13.28)
примет
вид:
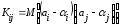 .
.
Рассматривая
ковариационную матрицу К,
легко
заметить, что на ее главной диагонали
находятся дисперсии опенок параметров
регрессии, ибо
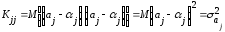 .
.
(13.29)
В
сокращенном виде ковариационная матрица
К
имеет
вид:
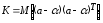 .
.
(13.30)
Учитывая
(13.28)
мы
можем записать
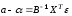 .
.
Тогда
выражение (12.30) примет вид:
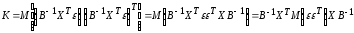 ,
,
(13.31)
ибо
элементы матрицы X
—неслучайные
величины.
Матрица
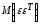
представляет
собой ковариационную матрицу
вектора возмущений
 :
:
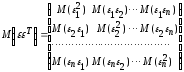
в
которой все элементы, не лежащие на
главной диагонали, равны нулю в силу
предпосылки 4
о
некоррелированности возмущений
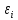 ,
,
и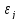
между
собой,
а
все элементы, лежащие на главной
диагонали, в силу предпосылок 2
и
3
регрессионного
анализа
равны
одной и той же дисперсии
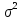 :
:
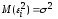 .
.
Поэтому
матрица
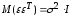 ,
,
где
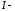
единичная
матрица
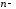 го
го
порядка.
Следовательно, в силу (13.31)
ковариационная
матрица вектора
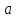
оценок
параметров:
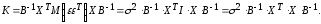
Так
как
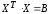 и
и
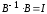 ,
,
то окончательно получим:
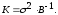 (13.32)
(13.32)
Таким
образом, с
помощью обратной матрицы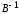 нормальных
нормальных
уравнении регрессии
определяется
не только сам вектор
 оценок
оценок
параметров (13.28),
но
и дисперсии и ковариации его компонент.
Входящая
в (13.32)
дисперсия
возмущений неизвестна. Заменив ее
выборочной остаточной дисперсией
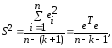 (13.33)
(13.33)
по
(13.32)
получаем
выборочную оценку ковариационной
матрицы К.
(В
знаменателе выражения (13.33)
стоит
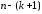 ,
,
а
не
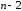 ,
,
как
это было выше в (13.6).
Это
связано с тем, что теперь
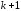 степеней
степеней
свободы (а не две) теряются при определении
неизвестных параметров, число которых
вместе со свободным членом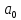 равно
равно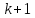 .
.
4.10. Определение доверительных интервалов для коэффициентов и функции множественной регрессии
Перейдем
теперь к оценке значимости коэффициентов
регрессии
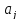
и
построению доверительного интервала
для параметров регрессионной модели
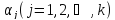 .
.
В
силу (13.29),
(13.32) и
изложенного выше оценка дисперсии
коэффициента регрессии
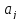
определится
по формуле:
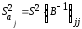
где
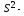
несмещенная
оценка параметра
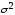 ;
;
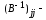 диагональный
диагональный
элемент матрицы
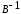 .
.
Среднее
квадратическое отклонение (стандартная
ошибка) коэффициента регрессии
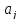
примет
вид:
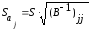 .
.
(13.34)
Значимость
коэффициента регрессии
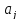
можно
проверить, если учесть, что статистика
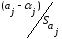 имеет
имеет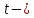 распределение
распределение
Стьюдента с
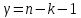 степенями
степенями
свободы. Поэтому
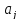
значимо
отличается от нуля на уровне
значимости
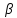 ,
,
если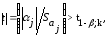 соответствующий
соответствующий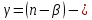 ныйдоверительный
ныйдоверительный
интервал для параметра
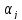
есть
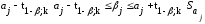 .
.
(13.35)
Наряду
с интервальным оцениванием коэффициентов
регрессии по (13.35)
весьма
важным для оценки точности определения
зависимой переменной (прогноза) является
построение доверительного
интервала для функции регрессии или
для условного математического
ожидания зависимой переменной
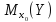 ,
,
найденного в предположении, что
объясняющие переменные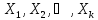
приняли
значения, задаваемые вектором
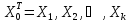 .Выше
.Выше
такой интервал получен для уравнения
парной регрессии (см. (13.13)
и
(13.12)).
Обобщая
соответствующие выражения на случай
множественной регрессии, можно получить
доверительный интервал для
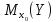 :
:
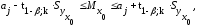
где
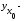 групповая
групповая
средняя, определяемая по уравнению
регрессии,
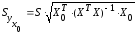 (13.36)
(13.36)
— ее
стандартная ошибка.
При
обобщении формул (13.15)
и
(13.14)
аналогичный
доверительный
интервал для индивидуальных значений
зависимой переменной
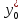 примет
примет
вид:
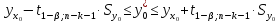 (13.37)
(13.37)
где
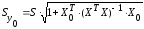 .
.
(13.38)
Доверительный
интервал для дисперсии возмущений
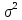
в
множественной регрессии с надежностью
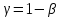 строится аналогично парной модели
строится аналогично парной модели
по формуле(13.20)
с
соответствующим изменением числа
степеней свободы критерия
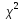 :
:
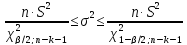 (13.39)
(13.39)
Пример
13.6.
По
данным примера 13.4
оценить
сменную добычу
угля на одного рабочего для шахт с
мощностью пласта 8 м и уровнем механизации
работ 6%; найти 95%-ные доверительные
интервалы для индивидуального и среднего
значений сменной добычи угля на 1
рабочего для таких же шахт. Проверить
значимость коэффициентов регрессии и
построить для них 95%-ные доверительные
интервалы. Найти с надежностью 0,95
интервальную оценку для дисперсии
возмущений
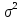 .
.
Решение.
В примере 13.4
уравнение
регрессии получено в виде:
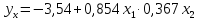 .
.
По
условию надо оценить
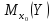 ,
,
где
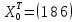 .
.
Выборочной оценкой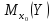 ,
,
является
групповая средняя, которую найдем по
уравнению регрессии:
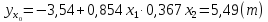 .
.
Для построения доверительного
интервала для М (у) необходимо знать
дисперсию его оценки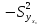 .
.
Для
ее вычисления обратимся к табл. 13.7
(точнее к ее двум последним столбцам,
при составлении которых учтено, что
групповые средние определяются по
полученному уравнению регрессии).
Теперь
по (13.37):
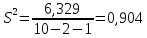
и
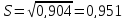 (т).
(т).
Определяем
стандартную ошибку групповой средней
г> по формуле (13.41).
Вначале
найдем
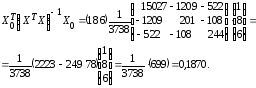
Теперь
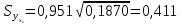
(т).
По
табл. IV приложений при числе степеней
свободы
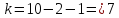
находим
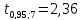 .
.
По
(13.40)
доверительный
интервал для
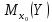 ,
,
равен
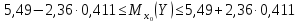 или
или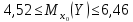 (т).
(т).
Итак,
с надежностью 0,95
средняя
сменная добыча угля на одного рабочего
для шахт с мощностью пласта 8
м
и уровнем механизации работ 6%
находится
в пределах от 4,52
до
6,46
т.
Сравнивая
новый доверительный интервал для функции
регрессии
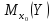 ,
,
полученный
с учетом двух объясняющих переменных,
с аналогичным интервалом с учетом одной
объясняющей переменной (см. пример
13.1),
можно
заметить уменьшение его величины. Это
связано с тем, что включение в модель
новой объясняющей переменной позволяет
несколько повысить точность модели
за счет увеличения взаимосвязи зависимой
и объясняющей переменных (см. ниже).
Найдем
доверительный интервал для индивидуального
значения
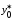
при
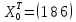 по
по
(13.43):
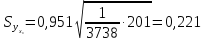
(т)
и по (13.42):
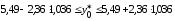 ,
,
т. е.
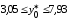 (т).
(т).
Итак,
с надежностью 0,95
индивидуальное
значение сменной добычи угля в шахтах
с мощностью пласта 8
м
и уровнем механизации работ 6%
находится
в пределах от 3,05
до
7,93
(т).
Проверим
значимость коэффициентов регрессии
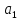
и
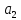 .
.
В
примере 13.4
получены
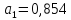
и
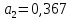 .
.
Стандартная
ошибка
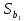
в
соответствии с (13.38)
равна:
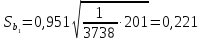 .
.
Так
как
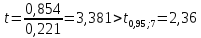 ,
,
то
коэффициент
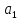
значим.
Аналогично вычисляем
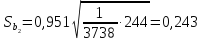 и
и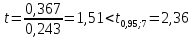 т.е. коэффициент
т.е. коэффициент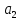
незначим
на 5%-ном уровне.
Доверительный
интервал имеет смысл построить только
для значимого коэффициента регрессии
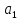 :
:
по
(13.39)
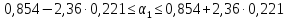
или
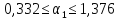 .
.
Итак,
с надежностью 0,95 за счет изменения на
1 м мощности пласта
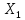
(при
неизменном
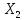 )
)
сменная
добыча угля на одного рабочего У
будет изменяться в пределах от 0,332 до
1,376 т.
Найдем
95%-ный доверительный интервал для
параметра ст2.
Учитывая, что
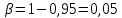 ,
,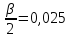 ,
,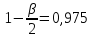 найдем по табл.
найдем по табл.
V
приложений при
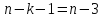 степенях свободы
степенях свободы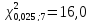 ;
;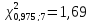 и по формуле(13.43′)
и по формуле(13.43′)
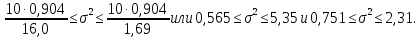
Таким
образом, с надежностью 0,95 дисперсия
возмущений заключена в пределах от
0,565 до 5,35, а их стандартное отклонение
— от 0,751 до 2,31 (т).
Формально
переменные, имеющие незначимые
коэффициенты регрессии, могут быть
исключены из рассмотрения. В экономических
исследованиях исключению переменных
из регрессии должен предшествовать
тщательный качественный
анализ.
Поэтому может оказаться целесообразным
все же оставить в регрессионной модели
одну или несколько объясняющих
переменных, не оказывающих существенного
(значимого) влияния на зависимую
переменную.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
27.03.20162.81 Mб141Учебник Туристское ресурсоведение.rtf
- #
- #
- #
- #
- #
- #
27.03.20164.24 Mб197Физика Яковлев.pdf