Метод дерева решений — это прекрасный способ выбрать стратегию последовательных действий в условиях риска. Именно риск здесь выступает ключевым словом, поскольку при опасности принять рациональное решение очень сложно, а продуманный план помогает проанализировать сложившуюся ситуацию.
Дерево принятия решений подобно настоящему: у него есть ствол, ветви и листья. «Ствол» — основа всего — это главный вопрос, на который нужно ответить. Ветви — это стрелочки с несколькими вариантами ответов. А листья — это ситуации, к которым приведет нас выбранный ответ.

Самый простой пример
Любая теория воспринимается намного легче, если привести пример. Дерево решений «Пойти гулять?» — это самый простой алгоритм. В бизнесе все базируется на таких принципах. Кстати, в основе всех электронных программ тоже лежит алгоритм построения дерева.
Итак, стоит задача: решить, можно ли идти гулять. Наш ствол — первый вопрос — это ключевой фактор: «На улице солнечно?» От него зависит наш дальнейший путь. Если ответ положительный, двигаемся по направлению слова «Да». Приходим к новому разветвлению. Если температура воздуха высокая, мы получаем окончательный ответ — «Не идти гулять», в противном случае тоже получаем итог, но уже с результатом «Идти гулять».
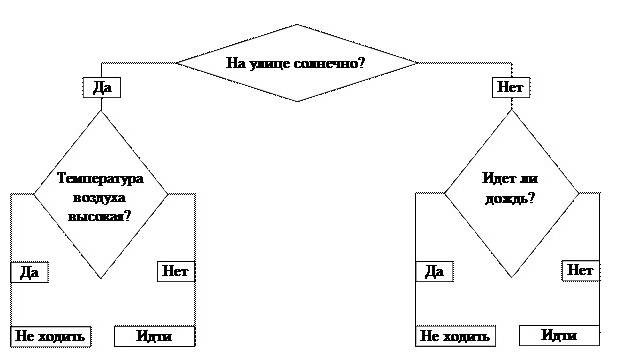
Можно было выбрать и другой путь. Дерево принятия решений подразумевает, что будут проанализированы все варианты движения и спрогнозированы результаты.
Почему следует выбирать этот метод
Преимущества дерева решений позволяют определить, почему данный метод является самым гибким из всех, что касаются вопроса о выборе решений.
- Это одномерная схема, которая наглядно показывает причинно-следственные связи. Что будет, если… И куда наш выбор приведет.
- Возможность одновременно рассматривать нетипичные ситуации и подбирать несколько вариантов их разрешения.
- Отсутствие каких-либо законов следствия.
- Простота в использовании.
- Работать над моделью может сразу несколько человек, что облегчает задачу.
- Дерево решений не ограничено во временных рамках.
- Подходит для большинства бизнес-ситуаций.

Область применения
Можно привести любой пример дерева решений. Это может быть вопрос о том, открывать ли новые производственные мощности, внедрять технологии, формировать новый ассортимент и т. д. Область применения данного метода невероятно широка.
Но можно выделить три большие группы, где дерево решений помогает выиграть время.
- Описание данных. Допустим, задача руководства — решить проблему расширения ассортимента. Схема данной задачи будет состоять из конкретных цифр возможных сумм прибыли и рентабельности. Структурировать такую информацию будет намного проще, если она будет храниться в виде схемы, а не в обширной таблице.
- Классификация. Появляется возможность сгруппировать исходные данные и сделать для них подборку.
- Регрессия. Дерево решений позволяет определить, как формируется целевая стратегия под воздействием независимых факторов. Например, на выбор стратегии формирования ассортимента будут влиять, кроме основных факторов производства, второстепенные, которые косвенно к этому относятся. Это может быть урожай какао-бобов из страны-экспортера или график движения транспортных судов. Вроде бы на выбор стратегии прямо не оказывают воздействия, но сбой их работы может помешать формированию ассортимента на кондитерской фабрике.

Алгоритмы
На сегодняшний день существует несколько известных алгоритмов, позволяющих создавать дерева решений (примеры мы уже рассмотрели).
- CART — аббревиатура слов Classificationand Regression Tree (классификация и регрессия). Согласно его принципам, каждый узел дерева может иметь только два ответвления.
- С4.5 — метод построения, при котором каждый узел может иметь неограниченное количество веток. В такой схеме тяжело делать прогнозы, поэтому ее используют для классификации.
- QUEST (Quick, Unbiased, Efficient Statistical Trees). Самая сложная из всех моделей, но очень достоверная. Позволяет создавать многомерное ветвление. Это значит, что в любом узле может создаваться не просто множество веток, а примеров действия.

Сбор данных
Метод дерева решений будет эффективен в том случае, если правильно подойти к вопросу сбора данных. Приведем характерную последовательность:
- Определение жизненного цикла проекта: сколько будет этапов и какова продолжительность каждого из них.
- Выделение ключевых событий, на этапе которых может возникнуть дилемма выбрать одно или другое.
- Описание каждого из возможных факторов, которые повлияют на наступление того или иного события, описанного в предыдущем шаге.
- Оценка вероятности принятия этих решений.
- Расчет стоимости всех этапов жизненного цикла (считается между ключевыми событиями).
Пример дерева решений
Рассмотрим типичную бизнес-ситуацию. Компании нужно выбрать выгодное инвестиционное вложение Ип1, Ип2, Ип3 с помощью дерева решений. Примеры решения задач формируются на основании исходных данных.
Первый проект требует вложения в размере 200 млн рублей и принесет прибыль 100 млн руб. Для второго необходимо 300 млн руб., но принесет 200 млн руб. Третий, самый прибыльный, — 300 млн руб., но вложить нужно 500. При этом есть риск потерять все. При первом варианте уровень риска — 10 %, при втором — 5 %, и при третьем — 20 %. Какой из проектов будет самый выгодный?
Провести математические расчеты довольно затруднительно. Поэтому нужно построить графическую схему. Правильное решение будет зависеть не только от того, насколько понятной будет модель, но и как будут расположены исходные данные.
Построение графика
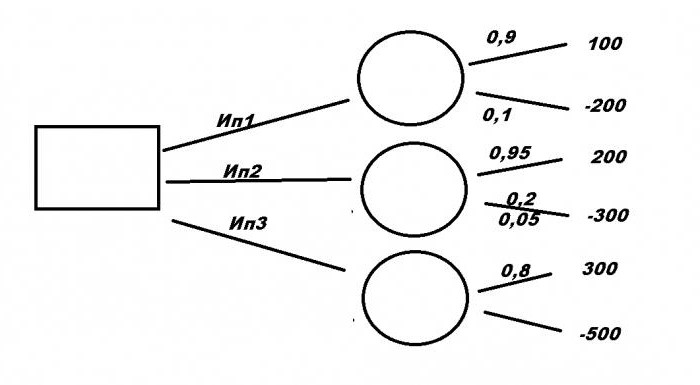
Итак, у нас есть три проекта: Ип1, Ип2 и Ип3. Рассмотрим, как составить дерево решений. Двигаться будем от первого ключевого момента, обозначенного большим квадратом. Здесь мы напишем конечный итог, а пока пускай сектор остается пустым. От него чертим три ответвления с именами проектов. Далее каждый вариант имеет свой уровень математических ожиданий, обозначенный кружочком. Пока они пустые, в них нужно будет написать полученный результат расчетов. От каждого из них будет еще два ответвления. Вверх — это доход и уровень его ожидания, вниз — затраты и риски потерь.
Математические расчеты
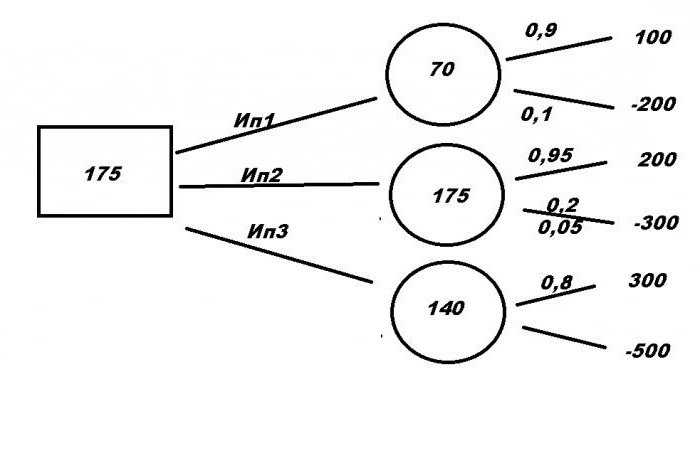
Пора приступать к поиску правильного решения. Для этого составим формулы:
- Ип1= 100 × 0.9 — 200 × 0.1 = 70
- Ип2 = 200× 0.95 — 300 × 0.05 = 175
- Ип3 = 300 × 0.8 — 500 × 0.2 = 140
Полученные данные записываем в кружочки. Выбираем наибольшее число — 175. И записываем его в квадрат. Это и есть математическое ожидание от проекта. И поскольку самое выгодное предложение — это Ип2, это и будет являться ответом на задачу.
Область применения
Казалось бы, что примеров дерева решений для бизнеса можно привести неограниченное количество. Действительно, чаще всего об этом методе говорят в контексте менеджмента. Но на самом деле область применения алгоритма намного больше. Приведем некоторые интересные факты:
- Дерево решений незаменимо в банковском деле. Его используют для оценки клиентов и принятия решения для выдачи кредита.
- Промышленность. Яркий пример — проверка качества. Поскольку на заводах не всегда есть возможность оценить все выпускаемые товары практическим методом, создают специальный алгоритм, с помощью которого брак отсекается на нескольких этапах проверки.
- Медицина. Для использования дерева решений в этой сфере не нужны листик и бумага. Любой врач делает это ежедневно при постановке диагноза. Доктор задает пациенту наводящие вопросы, ответы на которые приведут к единому правильному решению.
- Молекулярная биология. Даже в этой уникальной области есть где применить метод построения схем. Например, анализ строения аминокислот.
- Программирование. Любая программа или веб-страница построены по принципу алгоритма и движения от целого к множеству.
Пример использования алгоритма в банковской сфере
Попробуем построить дерево решений, представив, что мы сотрудники отдела кредитования любого банка. Обозначим ключевых факторы:
- возраст;
- уровень дохода;
- иждивенцы, семейное положение;
- кредиты в других организациях;
- наличие движимого и недвижимого имущества.
Теперь по каждой из ключевых веток необходимо составить примерный план возможных действий.
Начнем с возраста. Больше 21? Ответ «да» или «нет». «Нет» сразу приводит нас к нулю. После ответа «Да» двигаемся к следующему вопросу.
Уровень дохода выше 50 000 руб. в месяц? «Нет» — это сразу ноль, «Да» — переходим к следующей ветке.
Семейное положение. В этом разделе могут появляться дополнительные ответвления, которые будут важными для нашего решения. Сколько человек в семье? Сколько из них иждивенцы, какой доход у супругисупруга. Если ответы нас удовлетворили, можно переходить к следующему сектору.
Кредиты в других организациях. Здесь рационально выделить: какую сумму брали, как быстро отдали, есть ли долги?
Наличие движимого и недвижимого имущества может стать дополнительной гарантией возврата средств, поэтому, если потенциальный заемщик дошел до этого этапа и положительно ответил на последний вопрос, то однозначно решение о выдаче ему денег будет позитивным.
Сократить путь к любому из решений «Выдать» или «Не выдать» можно на любом этапе.
Пример из медицины
Рассмотрим типичную ситуацию. К врачу пришел на осмотр пациент с кашлем. При постановке диагноза доктор оценивает человека по нескольким параметрам:
- как давно кашель;
- есть ли температура;
- заложен ли нос;
- как прослушиваются легкие, бронхи, наличие хрипов;
- сердечный ритм;
- возраст, наличие флюрографии и др. факторы.
Ответ на каждый из этих вопросов приведет доктора к постановке правильного диагноза.
Вывод
Пример дерева решений можно встретить в повседневной жизни. Люди сотни раз сталкиваются с дилеммой, решить которую можно, выбрав только самый короткий или самый выгодный путь. Точно так же и в бизнесе. Алгоритм помогает выбрать правильное решение, классифицировать и структурировать данные о вопросе, спрогнозировать исход. Важной задачей является выбор основных вопросов, которые составляют ключевые моменты, и ветвей с результатом. Существует множество моделей, компьютерных программ, позволяющих быстро и качественно построить дерево решений и облегчить поиск.
Что такое дерево решений и где его используют?
Время на прочтение
11 мин
Количество просмотров 61K
Ребята, привет! Сегодня команда ProductStar подготовила для вас статью, в которой мы рассмотрели общие принципы работы и области применения дерева решений. Материал подготовлен на основе работы Акобира Шахиди «Деревья решений: общие принципы»

Дерево решений — метод автоматического анализа больших массивов данных. В этой статье рассмотрим общие принципы работы и области применения.
Дерево решений — эффективный инструмент интеллектуального анализа данных и предсказательной аналитики. Он помогает в решении задач по классификации и регрессии.
Дерево решений представляет собой иерархическую древовидную структуру, состоящую из правила вида «Если …, то …». За счет обучающего множества правила генерируются автоматически в процессе обучения.
В отличие от нейронных сетей, деревья как аналитические модели проще, потому что правила генерируются на естественном языке: например, «Если реклама привела 1000 клиентов, то она настроена хорошо».
Правила генерируются за счет обобщения множества отдельных наблюдений (обучающих примеров), описывающих предметную область. Поэтому их называют индуктивными правилами, а сам процесс обучения — индукцией деревьев решений.
В обучающем множестве для примеров должно быть задано целевое значение, так как деревья решений — модели, создаваемые на основе обучения с учителем. По типу переменной выделяют два типа деревьев:
-
дерево классификации — когда целевая переменная дискретная;
-
дерево регрессии — когда целевая переменная непрерывная.
Развитие инструмента началось в 1950-х годах. Тогда были предложены основные идеи в области исследований моделирования человеческого поведения с помощью компьютерных систем.
Дальнейшее развитие деревьев решений как самообучающихся моделей для анализа данных связано с Джоном Р. Куинленом (автором алгоритма ID3 и последующих модификаций С4.5 и С5.0) и Лео Брейманом, предложившим алгоритм CART и метод случайного леса.
Структура дерева решений
Рассмотрим понятие более подробно. Дерево решений — метод представления решающих правил в определенной иерархии, включающей в себя элементы двух типов — узлов (node) и листьев (leaf). Узлы включают в себя решающие правила и производят проверку примеров на соответствие выбранного атрибута обучающего множества.
Простой случай: примеры попадают в узел, проходят проверку и разбиваются на два подмножества:
-
первое — те, которые удовлетворяют установленное правило;
-
второе — те, которые не удовлетворяют установленное правило.

Далее к каждому подмножеству снова применяется правило, процедура повторяется. Это продолжается, пока не будет достигнуто условие остановки алгоритма. Последний узел, когда не осуществляется проверка и разбиение, становится листом.
Лист определяет решение для каждого попавшего в него примера. Для дерева классификации — это класс, ассоциируемый с узлом, а для дерева регрессии — соответствующий листу модальный интервал целевой переменной. В листе содержится не правило, а подмножество объектов, удовлетворяющих всем правилам ветви, которая заканчивается этим листом.
Пример попадает в лист, если соответствует всем правилам на пути к нему. К каждому листу есть только один путь. Таким образом, пример может попасть только в один лист, что обеспечивает единственность решения.
Терминология
Изучите основные понятия, которые используются в теории деревьев решений, чтобы в дальнейшем было проще усваивать новый материал.

Какие задачи решает дерево решений?
Его применяют для поддержки процессов принятия управленческих решений, используемых в статистистике, анализе данных и машинном обучении. Инструмент помогает решать следующие задачи:
-
Классификация. Отнесение объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные задачи.
-
Регрессия (численное предсказание). Предсказание числового значения независимой переменной для заданного входного вектора.
-
Описание объектов. Набор правил в дереве решений позволяет компактно описывать объекты. Поэтому вместо сложных структур, используемых для описания объектов, можно хранить деревья решений.
Процесс построения дерева решений
Основная задача при построении дерева решений — последовательно и рекурсивно разбить обучающее множество на подмножества с применением решающих правил в узлах. Но как долго надо разбивать? Этот процесс продолжают до того, пока все узлы в конце ветвей не станут листами.
Узел становится листом в двух случаях:
-
естественным образом — когда он содержит единственный объект или объект только одного класса;
-
после достижения заданного условия остановки алгоритм — например, минимально допустимое число примеров в узле или максимальная глубина дерева.
В основе построения лежат «жадные» алгоритмы, допускающие локально-оптимальные решения на каждом шаге (разбиения в узлах), которые приводят к оптимальному итоговому решению. То есть при выборе одного атрибута и произведении разбиения по нему на подмножества, алгоритм не может вернуться назад и выбрать другой атрибут, даже если это даст лучшее итоговое разбиение. Следовательно, на этапе построения дерева решений нельзя точно утверждать, что удастся добиться оптимального разбиения.
Популярные алгоритмы, используемых для обучения деревьев решений, строятся на базе принципа «разделяй и властвуй». Задают общее множество S, содержащее:
-
n примеров, для каждого из которых задана метка класса Ci(i = 1..k);
-
m атрибутов Aj(j = 1..m), которые определяют принадлежность объекта к тому или иному классу.
Тогда возможно три случая:
-
Примеры множества S имеют одинаковую метку Ci, следовательно, все обучающие примеры относятся к одному классу. В таком случае обучение не имеет смысла, потому что все примеры в модели будут одного класса, который и «научится» распознавать модель. Само дерево будет похоже на один большой лист, ассоциированный с классом Ci. Тогда его использование не будет иметь смысла, потому что все новые объекты будут относиться к одному классу.
-
Множество S — пустое множество без примеров. Для него сформируется лист, класс которого выберется из другого множества. Например, самый распространенный из родительского множества класс.
-
Множество S состоит из обучающих примеров всех классов Ck. В таком случае множество разбивается на подмножества в соответствии с классами. Для этого выбирают один из атрибутов Aj множества S, состоящий из двух и более уникальных значений: a1, a2, …, ap), где p — число уникальных значений признака. Множество S разбивают на p подмножеств (S1, S2, …, Sp), состоящих из примеров с соответствующим значением атрибута. Процесс разбиения продолжается, но уже со следующим атрибутом. Он будет повторяться, пока все примеры в результирующих подмножества не окажутся одного класса.
Третья применяется в большинстве алгоритмов, используемых для построения деревьев решений. Эта методика формирует дерево сверху вниз, то есть от корневого узла к листьям.
Сегодня существует много алгоритмов обучения: ID3, CART, C4.5, C5.0, NewId, ITrule, CHAID, CN2 и другие. Самыми популярными считаются:
-
ID3 (Iterative Dichotomizer 3). Алгоритм позволяет работать только с дискретной целевой переменной. Деревья решений, построенные на основе ID3, получаются квалифицирующими. Число потомков в узле неограниченно. Алгоритм не работает с пропущенными данными.
-
C4.5. «Продвинутая» версия ID3, дополненная возможностью работы с пропущенными значениями атрибутов. В 2008 году издание Spring Science провело исследование и выявило, что C4.5 — самый популярный алгоритм Data Mining.
-
CART (Classification and Regression Tree). Алгоритм решает задачи классификации и регрессии, так как позволяет использовать дискретную и непрерывную целевые переменные. CART строит деревья, в каждом узле которых только два потомка.
Основные этапы построения дерева решений
Построение осуществляется в 4 этапа:
-
Выбрать атрибут для осуществления разбиения в данном узле.
-
Определить критерий остановки обучения.
-
Выбрать метод отсечения ветвей.
-
Оценить точность построенного дерева.
Далее рассмотрим каждый подробнее.
Выбор атрибута разбиения
Разбиение должно осуществляться по определенному правилу, для которого и выбирают атрибут. Причем выбранный атрибут должен разбить множество наблюдений в узле так, чтобы результирующие подмножества содержали примеры с одинаковыми метками класса или были максимально приближены к этому. Иными словами — количество объектов из других классов в каждом из этих множеств должно быть как можно меньше.
Критериев существует много, но наибольшей популярностью пользуются теоретико-информационный и статистический.
Теоретико-информационный критерий
В основе критерия лежит информационная энтропия:

где n — число классов в исходном подмножестве, Ni — число примеров i-го класса, N — общее число примеров в подмножестве.
Энтропия рассматривается как мера неоднородности подмножества по представленным в нем классам. И даже если классы представлены в равных долях, а неопределенность классификации наибольшая, то энтропия тоже максимальная. Логарифм от единицы будет обращать энтропию в ноль, если все примеры узла относятся к одному классу.
Если выбранный атрибут разбиения Aj обеспечивает максимальное снижение энтропии результирующего подмножества относительно родительского, его можно считать наилучшим.
Но на деле об энтропии говорят редко. Специалисты уделяют внимание обратной величине — информации. В таком случае лучшим атрибутом будет тот, который обеспечит максимальный прирост информации результирующего узла относительно исходного:

где Info(S) — информация, связанная с подмножеством S до разбиения, Info(Sa) — информация, связанная с подмножеством, полученным при разбиении атрибута A.
Задача выбора атрибута в такой ситуации заключается в максимизации величины Gain(A), которую называют приростом информации. Поэтому теоретико-информационный подход также известен под название «критерий прироста информации.
Статистический подход
В основе этого метода лежит использования индекса Джини. Он показывает, как часто случайно выбранный пример обучающего множества будет распознан неправильно. Важное условие — целевые значения должны браться из определенного статистического распределения.
Если говорить проще, то индекс Джини показывает расстояние между распределениями целевых значений и предсказаниями модели. Минимальное значение показателя говорит о хорошей работе модели.
Индекс Джини рассчитывается по формуле:

где Q — результирующее множество, n — число классов в нем, pi — вероятность i-го класса (выраженная как относительная частота примеров соответствующего класса).
Значение показателя меняется от 0 до 1. Если индекс равен 0, значит, все примеры результирующего множества относятся к одному классу. Если равен 1, значит, классы представлены в равных пропорциях и равновероятны. Оптимальным считают то разбиение, для которого значение индекса Джини минимально.
Критерий остановки алгоритма
Алгоритм обучения может работать до получения «чистых» подмножеств с примерами одного класса. В таком случае высока вероятность получить дерево, в котором для каждого примера будет создан отдельный лист. Такое дерево не получится применять на практике из-за переобученности. Каждому примеру будет соответствовать свой уникальный путь в дереве. Получится набор правил, актуальный только для данного примера.
Переобучение в случае дерева решений имеет схожие с нейронными сетями последствия. Оно будет точно распознавать примеры из обучения, но не сможет работать с новыми данными. Еще один минус — структура переобученного дерева сложна и плохо поддается интерпретации.
Специалисты решили принудительно останавливать строительство дерева, чтобы оно не становилось «переобученным».
Для этого используют несколько подходов:
-
Ранняя остановка. Алгоритм останавливается после достижения заданного значения критерия (например, процентной доли правильно распознанных примеров). Преимущество метода — сокращение временных затрат на обучение. Главный недостаток — ранняя остановка негативно сказывается на точности дерева. Из-за этого многие специалисты советуют отдавать предпочтение отсечению ветей.
-
Ограничение глубины дерева. Алгоритм останавливается после достижения установленного числа разбиений в ветвях. Этот подход также негативно сказывается на точности дерева.
-
Задание минимально допустимого числа примеров в узле. Устанавливается ограничение на создание узлов с числом примером меньше заданного (например, 7). В таком случае не будут создаваться тривиальные разбиения и малозначимые правила.
Этими подходами пользуются редко, потому что они не гарантируют лучшего результата. Чаще всего, они работают только в каких-то определенных случаях. Рекомендаций по использованию какого-либо метода нет, поэтому аналитикам приходится набирать практический опыт путем проб и ошибок.
Отсечение ветвей
Без ограничения «роста» дерево решений станет слишком большим и сложным, что сделает невозможной дальнейшую интерпретацию. А если делать решающие правила для создания узлов, в которые будут попадать по 2-3 примера, они не лишатся практической ценности.
Поэтому многие специалисты отдают предпочтение альтернативному варианту — построить все возможные деревья, а потом выбрать те, которые при разумной глубине обеспечивают приемлемый уровень ошибки распознавания. Основная задача в такой ситуации — поиск наиболее выгодного баланса между сложностью и точностью дерева.
Но и тут есть проблема: такая задача относится к классу NP-полных задач, а они, как известно, эффективных решений не имеют. Поэтому прибегают к методу отсечения ветвей, который реализуется в 3 шага:
-
Строительство полного дерева, в котором листья содержат примеры одного класса.
-
Определение двух показателей: относительную точность модели (отношение числа правильно распознанных примеров к общему числу примеров) и абсолютную ошибку (число неправильно классифицированных примеров).
-
Удаление листов и узлов, потеря которых минимально скажется на точности модели и увеличении ошибки.
Отсечение ветвей проводят противоположно росту дерева, то есть снизу вверх, путем последовательного преобразования узлов в листья.
Главное отличие метода «отсечение ветвей» от преждевременной остановки — получается найти оптимальное соотношение между точностью и понятностью. При этом уходит больше времени на обучение, потому что в рамках этого подхода изначально строится полное дерево.
Извлечение правил
Иногда упрощения дерева недостаточно, чтобы оно легко воспринималось и интерпретировалось. Тогда специалисты извлекают из дерева решающие правила и составляют из них наборы, описывающие классы.
Для извлечения правил нужно отслеживать все пути от корневого узла к листьям дерева. Каждый путь дает правило с множеством условий, представляющих собой проверку в каждом узле пути.
Если представить сложное дерево решений в виде решающих правил (вместо иерархической структуры узлов), оно будет проще восприниматься и интерпретироваться.
Преимущества и недостатки дерева решений
Преимущества:
-
Формируют четкие и понятные правила классификации. Например, «если возраст < 40 и нет имущества для залога, то отказать в кредите». То есть деревья решений хорошо и быстро интерпретируются.
-
Способны генерировать правила в областях, где специалисту трудно формализовать свои знания.
-
Легко визуализируются, то есть могут «интерпретироваться» не только как модель в целом, но и как прогноз для отдельного тестового субъекта (путь в дереве).
-
Быстро обучаются и прогнозируют.
-
Не требуется много параметров модели.
-
Поддерживают как числовые, так и категориальные признаки.
Недостатки:
-
Деревья решений чувствительны к шумам во входных данных. Небольшие изменения обучающей выборки могут привести к глобальным корректировкам модели, что скажется на смене правил классификации и интерпретируемости модели.
-
Разделяющая граница имеет определенные ограничения, из-за чего дерево решений по качеству классификации уступает другим методам.
-
Возможно переобучение дерева решений, из-за чего приходится прибегать к методу «отсечения ветвей», установке минимального числа элементов в листьях дерева или максимальной глубины дерева.
-
Сложный поиск оптимального дерева решений: это приводит к необходимости использования эвристики типа жадного поиска признака с максимальным приростом информации, которые в конечном итоге не дают 100-процентной гарантии нахождения оптимального дерева.
-
Дерево решений делает константный прогноз для объектов, находящихся в признаковом пространстве вне параллелепипеда, который охватывает не все объекты обучающей выборки.
Где применяют деревья решения?
Модули для построения и исследования деревьев решений входят в состав множества аналитических платформ. Это удобный инструмент, применяемый в системах поддержки принятия решений и интеллектуального анализа данных.
Успешнее всего деревья применяют в следующих областях:
-
Банковское дело. Оценка кредитоспособности клиентов банка при выдаче кредитов.
-
Промышленность. Контроль качества продукции (обнаружение дефектов в готовых товарах), испытания без нарушений (например, проверка качества сварки) и т.п.
-
Медицина. Диагностика заболеваний разной сложности.
-
Молекулярная биология. Анализ строения аминокислот.
-
Торговля. Классификация клиентов и товар.
Это не исчерпывающий список областей применения дерева решений. Круг использования постоянно расширяется, а деревья решений постепенно становятся важным инструментом управления бизнес-процессами и поддержки принятия решений.
Надеемся, наша статья оказалась для вас полезной. Больше интересного контента от ProductStar вы найдёте в нашем блоге на vc и в аналитическом тг-канале.
Попробуйте применить дерево решений на практике для решения маленькой задачи. Постепенно, получая новый опыт, вы сможете использовать инструмент в крупном бизнесе и извлекать пользу от работы с ним.
В настоящей статье описан пошаговый подход к построению дерева решений на базе простого примера, который позволит лучше понять этот метод.
Для построения дерева решений не существует универсального набора символов, но чаще всего квадраты (□) используются для представления «решений», а круги (○) для представления «результатов». Поэтому я буду использовать в своей статье именно эти символы.
Дерево решений и задача, требующая многошагового принятия решений
Дерево решений – это представление задачи в виде диаграммы, отражающей варианты действий, которые могут быть предприняты в каждой конкретной ситуации, а также возможные исходы (результаты) каждого действия. Такой подход особенно полезен, когда необходимо принять ряд последовательных решений и (или) когда на каждом этапе процесса принятия решения могут возникать множественные исходы.
Например, если рассматривается вопрос, стоит ли расширять бизнес, решение может зависеть более чем от одной переменной.
Например, может существовать неопределенность как в отношении объема продаж, так и величины затрат. Более того, значение некоторых переменных может зависеть от значения других переменных: например, если будет продано 100,000 единиц продукта, себестоимость единицы продукта составит $4, но если будет продано 120,000 единиц, себестоимость единицы снизится до $3.80. Таким образом, возможны различные исходы ситуации, при этом некоторые из них будут зависеть от предыдущих исходов. Дерево решений представляет собой полезный метод разделения сложной задачи на более мелкие и более управляемые подзадачи.
Решение задачи при помощи дерева решений осуществляется в два этапа. Первый этап включает построение дерева решений с указанием всех возможных исходов (финансовых результатов) и их вероятностей. Следует помнить, что при принятии решений нужно опираться на принцип релевантных затрат, т. е. использовать только релевантные затраты и выручку. Второй этап включает оценку и формулировку рекомендаций. Принятие решения осуществляется путем последовательного расчета ожидаемых значений исходов в обратном порядке от конца к началу (справа налево). После этого формируются рекомендации для руководства по выбору оптимального образа действий.
Построение дерева решений
Дерево решений всегда следует строить слева направо. Выше я упоминал «решения» и «исходы». Точки принятия решений представляют собой варианты альтернативных действий, то есть возможные выборы. Вы принимаете решение пойти либо этим, либо другим путем. Исходы (результаты решений) от вас не зависят. Они зависят от внешней среды, например, от клиентов, поставщиков или состояния экономики в целом. Как из точек принятия решений, так и из точек исходов выходят «ветви» дерева. Если существует, например, два возможный варианта действий, из точки принятия решения будут выходить две ветви, и если существует два возможных исхода (например, хороший и плохой), то из точки исхода тоже будут выходить две ветви. Поскольку дерево решений является инструментом оценки различных вариантов действий, то все деревья решений должны начинаться с точки принятия решения, которая графически представляется квадратом.
Пример простого дерева решений показан ниже. Из рисунка видно, что лицо, принимающее решение, может выбрать из двух вариантов, поскольку из точки
принятия решения выходит две ветви. Исход одного из вариантов действий, представленного верхней ветвью, точно известен, поскольку на этой ветви нет никаких точек возможных исходов. Но на нижней ветви есть круг, который показывает, что в результате данного решения возможны два исхода, поэтому из него исходят две ветви. На каждой из этих двух ветвей тоже имеется по кругу, из которых, в свою очередь, тоже выходят по две ветви. Это значит, что для каждого из упомянутых возможных исходов имеется два варианта развития ситуации, и каждый из вариантов имеет свой исход. Возможно, первые два исхода представляют собой различные уровни дохода в случае осуществления определенной инвестиции, а второй ряд исходов — различные варианты переменных затрат для каждого уровня доходов.

После построения основы дерева, как показано выше, необходимо указать финансовые значения исходов и их вероятности. Важно помнить, что вероятности, указанные для ветвей, исходящих из одной точки, в сумме должны давать 100%, иначе это будет означать, что вы не указали на диаграмме какой-либо результат, или допустили ошибку в расчетах. Пример приведен ниже в статье.
После построение дерева решений необходимо оценить решение.
Оценка решения
Дерево решений оценивается справа налево, т. е. в направлении, обратном тому, которое использовалось для построения дерева решений. Для того, чтобы осуществить оценку, вы должны предпринять следующие шаги:
- Подпишите все точки принятия решений и исходов, т.е. все квадраты и круги. Начните с тех, которые расположены в самой правой части диаграммы, сверху вниз, и затем перемещайтесь влево до самого левого края диаграммы.
- Последовательно рассчитайте ожидаемые значения всех исходов, двигаясь справа налево, используя финансовые показатели исходов и их вероятности.
Наконец, выберите вариант, который обеспечивает максимальное ожидаемое значение исхода и подготовьте рекомендации для руководства.
Важно помнить, что использование ожидаемых значений для принятия решения имеет свои недостатки. Ожидаемое значение – это средневзвешенное значение исходов решения в долгосрочной перспективе, если бы это решение принималось много раз.
Таким образом, если мы принимаем однократное решение, то фактический результат
быть далек от ожидаемого значения, поэтому данный метод нельзя назвать очень точным. Кроме того, рассчитать точные вероятности довольно сложно, поскольку конкретная рассматриваемая ситуация могла никогда не случаться в прошлом.
Метод ожидаемого значения при принятии решений полезен тогда, когда инвестор имеет нейтральное отношение к риску. Такой инвестор не принимает на себя чрезмерные риски, но и не избегает их. Если отношение к риску лица, принимающего решение, неизвестно, то сложно сказать, стоит ли использовать метод ожидаемого значения. Может оказаться более полезным просто рассмотреть наихудший и наилучший сценарии, чтобы создать основу для принятия решения.
Я приведу простой пример использования дерева решений. В целях упрощения считайте, что все цифры являются чистой приведенной стоимостью соответствующего показателя.
Пример 1
Компания принимает решение, стоит ли разрабатывать и запускать новый продукт. Ожидается, что затраты на разработку составят $400,000, при этом вероятность того, продукт окажется успешным, составляет 70%, а вероятность неудачи, соответственно, 30%. Ниже приведена оценка прибыли от продажи продукта, в зависимости от уровня спроса – высокого, среднего или низкого, а также соответствующие каждому уровню вероятности:
|
Спрос |
Вероятность |
|
|---|---|---|
|
Высокий |
0.2 |
$500,000 в год, в течение 2-х лет |
|
Средний |
0.5 |
$400,000 в год, в течение 2-х лет |
|
Низкий |
0.3 |
$300,000 в год, в течение 2-х лет |
В случае неудачи имеется 60% вероятность, что результаты разработки можно будет продать за $50,000, однако существует 40% вероятность, что продать эти результаты будет невозможно.
Базовое дерево решений представлено ниже:

Далее необходимо указать значения прибыли, не забывая о том, что прибыль в случае успешного запуска будут генерироваться на протяжении двух лет, а также их вероятности.

Теперь необходимо подписать точки принятия решений и исходов, продвигаясь справа налево по дереву решений.

После этого нужно рассчитать ожидаемые значения каждого исхода, умножив показатели прибыли на соответствующие вероятности. Ожидаемое значение рассчитывается для точки исходов А, а затем для точки исходов В, после чего можно рассчитать ожидаемое значение в точке С, умножив ожидаемые значение в точках А и В на соответствующие вероятности.
ОЗ в А = (0.2 x $1,000,000) + (0.5 x $800,000) + (0.3 x $600,000) = $780,000.
ОЗ в В = (0.6 x $50,000) + (0.4 x $0) = $30,000.
ОЗ в С = (0.7 x $780,000) + (0.3 x $30,000) = $555,000
Ожидаемые значения можно указать на диаграмме.

После выполнения расчетов можно двигаться дальше влево к точке принятия решений D. Для принятия решения в точке D нужно сравнить ожидаемое значение верхней ветви дерева (которая, учитывая отсутствие точек исходов, имеет единственный исход, вероятность которого равна 100%) с ожидаемым значением нижней ветви, за вычетом соответствующих затрат. Таким образом, в точке принятия решений D нужно сравнить ожидаемое значение отказа от разработки продукта, которое равно $0, с ожидаемым значением решения разрабатывать продукт которое за вычетом затрат в размере $400,000, составит $155,000.
Теперь можно сформулировать рекомендацию для руководства: разрабатывать продукт, поскольку ожидаемое значение прибыли в этом случае составит $155,000.
Часто существует несколько способов представления дерева решений. В нашем примере, фактически, имеется пять исходов решения начать разработку продукта:
- Продукт будет успешным и обеспечит высокую прибыль в размере $1,000,000.
- Продукт будет успешным и обеспечит среднюю прибыль в размере $800,000.
- Продукт будет успешным и обеспечит небольшую прибыль в размере $600,000.
- Продукт будет неудачным, но результаты разработки будут проданы за $50,000.
- Продукт будет неудачным и не принесет никакого дохода.
Таким образом, вместо дерева решений, в котором из точки С выходит две ветви, каждая из которых имеет еще по нескольку ветвей, можно нарисовать другое дерево, как показано ниже:

Теперь вы можете видеть, что вероятности для ветвей дерева, выходящих из точки результатов А, изменились. Это произошло потому, что в данном случае указаны совместные вероятности, которые являются комбинацией вероятности успеха или неудачи (0,7 и 0,3) с вероятностью высокой, низкой или средней прибыли (0.2, 0.5 и 0.3 соответственно). Совместные вероятности рассчитываются путем умножения двух вероятностей, соответствующих каждому исходу:
Успех и высокая прибыль: 0.7 x 0.2 = 0.14
Успех и средняя прибыль: 0.7 x 0.5 = 0.35
Успех и невысокая прибыль: 0.7 x 0.3 = 0.21
Неудача и продажа результатов разработки: 0.3 x 0.6 = 0.18
Неудача и отсутствие дохода от продажи результатов разработки: 0.3 x 0.4 = 0.12
Сумма всех совместных вероятностей должна быть равна 1, если это не так, вы сделали ошибку в расчетах.
Результат не изменится от того, будете вы использовать первый метод (который я считаю более простым) или второй.
Приведенный выше пример дерева решений довольно простой, но принципы, которые мы рассмотрели, могут применяться к более сложным решениям, требующим построения деревьев со значительно большим количеством точек принятия решений, точек исходов и ветвей.
И, наконец, я всегда перечеркиваю двумя параллельными линиями ту ветвь или ветви, которые указывают на альтернативу, от которой я решил отказаться (в данном случае такой ветвью будет «не разрабатывать продукт»). Не все так поступают, но, на мой взгляд, это делает дерево более читабельным. Важно помнить, что лицо, принимающее решение, не контролирует исходы, поэтому ветви, выходящие из точек исходов, никогда не перечеркиваются. Перечеркивание ветвей показано ниже на примере первоначального (предпочтительного) дерева:

Стоимость полной и неполной информации
Информация считается полной, если она является 100% достоверным прогнозом. Однако даже информация, которая не является 100% достоверным прогнозом, все же лучше, чем отсутствие какой-либо информации вообще. Такая информация называется неполной. Стоимость неполной информации рассчитать гораздо сложнее, такое задание может появится на экзамене, только если все остальные расчеты в вопросе будут очень простыми. В этой статье мы будем рассматривать только полную информацию, так как расчет стоимости неполной информации в примере, который предлагаю я, будет очень сложным, гораздо сложнее того, который может встретиться на экзамене.
Полная информация
Стоимость полной информации – это разница между ожидаемым значением исхода при наличии полной информации и ожидаемым значением исхода в отсутствие этой информации. Предположим, в нашем примере, что некое агентство может предоставить информацию о том, будет ли продукт успешным и какую прибыль в результате удастся получить: высокую, среднюю или низкую. Ожидаемое
значение полной информации можно рассчитать, используя таблицу. Для этого полезно иметь результаты расчетов совместных вероятностей, сделанных при построении второго дерева решений, поскольку в этом случае расчет ожидаемого значения можно представить следующим образом.
| Успех или неудача продукта и уровень спроса |
Совместная вероятность |
Прибыль минус затраты на разработку |
Продолжать? |
|
|---|---|---|---|---|
|
Успех и высокий |
0.14 |
$600,000 |
Да |
$84,000 |
|
Успех и средний |
0.35 |
$400,000 |
Да |
$140,000 |
|
Успех и низкий |
0.21 |
$200,000 |
Да |
$420,000 |
|
Неуспех и продажа |
0.18 |
($350,000) |
Нет |
0 |
| Неуспех и невозможность продать |
0.12 |
($400,000) |
Нет |
0 |
|
$266,000 |
Однако это можно сделать и с помощью вероятностей из нашего первоначального дерева, как показано в таблице ниже, которые затем нужно умножить на вероятность успеха или неудачи, т.е. на 0.7 или 0.3:
| Сценарий (уровень спроса) |
Вероятность |
Прибыль минус затраты на разработку |
Продолжать? |
|
|---|---|---|---|---|
|
Высокий |
0.20 |
$600,000 |
Да |
$120,000 |
|
Средний |
0.50 |
$400,000 |
Да |
$200,000 |
|
Низкий |
0.30 |
$200,000 |
Да |
$60,000 |
|
$380,000 |
Ожидаемое значение успеха при наличии полной информации = 0.7 x $380,000 = $266,000
|
Сценарий |
Вероятность |
Прибыль минус затраты на разработку |
Продолжать? |
|
|---|---|---|---|---|
|
Неуспех и продажа |
0.60 |
($350,000) |
Нет |
0 |
|
Неуспех и невозможность продать |
0.40 |
($400,000) |
Нет |
0 |
|
$0 |
Ожидаемое значение неудачи при наличии полной информации = 0.3 x $0 = $0. Таким образом, общее ожидаемое значение при наличии полной информации = $266,000
Независимо от того, какой метод используется, стоимость полной информации рассчитывается как разница между ожидаемым значением исхода при наличии полной информации и ожидаемым значением исхода в ее отсутствие, т. е. $266,000 – $155,000 = $111,000. Полученное значение представляет собой максимальную сумму, которую имеет смысл заплатить за полную информацию.
Неполная информация
В реальной жизни информация редко является полной. Как правило, удается получить лишь некоторую информацию о вероятностях возможных исходов. Расчет стоимости неполной информации довольно сложен, а на экзамене данного уровня любые расчетные задачи должны быть относительно простыми. Пример расчета стоимости неполной информации вы можете найти в рекомендованных учебниках. Здесь же достаточно сказать, что стоимость неполной информации всегда ниже стоимости полной информации, если только стоимость обеих не равна нулю. Так бывает, если дополнительная информация не влияет на принятие решения. Обратите внимание, что принципы, которые применяются при расчете стоимости неполной информации, ничем не отличаются от принципов, которые применяются при расчете стоимости полной информации.
Статья написана членом экзаменационного совета по курсу «Управление эффективностью бизнеса».
Деревья решений — один из методов автоматического анализа данных. Разбираем общие принципы работы и области применения.
- Терминология
- Структура дерева решений
- Задачи
- Процесс построения
- Основные этапы построения
- Выбор атрибута разбиения
- Статистический подход
- Критерий остановки алгоритма
- Отсечение ветвей
- Извлечение правил
- Преимущества алгоритма
- Области применения
Деревья решений являются одним из наиболее эффективных инструментов интеллектуального анализа данных и предсказательной аналитики, которые позволяют решать задачи классификации и регрессии.
Они представляют собой иерархические древовидные структуры, состоящие из решающих правил вида «Если …, то …». Правила автоматически генерируются в процессе обучения на обучающем множестве и, поскольку они формулируются практически на естественном языке (например, «Если объём продаж более 1000 шт., то товар перспективный»), деревья решений как аналитические модели более вербализуемы и интерпретируемы, чем, скажем, нейронные сети.
Поскольку правила в деревьях решений получаются путём обобщения множества отдельных наблюдений (обучающих примеров), описывающих предметную область, то по аналогии с соответствующим методом логического вывода их называют индуктивными правилами, а сам процесс обучения — индукцией деревьев решений.
В обучающем множестве для примеров должно быть задано целевое значение, т.к. деревья решений являются моделями, строящимися на основе обучения с учителем. При этом, если целевая переменная дискретная (метка класса), то модель называют деревом классификации, а если непрерывная, то деревом регрессии.
Основополагающие идеи, послужившие толчком к появлению и развитию деревьев решений, были заложены в 1950-х годах в области исследований моделирования человеческого поведения с помощью компьютерных систем. Среди них следует выделить работы К. Ховеленда «Компьютерное моделирование мышления»[1] и Е. Ханта и др. «Эксперименты по индукции»[2].
Дальнейшее развитие деревьев решений как самообучающихся моделей для анализа данных связано с именами Джона Р. Куинлена[3], который разработал алгоритм ID3 и его усовершенствованные модификации С4.5 и С5.0, а так же Лео Бреймана[4], который предложил алгоритм CART и метод случайного леса.
Терминология
Введем в рассмотрение основные понятия, используемые в теории деревьев решений.
Структура дерева решений
Собственно, само дерево решений — это метод представления решающих правил в иерархической структуре, состоящей из элементов двух типов — узлов (node) и листьев (leaf). В узлах находятся решающие правила и производится проверка соответствия примеров этому правилу по какому-либо атрибуту обучающего множества.
В простейшем случае, в результате проверки, множество примеров, попавших в узел, разбивается на два подмножества, в одно из которых попадают примеры, удовлетворяющие правилу, а в другое — не удовлетворяющие.

Затем к каждому подмножеству вновь применяется правило и процедура рекурсивно повторяется пока не будет достигнуто некоторое условие остановки алгоритма. В результате в последнем узле проверка и разбиение не производится и он объявляется листом. Лист определяет решение для каждого попавшего в него примера. Для дерева классификации — это класс, ассоциируемый с узлом, а для дерева регрессии — соответствующий листу модальный интервал целевой переменной.
Таким образом, в отличие от узла, в листе содержится не правило, а подмножество объектов, удовлетворяющих всем правилам ветви, которая заканчивается данным листом.
Очевидно, чтобы попасть в лист, пример должен удовлетворять всем правилам, лежащим на пути к этому листу. Поскольку путь в дереве к каждому листу единственный, то и каждый пример может попасть только в один лист, что обеспечивает единственность решения.
Задачи
Основная сфера применения деревьев решений — поддержка процессов принятия управленческих решений, используемая в статистике, анализе данных и машинном обучении. Задачами, решаемыми с помощью данного аппарата, являются:
- Классификация — отнесение объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные значения.
- Регрессия (численное предсказание) — предсказание числового значения независимой переменной для заданного входного вектора.
- Описание объектов — набор правил в дереве решений позволяет компактно описывать объекты. Поэтому вместо сложных структур, описывающих объекты, можно хранить деревья решений.
Процесс построения
Процесс построения деревьев решений заключается в последовательном, рекурсивном разбиении обучающего множества на подмножества с применением решающих правил в узлах. Процесс разбиения продолжается до тех пор, пока все узлы в конце всех ветвей не будут объявлены листьями. Объявление узла листом может произойти естественным образом (когда он будет содержать единственный объект, или объекты только одного класса), или по достижении некоторого условия остановки, задаваемого пользователем (например, минимально допустимое число примеров в узле или максимальная глубина дерева).
Алгоритмы построения деревьев решений относят к категории так называемых жадных алгоритмов. Жадными называются алгоритмы, которые допускают, что локально-оптимальные решения на каждом шаге (разбиения в узлах), приводят к оптимальному итоговому решению. В случае деревьев решений это означает, что если один раз был выбран атрибут, и по нему было произведено разбиение на подмножества, то алгоритм не может вернуться назад и выбрать другой атрибут, который дал бы лучшее итоговое разбиение. Поэтому на этапе построения нельзя сказать обеспечит ли выбранный атрибут, в конечном итоге, оптимальное разбиение.
В основе большинства популярных алгоритмов обучения деревьев решений лежит принцип «разделяй и властвуй». Алгоритмически этот принцип реализуется следующим образом. Пусть задано обучающее множество S, содержащее n примеров, для каждого из которых задана метка класса C_i(i=1..k), и m атрибутов A_j(j=1..m), которые, как предполагается, определяют принадлежность объекта к тому или иному классу. Тогда возможны три случая:
- Все примеры множества S имеют одинаковую метку класса C_i (т.е. все обучающие примеры относятся только к одному классу). Очевидно, что обучение в этом случае не имеет смысла, поскольку все примеры, предъявляемые модели, будут одного класса, который и «научится» распознавать модель. Само дерево решений в этом случае будет представлять собой лист, ассоциированный с классом C_i. Практическое использование такого дерева бессмысленно, поскольку любой новый объект оно будет относить только к этому классу.
- Множество S вообще не содержит примеров, т.е. является пустым множеством. В этом случае для него тоже будет создан лист (применять правило, чтобы создать узел, к пустому множеству бессмысленно), класс которого будет выбран из другого множества (например, класс, который наиболее часто встречается в родительском множестве).
- Множество S содержит обучающие примеры всех классов C_k. В этом случае требуется разбить множество S на подмножества, ассоциированные с классами. Для этого выбирается один из атрибутов A_j множества S который содержит два и более уникальных значения (a_1,a_2,…,a_p), где p — число уникальных значений признака. Затем множество S разбивается на p подмножеств (S_1,S_2,…,S_p), каждое из которых включает примеры, содержащие соответствующее значение атрибута. Затем выбирается следующий атрибут и разбиение повторяется. Это процедура будет рекурсивно повторяться до тех пор, пока все примеры в результирующих подмножествах не окажутся одного класса.
Описанная выше процедура лежит в основе многих современных алгоритмов построения деревьев решений. Очевидно, что при использовании данной методики, построение дерева решений будет происходить сверху вниз (от корневого узла к листьям).
В настоящее время разработано значительное число алгоритмов обучения деревья решений: ID3, CART, C4.5, C5.0, NewId, ITrule, CHAID, CN2 и т.д. Но наибольшее распространение и популярность получили следующие:
- ID3 (Iterative Dichotomizer 3) — алгоритм позволяет работать только с дискретной целевой переменной, поэтому деревья решений, построенные с помощью данного алгоритма, являются классифицирующими. Число потомков в узле дерева не ограничено. Не может работать с пропущенными данными.
- C4.5 — усовершенствованная версия алгоритма ID3, в которую добавлена возможность работы с пропущенными значениями атрибутов (по версии издания Springer Science в 2008 году алгоритм занял 1-е место в топ-10 наиболее популярных алгоритмов Data Mining).
- CART (Classification and Regression Tree) — алгоритм обучения деревьев решений, позволяющий использовать как дискретную, так и непрерывную целевую переменную, то есть решать как задачи классификации, так и регрессии. Алгоритм строит деревья, которые в каждом узле имеют только два потомка.
Основные этапы построения
В ходе построения дерева решений нужно решить несколько основных проблем, с каждой из которых связан соответствующий шаг процесса обучения:
- Выбор атрибута, по которому будет производиться разбиение в данном узле (атрибута разбиения).
- Выбор критерия остановки обучения.
- Выбор метода отсечения ветвей (упрощения).
- Оценка точности построенного дерева.
Рассмотрим эти этапы ниже.
Выбор атрибута разбиения
При формировании правила для разбиения в очередном узле дерева необходимо выбрать атрибут, по которому это будет сделано. Общее правило для этого можно сформулировать следующим образом: выбранный атрибут должен разбить множество наблюдений в узле так, чтобы результирующие подмножества содержали примеры с одинаковыми метками класса, или были максимально приближены к этому, т.е. количество объектов из других классов («примесей») в каждом из этих множеств было как можно меньше. Для этого были выбраны различные критерии, наиболее популярными из которых стали теоретико-информационный и статистический.
Теоретико-информационный критерий
Как следует из названия, критерий основан на понятиях теории информации, а именно — информационной энтропии.
H = -sum limits_{i=1}^{n} frac{N_i}{N},log,Bigl(frac{N_i}{N}Bigr)
где n — число классов в исходном подмножестве, N_i — число примеров i-го класса, N — общее число примеров в подмножестве.
Таким образом, энтропия может рассматриваться как мера неоднородности подмножества по представленным в нём классам. Когда классы представлены в равных долях и неопределённость классификации наибольшая, энтропия также максимальна. Если все примеры в узле относятся к одному классу, т.е. N=N_i, логарифм от единицы обращает энтропию в ноль.
Таким образом, лучшим атрибутом разбиения A_j будет тот, который обеспечит максимальное снижение энтропии результирующего подмножества относительно родительского. На практике, однако, говорят не об энтропии, а о величине, обратной ей, которая называется информацией. Тогда лучшим атрибутом разбиения будет тот, который обеспечит максимальный прирост информации результирующего узла относительно исходного:
text{Gain}(A)=text{Info}(S)-text{Info}(S_A),
где text{Info}(S) — информация, связанная с подмножеством S до разбиения, text{Info}(S_A) — информация, связанная с подмножеством, полученными при разбиении по атрибуту A.
Таким образом, задача выбора атрибута разбиения в узле заключается в максимизации величины text{Gain}(A), называемой приростом информации (от англ. gain — прирост, увеличение). Поэтому сам теоретико-информационный подход известен как критерий прироста информации. Он впервые был применён в алгоритме ID3, а затем в C4.5 и других алгоритмах.
Статистический подход
В основе статистического подхода лежит использование индекса Джини (назван в честь итальянского статистика и экономиста Коррадо Джини). Статистический смысл данного показателя в том, что он показывает — насколько часто случайно выбранный пример обучающего множества будет распознан неправильно, при условии, что целевые значения в этом множестве были взяты из определённого статистического распределения.
Таким образом индекс Джини фактически показывает расстояние между двумя распределениями — распределением целевых значений, и распределением предсказаний модели. Очевидно, что чем меньше данное расстояние, тем лучше работает модель.
Индекс Джини может быть рассчитан по формуле:
text{Gini}(Q)=1-sum limits_{i=1}^{n}p_i^2,
где Q — результирующее множество, n — число классов в нём, p_i — вероятность i-го класса (выраженная как относительная частота примеров соответствующего класса). Очевидно, что данный показатель меняется от 0 до 1. При этом он равен 0, если все примеры Q относятся к одному классу, и равен 1, когда классы представлены в равных пропорциях и равновероятны. Тогда лучшим будет то разбиение, для которого значение индекса Джини будут минимальным.
Критерий остановки алгоритма
Теоретически, алгоритм обучения дерева решений будет работать до тех пор, пока в результате не будут получены абсолютно «чистые» подмножества, в каждом из которых будут примеры одного класса. Правда, возможно при этом будет построено дерево, в котором для каждого примера будет создан отдельный лист. Очевидно, что такое дерево окажется бесполезным, поскольку оно будет переобученным — каждому примеру будет соответствовать свой уникальный путь в дереве, а следовательно, и набор правил, актуальный только для данного примера.
Переобучение в случае дерева решений ведёт к тем же последствиям, что и для нейронной сети — точное распознавание примеров, участвующих в обучении и полная несостоятельность на новых данных. Кроме этого, переобученные деревья имеют очень сложную структуру, и поэтому их сложно интерпретировать.
Очевидным решением проблемы является принудительная остановка построения дерева, пока оно не стало переобученным. Для этого разработаны следующие подходы.
- Ранняя остановка — алгоритм будет остановлен, как только будет достигнуто заданное значение некоторого критерия, например процентной доли правильно распознанных примеров. Единственным преимуществом подхода является снижение времени обучения. Главным недостатком является то, что ранняя остановка всегда делается в ущерб точности дерева, поэтому многие авторы рекомендуют отдавать предпочтение отсечению ветвей.
- Ограничение глубины дерева — задание максимального числа разбиений в ветвях, по достижении которого обучение останавливается. Данный метод также ведёт к снижению точности дерева.
- Задание минимально допустимого числа примеров в узле — запретить алгоритму создавать узлы с числом примеров меньше заданного (например, 5). Это позволит избежать создания тривиальных разбиений и, соответственно, малозначимых правил.
Все перечисленные подходы являются эвристическими, т.е. не гарантируют лучшего результата или вообще работают только в каких-то частных случаях. Поэтому к их использованию следует подходить с осторожностью. Каких-либо обоснованных рекомендаций по тому, какой метод лучше работает, в настоящее время тоже не существует. Поэтому аналитикам приходится использовать метод проб и ошибок.
Отсечение ветвей
Как было отмечено выше, если «рост» дерева не ограничить, то в результате будет построено сложное дерево с большим числом узлов и листьев. Как следствие оно будет трудно интерпретируемым. В то же время решающие правила в таких деревьях, создающие узлы, в которые попадают два-три примера, оказываются малозначимыми с практической точки зрения.
Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое число примеров из обучающей выборки. Поэтому представляет интерес подход, альтернативный ранней остановке — построить все возможные деревья и выбрать то из них, которое при разумной глубине обеспечивает приемлемый уровень ошибки распознавания, т.е. найти наиболее выгодный баланс между сложностью и точностью дерева.
К сожалению, это задача относится к классу NP-полных задач, что было показано Л. Хайфилем (L. Hyafill) и Р. Ривестом (R. Rivest), и, как известно, этот класс задач не имеет эффективных методов решения.
Альтернативным подходом является так называемое отсечение ветвей (pruning). Он содержит следующие шаги:
- Построить полное дерево (чтобы все листья содержали примеры одного класса).
- Определить два показателя: относительную точность модели — отношение числа правильно распознанных примеров к общему числу примеров, и абсолютную ошибку — число неправильно классифицированных примеров.
- Удалить из дерева листья и узлы, отсечение которых не приведёт к значимому уменьшению точности модели или увеличению ошибки.
Отсечение ветвей, очевидно, производится в направлении, противоположном направлению роста дерева, т.е. снизу вверх, путём последовательного преобразования узлов в листья. Преимуществом отсечения ветвей по сравнению с ранней остановкой является возможность поиска оптимального соотношения между точностью и понятностью дерева. Недостатком является большее время обучения из-за необходимости сначала построить полное дерево.
Извлечение правил
Иногда даже упрощённое дерево решений все ещё является слишком сложным для визуального восприятия и интерпретации. В этом случае может оказаться полезным извлечь из дерева решающие правила и организовать их в наборы, описывающие классы.
Для извлечения правил нужно отследить все пути от корневого узла к листьям дерева. Каждый такой путь даст правило, состоящее из множества условий, представляющих собой проверку в каждом узле пути.
Визуализация сложных деревьев решений в виде решающих правил вместо иерархической структуры из узлов и листьев может оказаться более удобной для визуального восприятия.
Преимущества алгоритма
Рассмотрев основные проблемы, возникающие при построении деревьев, было бы несправедливо не упомянуть об их достоинствах:
- быстрый процесс обучения;
- генерация правил в областях, где эксперту трудно формализовать свои знания;
- извлечение правил на естественном языке;
- интуитивно понятная классификационная модель;
- высокая точность предсказания, сопоставимая с другими методами анализа данных (статистика, нейронные сети);
- построение непараметрических моделей.
В силу этих и многих других причин, деревья решений являются важным инструментом в работе каждого специалиста, занимающегося анализом данных.
Области применения
Модули для построения и исследования деревьев решений входят в состав большинства аналитических платформ. Они являются удобным инструментом в системах поддержки принятия решений и интеллектуального анализа данных.
Деревья решений успешно применяются на практике в следующих областях:
- Банковское дело. Оценка кредитоспособности клиентов банка при выдаче кредитов.
- Промышленность. Контроль за качеством продукции (выявление дефектов), испытания без разрушений (например, проверка качества сварки) и т.д.
- Медицина. Диагностика заболеваний.
- Молекулярная биология. Анализ строения аминокислот.
- Торговля. Классификация клиентов и товаров.
Это далеко не полный список областей где можно использовать деревья решений. Вместе с анализом данных деревья решений постоянно расширяют круг своего использования, становясь важным инструментом управления бизнес-процессами и поддержки принятия решений.
Литература
- Hovland, C. I. (1960). Computer simulation of thinking. American Psychologist, 15(11), 687-693.
- Hunt, Earl B.; Janet Marin; Philip J. Stone (1966). Experiments in Induction. New York: Academic Press. ISBN 978-0-12-362350-8.
- Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1(1):81-106.
- Quinlan, J. Ross. C4.5: Programs for Machine learning. Morgan Kaufmann Publishers 1993.
- Breiman, Leo, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Wadsworth, Belmont, CA, 1984.
- Murthy, S. Automatic construction of decision trees from data: A Multi-disciplinary survey.1997.
- Buntine, W. A theory of classification rules. 1992.
- Machine Learning, Neural and Statistical Classification. Editors D. Mitchie et.al. 1994.
- Шеннон, К. Работы по теории информации и кибернетике. М. Иностранная литература, 1963.
- Айвазян С. А., Мхитарян В. С Прикладная статистика и основы эконометрики, М. Юнити, 1998.
Другие материалы по теме:
Деревья решений — C4.5 математический аппарат | Часть 1
Деревья решений — C4.5 математический аппарат | Часть 2
Рассказываем, как правильно использовать дерево решений для машинного обучения, визуализации данных и наглядной демонстрации процесса принятия решений. Пригодится не только аналитикам данных, но и тем, кто хочет найти методику, помогающую более взвешенно принимать решения в жизни и бизнесе.
Основные задачи, которые дерево решений решает в машинном обучении, анализе данных и статистике:
- Классификация — когда нужно отнести объект к конкретной категории, учитывая его признаки.
- Регрессия — использование данных для прогнозирования количественного признака с учетом влияния других признаков.
Деревья решений также могут помочь визуализировать процесс принятия решения и сделать правильный выбор в ситуациях, когда результаты одного решения влияют на результаты следующих решений. Попробуем объяснить, как это работает на простых примерах из жизни.
Что такое дерево решений
Визуально дерево решений можно представить как карту возможных результатов из ряда взаимосвязанных выборов. Это помогает сопоставить возможные действия, основываясь на их стоимости (затратах), вероятности и выгоде.
Как понятно из названия, для этого используют модель принятия решений в виде дерева. Такие древовидные схемы могут быть полезны и в процессе обсуждения чего-либо, и для составления алгоритма, который математически определяет наилучший выбор.
Обычно дерево решений начинается с одного узла, который разветвляется на возможные результаты. Каждый из них продолжает схему и создает дополнительные узлы, которые продолжают развиваться по тому же признаку. Это придает модели древовидную форму.
В дереве решений могут быть три разных типа узлов:
- Decision nodes — узлы решения, они показывают решение, которое нужно принять.
- Chance nodes — вероятностные узлы, демонстрируют вероятность определенных результатов.
- End nodes — замыкающие узлы, показывают конечный результат пути решения.
Преимущества и недостатки методики дерева решений
Преимущества метода:
- Деревья решений создаются по понятным правилам, они просты в применении и интерпретации.
- Можно обрабатывать как непрерывные, так и качественные (дискретные) переменные.
- Можно работать с пропусками в данных, деревья решений позволяют заполнить пустое поле наиболее вероятным значением.
- Помогают определить, какие поля больше важны для прогнозирования или классификации.
Недостатки метода:
- Есть вероятность ошибок в задачах классификации с большим количеством классов и относительно небольшим числом примеров для обучения.
- Нестабильность процесса: изменение в одном узле может привести к построению совсем другого дерева, что связано с иерархичностью его структуры.
- Процесс «выращивания» дерева решений может быть довольно затратным с точки зрения вычислений, ведь в каждом узле каждый атрибут должен раскладываться до тех пор, пока не будет найден наилучший вариант решения или разветвления. В некоторых алгоритмах используются комбинации полей, в таком случае приходится искать оптимальную комбинацию по «весу» коэффициентов. Алгоритм отсечения (или «обрезки») также дорогостоящий, так как необходимо сформировать и сравнить большое количество потенциальных ветвей.
Как создать дерево решений
Для примера предлагаем сценарий, в котором группа астрономов изучает планету — нужно выяснить, сможет ли она стать новой Землей.
Существует N решающих факторов, которые нужно тщательно изучить, чтобы принять разумное решение. Этими факторами может быть наличие воды на планете, температурный диапазон, подвержена ли поверхность постоянным штормам, сможет ли выжить флора и фауна в этом климате и еще сотни других параметров.
Задачу будем исследовать через дерево решений.
- Пригодная для обитания температура находится в диапазоне от 0 до 100 градусов Цельсия?
Таким образом, у нас получилось завершенное дерево решений.
Правила классификации
Сначала определимся с терминами и их значениями.
Правила классификации — это случаи, в которых учитываются все сценарии, и каждому присваивается переменная класса.
Переменная класса — это конечный результат, к которому приводит наше решение. Переменная класса присваивается каждому конечному, или листовому, узлу.
Вот правила классификации из примера дерева решений про исследование новой планеты:
- Если температура не находится в диапазоне от -0,15 °C до 99,85 °C, то выживание затруднительно.
- Если температура находится в диапазоне от -0,15 °C до 99,85 °C, но нет воды, то выживание затруднительно.
- Если температура находится в диапазоне от -0,15 °C до 99,85 °C, есть вода, но нет флоры и фауны, то выживание затруднительно.
- Если температура находится в диапазоне от -0,15 °C до 99,85 °C, есть вода, есть флора и фауна, поверхность не подвержена штормам, то выживание возможно.
- Если температура находится в диапазоне от -0,15 °C до 99,85 °C, есть вода, есть флора и фауна, но поверхность подвержена штормам, то выживание затруднительно.
Почему сложно построить идеальное дерево решений
В структуре дерева решений выделяют следующие компоненты:
- Root Node, или корневой узел — тот, с которого начинается дерево, в нашем примере в качестве корня рассматривается фактор «температура».
- Internal Node, или внутренний узел — узлы с одним входящим и двумя или более исходящими соединениями.
- Leaf Node, или листовой узел — это заключительный элемент без исходящих соединений.
Когда создается дерево решений, мы начинаем от корневого узла, проверяем условия тестирования и присваиваем элемент управления одному из исходящих соединений. Затем снова тестируем условия и назначаем следующий узел. Чтобы считать дерево законченным, нужно все условия привести к листовому узлу (Leaf Node). Листовой узел будет содержать все метки класса, которые влияют на «за» и «против» в принятии решения.
Обратите внимание — мы начали с признака «температура», посчитали его корнем. Если выбрать другой признак, то и дерево получится другим. В этом принцип метода — нужно выбрать оптимальный корень и с помощью него выстраивать дерево, решить, какое же дерево нужно для выполнения задачи.
Есть разные способы найти максимально подходящее дерево решений для конкретной ситуации. Ниже расскажем об одном из них.
Как использовать жадный алгоритм для построения дерева решений
Смысл подхода — принцип так называемой жадной максимизации прироста информации. Он основан на концепции эвристического решения проблем — делать оптимальный локальный выбор в каждом узле, так достигая решения, которое с высокой вероятностью будет самым оптимальным.
Упрощенно алгоритм можно объяснить так:
- На каждом узле выбирайте оптимальный способ проверки.
- После разбейте узел на все возможные результаты (внутренние узлы).
- Повторите шаги, пока все условия не приведут к конечным узлам.
Главный вопрос: «Как выбрать начальные условия для проверки?». Ответ заключается в значениях энтропии и прироста информации (информационном усилении). Рассказываем, что это и как они влияют на создание нашего дерева:
- Энтропия — в дереве решений это означает однородность. Если данные полностью однородны, она равна 0; в противном случае, если данные разделены (50-50%), энтропия равна 1. Проще этот термин можно объяснить так — это то, как много информации, значимой для принятия решения, мы не знаем.
- Прирост информации — величина обратная энтропии, чем выше прирост информации, тем меньше энтропия, меньше неучтенных данных и лучше решение.
Итого — мы выбираем атрибут, который имеет наибольший показатель прироста информации, чтобы пойти на следующий этап разделения. Это помогает выбрать лучшее решение на любом узле.
Смотрите на примере. У нас есть большое количество таких данных:
Здесь может быть n деревьев решений, которые формируются из этого набора атрибутов.
Ищем оптимальное решение с жадным алгоритмом
Первый шаг: создать два условных класса:
- «Да», человек может купить компьютер.
- «Нет», возможность отсутствует.
Второй шаг — вычислить значение вероятности для каждого из них.
- Для результата «Да», «buys_computer=yes», формула выглядит так:
- Для результата «Нет», «buys_computer=no», вот так:
$$P(buys = yes) = {9 over 14}$$
$$P(buys = no) = {5 over 14}$$
Третий шаг: вычисляем значение энтропии, поместив значения вероятности в формулу.
$$Info(D) = I(9,5) = -{9 over 14}log_{2}({9 over 14})-{5 over 14}log_{2}({5 over 14})=0,940$$
Это довольно высокий показатель энтропии.
Четвертый шаг: углубляемся и считаем прирост информации для каждого случая, чтобы вычислить подходящий корневой атрибут для дерева решения.
Здесь нужно пояснение. Например, что будет означать показатель прироста информации, если за основу взять атрибут «Возраст»? Эти данные показывают, сколько людей, попадающих в определенную возрастную группу, покупают и не покупают продукт.
Допустим, среди людей в возрасте 30 лет и младше покупают (Да) два человека, не покупают (Нет) три человека. Info(D) рассчитывается для последних трех категорий людей — соответственно, Info(D) будем считать по сумме этих трех диапазонов значений возраста.
В итоге разница между общей энтропией Info(D) и энтропией для возраста Info(D) age (пусть она равна 0,694) будет нужным значением прироста информации. Вот формула:
$$Gain(age)=Info(D)-Info_{age}(D)=0,246$$
Сравним показатели прироста информации для всех атрибутов:
- Возраст = 0,246.
- Доход = 0.029.
- Студент = 0,151.
- Кредитный рейтинг = 0,048.
Получается, что прирост информации для атрибута возраста является самым значимым — значит, стоит использовать его. Аналогично мы сравниваем прирост в информации при каждом разделении, чтобы выяснить, брать этот атрибут или нет.
Таким образом, оптимальное дерево выглядит так:
Правила классификации для этого дерева можно записать следующим образом:
- Если возраст человека меньше 30 лет и он не студент, то не будет покупать компьютер.
- Если возраст человека меньше 30 лет, и он студент, то купит компьютер.
- Если возраст человека составляет от 31 до 40 лет, он, скорее всего, купит компьютер.
- Если человек старше 40 лет и имеет отличный кредитный рейтинг, то не будет покупать компьютер.
- Если возраст человека превышает 40 лет, при среднем кредитном рейтинге он, вероятно, купит компьютер.
Вот мы и достигли оптимального дерева решений. Готово.