История хранит множество загадок и тайн. Большая их часть известна узкому кругу людей, имеющих доступ к секретным данным.
Но рано или поздно все становится явным, срок хранения секретов заканчивается и уникальные свидетельства исторических событий открывают для всех.
Без цензуры или правок — как есть, как было составлено, записано и сохранено. Где же искать рассекреченные разными государствами документы?
Попробуем разобраться: где и как искать ставшие доступными ранее секретные документы России, СНГ и других стран, и как получить к ним доступ.
Основные проблемы поиска

В интернете чаще всего можно встретить рассекреченные документы из государственных архивов, реже — личные записи, относящиеся к государтсвенной тайне.
Любая гостайна хотя и является защищенной от лишних глаз, имеет заранее оговоренный срок хранения.
Для большинства документов срок варьируется от 5 до 75 лет. Другая часть хранится до указания о списании руководящего органа управления.
Третья – предполагает открытие доступа только при прямом указании правительства или ведомств, к которым относится хранимая информация.

Ввиду большого объема рассекреченных бумажных документов, даже важные исторические документы не всегда оцифровываются, хотя в интернете можно найти, где они хранятся.
Некоторые архивные источники имеют ветхое состояние и предполагают только личное обращение. Интернет в данном случае может помочь разыскать место хранения и составить предварительную заявку на доступ.
Да, вы правильно поняли — ввиду определенного установленного режима обращения, отдельные виды рассекреченных документов могут быть доступны только по паспорту.
Еще 2 проблемы — безумная фрагментация и колоссальное количество информации. Как секретные, так и несекретные документы хранятся архивными органами власти.
Как устроено хранение архивов в России

Все существующие в России архивы делятся на 2 категории: общие и ведомственные. Ведомственные хранят документы тех или иных государственных служб в течении оговоренного срока, потом по специальному приказу передают их в общий фонд.
Все операции с межведомственными и переданными из ведомств документами ведет Архивный фонд Российской Федерации (подробно о его структуре можно узнать здесь), находящийся под управлением Федерального архивного агентства «Росархив».
В свою очередь, «Росархив» является не библиотекой, а федеральным органом исполнительной власти, находящимся в ведении Президента Российской Федерации.

Архивный фонд только хранит документы, архивное агенство их выпускает, каталогизирует, устанавливает права и порядки обращения, а так же определяет порядок обращения даже в силовых структурах.
При создании особо важного документа, закона, договора — он сразу попадает в каталог Росархива с оформленной копией.
Объем Архивного фонда Российской Федерации составляет более 500 млн. единиц хранения на различных носителях, или более 8,5 тыс. км архивных полок.
Документы Архивного фонда Российской Федерации в законодательно определенном порядке хранятся:
постоянно в
- федеральных государственных архивах,
- государственных архивах субъектов Российской Федерации,
- муниципальных архивах, федеральных и других государственных и муниципальных библиотеках и музеях,
- организациях Российской академии наук;
временно в
- государственных органах,
- государственных организациях,
- муниципальных архивах,
- на депозитарном хранении в ряде федеральных органов исполнительной власти и федеральных организаций.
Последний пункт как раз чаще всего относится к ведомственным засекреченным архивам. Перечень таких организаций можно узнать в постановлении Правительства Российской Федерации № 808 от 27 декабря 2006 г.
Важно: ведомственные архивы спецслужб не входят в подчинение Росархива, но передают ему или его подразделениям рассекреченные документы на ответственное хранение, каталогизацию и публикацию.
Как найти секретный документ в России

Любой запрос при поиске архивного документа в России имеет смысл начинать с сайта Росархива.
Здесь есть все нормативные документы и полный перечень архивных ведомств на данный момент. Кроме того, Росархив предоставляет возможность электронных письменных и устных запросов, а так же подробных телефонных консультаций.
Правила составления запросов на поиск можно найти на сайте в соответствующем разделе, либо пройти предварительную консультацию.
В том случае, если документ находится в подведомственном Росархиву учреждении, организация даёт подробный ответ о возможности, месте и сроке получения.

Если документ засекречен, о нём расскажут тоже самое без упоминания содержания и пояснят — какие права либо процедура потребуется для подробного изучения материала.
Так же существует специальный поисковый инструмент: Справочно-информационный центр федеральных государственных архивов (сайт).
Здесь можно составить запрос в удобной форме и получить подробную консультацию — где и как искать необходимую информацию.
Архивные источники официальных документов

С порядком создания, архивирования и рассекречивания определились. Если есть интерес к старым историческим документам — вперед, в главный государственный архив.
Теперь попробуем определиться, какие ресурсы в интернете хранят рассекреченные документы.
Рассматривать все подведомственные Росархиву объединения не имеет смысла — при необходимости на них можно перейти через специальные структурные подразделения головной организации.
База данных рассекреченных дел и документов федеральных государственных архивов
Эта огромная база с довольно скромным оформлением есть ни что иное, как официальный ресурс Росархива, который публикует подробную сводку по рассекреченным в стране документам.
Получается что-то вроде новостного дайджеста, из которого можно узнать о появлении в открытом доступе тех или иных данных.
Часть из них оцифровывается и появляется для ознакомления на страницах базы. Для ознакомления с другими оцифровками придется посетить ссылки, представленные на другие архивные ресурсы.
Основную часть информационной сводки составляют перечисления доступных в архивах рассекреченных документов, доступных в «живом» и оцифрованном виде через запрос с ресурсов Росархива.
Посетить Базу рассекреченных дел
Архив Министерства обороны

Центральный архив Министерства обороны хранит все документы органов военного управления, соединений, частей и учреждений Министерства обороны с 1941 года по настоящее время.
Именно здесь прячутся военные тайны, стратегические планы и карты личного состава, включая наградные листы. Чертежей и донесений разведки, правда, не найти — такого рода старые документы находятся в управлении соответствующих ведомств.
Документы государственной важности из архива Минобороны передаются в Росархив на ответственное хранение и оцифровку. Тем не менее, ряд материалов можно найти прямо на официальном сайте самого ведомства.
Посетить Архив Минобороны
Раздел с рассекреченными документами
Ассоциация «Российское историческое общество»

Создана в качестве правопреемницы Императорского Русского исторического общества, в 1866–1917 годах, собиравшего, обрабатывавшего и публиковавшего материалы и документы, связанные с историей государства.
Современная организация занимается преимущественно сбором и обработкой дореволюционных материалов, публикуя их в удобоваримом виде подборок/коллекций с комментариями и описанием.
Участники Российского исторического сообщества ввиду высокого статуса имеют доступ к гостайне и право на на работу с соответствующими материалами с последующей публикацией.
Посетить официальный сайт
Зарубежные источники рассекреченных документов
Аналогично российскому устроено хранение архивов в США, Великобритании и странах ЕС — поэтому они так же доступны в сети.
Все эти государства имеют централизованную систему хранения архивов, в которую государственные ведомства и спецслужбы обязаны сдавать документы по истечении срока хранения.
Благодаря чему можно найти множество интересных исторических, военных и юридических документов. Многие из них касаются России и её взаимоотношений с другими государствами.
База рассекреченных документов CREST

По закону Freedom of Information Act Центральное разведывательное управление с 31 декабря 2006 года обязано снимать гриф секретности с документов старше 25 лет и обеспечивать свободный доступ к ним.
Благодаря этому появилась база рассекреченных документов CREST (CIA Records Search Tool) с полным «свободным» доступом, который заметно удобнее российских вариантов, правда нет информационных дайджестов.
Доступен полнотекстовый поиск, все материалы оцифрованы, текст на них распознан и доступен полнотекстовый поиск. Доступны практически все материалы ЦРУ, касающиеся ведомства и политики государства.
Посетить официальный сайт
Воспользоваться поиском
Национальное управление архивов и документации

Национальные архивы (National Archives and Records Administration, NARA) официально ответственны за ведение и публикацию юридически достоверных и авторитетных копий актов Конгресса США, президентских обращений и распоряжений, также ведает федеральными нормами.
Кроме того, именно здесь публикуют рассекреченные документы ФБР (FBI), разведка (NSA) и различные подразделения армии США, а так же ряд научных и промышленных организаций, включая NASA.
Большинство документов доступно в оцифрованном и распознанном виде. Так же публикуются подробные дайджесты рассекреченных документов. Отсутствующее всегда можно запросить прямо на сайте.
Посетить официальный сайт
Национальный архив Великобритании

Национальный архив (The National Archive) содержит, как и Росархив, все рассекреченные документы государственного или исторического значения, переданные ведомствами на ответственное хранение.
Кроме того, учреждение собирает, каталогизирует и публикует основные документы об управлении государством, судебные документы и домовые книги, корреспонденцию ведомств и их приказы и многое другое.
Фактически, является наиболее полным и структурированным архивом среди перечисленных: на базе блокчейна они хранят сводку за 1000 лет. Другие источники по Великобритании, скорее всего, не потребуется.
Все самое важное уже оцифровано и опубликовано в свободном доступе, а при необходимости — оцифруют по запросу.
Посетить National Archive
Федеральный архив Германии

Федеральный архив Германии (Bundesarchiv) содержит документы, относящихся к Западной Германии времён до объединения и к современной Германии, а также из документов, относящихся к имперскому прошлому Германии и к ГДР.
Помимо государственных документов, в архиве хранятся материалы, относящиеся к деятельности политических партий и общественных организаций, а также исторические коллекции.
Есть текстовые документы, фотографии, фильмы, плакаты, а также материалы в электронном виде. Однако, основной доступ организован в оффлайн-виде.
Посетить Федеральный архив
Раздел с электронными коллекциями
Высокоточные спутниковые снимки

Основной пробел большинства вышеописанных служб и архивов — полное отсутствие карт и географических данных. Более того, в России с некоторых пор старые карты и вовсе «засекретились обратно».
С учетом изменчивости ландшафта и постоянных геологических процессов, а так же отсутствия точных официальных карт некоторых регионов этот факт составляет большую проблему.
Исправить ситуацию вызвалось Американское геологическое сообщество (U.S. Geological Survey), публикующее точные спутниковые карты с отображением изменений в «реальном времени» (по геологическим меркам).
Министерство обороны США, в свою очередь, для исторических работ рассекретило и открыло публичных доступ к базе данных спутниковых снимков высокого разрешения Corona.

Ещё большую точность дают картографические материалы базы SRTM (Shuttle Radar Topography Mission), рассекреченные и опубликованные Белым домом (США): здесь точность составляет 1 угловую секунду (30 метров).
Посетить Американское геологическое сообщество
Посетить Базу спутниковых снимков Corona
Посетить SRTM
«Краденые» данные, опубликованные в сети

Неофициально рассекреченные данные, утечки и «ворованные» документы в сети тоже встречаются. Вопреки всем опасностям, связанным с подобной работой.
Основным общественным источником рассекреченных документов разведок и правительств мира является сетевой проект WikiLeaks Джулиана Ассанжа, на данный момент находящегося в британской тюрьме.
Публикации WikiLeaks ответственны за множество серьезных политических скандалов. С осени 2019 года сайт перестал обновляться, но ранние публикации доступны для чтения — вероятно, причиной стал суд над Ассанжем.
Череда скандалов и серьезное противодействие со стороны властей, обеспокоенных публикацией секретной документации (прежде всего перепиской официальных лиц и дипломатов), привела к появлению множества аналогичных проектов.

К сожалению, до 2020 года не дожил ни один из крупных аналогов WikiLeaks. Работоспособны только
1. SportsLeaks.com, посвященный допинговым и договорным скандалам в профессиональном спорте,
2. Distributed Denial of Secrets («DDOS»), посвященный прочим утечкам.
SportsLeaks предлагает участникам делиться подтвержденными данными о нарушениях в спортивной этике. На данный момент документы не публикуются.
DDOS содержит огромные частные коллекции документов, посвященных глобальным вопросам в разнообразных сферах жизни. Ядерные программы, корпоративная этика.
Большой пул данных составляют утечки российских спецслужб, либо добытые ими (по заявлениям создателей сайта) в результате хакерских атак.
Кратко подведем итог: где искать?

Еще раз повторим: как только секретные данные официально рассекречиваются, они попадают в архив. Так происходит в России, США, Великобритании и странах ЕС.
Документы государственной важности при этом передаются государственными ведомствами и спецслужбами в центральную архивную службу:
- в России — отделение Росархива,
- в США — Национальный архив,
- в Великобритании — Национальный архив,
- в Германии — Федеральный архив.

Ведомственные документы рангом ниже публикуются прямо на сайте конкретной службы: Минобороны РФ, ЦРУ, NASA.
Узнать об официально снятом грифе «секретно» можно на:
- сайте ведомства,
- на сайте главного архивного управления государства.
При необходимости в единую государственную службу можно направить официальный запрос и получить конкретный ответ об интересующем документе и необходимых для работы с ним правах/документах/процедурах.
P.S. Добавляйте в комментариях интересные источники, актуальные платформы. А в следующей статье обсудим – как на практике составить поисковый запрос в архивы и найти что-то полезное.

 (11 голосов, общий рейтинг: 4.73 из 5)
(11 голосов, общий рейтинг: 4.73 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Удивительные тайны уже ждут.
- Это интересно
![]()
Николай Маслов
@nicmaslov
Не инженер, радиофизик и музыкант. Рассказываю о технике простым языком.
Время на прочтение
4 мин
Количество просмотров 48K

Рассекреченный архив документов ЦРУ (справа) и всего четыре компьютера, с которых можно было получить доступ к информации (слева)
Некоторые законы очень неудобны для жуликов, которые хотят скрыть информацию. Поэтому они выполняют требования закона, но прибегают к «невинному саботажу», чтобы свести ущерб к минимуму. Например, в России информацию о тендерах вносили в открытый реестр с заменой кириллических символов на латинские, чтобы их трудно было найти обычным поиском. Спецслужбы в США тоже мастера на творческий уход от выполнения законов, формально соблюдая их. Только оцените талант сотрудников ЦРУ. По закону Freedom of Information Act Центральное разведывательное управление с 31 декабря 2006 года обязано снимать гриф секретности с документов старше 25 лет и обеспечивать свободный доступ к ним. ЦРУ формально выполнило требование закона: оно создало базу рассекреченных документов CREST (CIA Records Search Tool) и организовало «свободный» доступ к ней через… четыре компьютера в здании филиала Национального архива в городе Колледж-Парк, шт. Мэриленд, который открыт для публики с 9:00 до 17:00. Здесь у разведчиков явное упущение: по логике ЦРУ, надо было ограничить время работы архива, например, с 7:00 до 7:10 на один день в неделю.
Такой беспредел продолжался до настоящего времени. В конце концов справедливость восторжествовала. С января 2017 года вся база рассекреченных документов CREST открыта в интернете c полнотекстовым поиском — проверьте поиск по городам и райцентрам России, фамилиям учёных, названиям наркотиков и т.д. Теперь всё действительно работает как положено. Вся информация открыта.
Ежегодно к 31 декабря сотрудники ЦРУ пополняют базу данных CREST новыми рассекреченными документами старше 25 лет, предварительно проведя необходимое редактирование (удалив из документов фрагменты, которые остаются предметом государственной тайны). Например, на 31 декабря 2016 года база содержала все документы с момента основания ЦРУ в 1947 году и до 31 декабря 1991 года. Проблема была только в том, что реально широкая общественность не имела возможность получить доступ к этим документам.
Ситуацию взялись исправить активисты из некоммерческого проекта MuckRock. Они стремятся принудить государственные органы к прозрачности, подотчётности народу и соблюдению своих же собственных законов.
В июне 2014 года активисты MuckRock подали в суд на ЦРУ, требуя обеспечить свободный доступ к базе данных CREST, а также к различным метаданным, связанным с этой БД.
Судебные разбирательства были непростыми. Юристы ЦРУ пытались всячески затянуть процесс. Например, в 2015 году они заявили ходатайство о том, что требуется шесть лет для публикации документов. И это несмотря на то, что все документы оцифрованы и доступны в Национальной библиотеке. Не было только веб-интерфейса для доступа к ним.
Дошло до того, что в 2016 году один из активистов Майкл Бест запустил сбор средств на Kickstarter, чтобы пойти в библиотеку и вручную отсканировать все документы, которые ЦРУ отказывается выложить в интернет, хотя они рассекречены по закону. Почему отсканировать? Потому что по правилам библиотеки пользователям было запрещено сохранять уже отсканированные документы на флешку или другие носители информации. Можно было только распечатать их! Если вы хотите выложить документы для всеобщего обозрения, единственным способом было сходить в библиотеку, распечатать цифровой документ, а затем снова отсканировать его — и опубликовать.
Вот так в ЦРУ формально соблюдали указ Билла Клинтона о рассекречивании информации. Технически документы доступны — указ президента исполнен. На практике из 13 млн рассекреченных документов за все годы существования базы CREST было распечатано чуть более 1 млн документов, и только малая доля из них оцифрована и опубликована в интернете.
К счастью, Майклу Бресту не пришлось воплощать в жизнь свой сумасшедший план по сканированию 13 млн документов, потому что ЦРУ всё-таки проиграло суд. В октябре 2016 года стало понятно, что разведчиков заставят выложить базу в интернет.
18 ноября 2016 года юристы ЦРУ официально выбросили белый флаг и пообещали, что с I кв. 2017 года откроют онлайновый доступ к базе CREST и будут периодически её пополнять. Официальное обязательство ЦРУ приведено в судебном документе.
В январе 2017 года ЦРУ начала выполнять обязательства. На официальном сайте открылся полнотекстовый поиск по базе. В данный момент сервер не выдерживает наплыва посетителей и временами выдаёт ошибки при попытке поиска. Видно, квалификация айтишников в ЦРУ не очень высока. Или так было задумано?
Не совсем понятно, какое количество документов доступно через онлайновую форму в данный момент, но в конце концов там должны появиться все 13 с лишним миллионов рассекреченных документов ЦРУ, а каждый год — новое пополнение. В конце 2017 года выложат документы за 1992 год и так далее.
Кроме доступа ко всей базе, ЦРУ опубликовало даже несколько тематических подборок документов: по берлинскому туннелю, с обзорами научных исследований советских учёных, по правилам шпионской тайнописи, по проекту Stargate (эксперименты с экстрансенсами) и т.д. По ключевому слову «keyhole» можно найти некоторые интересные фотографии со шпионских спутников.
На форумах высказывают мнение, что рассекреченные документы желательно быстро скачать и опубликовать торрент, пока новая администрация президента США не прикрыла доступ к базе.
Как найти секретные документы NASA в интернете?
LOCKNET

Привет, подписчики! Вот знаете, недавно мне пришла в голову одна мысль: почему бы вас не обучить нетсталкингу? Это реально крутая тема, так как благодаря ей вы сможете найти малоизвестные или малопосещаемые объекты. Также благодаря ей можно найти субъективно подозрительную, фантастическую информациию в Интернете. Схемы заработка, секретные документы и т.д. Интересно?
Что несталкеры находили в интернете?
Итак, начнём с игры » «No Players Online». По словам игрока, во время игры он ощутил жуткость. В игре много шифров, непонятных и страшных звуков. Короче, вы поняли.

Ну а продолжим мы с самого интересного. Один нетсталкер нашёл сайт, в котором был добавлен какой-то проект. На нём размещали журналы на ту тему, которую вы очень сильно обожаете. Вот представьте, что можно изучить и применить, использовал эти журналы?

Перейдя на этот сайт с журналами, я увидел следующее:

Разве это не круто? Нам уже недалеко до находки секретных документов. Вот например, некие парни нашли сайт бывшего сотрудника HP, посвященный старым компьютерам (в частности, компьютеру Apple II).

Также недавно я находил целый список исходных кодов от игр-клонов. Смотрите какую игру я нашёл. Думаю, вы все с ней знакомы:

Софт нетсталкеров
Как вы уже могли догадаться, каждый настоящий нетсталкер использует софты для решение какой-либо задачи. Я вам кидаю ссылку, по которой вы с лёгкостью скачаете все файлы. Архив весит 300MB: https://yadi.sk/d/R0VdqI_93JyssH
Секретные документы NASA
Недавно я искал что-нибудь интересное в интернете и наткнулся на фотографии Nasa. (Там вроде было что-то ещё). До этого нашёл исходный код компьютера Apollo-11, который использовался для команды. Показывать это я не буду, сами найдёте после обучения.

И да, секретные документы… Их тоже можно найти. Ребята, да здесь можно найти что-угодно!
Начнём интересные приключения?
Вы должны понимать, что я хочу постить для вас только годноту, поэтому я у вас спрошу: Делать ли авторское обучение по нетсталкингу?
Платить ничего не нужно, всё будет бесплатно, только для вас!
Если вам интересна эта тема и вы хотите, чтобы обучение вышло, то пожалуйста, отправьте «+». Одним предложением — заспамьте плюсами этот чат!
Ссылка на чат — https://t.me/joinchat/D_rO2UmKX_5dnUikdX0YYw
Только от вас зависит моё решение: постить или нет. Поэтому, жду от вас огромной активности. Вы просто не представляете как можно монетизировать этот вид деятельности. До новых встреч!
Я никого ни к чему не призываю, статья написана в ознакомительных целях!

Инкогнито — не забываем подписываться на наш второй канал!
DARK PLACE — место, где ты заработаешь 100.000₽ уже через месяц!
BLACK — самые топовые сливы схем заработка и обучений.
Предыдущие статьи:
Хакеры получили доступ к личным сообщениям Джеффа Безоса
Как зарабатывают на фейк-взломах соц. сетей?
Зарабатываем миллион на казино-стримах
Лучший аналог даркнета с встроенным Windows
Зарабатываем 50.000р на эротических видео
Другие статьи на нашем с вами любимом канале LOCKNET! Подписывайся, делись ссылкой на статью с друзьями!
Когда нам нужно что-то найти, тогда Google или yandex внезапно приходят в голову.
Но Google и Yandex не будут предоставлять всю скрытую информацию, которая обслуживается в Даркнете.
У Google есть возможность отслеживать каждое ваше движение в Интернете во время поиска с помощью Google.
Если вы не хотите, чтобы Google собирал вашу личную информацию и ваши действия в Интернете, вы должны сохранять анонимность в Интернете.
«Дип вэб».
Этот термин, также известный как «невидимая сеть», относится к обширному хранилищу базового контента, например документов в онлайн-базах данных, недоступных сканерам общего назначения.
Поскольку большинство личных профилей, общедоступных записей и других связанных с людьми документов хранятся в базах данных, а не на статических веб-страницах, большая часть высококачественной информации о людях просто «невидима» для обычной поисковой системы.
Содержание
- Почему Google не предоставляет результаты поиска в Дип нете?
- 1.pipl
- 2. My Life
- 3. Yippy
- 4. Surfwax
- 5. Way Back Machine
- 6. Google Scholar
- 7. DuckDuckgo
- 8. Fazzle
- 9. not Evil
- 10. Start Page
- 11. Spokeo
Почему Google не предоставляет результаты поиска в Дип нете?
По сути, секретное содержимое Deep Web или Dark Web не индексируется для предоставления результатов обычными поисковыми системами, такими как Google и Bing.all, на сайтах Deb (.onion) не индексируются.
Google не будет предоставлять результаты поиска, которые не индексируются в глобальной сети.
Содержание скрыто за HTML-формами.
Регулярные поиски, которые вы ищете в Google, и его результаты перенаправляются с взаимосвязанных серверов.
Здесь мы покажем интересные поисковые системы, которые позволяют получить результаты поиска в дип вебе, которые, вероятно, большинство людей не знают.
1.pipl
Система запросов Pipl помогает вам находить веб-страницы, которые невозможно найти в обычных поисковых системах.
В отличие от других поисковых систем, например Google и Bing, pipl предоставляет результаты поиска, полученные из Deep Web.
Роботы Pipl предназначены для взаимодействия с базами данных с возможностью поиска и извлечения фактов, контактных данных и другой соответствующей информации из личных профилей, справочников, научных публикаций, судебных отчетов и многочисленных других источников в Интернете.
Согласно pipl, они используют расширенные алгоритмы языкового анализа и ранжирования, чтобы предоставить вам наиболее релевантные фрагменты информации о человеке на единой, легко читаемой странице результатов.
2. My Life

На общедоступной странице Mylife можно перечислить данные о человеке, включая возраст, прошлые и текущие места жительства, номера телефонов, адреса электронной почты, места работы, инструкции, фотографии, родственников, меньшую, чем ожидалось, историю и отдельный сегмент опроса, который призывает других людей Mylife оценить друг друга.
Вы можете зарегистрироваться на эту услугу и получить изрядное количество информации бесплатно, но за 6,95 долларов США вы можете пользоваться этой услугой в течение месяца и получать полные отчеты и все виды сочной информации.
У Mylife есть «более 225 миллионов публичных страниц с данными практически обо всех в Америке, в возрасте 18 лет и старше».
Согласно MyLife, «открытая страница не может быть стерта», и «только премиум-пользователи могут скрывать контент на своей общедоступной странице и удалять информацию из первого источника.
3. Yippy

Yippy на самом деле Metasearch Engine (он получает свои результаты, используя другие веб-индексы), я включил сюда Yippy, так как он имеет место для входа с устройств, которыми может быть занят веб-клиент, например, таких как электронная почта, игры , видео и тд.
Совсем не так, как в Google, он не хранит вашу историю, не видят термины или электронную почту, что является более важным моментом, однако традиционная семейная картина благонадежности повлияла на качество поиска.
Поиск [алкоголь] возвращает результаты алкоголиков, анонимных групп, а не, скажем, страницу Википедии о том, что такое алкоголь, например.
Он хорошо подойдет для родителей, чьи дети пользуются ноутбуком.
4. Surfwax

SurfWax поиск доступен как бесплатно, так и на основе подписки.
Поисковый сайт связан с рядом функций, помимо простого поиска.
По словам Surfwax, на волнах, серфовый воск помогает серферам захватывать их доску для серфинга; для веб-серфинга SurfWax помогает вам лучше справляться с информацией – обеспечивает «наилучшее использование» релевантных результатов поиска.
Дизайн / пользовательский интерфейс SurfWax был первым, кто сделал поиск «визуальным процессом», бесшовно интегрируя поиск по смыслу с ключевыми элементами поиска знаний для эффективной связи и отзывов.
5. Way Back Machine

Wayback Machine – это интерфейс для сбора открытых веб-страниц в интернет-архиве.
Он включает в себя более 100 терабайт даты – колоссальное собрание с огромными запасными предпосылками.
Wayback Machine предоставляет доступ к этой информации по URL.
Он недоступен для содержимого – клиент должен знать правильный URL-адрес конкретной веб-страницы или, возможно, веб-сайта, чтобы иметь возможность вести хронику.
Интернет-архив позволяет общественности загружать и скачивать цифровые материалы в свой кластер данных, но большая часть его данных автоматически собирается поисковыми роботами, которые стремятся сохранить как можно большую часть общедоступной сети.
Его веб-архив, Wayback Machine, содержит более 150 миллиардов веб-снимков.
Архив также курирует один из крупнейших в мире проектов оцифровки книг.
6. Google Scholar

Google Scholar позволяет выполнять поиск по широкому кругу научной литературы.
Он опирается на информацию издателей журналов, университетских репозиториев и других веб-сайтов, которые он определил как научные.
Google Scholar предназначен для того, чтобы помочь вам найти научные источники, которые существуют по вашей теме.
Как только вы обнаружите эти источники, вам захочется их заполучить.
Вы можете настроить Google Scholar, чтобы разрешить автоматический доступ к подпискам библиотек NCSU на журналы и базы данных.
7. DuckDuckgo

Этот механизм глубокого веб-поиска, который, как и многие другие механизмы глубокого веб-поиска в этом списке, также позволяет осуществлять поиск в обычном Интернете, имеет простой и понятный интерфейс и не отслеживает ваши открытия.
Варианты тем для поиска бесконечны, и вы даже можете настроить его для повышения вашего опыта.
DuckDuckGo делает упор на возвращении лучших результатов, а не большинства результатов, и генерирует эти результаты из более чем 400 отдельных источников, включая ключевые краудсорсинговые сайты, такие как Википедия, и другие поисковые системы, такие как Bing, Yahoo !, Yandex и Yummly.
8. Fazzle

Fazzle.com – это мета-веб-индекс, доступный на английском, французском и голландском языке.
Fazzle просматривает более 120 измененных веб-индексов, чтобы передать «быстрые точные результаты», к которым присоединяется страница просмотра рядом с каждой публикацией.
Пункты запросов Fazzle включают в себя Интернет, файлы для загрузки, изображения, видео, аудио, желтые страницы, белые страницы, покупки и новости.
Совсем не так, как большая часть более известных мета-веб-индексов, результаты Fazzle не охватываются поддерживаемыми соединениями, и Fazzle просто выделяет место № 1 в списке элементов для продвижения.
Все, что осталось от элементов запроса, собрано из многочисленных списков поиска, которые Fazzle запускает, однако для определения своего «лучшего выбора» и 20 различных результатов на своих страницах SERPS.
9. not Evil
В отличие от других поисковых систем Tor, not Evil не для прибыли.
Цена за то, чтобы запустить его, является вкладом в то, что, как можно надеяться, является растущим щитом против тирании нетерпимого большинства.
not Evil еще одна поисковая система в сети TOR.
По своей функциональности и качеству он очень конкурентоспособен.
Там нет рекламы и отслеживания
. Благодаря продуманным и постоянно обновляемым алгоритмам поиска легко найти нужный товар, контент или информацию.
Используя not Evil , вы можете сэкономить много времени и сохранить полную анонимность.
Пользовательский интерфейс очень интуитивно понятен.
Следует отметить, что ранее этот проект был широко известен как TorSearch.
10. Start Page
Если вы беспокоитесь о конфиденциальности, Start Page от Ixquick – одна из лучших поисковых систем, даже если вы не используете Tor.
В отличие от других поисковых систем,Start Page не записывает ваш IP-адрес, что позволяет хранить историю поиска в секрете.
Обидно, что Google знает о тебе все.
Start Page это способ провести исследование, не передавая вашу информацию кому-либо еще.
11. Spokeo
Таким образом, после проведения поиска, к вашим услугам будут местоположение, адреса электронной почты, профили в социальных сетях и даже дополнительные сведения о судимости.
Этот веб-сайт действительно прост в использовании, просто введите 10-значный номер телефона в специальной строке и нажмите «search».
Вы можете использовать Spokeo в случае, если вы хотите найти потерянного члена семьи или друга, проверить своих близких, избежать мошенников, узнать больше об этом человеке, проверить, кто вам звонит, найти еще один шанс связаться с ним и т. д.
Содержание
- 1 Copernic Desktop Search
- 2 Archivarius 3000
- 3 DNS Lookup
- 4 Google Desktop
- 5 Web Directory Buster
- 6 X1 Enterprise Client
- 7 Fact200
- 8 SearchInform Standard
- 9 BlackWidow
- 10 2 Find MP3 8.7.3
- 11 Как скачать Everything на русском языке
- 12 Установка Everything на русский язык
- 13 Как пользоваться Everything
- 14 Дополнительные настройки Everything
- 15 Портативная версия программы поиска Everything
Copernic Desktop Search
Поисковая система по жесткому диску (дискам)- мгновенно находит интересующие сведения в документах.
Archivarius 3000
Архивариус — программа для мгновенного поиска документов на локальном компьютере, в локальной сети и на съемных дисках.
DNS Lookup
Инструмент для просмотра записей DNS и WHOIS.
Google Desktop
Google Desktop предоставляет вам простой доступ к информации на вашем компьютере и в Интернете.
Web Directory Buster
Полезная утилита, предназначенная для поиска скрытых файлов на различных порталах.
X1 Enterprise Client
X1 Enterprise Client – утилита для настольного поиска, бесплатная для персонального использования.
Fact200
Fact200 – утилита для Интернет поиска, позволяющая искать информацию в нескольких источниках одновременно.
SearchInform Standard
Программа полнотекстового поиска документов.
BlackWidow
BlackWidow — офлайн браузер и site downloader.
2 Find MP3 8.7.3
Программа для быстрого поиска и закачки MP3-файлов из сети.
Последнее обновление — 11 мая 2019 г.

Чтобы находить нужные файлы на компьютере, мы уже рассматривали стандартные возможности, которые есть в системе Windows изначально. Подробнее о стандартном поиске в Windows можно прочитать в статьях: Поиск файлов в Windows XP и Поиск файлов в Windows 7.
Преимущества стандартного поиска в том, что ничего дополнительно устанавливать на компьютер не нужно!
Но есть и серьезный недостаток, — не у всех стандартный поиск работает или работает не так, как хотелось бы!
Поэтому в этой статье мы рассмотрим отдельную отличную бесплатную программу Everything, которая позволяет очень быстро, можно даже сказать моментально (на лету), находить нужные файлы на компьютере!
С помощью программы Everything можно делать поиск файлов на компьютере не только по полному названию файлов, но даже по части слова! Это отличная функция для ситуаций, когда мы не помним название всего файла.
Мы просто в поле поиска вводим слово или часть слова и тут же получаем результат! При этом на удивление, Everything вообще не тормозит работу компьютера, как это бывает с другими программами.
Everything, — быстрая, легкая и удобная программа для поиска файлов и папок на компьютере.
Начнем пошаговый разбор установки и использования этой программы.
Как скачать Everything на русском языке
Заходим на официальный сайт этой программы. На сайте представлен список разных установочных файлов программы (разберем их значение):

Прежде всего, обратите внимание, что список разделен на две группы (подсвечено желтым). Первая группа Installer и вторая Portable.
Первая группа (Installer) предназначена для стационарной установки на компьютер, т.е. все файлы программы будут установлены в стандартную папку на компьютере, куда устанавливаются все другие программы.
Также в меню Пуск будут добавлены ярлыки для быстрого запуска Everything.
Если Вы будете использовать программу поиска на своем компьютере, то лучше установить именно эту версию, — ее мы и будем рассматривать в начале.
Вторая группа (Portable), это портативная версия программы. Если возникнут ситуации, когда нужно быстро найти какие-нибудь файлы на другом компьютере, чтобы там не устанавливать никаких дополнительных программ, можно просто поместить на флешку данную портативную версию программы, подключить флешку к компьютеру, запустить программу с флешки и произвести поиск файлов на компьютере.
Рассмотрим другие параметры разных ссылок. Зеленым подсвечена разрядность операционной системы, для которой предназначен данный установочный файл. Если Вы не знаете, какая разрядность у Вашего компьютера, чтобы выяснить это, нужно зайти в меню Пуск -> Компьютер -> Свойства (вызов контекстного меню вызывается правой кнопкой мыши):

И в свойствах Компьютера посмотрите разрядность своего компьютера: 32 или 64:

Примечание на счет разрядности: Установочный файл, предназначенный для 32 разрядной системы компьютера, подойдет для обеих систем, — хоть для 32, хоть для 64. А вот файл, предназначенный только для 64 разрядной системы, подойдет только для 64.
Ну и последний параметр в выборе ссылки для скачивания программы, это выбор языка. Для того чтобы установить себе программу с интерфейсом на русском языке, нужно выбрать ссылку с пометкой Multilingual (подсвечено голубым цветом на снимке выше).
Итак, большинство пользователей выберут ссылку ( 1 ) для своего компьютера и портативную версию ( 2 ), если будут пользоваться этой программа для поиска на других компьютерах.
Рассмотрим теперь установку и использование стационарной версии программы Everything, а потом в конце еще немного поговорим о портативной.
Установка Everything на русский язык
Запускаем установочный файл. Выбираем русский язык:

В следующем шаге просто нужно принять соглашение. Далее показывает, где на компьютере будет установлена программа. Здесь можно ничего не менять. Идем далее:

Следующее окно содержит дополнительные параметры установки, которые не так важны, чтобы в них что-то менять. Оставляем так, как предлагается:

Следующие настройки также не требуют особой корректировки, так как выставлены разработчиками так, что они подойдут для большинства пользователей, тем более начинающим пользователям можно оставить все как есть (все эти настройки можно изменять потом в самой программе). Жмем Установить:

После быстрой установки появится последнее окошко, в котором для запуска программы в первый раз оставляем галочку и нажимаем Готово:

Как пользоваться Everything
После первого запуска программа Everything всего за несколько секунд (нужно совсем чуть-чуть подождать) проиндексирует все названия файлов на компьютере и выдаст их общий список:

На моем компьютере всех файлов оказалось почти 300 тыс.
В дальнейшем для поиска файлов на компьютере программу Everything можно будет запускать через меню Пуск -> Все программы -> Everything:

Теперь, чтобы найти какой-либо файл или папку, достаточно в поле поиска ввести искомое слово файла или даже часть слова. И в результате получим список файлов, которые содержат поисковый запрос.
Например, мне нужно найти на своем компьютере электронную книгу «5 самых важных бесплатных программ для начинающих пользователей ПК».
Допустим, я не помню, где эта книга хранится у меня на компьютере.
Чтобы ее найти с помощью программы Everything, мне не обязательно вводить все это длинное название книги. Я могу ввести просто слово книга и получить такой результат:

В данном случае поиск мне показал, что у меня 33 элемента, в которых встречается слово книга. Причем поисковая выдача выводит все элементы по типу файлов с выделением слова, которое я искал.
А я уже в выведенном списке могу найти нужный мне файл и перейти на него, просто дважды быстро кликнув на него. Если это файл, то он откроется сразу же. Если это папка с файлами, то откроется папка.
Или я могу сузить поиск, чтобы список файлом был поменьше. Например, напишу слово самых. Мгновенно получаю нужную мне папку:

Как видите, находить файлы и папки на компьютере очень просто с программой Everything. Радует, что она бесплатная, на русском языке и очень быстро выдает результаты поиска!
Дополнительные настройки Everything
Программа Everything изначально уже оптимально настроена для большинства пользователей. Однако есть дополнительные возможности, которые можно использовать при необходимости.
Так, например, с помощью меню Поиск можно указывать, по каким критериям выводить выдачу: по файлам определенных форматов, по папкам или всё. Такие ограничения могут пригодиться, если название встречается в разных файлах и список таких файлов большой. А благодаря ограничению по определенным категориям, можно прицельно сузить поиск:

Также было бы полезно просто просмотреть функции, которые можно найти в меню Сервис -> Настройки. Повторюсь, что по умолчанию уже все настроено для запросов большинства пользователей, но, возможно, какие-то дополнительные настройки Вы захотите включить или наоборот отключить.
Портативная версия программы поиска Everything
В начале статьи мы уже говорили о такой портативной версии данной программы. Пользоваться портативной версией также как и стационарной. Стоит лишь только упомянуть, что портативная версия запакована в архив.
Поэтому, после скачивания архива портативной версии нужен архиватор, чтобы можно было открыть архив. Если скачанный архив не получается открыть, значит на компьютере не установлен архиватор. В таком случае скачайте и установите бесплатный архиватор 7-Zip, установку и использование которого мы уже рассматривали в отдельной статье.
Если Вы планируете использовать портативную версию на компьютере, у которого не знаете какая разрядность, — используете архив предназначенный для 32 разрядных систем. Или лучше скачайте обе версии, — какая-то точно запустится, а иначе просто выдаст сообщение:

Итак: Если вам приходится даже время от времени искать файлы или папки на компьютере, уверен Вы оцените эту бесплатную программу!
Скачивайте, пользуйтесь, делитесь в комментариях впечатлениями!
DocFetcher – это приложение с открытым исходным кодом, позволяющее вам совершать поиск по содержимому файлов на вашем компьютере. — Это как Google, но только для локальных файлов. Приложение работает на Windows, Linux и OS X. Распространяется по лицензии Eclipse Public License.
Приведённый ниже скриншот отображает основной пользовательский интерфейс программы. Запросы вводятся в текстовое поле (1). Результаты поиска отображаются в панели результатов (2). В поле предпросмотра (3) можно увидеть текстовое содержание файлого, выделенного в панели результатов. Все совпадения выделены жёлтым.
Вы можете фильтровать результаты, указав минимальный или максимальный размер файла (4), тип файла (5) или его расположение (6). Кнопки, отмеченные цифрой (7), используются для вызова руководства пользователя, настроек и сворачивания программы в трей.

Для работы DocFetcher необходимо проиндексиоровать те папки, в которых вы хотите осуществлять поиск. Что такое индексация и как она работает подробнее описано ниже. Вкратце, индекс позволят DocFetcher быстро (буквально за несколько мгновений) определить, в каких файлах содержится определённый набор слов. Соответственно, скоость поиска увеличивается. Данный скриншот показывает диалог DocFetcher по созданию новых индексов.
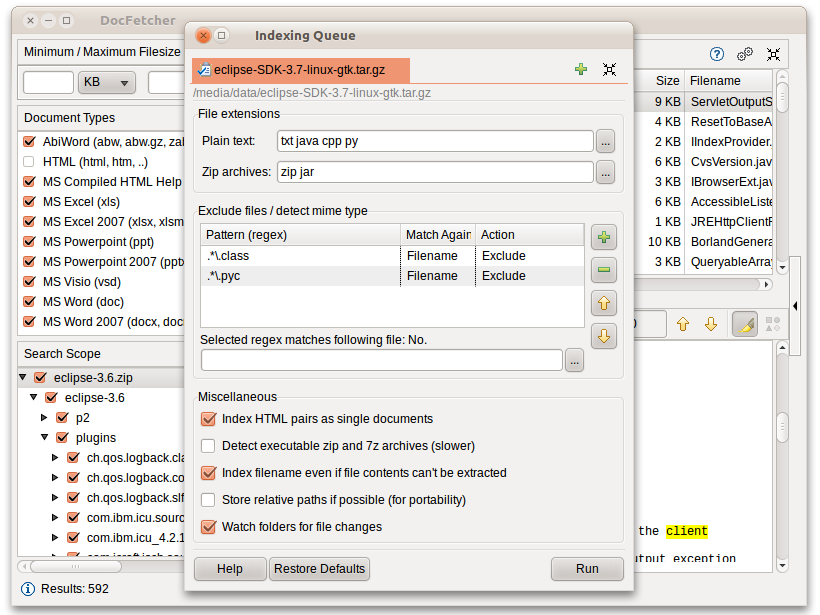
Нажатие на кнопку «Запуск» внизу этого диалогового окна запускает индексацию. Процесс индексирования может занять некоторое время, в зависимости от количества и размера файлов для индексирования. Как правило, в минуту индексируется около двухсот файлов.
Нет необходимости каждый раз индексировать заново одну и ту же папку. Обновление индекса папки после изменения её содержимого происходит гораздо быстрее. Этот процесс обычно занимает несколько секунд.
- Портативная версия: Портативная версия DocFetcher работает на Windows, Linux и OS X. Ниже описано, зачем это нужно.
- Поддержка 64-битных систем: Поддерживаются как 32-битные, так и 64-битные операционные системы.
- Поддержка Unicode: DocFetcher поддерживает Unicode для всех основных форматов файлов, включая Microsoft Office, OpenOffice.org, PDF, HTML, RTF и TXT.
- Поддержка архивированных файлов: DocFetcher поддерживает следующие форматы архивов: zip, 7z, rar, и всё семейство архивов tar.*. Список расширений файлов для zip-архивов может быть изменён, что позволит вам добавить поддержку других форматов, основанных на zip. Кроме того, DocFetcher может с лёгкосьтью справляется с неограниченным количеством вложенных архивов.
- Поиск в файлах исходных кодов: Расширения файлов, в которых DocFetcher распознаёт обычный текст, может быть изменён, это позволит вам использовать DocFetcher для поиска в исходном коде любого вида и других текстовых форматах. (Эта функция в сочетании с функцией изменения расширений для zip-архивов даёт хорошие результаты, например, например, вы можете осуществлять поиск в исходном коде Java внутри файлов jar)
- Файлы Outlook PST: DocFetcher позволяет осуществлять поиск по письмам Outlook, которые обычно хранятся в файлах PST.
- Определение HTML-пар DocFetcher по умолчанию определяет пары HTML-файлов (например, файл под названием «foo.html» и папка под названием «foo_files») и рассматривает их как один документ. На первый взгляд эта функция может показаться бесполезной, но на самом деле она сильно увеличивает производительность при поиске по файлам HTML, так как вся неразбериха из HTML-папок не попадает в результаты поиска.
- Исключения файлов из индекса на основе регулярных выражений: Вы можете использовать регулярные выражения, чтобы исключить определённые файлы из индекса. Например, чтобы исключить файлы Microsoft Excel, вы можете использовать такое регулярное выражение: .*.xls
- Определение MIME-типов: вы можете использовать регулярные выражения, чтобы включить «определение MIME-типов» для определённых файлов, что будет означать, что DocFetcher будет пытаться определить тип файла не просто по названию этого файла, но и по его содержимому.
- Мощный синтаксис запросов: В дополнение к стандартным выражениям типа ‘OR’, ‘AND’ и ‘NOT’, DocFetcher также поддерживает шаблоны подстановки, поиск фраз, неточный поиск («найти слова, похожие на данное»), поиск по соседству («эти два слова должны находиться на расстоянии не более чем в 10 слов друг от друга»), повышение («повысить оценку документов, содержащих…»)
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 и новее (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, . )
- Plain text (customizable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Вот чем выделяется DocFetcher на фоне других приложений по поиску на локальном компьютере:
Отсутсвие мусора: Интерефейс DocFetcher полностью чист. Никакой рекламы и всплывающих окон с предложением зарегестрироваться. Ничего ненужного не устанавливается в ваш браузер, реестр или ещё куда-нибудь.
Приватность DocFetcher не собирает вашу личную информацию. Никакую и никогда. Сомневающиеся могут проверить это, просмотрев исходный код программы.
Бесплатно навсегда: Так как у DocFetcher открытый исходный код, вам не стоит бояться, что программа когда-нибудь устареет и перестанет развиваться. А если говорить о технической поддержке, слышали ли вы о том, что Google Desktop, один из основных коммерческих конкурентов DocFetcher перестал разрабатываться в 2011? Вот.
Кроссплатформенность: В отличие от многих конкурентов, DocFetcher работает не только на Windows, но и на Linux, и на OS X. Таким образом, если вы вдруг решите перейти с Windows на Linux или OS X, DocFetcher будет ждать вас там.
*Портативность: Один из главных плюсов DocFetcher – это портативность. Короче говоря, вы можете создать полноценное доступное для поиска хранилище документов на USB-носителе. Подробнее в следующем разделе.
Индексирование только необходимых документов: Среди коммерческих конкурентов DocFetcher наблюдается тенденция по сканированию всего жёсткого диска — Возможно, это делается из соображений о том, что пользователи «туповаты» и не смогут правильно пользоваться программой. А возможно, программы собирают таким образом конфиденциальные данные. Практика показывает, что большинство пользователей не хотят индексировать весь жёсткий диск. Не только из-за пустой трата времени и места на диске, но ещё и потому, что это засоряет поисковую выдачу ненужными файлами. DocFetcher же индексирует только те папки, на которые вы укажете. А ещё вам доступно множество опций фильтрации.
Одна из выдающихся особенностей DocFetcher – это его доступность в виде портативной версии, которая позволяет вам создать портативное хранилище документов — полностью доступное для индекса и поиска. Вы можете взять с собой.
Примеры использования: Вот что вы можете делать с таким хранилищем документов: вы можете взять его с собой на USB-диске, записать его на CD в целях архивации, поместить его на защищённый раздел диска (рекомендуем использовать TrueCrypt), синхронизировать его с другими компьютерами через облачное хранилище вроде DropBox. А так как у DocFetcher открытый исходный код, вы можете поделиться своим хранилищем документов со всем миром, если вдруг вам захочется.
Java: Производительность и портативность: Наверное, не всем нравится тот факт, что DocFetcher написан на платформе Java, имеющей репутацию «медленной». Лет десять назад производительность Java действительно оставляла желать лучшего, но сейчас всё хорошо, можете почитать об этом на Википедии. Как бы то ни было, Java позволяет одному и тому же пакету DocFetcher быть запущеным на Windows, Linux и OS X — В то же время многие другие программы требуют разных пакетов для каждой платформы. В итоге вы можете, например, поместить ваше портативное хранилище документов на USB-диск, а потом получить доступ к нему из любой из вышеперечисленных операционных систем, убедившись, что в системе установлена Java.
Данный раздел даёт базовое представление о том, что такое индексация и как она работает.
Простой подход к поиску файлов: Самым простым подходом к файловому поиску является банальный перебор каждого файла в папке. Это отличное решение для поиска только по имени файла, ведь анализ названий происходит достаточно быстро. Но если вам необходим поиск по содержимому файлов, то перебор здесь не подойдёт – извлечение текста более трудоёмкая задача.
Поиск, основанный на индексе: Именно поэтому DocFetcher, выполняя поиск по содержимому, использует подход, называемый «индексация». Считается, что большинство файлов (примерно 95%), по которым пользователь осуществляет поиск, не изменяются (как минимум делают это редко). Вместо того, чтобы открывать каждый файл после каждого нового поискового запроса, гораздо эффективнее было бы сделать это лишь раз. Таким образом создаётся что-то вроде словаря, который называется индексом. Он позволяет быстро находить документы по содержащимся в них словам.
Сравнение с телефонной книгой: Просто подумайте о том, насколько удобнее искать чей-то номер телефона в телефонной книге (это своеобразный индекс), а не обзванивать каждый возможный номер телефона с целью узнать, не является ли человек на другом конце провода тем, кого вы ищете. — Звонок кому-либо и извлечение текста из файла – это трудоёмкие операции. Кроме того, люди не очень часто меняют свои телефонные номера. Точно так же и многие файлы на компьютере долго остаются неизменными.
Обновления индекса: Конечно, индекс отображает файлы в их состоянии на момент индексирования. А оно могло и измениться. То есть, если индекс не актуален, результаты поиска будут устаревшими. Точно так же устаревает телефонная книга. Но это не проблема. Как мы уже знаем, большинство файлов обновляется очень редко. Кроме того, DocFetcher может автоматически обновлять индексы: (1) При запуске он определяет изменённые файлы и, соответственно, обновляет их индексы. (2) Когда он не запущен, маленький фоновый процесс будет определять изменения в файлах и составлять список тех из них, которые требуют обновления индекса. DocFetcher обновит эти индексы при следующем запуске. Вы можете не беспокоиться об этом фоновом процессе: он действительно мало нагружает процессор и память, так как не делает ничего, кроме обнаружения изменения в папках, оставляя боле затратное обновления индекса DocFetcher.