Структурные
средние величины
Мода —
это наиболее часто встречающийся вариант
ряда. Мода применяется, например, при
определении размера одежды, обуви,
пользующейся наибольшим спросом у
покупателей. Модой для дискретного ряда
является варианта, обладающая наибольшей
частотой. При вычислении моды для
интервального вариационного ряда
необходимо сначала определить модальный
интервал (по максимальной частоте), а
затем — значение модальной величины
признака по формуле:Кроме степенных
средних в статистике для относительной
характеристики величины варьирующего
признака и внутреннего строения рядов
распределения пользуются структурными
средними, которые представлены ,в
основном, модой и медианой.
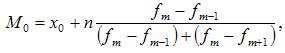
где:
![]() —
—
значение моды
![]() —
—
нижняя граница
модального интервала
![]() —
—
величина интервала
![]() —
—
частота модального
интервала
![]() —
—
частота интервала,
предшествующего модальному
![]() —
—
частота интервала,
следующего за модальным
Медиана
— это значение признака, которое
лежит в основе ранжированного ряда и
делит этот ряд на две равные по численности
части.
Для
определения медианы в дискретном
ряду при наличии частот сначала
вычисляют полусумму частот ![]() ,
,
а затем определяют, какое значение
варианта приходится на нее. (Если
отсортированный ряд содержит нечетное
число признаков, то номер медианы
вычисляют по формуле:
Ме =
(n(число
признаков в совокупности) +
1)/2,
в
случае четного числа признаков медиана
будет равна средней из двух признаков
находящихся в середине ряда).
При
вычислении медианы для интервального
вариационного ряда сначала определяют
медианный интервал, в пределах которого
находится медиана, а затем — значение
медианы по формуле:
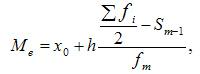
где:
![]() —
—
искомая медиана
![]() —
—
нижняя граница
интервала, который содержит медиану
![]() —
—
величина интервала
![]() —
—
сумма частот или
число членов ряда
![]() —
—
сумма накопленных частот интервалов,
предшествующих медианному
![]() —
—
частота медианного
интервала
Пример.
Найти моду и медиану.
|
Возрастные |
Число |
Сумма |
|
До |
346 |
346 |
|
20 — |
872 |
1218 |
|
25 |
1054 |
2272 |
|
30 — |
781 |
3053 |
|
35 — |
212 |
3265 |
|
40 — |
121 |
3386 |
|
45 |
76 |
3462 |
|
Итого |
3462 |
Решение:
В
данном примере модальный интервал
находится в пределах возрастной группы
25-30 лет, так как на этот интервал приходится
наибольшая частота (1054).
Рассчитаем
величину моды:
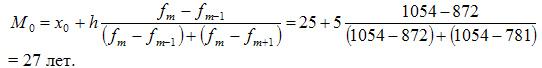
Это
значит что модальный возраст студентов
равен 27 годам.
Вычислим
медиану. Медианный интервал находится
в возрастной группе 25-30 лет, так как в
пределах этого интервала расположена
варианта, которая делит совокупность
на две равные части (Σfi/2
= 3462/2 = 1731). Далее подставляем в формулу
необходимые числовые данные и получаем
значение медианы:

Это
значит что одна половина студентов
имеет возраст до 27,4 года, а другая свыше
27,4 года.
Кроме
моды и медианы могут быть использованы
такие показатели, как квартили, делящие
ранжированный ряд на 4 равные части,
децили -10 частей и перцентили — на 100
частей.
Определение
моды и медианы графическим методом
Моду
и медиану в интервальном ряду можно
определить графически.
Мода определяется по гистограмме
распределения. Для этого выбирается
самый высокий прямоугольник, который
является в данном случае модальным.
Затем правую вершину модального
прямоугольника соединяем с правым
верхним углом предыдущего прямоугольника.
А левую вершину модального прямоугольника
– с левым верхним углом последующего
прямоугольника. Из точки их пересечения
опускаем перпендикуляр на ось абсцисс.
Абсцисса точки пересечения этих прямых
и будет модой распределения (рис.
5.3).
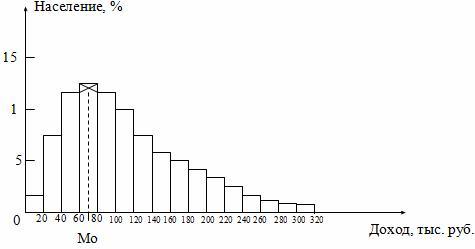
Рис.
5.3. Графическое определение моды по
гистограмме.
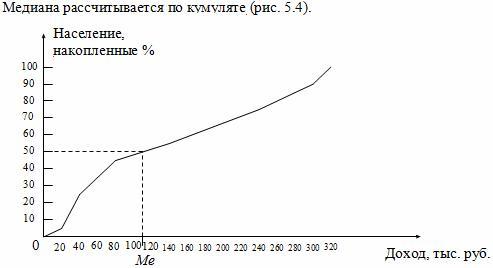
Рис.
5.4. Графическое определение медианы по
кумуляте
Для
определения медианы из точки на шкале
накопленных частот (частостей),
соответствующей 50 %, проводится прямая,
параллельная оси абсцисс до пересечения
с кумулятой. Затем из точки пересечения
опускается перпендикуляр на ось абсцисс.
Абсцисса точки пересечения является
медианой.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дискретный вариационный ряд и его характеристики
- Классификация рядов распределения
- Дискретный вариационный ряд, полигон частот и кумулята
- Выборочная средняя, мода и медиана
- Степень асимметрии вариационного ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования дискретного вариационного ряда
- Примеры
п.1. Классификация рядов распределения
Статистический ряд распределения – это количественное распределение единиц совокупности на однородные группы по некоторому варьирующему признаку.
В зависимости от природы признака различают атрибутивные и вариационные ряды.
Атрибутивный ряд распределения построен на качественном признаке.
Вариационный ряд распределения построен на количественном признаке.
Например:
Качественными признаками, которые не поддаются измерению, являются: профессия, пол, национальность и т.п.
Количественными признаками, которые можно подсчитать или измерить, являются: количество людей в группе, число повторений в опыте, возраст, вес, рост, скорость, температура и т.п.
По упорядоченности вариационные ряды делятся на упорядоченные (ранжированные) и неупорядоченные. Упорядочить ряд можно по возрастанию или убыванию исследуемого признака.
По характеру непрерывности признака вариационные ряды делятся на дискретные и интервальные.
Например:
Дискретными признаками, которые принимают отдельные значения, являются: количество людей в группе, число детей в семье, количество домов, число опытов и т.п.
Непрерывными признаками, которые могут принимать любые значения в интервале, являются: возраст, вес, рост, скорость, температура и т.п.
Варианты – это отдельные значения признака, которые он принимает в вариационном ряду.
Частоты – это численности отдельных вариант.
Например:
Распределение учеников по оценкам за контрольную работу
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
В данном ряду признак – это оценка, варианты признака (x_i) – это множество {2;3;4;5}, частоты (f_i) – это количество учеников, получивших каждую из оценок.
п.2. Дискретный вариационный ряд, полигон частот и кумулята
Дискретный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся прерывно и принимающему конечное множество значений.
Общий вид дискретного вариационного ряда
| Варианты, (x_i) | (x_1) | (x_2) | … | (x_k) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k — число вариант исследуемого признака.
Тогда общее количество исходов (число единиц в совокупности): (N=sum_{i=1}^k f_i)
Полигон частот – это ломаная, которая соединяет точки ((x_i,f_i)).
Например:
| Для распределения учеников по оценкам из нашего примера получаем такой полигон: |  |
Относительная частота варианты (x_i) — это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$ Относительная частота (w_i) является эмпирической оценкой вероятности варианты (x_i) в исследуемом ряду.
Полигон относительных частот – это ломаная, которая соединяет точки ((x_i,w_i)).
Полигон относительных частот является эмпирическим законом распределения исследуемого признака.
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)).
Ступенчатая кривая (F(x_i)), построенная по точкам ((x_i,S_i)), является эмпирической функцией распределения исследуемого признака.
Например:
Проведем необходимые расчеты и построим полигон относительных частот, кумуляту и эмпирическую функцию распределения учеников по оценкам.
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (w_i) | 0,0909 | 0,4545 | 0,3030 | 0,1515 | 1 |
| (S_i) | 0,0909 | 0,4545 | 0,8485 | 1 | — |
Полигон относительных частот (эмпирический закон распределения)
Кумулята (красная ломаная) и эмпирическая функция распределения (ступенчатая синяя кривая).
Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 2\ 0,0909, 2lt xleq 3\ 0,5455, 3lt xleq 4\ 0,8485, 4lt xleq 5\ 1, xgt 5 end{cases} $$
п.3. Выборочная средняя, мода и медиана
Выборочная средняя дискретного вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Мода дискретного вариационного ряда – это варианта с максимальной частотой: $$ M_o=x*, f(x*)=underset{i=overline{1,k}}{max}f_i $$ Мод может быть несколько. Тогда говорят, что ряд мультимодальный.
На полигоне частот мода – это абсцисса самой высокой точки.
Медиана дискретного вариационного ряда – это значение варианты посредине упорядоченного ряда.
Алгоритм:
1. Отсортировать ряд по возрастанию.
2а. Если общее количество измерений N нечётное, найти (m=lceilfrac N2rceil) и округлить в сторону увеличения. (M_e=x_m) — искомая медиана.
2б. Если общее количество измерений N чётное, найти (m=frac N2) и вычислить медиану как среднее (M_e=frac{x_m+x_{m+1}}{2}).
На графике кумуляты медиана – это абсцисса первой точки слева, ордината которой превысила 0,5.
Например:
1) Найдем выборочную среднюю для распределения учеников по оценкам:
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (x_if_i) | 6 | 45 | 40 | 25 | 116 |
$$ X_{cp}=frac{6+45+40+25}{33}=frac{116}{33}approx 3,5 $$ Средняя оценка за контрольную – 3,5.
2) Найдем моду. Максимальная частота – 15 человек – у троечников. Значит: (M_o=3).
3) Найдем медиану. Общее количество измерений N=33 — нечетное.
Находим: (m=lceilfrac N2rceil=17)
Смотрим на ряд слева направо. Сначала у нас идет 3 двоечника, затем 15 троечников.
Вместе их 18, и 17-й человек в ряду — троечник. Группа троечников является медианной: (M_e=3).
Также, медиану можно найти по графику кумуляты. (3;0,5455) – это первая слева точка, в которой ордината больше 0,5. Значит, медиана равна абсциссе этой точки, т.е. (M_e=3).
п.4. Степень асимметрии вариационного ряда
В рядах с асимметрией или выбросами выборочная средняя не отражает в полной мере особенности исследуемого признака. Типичный случай – значение среднего уровня доходов в странах с высоким индексом Джини, где 5% населения получает 95% доходов. Или анекдотичный случай со «средней температурой по больнице».
Поэтому, кроме средней, в статистическом исследовании всегда следует определять моду и медиану.
Мода, медиана и выборочная средняя совпадут, если вариационный ряд является симметричным: $$ X_{cp}=M_o=M_e $$ Если вершина распределения сдвинута влево и правая часть ветви длиннее левой (длинный правый хвост), такая асимметрия называется правосторонней. При правосторонней асимметрии: $$ M_olt M_elt X_{cp} $$ Если вершина распределения сдвинута вправо и левая часть ветви длиннее правой (длинный левый хвост), такая асимметрия называется левосторонней. При левосторонней асимметрии: $$ M_ogt M_egt X_{cp} $$ Для умеренно асимметричных рядов (по Пирсону) модуль разности между модой и средней не более 3 раз превышает модуль разности между медианой и средней: $$ frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}geq 3 $$
Например:
Для распределения учеников по оценкам мы получили (X_{cp}=3,5; M_o=3; M_e=3).
Т.к. средняя оказалась больше моды и медианы, наше распределение имеет правостороннюю асимметрию (что видно на полигоне частот – правый хвост длиннее).
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{0,5}{0,5}=1lt 3), т.е. распределение умеренно асимметрично.
п.5. Выборочная дисперсия и СКО
Выборочная дисперсия дискретного вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac{(x_1-X_{cp})^2 f_1+(x_2-X_{cp})^2 f_2+…+(x_k-X_{cp})^2 f_k}{N}=\ =frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
1) Найдем выборочную дисперсию для распределения учеников по оценкам:
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (x_i^2) | 4 | 9 | 16 | 25 | — |
| (x_i^2 f_i) | 12 | 135 | 160 | 125 | 432 |
$$ D=frac{12+135+160+125}{33}-3,5^2=frac{432}{33}-3,5^2approx 0,73 $$ 2) Значение СКО: (sigma=sqrt{D}approx 0,86)
п.6. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия дискретного вариационного ряда определяется как: begin{gather*} S^2=frac{1}{N-1}sum_{i=1}^k(x_i-X_{cp})^2 f_i=frac{N}{N-1}D end{gather*}
В теоретической статистике доказывается, что выборочная дисперсия D является смещенной оценкой дисперсии при распространении на генеральную совокупность.
А именно, выборочная дисперсия D всегда меньше математического ожидания для дисперсии генеральной совокупности.
Исправленная выборочная дисперсия S2 является несмещенной оценкой.
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Если показатель вариации V<33%, то выборка считается однородной, т.е. большинство полученных в ней вариант находятся недалеко от средней, и выборочная средняя хорошо характеризует среднюю генеральной совокупности.
В противном случае, выборка неоднородна. Варианты в выборке находятся далеко от средней, есть выбросы. А значит, и в генеральной совокупности они возможны. Т.е., распространять результаты выборки на генеральную совокупность нельзя.
Если исследуется не выборка, а вся генеральная совокупность, дисперсию «исправлять» не нужно.
Например:
Для распределения учеников по оценкам получаем:
1) Исправленная выборочная дисперсия $$ S^2=frac{N}{N-1}D=frac{33}{32}cdot 0,73approx 0,76 $$ 2) Стандартное отклонение $$ x=sqrt{S^2}approx 0,87 $$ 3) Коэффициент вариации: $$ V=frac{0,87}{3,5}cdot 100text{%}approx 24,8text{%}lt 33text{%} $$ Выборка является однородной.
Это означает, что согласно коэффициенту вариации полученные результаты контрольной работы можно рассматривать в качестве «типичных» и распространить их на генеральную совокупность, т.е. на всех школьников, которые будут писать эту работу.
п.7. Алгоритм исследования дискретного вариационного ряда
На входе: таблица с вариантами (x_i) и частотами (f_i, i=overline{1,k})
Шаг 1. Составить расчетную таблицу. Найти (w_i,S_i,x_if_i,x_i^2,x_i^2f_i)
Шаг 2. Построить полигон относительных частот (эмпирический закон распределения) и график кумуляты с эмпирической функцией распределения. Записать эмпирическую функцию распределения.
Шаг 3. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 4. Найти выборочную дисперсию и СКО.
Шаг 5. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.8. Примеры
Пример 1. На площадке фриланса была проведена выборка из 100 фрилансеров и подсчитано количество постоянных заказчиков, с которыми они работают.
В результате было получено следующее распределение:
| Число постоянных заказчиков | 0 | 1 | 2 | 3 | 4 | 5 |
| Число фрилансеров | 22 | 35 | 27 | 11 | 3 | 1 |
Исследуйте полученный вариационный ряд.
1) Вариационный ряд является дискретным.
Исследуемый признак – «число постоянных заказчиков».
Варианты признака (x_iinleft{0;1;..;5right}). Количество вариант k=6.
Составим расчетную таблицу:
| (x_i) | 0 | 1 | 2 | 3 | 4 | 5 | ∑ |
| (f_i) | 23 | 35 | 27 | 11 | 3 | 1 | 100 |
| (w_i) | 0,23 | 0,35 | 0,27 | 0,11 | 0,03 | 0,01 | — |
| (S_i) | 0,23 | 0,58 | 0,85 | 0,96 | 0,99 | 1 | — |
| (x_if_i) | 0 | 35 | 54 | 33 | 12 | 5 | 139 |
| (x_i^2) | 0 | 1 | 4 | 9 | 16 | 25 | — |
| (x_i^2f_i) | 0 | 35 | 108 | 99 | 48 | 25 | 315 |
2) Полигон относительных частот (эмпирический закон распределения):
Кумулята и эмпирическая функция распределения:
$$ F(x)= begin{cases} 0, xleq 0\ 0,23, 0lt xleq 1\ 0,58, 1lt xleq 2\ 0,85, 2lt xleq 3\ 0,96, 3lt xleq 4\ 0,99, 4lt xleq 5\ 1, xgt 5 end{cases} $$ 3) Выборочная средняя: $$ X_{cp}=frac1Nsum_{i=1}^k x_if_i= frac{1}{100}cdot 139=1,39 $$ Мода (абсцисса самой высокой точки на полигоне частот): (M_0=1).
Медиана (абсцисса первой слева точки на кумуляте, где значение превысило 0,5): точка (1;0,58), (M_e=1).
(X_{cp}gt M_e=M_0) – распределение асимметрично, с правосторонней асимметрией.
При этом (frac{|M_0-X_{cp}|}{|M_e-X_{cp}|}=frac{0,39}{0,39}=1lt 3), т.е. распределение умеренно асимметрично.
4) Выборочная дисперсия: $$ D=frac1Nsum_{i=1}^k x_i^2f_i-X_{cp}^2=frac{1}{100}cdot 315-1,39^2=1,2179approx 1,218 $$ CKO: $$ sigma=sqrt{D}approx 1,104 $$
5) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{100}{99}cdot 1,218approx 1,230 $$ Стандартное отклонение выборки: $$ s=sqrt{S^2}approx 1,109 $$ Коэффициент вариации: $$ V=frac{s}{X_{cp}}cdot 100text{%}=frac{1,109}{1,39}cdot 100text{%}approx 79,8text{%}gt 33text{%} $$ Представленная выборка неоднородна. Полученное значение средней (X_{cp}=1,39) не может быть распространено на генеральную совокупность всех фрилансеров.
8.2. Медиана, квартили, децили
Медиана — это значение признака, которое делит статистическую совокупность на две равные части: половина единиц совокупности имеет значения признака не меньше медианы, другая половина — значения признака не больше медианы.
Значения изучаемого признака всех единиц статистической совокупности можно расположить в порядке возрастания (или убывания). В этом случае мы получим ранжированный ряд. Если число единиц совокупности нечетное, то значение признака, находящееся в середине ранжированного ряда, будет являться медианой. Если число единиц совокупности четное, то медианой будет средняя величина из двух значений признака, находящихся в середине ряда.
Пример 8.5. Имеются следующие данные о результатах сдачи экзамена по статистике в студенческой группе:
| Номер студента | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Оценка по статистике | 3 | 4 | 2 | 3 | 4 | 4 | 4 | 3 | 4 | 5 | 5 |
Представим их в виде ранжированного ряда:
| Номер студента | 3 | 1 | 4 | 8 | 2 | 5 | 6 | 7 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Оценка по статистике | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 5 | 5 |
Как видим, в ранжированном ряду оценки расположились следующим образом: сначала записана одна неудовлетворительная оценка (ее получил студент, имеющий в ведомости номер 3), затем три оценки «удовлетворительно», пять оценок «хорошо» и две оценки «отлично». В середине ранжированного ряда, имеющего нечетное число членов, стоит оценка «4», которую получил студент, записанный в ведомости под номером 5. Следовательно, оценка «4 (хорошо)» является медианой для данного ряда распределения. Пять студентов получили оценки 4 и ниже (2, 3, 3, 3, 4), другие пять студентов — 4 и выше (4, 4, 4, 5, 5).
Пример 8.6. Имеются данные о цене антоновских яблок в шести магазинах города. Представим их сразу в виде ранжированного ряда:
| Название магазина | «Огонек» | «Маяк» | «Заря» | «Татьяна» | «Ночной» | «Любимый» |
|---|---|---|---|---|---|---|
| Цена яблок, руб. за кг | 40 | 41 | 42 | 44 | 44 | 45 |
В середине ранжированного ряда находятся цены двух магазинов, причем они разные. Медиана определяется как средняя величина из этих значений признака. Она равна 43 руб. [(42 + 44) : 2 = 43].
Таким образом, в 50% магазинов города яблоки продаются по цене не выше 43 руб. за килограмм, а в других 50% магазинов — по цене не ниже 43 руб.
Квартили (Q) делят ранжированный ряд на четыре равные части: первый квартиль (Q1) включает значения признака, не превышающие 25% единиц совокупности, второй квартиль (Q2) — совпадает с медианой (Ме), третий квартиль (Q3) — значения признака, не превышающие 75% единиц совокупности (рис. 8.3).
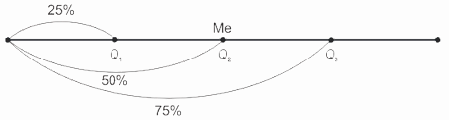
Рис.
8.3.
Деление ранжированного ряда на четыре равные части
Децили (D) делят ранжированный ряд на десять равных частей: первым децилем (D1) является значение признака, которое не превышает 10% единиц совокупности, вторым (D2) — 20%, третьим (D3) — 30% и т.д. При этом пятый дециль (D5) совпадает с медианой и вторым квартилем (Q2) (рис. 8.4).

Рис.
8.4.
Деление ранжированного ряда на десять равных частей
Медиана, квартили и децили относятся к группе квантилей. Квантили — это показатели, которые делят вариационные ряды на определенное количество равных частей. Среди них, помимо названных, также имеются квантили, которые делят ряд на пять равных частей, перцентили — на сто и т.д.
Структурные показатели не зависят от того, имеются ли в статистической совокупности аномальные (резко выделяющиеся) наблюдения. И если средняя величина при их наличии теряет свою практическую значимость, то информативность медианы наоборот усиливается — она начинает выполнять функции средней, т.д. характеризовать центр совокупности.
Способы расчета рассматриваемых структурных показателей зависят от вида вариационного ряда. Рассмотрим их подробнее.
8.2.1. Определение структурных средних в дискретных вариационных рядах
Для определения медианы в дискретных вариационных рядах:
- находят ее порядковый номер по формуле

- строят ряд накопленных частот;
- находят накопленную частоту, которая равна порядковому номеру медианы или его превышает;
- варианта, соответствующая данной накопленной частоте, является медианой.
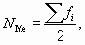
Пример 8.7. Определим медианный стаж сотрудников страховой компании на основе следующих данных:
| Время работы, лет, xi | Число сотрудников, чел., fi | Накопленная частота, Si |
|---|---|---|
| 1 | 5 | 5 |
| 2 | 7 | 12 |
| 3 | 4 | 16 |
| 4 | 9 | 25 |
| 5 | 13 | 38 |
| 6 | 10 | 48 |
| 7 | 16 | 64 |
| 8 | 13 | 77 |
| Итого | 77 | — |
Номер медианы равен
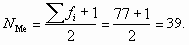
Для того чтобы найти значение варианты, стоящей на 39 месте, рассчитаем накопленные частоты. Для пятой группы накопленная частота равна 38. Это означает, что 38 работников имеют стаж работы 5 лет и меньше. Для шестой группы накопленная частота — 48 (она первая превышает порядковый номер медианы), следовательно, в эту группу входят сотрудники с порядковыми номерами от 39 до 48, в том числе и искомый 39-й сотрудник. Стаж работы сотрудников в шестой группе — 6 лет. Значит, Ме = 6. Итак, 50% сотрудников работают в данной страховой компании не более шести лет.
Квартили и децили определяют аналогично медиане: сначала находят их номер, затем среди накопленных частот ищут такую, которая первая равна или превышает порядковый номер показателя, ей соответствует варианта, которая является искомым показателем. Номера квартилей рассчитываются по формулам:
Порядковые номера децилей исчисляются следующим образом:
Определим квартили по данным примера 8.7. Их номера равны:
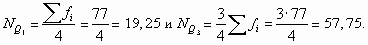
Первая накопленная частота, превышающая 19,25, равна 25. Ей соответствует варианта 4, являющаяся первым квартилем. Первая накопленная частота, которая превышает 57,75 — это 64; ей соответствует варианта, равная 7. Это третий квартиль. Итак, 25% сотрудников работают в данной компании не более четырех лет, а 75% — не более семи лет.
Аналогично определяются децили. Например, восьмой дециль вычисляется следующим образом:

Накопленная частота 64 — первая, превышающая ND8, ей соответствует значение признака — 7 лет, т.д. у 80% сотрудников стаж работы в данной компании не превышает семи лет.
8.2.2. Определение структурных средних в интервальном вариационном ряду
В интервальных рядах сначала определяют медианный интервал. Для этого так же, как и в дискретных рядах, рассчитывают порядковый номер медианы

Накопленной частоте, которая равна номеру медианы или первая его превышает, в интервальном вариационном ряду соответствует медианный интервал. Обозначим эту накопленную частоту SМе. Непосредственно расчет медианы проводят по формуле:

где хМе — нижняя граница медианного интервала;
dMe — величина медианного интервала;
SMe — 1 — накопленная частота интервала, предшествующего медианному;
fMe — частота медианного интервала.
Пример 8.8. По следующим данным определим медианное значение суммы выданных банками кредитов:
| Сумма выданных кредитов, млн ден. ед. | Количество банков, fi | Накопленная частота, Si. |
|---|---|---|
| 20-40 | 8 | 8 |
| 40-60 | 15 | 23 |
| 60-80 | 21 | 44 |
| 80-100 | 12 | 56 |
| 100-120 | 9 | 65 |
| 120-140 | 7 | 72 |
| 140-160 | 4 | 76 |
| Итого | 76 | — |
Проведем расчет:
- определим порядковый номер медианы
- определим накопленную частоту медианного интервала: SМе > NМе; SМе = 44;
- определим соответствующий ей медианный интервал «60-80»;
- рассчитаем значение медианы по формуле
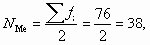

т.е. у 50% банков сумма выданных кредитов не превышает 74,286 млн ден. ед.
Далее произведем расчет квартилей и децилей в интервальном вариационном ряду.
Для приведенного интервального ряда необходимо определить:
- номер первого (нижнего) квартиля:
тогда ей соответствует интервал «40-60», в котором находится первый квартиль;
- номер третьего (верхнего) квартиля:
тогда ей соответствует интервал «100-120», в котором находится третий квартиль;
- первый (нижний) квартиль рассчитаем по формуле:
т.е. у 25% банков сумма выданных кредитов не превышает 54,7 млн ден. ед.;
- третий (верхний) квартиль рассчитаем по формуле:
т.е. у 75% банков сумма выданных кредитов не превышает 102,2 млн ден. ед.




Аналогично квартилям определяем децили. Формулы, используемые в ходе расчетов, поместим в таблицу.
|
|
|
Здесь хD — нижняя граница децильного интервала; dD — величина децильного интервала; SD — 1 — сумма накопленных частот интервала, предшествующего децильному; fD — частота децильного интервала. |
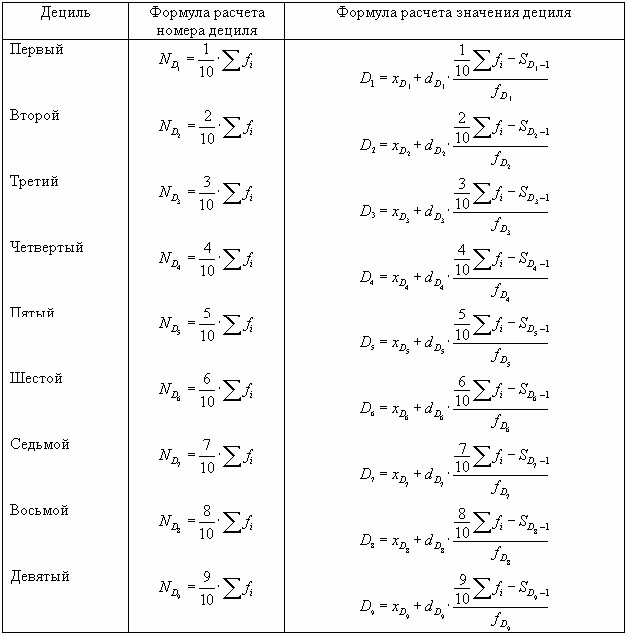
Номер шестого дециля равен: следовательно SQ6 = 56, этой накопленной частоте соответствует интервал «80-100», в котором находится шестой дециль. Величина децильного значения равна:
следовательно SQ6 = 56, этой накопленной частоте соответствует интервал «80-100», в котором находится шестой дециль. Величина децильного значения равна:  (млн ден. ед.), т.д. у 60% банков сумма выданных кредитов не превышает 82,7 млн ден. ед.
(млн ден. ед.), т.д. у 60% банков сумма выданных кредитов не превышает 82,7 млн ден. ед.
В статистике для характеристики степени неоднородности совокупности часто используют коэффициенты дифференциации (квартильные и децильные). Децильный коэффициент дифференциации представляет собой отношение девятого дециля к первому:

Данный коэффициент показывает, во сколько раз варианта, выше которой находятся 10% единиц совокупности, имеющих самые большие значения признака, больше варианты, ниже которой находятся 10% единиц совокупности с самыми маленькими значениями признака. Аналогично квартильный коэффициент дифференциации определяется как отношение третьего квартиля к первому.
В заключение отметим, что приблизительное равенство средней арифметической, моды и медианы, рассчитанных по отношению к одному и тому же ряду, говорит о том, что значения признака в изучаемой совокупности имеют нормальный закон распределения (или приближаются к нему).
Медиана может быть определена графически по кумуляте. Для этих целей на оси ординат, где отмечаются накопленные частоты, находится точка, соответствующая полусумме всех частот (т.е. порядковому номеру медианы). Из нее проводится прямая параллельно оси абсцисс до пересечения с графиком (кумулятой распределения). Абсцисса точки пересечения соответствует медиане данного ряда распределения.
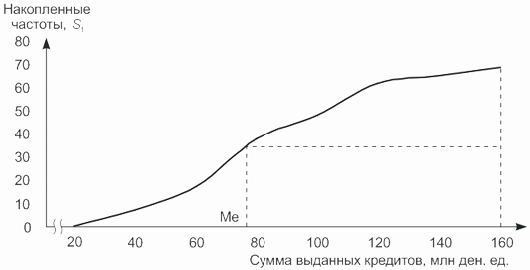
Рис.
8.5.
Определение медианы по кумуляте
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ № 4.
Расчёт структурных характеристик
вариационного ряда распределения.
Студент
должен:
знать:
— область применения и методику расчёта структурных
средних величин;
уметь:
— исчислять структурные средние величины;
— формулировать вывод по полученным результатам.
Методические указания
В
статистике исчисляются мода и медиана, которые относятся к структурным средним,
так как их величина зависит от строения статистической совокупности.
Расчёт моды
Модой называется значение признака
(варианта), чаще всеговстречающееся в изучаемой
совокупности. В дискретном ряду распределения модой будет варианта с наибольшей
частотой.
Например: Распределение проданной женской обуви по размерам характеризуется
следующим образом:
|
Размер |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
|
Количество |
8 |
19 |
34 |
108 |
72 |
51 |
6 |
2 |
В этом ряду
распределения модой является 37 размер,
т.е. Мо=37 размер.
Для
интервального ряда распределения мода определяется по формуле:
![]()
где ХMo —
нижняя граница модального интервала;
hMo — величина модального интервала;
fMo –
частота модального интервала;
fMo—1 и
fMo+1 – частота интервала соответственно
предшествующего модальному и следующего за ним.
Например:
Распределение рабочих по стажу работы характеризуется следующими данными.
|
Стаж работы, лет |
до 2 |
2-4 |
4-6 |
6-8 |
8-10 |
10 и более |
|
Число рабочих, чел. |
4 |
23 |
20 |
35 |
11 |
7 |
Определить моду
интервального ряда распределения.
Мода интервального ряда составляет
![]()
Мода всегда бывает
несколько неопределённой, т.к. она зависит от величины групп и точного
положения границ групп. Мода широко применяется в коммерческой практике при
изучении покупательского спроса, при регистрации цен и т.п.
Расчёт медианы
Медианой в статистике называется варианта,
расположенная в середине упорядоченного ряда данных, и которая делит
статистическую совокупность на две равные части так, что у одной половины
значения меньше медианы, а у другой половины – больше её. Для определения
медианы необходимо построить ранжированный ряд, т.е. ряд в порядке возрастания
или убывания индивидуальных значений признака.
В дискретном
упорядоченном ряду с нечётным числом членов медианой будет варианта,
расположенная в центре ряда.
Например: Стаж пяти рабочих составил 2, 4, 7, 9 и 10 лет. В таком ряду медиана-7
лет, т.е. Ме=7 лет
Если дискретный
упорядоченный ряд состоит из чётного числа членов, то медианой будет средняя
арифметическая из двух смежных вариант, стоящих в центре ряда.
Например: Стаж работы шести рабочих составил 1, 3, 4, 5, 10 и 11лет. В этом ряду
имеются две варианты, стоящие в центре ряда. Это варианты 4 и 5. Средняя
арифметическая из этих значений и будет медианой ряда
![]()
Чтобы определить медиану для
сгруппированных данных, необходимо считать накопленные частоты.
Например: По имеющимся данным определим медиану размера обуви
|
Размер обуви |
Количество проданных пар |
Сумма накопленных частот |
|
34 |
8 |
8 |
|
35 |
19 |
8+19=27 |
|
36 |
34 |
27+34=61 |
|
37 |
108 |
61+108=169 |
|
38 |
72 |
— |
|
39 |
51 |
— |
|
40 |
6 |
— |
|
41 |
2 |
— |
|
Итого |
300 |
Для
определения медианы надо подсчитать сумму накопленных частот ряда. Наращивание
итога продолжается до получения накопленной суммы частот, превышающей половину суммы частот
ряда. В нашем примере сумма частот составила 300, её половина – 150. Накопленная
сумма частот получилась равной 169. Варианта, соответствующая этой сумме, т.е.
37 и есть медиана ряда.
Если
же сумма накопленных частот против одной из вариант равна точно половине суммы
частот ряда, то медиана определяется как средняя арифметическая этой варианты и
последующей.
Например: По имеющимся данным определим медиану заработной платы рабочих
|
Месячная заработная плата, тыс.руб. |
Число рабочих, чел. |
Сумма накопленных частот |
|
14,0 |
2 |
2 |
|
14,2 |
6 |
2+6=8 |
|
16,0 |
12 |
8+12=20 |
|
16,8 |
16 |
— |
|
18,0 |
4 |
— |
|
Итого: |
40 |
— |
Медиана будет равна: ![]()
Медиана
интервального вариационного ряда распределения определяется по формуле:
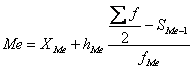
Где ХМе – нижняя граница медианного интервала;
hMe –
величина медианного интервала;
∑f
— сумма частот ряда;
fМе – частота медианного интервала;
Например: По имеющимся данным о распределении предприятий по численности
промышленно – производственного персонала рассчитать медиану в интервальном
вариационном ряду
|
Группы предприятий по численности ППП, чел. |
Число предприятий |
Сумма накопленных частот |
|
100-200 |
1 |
1 |
|
200-300 |
3 |
1+3=4 |
|
300-400 |
7 |
4+7=11 |
|
400-500 |
30 |
11+30=41 |
|
500-600 |
19 |
— |
|
600-700 |
15 |
— |
|
700-800 |
5 |
|
|
Итого: |
80 |
Определим, прежде всего,
медианный интервал. В данном примере сумма накопленных частот, превышающих половину
суммы всех значений ряда, соответствует интервалу 400-500.Это и есть медианный
интервал, т.е. интервал, в котором находится медиана ряда. Определим её
значение
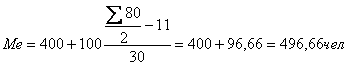
Если же сумма накопленных частот
против одного из интервалов равна точно половине суммы частот ряда, то медиана
определяется по формуле:
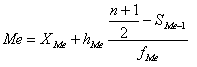
где n – число
единиц в совокупности.
Например: По имеющимся данным о распределении предприятий по
численности промышленно – производственного персонала рассчитать медиану в
интервальном вариационном ряду
|
Группы предприятий по численности ППП, чел. |
Число предприятий |
Сумма накопленных частот |
|
100-200 |
1 |
1 |
|
200-300 |
3 |
1+3=4 |
|
300-400 |
6 |
4+6=10 |
|
400-500 |
30 |
10+30=40 |
|
500-600 |
20 |
40+20=60 |
|
600-700 |
15 |
— |
|
700-800 |
5 |
|
|
Итого: |
80 |
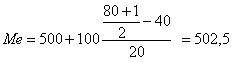 чел
чел
Моду и медиану в
интервальном ряду можно определить
графически:
моду
в дискретных рядах — по полигону распределения, моду в интервальных рядах — по
гистограмме распределения, а медиану — по кумуляте.
Мода интервального ряда распределения
определяется по гистограмме распределения определяют
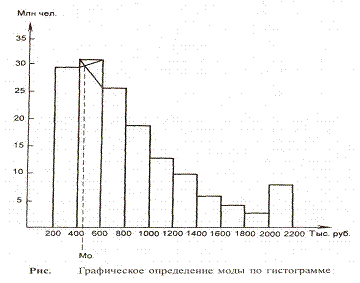
следующим образом. Для этого выбирается самый высокий прямоугольник, который
является в данном случае модальным. Затем правую вершину модального
прямоугольника соединяем с правым верхним углом предыдущего прямоугольника. А
левую вершину модального прямоугольника – с левым верхним углом последующего
прямоугольника. Далее из точки их пересечения опускают перпендикуляр на ось
абсцисс. Абсцисса точки пересечения этих прямых и будет модой распределения.
Медиана рассчитывается по
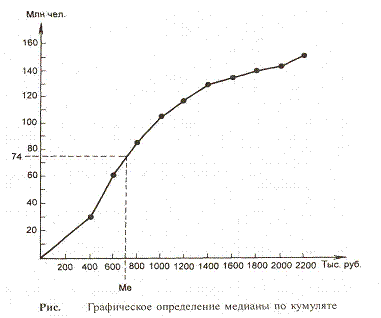
кумуляте. Для её определения из точки на шкале
накопленных частот (частостей), соответствующей 50%,
проводится прямая, параллельная оси абсцисс, до
пересечения с кумулятой. Затем из точки пересечения
указанной прямой с кумулятой опускается перпендикуляр
на ось абсцисс. Абсцисса точки пересечения является медианой.
Кроме моды и медианы в вариантных рядах могут быть
определены и другие структурные характеристики – квантили. Квантили
предназначены для более глубокого изучения структуры ряда распределения.
Квантиль – это значение
признака, занимающее определенное место в упорядоченной по данному признаку
совокупности. Различают следующие виды квантилей:
— квартили – значения признака, делящие упорядоченную
совокупность на четыре
равные части;
— децили
– значения признака, делящие упорядоченную совокупность на десять
равных частей;
— перцентели —
значения признака, делящие упорядоченную совокупность на сто равных частей.
Таким образом, для характеристики положения центра ряда распределения
можно использовать 3 показателя: среднее значение признака, мода, медиана. При выборе вида и формы конкретного показателя
центра распределения необходимо исходить из следующих рекомендаций:
—
для устойчивых социально-экономических
процессов в качестве показателя центра используют среднюю
арифметическую. Такие процессы характеризуются симметричными распределениями, в
которых ![]() ;
;
—
для неустойчивых процессов положение
центра распределения характеризуется с помощью Mo
или Me. Для асимметричных процессов предпочтительной
характеристикой центра распределения является медиана, поскольку занимает
положение между средней арифметической и модой.
Интервальный ряд
Условие:
Имеются данные о возрастном составе рабочих (лет):
18, 38, 28, 29, 26, 38, 34, 22, 28, 30, 22, 23, 35, 33, 27, 24,
30, 32, 28, 25, 29, 26, 31, 24, 29, 27, 32, 25, 29, 29.
1.
Построить интервальный ряд
распределения.
2.
Построить графическое изображение
ряда.
3.
Графически определить моду и
медиану.
Решение.
1) По формуле Стерджесса совокупность надо разделить на
1 + 3,322 lg 30 = 6 групп.
Максимальный возраст – 38, минимальный – 18.
Ширина интервала ![]()
.
Так как концы интервалов должны быть целыми числами, разделим
совокупность на 5 групп. Ширина интервала – 4.
Для облегчения подсчетов расположим данные в порядке
возрастания
18, 22, 22, 23, 24, 24, 25, 25, 26, 26, 27, 27, 28, 28, 28, 29,
29, 29, 29, 29, 30, 30, 31, 32, 32, 33, 34, 35, 38, 38.
Распределение возрастного состава рабочих
|
№ пп |
Возраст х |
Частота f |
Накопленная частота S |
|
1 |
18-22 |
3 |
3 |
|
2 |
23-26 |
7 |
10 |
|
3 |
27-30 |
12 |
22 |
|
4 |
31-34 |
5 |
27 |
|
5 |
35-38 |
3 |
30 |
|
Всего |
30 |
Графически ряд можно изобразить в виде гистограммы или полигона.
Гистограмма – столбиковая диаграмма. Основание столбика – ширина
интервала. Высота столбика равна частоте.

Полигон (или многоугольник распределения) – график частот. Чтобы его
построить по гистограмме, соединяем середины верхних сторон
прямоугольников. Многоугольник замыкаем на оси Ох на
расстояниях, равных половине интервала от крайних значений х.
Мода (Мо) – это величина изучаемого признака, которая в данной
совокупности встречается наиболее часто.
Чтобы определить моду по гистограмме, надо выбрать самый высокий
прямоугольник, провести линию от правой вершины этого
прямоугольника к правому верхнему углу предыдущего
прямоугольника, и от левой вершины модального прямоугольника
провести линию к левой вершине последующего прямоугольника. От
точки пересечения этих линий провести перпендикуляр к оси х.
Абсцисса и будет модой. Мо ≈ 27,5. Значит, наиболее часто
встречаемый возраст в данной совокупности 27-28 лет.
Медиана (Mе) – это величина изучаемого
признака, которая находится в середине упорядоченного
вариационного ряда.
Медиану находим по кумуляте. Кумулята – график накопленных частот.
Абсциссы – варианты ряда. Ординаты – накопленные частоты.
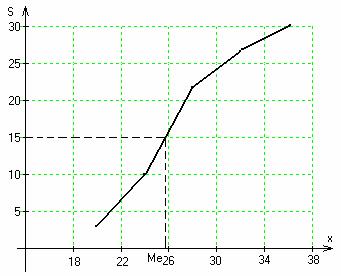
Для определения медианы по кумуляте находим по оси ординат точку,
соответствующую 50% накопленных частот (в нашем случае 15),
проводим через неё прямую, параллельно оси Ох, и от точки её
пересечения с кумулятой проводим перпендикуляр к оси х. Абсцисса
является медианой. Ме ≈ 25,9. Это означает, что половина
рабочих в данной совокупности имеет возраст менее 26 лет.