try this:
declare @YourTable table (id int, name varchar(10), email varchar(50))
INSERT @YourTable VALUES (1,'John','John-email')
INSERT @YourTable VALUES (2,'John','John-email')
INSERT @YourTable VALUES (3,'fred','John-email')
INSERT @YourTable VALUES (4,'fred','fred-email')
INSERT @YourTable VALUES (5,'sam','sam-email')
INSERT @YourTable VALUES (6,'sam','sam-email')
SELECT
name,email, COUNT(*) AS CountOf
FROM @YourTable
GROUP BY name,email
HAVING COUNT(*)>1
OUTPUT:
name email CountOf
---------- ----------- -----------
John John-email 2
sam sam-email 2
(2 row(s) affected)
if you want the IDs of the dups use this:
SELECT
y.id,y.name,y.email
FROM @YourTable y
INNER JOIN (SELECT
name,email, COUNT(*) AS CountOf
FROM @YourTable
GROUP BY name,email
HAVING COUNT(*)>1
) dt ON y.name=dt.name AND y.email=dt.email
OUTPUT:
id name email
----------- ---------- ------------
1 John John-email
2 John John-email
5 sam sam-email
6 sam sam-email
(4 row(s) affected)
to delete the duplicates try:
DELETE d
FROM @YourTable d
INNER JOIN (SELECT
y.id,y.name,y.email,ROW_NUMBER() OVER(PARTITION BY y.name,y.email ORDER BY y.name,y.email,y.id) AS RowRank
FROM @YourTable y
INNER JOIN (SELECT
name,email, COUNT(*) AS CountOf
FROM @YourTable
GROUP BY name,email
HAVING COUNT(*)>1
) dt ON y.name=dt.name AND y.email=dt.email
) dt2 ON d.id=dt2.id
WHERE dt2.RowRank!=1
SELECT * FROM @YourTable
OUTPUT:
id name email
----------- ---------- --------------
1 John John-email
3 fred John-email
4 fred fred-email
5 sam sam-email
(4 row(s) affected)
Сборник запросов для поиска, изменения и удаления дублей в таблице MySQL по одному и нескольким полям. В примерах все запросы будут применятся к следующий таблице:
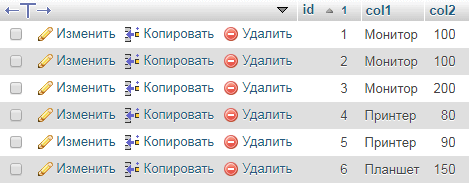
1
Поиск дубликатов
Подсчет дублей
Запрос подсчитает количество всех записей с одинаковыми значениями в поле `col1`.
SELECT
`col1`,
COUNT(`col1`) AS `count`
FROM
`table`
GROUP BY
`col1`
HAVING
`count` > 1SQL

Подсчет дубликатов по нескольким полям:
SELECT
`col1`,
`col2`,
COUNT(*) AS `count`
FROM
`table`
GROUP BY
`col1`,`col2`
HAVING
`count` > 1SQL

Все записи с одинаковыми значениями
Запрос найдет все записи с одинаковыми значениями в `col1`.
SELECT
*
FROM
`table`
WHERE
`col1` IN (SELECT `col1` FROM `table` GROUP BY `col1` HAVING COUNT(*) > 1)
ORDER BY
`col1`SQL
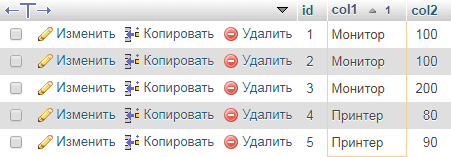
Для одинаковых значений в `col1` и `col2`:
SELECT
*
FROM
`table`
WHERE
`col1` IN (SELECT `col1` FROM `table` GROUP BY `col1` HAVING COUNT(*) > 1)
AND `col2` IN (SELECT `col2` FROM `table` GROUP BY `col2` HAVING COUNT(*) > 1)
ORDER BY
`col1`SQL
Получить только дубликаты
Запрос получит только дубликаты, в результат не попадают записи с самым ранним `id`.
SELECT
`table`.*
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL

Для нескольких полей:
SELECT
`table`.*
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`a`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
2
Уникализация записей
Запрос сделает уникальные названия только у дублей, дописав `id` в конец `col1`.
UPDATE
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
SET
`table`.`col1` = CONCAT(`table`.`col1`, '-', `table`.`id`)
WHERE
`tmp`.`id` IS NULLSQL
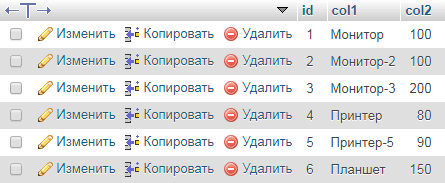
По нескольким полям:
UPDATE
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
SET
`table`.`col1` = CONCAT(`table`.`col1`, '-', `table`.`id`)
WHERE
`tmp`.`id` IS NULLSQL
3
Удаление дубликатов
Удаление дублирующихся записей, останутся только уникальные.
DELETE
`table`
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
По нескольким полям:
DELETE
`table`
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
I have a table with a varchar column, and I would like to find all the records that have duplicate values in this column. What is the best query I can use to find the duplicates?
asked Mar 27, 2009 at 4:22
![]()
Jon TackaburyJon Tackabury
47.4k50 gold badges129 silver badges167 bronze badges
3
Do a SELECT with a GROUP BY clause. Let’s say name is the column you want to find duplicates in:
SELECT name, COUNT(*) c FROM table GROUP BY name HAVING c > 1;
This will return a result with the name value in the first column, and a count of how many times that value appears in the second.
![]()
the Tin Man
158k42 gold badges214 silver badges302 bronze badges
answered Mar 27, 2009 at 4:24
![]()
12
SELECT varchar_col
FROM table
GROUP BY varchar_col
HAVING COUNT(*) > 1;
![]()
simhumileco
31.2k16 gold badges137 silver badges112 bronze badges
answered Mar 27, 2009 at 4:27
![]()
maxyfcmaxyfc
11.1k7 gold badges36 silver badges46 bronze badges
2
SELECT *
FROM mytable mto
WHERE EXISTS
(
SELECT 1
FROM mytable mti
WHERE mti.varchar_column = mto.varchar_column
LIMIT 1, 1
)
ORDER BY varchar_column
This query returns complete records, not just distinct varchar_column‘s.
This query doesn’t use COUNT(*). If there are lots of duplicates, COUNT(*) is expensive, and you don’t need the whole COUNT(*), you just need to know if there are two rows with same value.
This is achieved by the LIMIT 1, 1 at the bottom of the correlated query (essentially meaning «return the second row»). EXISTS would only return true if the aforementioned second row exists (i. e. there are at least two rows with the same value of varchar_column) .
Having an index on varchar_column will, of course, speed up this query greatly.
![]()
techtheatre
5,4987 gold badges31 silver badges51 bronze badges
answered Mar 27, 2009 at 10:54
![]()
QuassnoiQuassnoi
411k91 gold badges612 silver badges612 bronze badges
11
Building off of levik’s answer to get the IDs of the duplicate rows you can do a GROUP_CONCAT if your server supports it (this will return a comma separated list of ids).
SELECT GROUP_CONCAT(id), name, COUNT(*) c
FROM documents
GROUP BY name
HAVING c > 1;
![]()
Novocaine
4,6534 gold badges43 silver badges66 bronze badges
answered Feb 19, 2015 at 0:56
![]()
Matt R.Matt R.
2,1291 gold badge16 silver badges19 bronze badges
3
to get all the data that contains duplication i used this:
SELECT * FROM TableName INNER JOIN(
SELECT DupliactedData FROM TableName GROUP BY DupliactedData HAVING COUNT(DupliactedData) > 1 order by DupliactedData)
temp ON TableName.DupliactedData = temp.DupliactedData;
TableName = the table you are working with.
DupliactedData = the duplicated data you are looking for.
![]()
slfan
8,920115 gold badges65 silver badges78 bronze badges
answered May 8, 2019 at 8:40
![]()
udiudi
2413 silver badges5 bronze badges
2
Assuming your table is named TableABC and the column which you want is Col and the primary key to T1 is Key.
SELECT a.Key, b.Key, a.Col
FROM TableABC a, TableABC b
WHERE a.Col = b.Col
AND a.Key <> b.Key
The advantage of this approach over the above answer is it gives the Key.
answered Mar 27, 2009 at 4:29
![]()
TechTravelThinkTechTravelThink
2,9843 gold badges20 silver badges13 bronze badges
3
Taking @maxyfc’s answer further, I needed to find all of the rows that were returned with the duplicate values, so I could edit them in MySQL Workbench:
SELECT * FROM table
WHERE field IN (
SELECT field FROM table GROUP BY field HAVING count(*) > 1
) ORDER BY field
answered Aug 1, 2017 at 22:29
![]()
AbsoluteƵERØAbsoluteƵERØ
7,8162 gold badges24 silver badges35 bronze badges
SELECT *
FROM `dps`
WHERE pid IN (SELECT pid FROM `dps` GROUP BY pid HAVING COUNT(pid)>1)
![]()
demongolem
9,42036 gold badges90 silver badges105 bronze badges
answered May 22, 2014 at 14:48
![]()
strustamstrustam
1211 silver badge2 bronze badges
1
To find how many records are duplicates in name column in Employee, the query below is helpful;
Select name from employee group by name having count(*)>1;
![]()
davejal
5,98910 gold badges39 silver badges82 bronze badges
answered Nov 24, 2015 at 12:12
![]()
0
My final query incorporated a few of the answers here that helped — combining group by, count & GROUP_CONCAT.
SELECT GROUP_CONCAT(id), `magento_simple`, COUNT(*) c
FROM product_variant
GROUP BY `magento_simple` HAVING c > 1;
This provides the id of both examples (comma separated), the barcode I needed, and how many duplicates.
Change table and columns accordingly.
answered May 5, 2017 at 2:38
![]()
I am not seeing any JOIN approaches, which have many uses in terms of duplicates.
This approach gives you actual doubled results.
SELECT t1.* FROM my_table as t1
LEFT JOIN my_table as t2
ON t1.name=t2.name and t1.id!=t2.id
WHERE t2.id IS NOT NULL
ORDER BY t1.name
![]()
Mahbub
4,7321 gold badge31 silver badges34 bronze badges
answered Apr 20, 2018 at 10:33
![]()
Adam FischerAdam Fischer
1,07511 silver badges23 bronze badges
1
I saw the above result and query will work fine if you need to check single column value which are duplicate. For example email.
But if you need to check with more columns and would like to check the combination of the result so this query will work fine:
SELECT COUNT(CONCAT(name,email)) AS tot,
name,
email
FROM users
GROUP BY CONCAT(name,email)
HAVING tot>1 (This query will SHOW the USER list which ARE greater THAN 1
AND also COUNT)
![]()
davejal
5,98910 gold badges39 silver badges82 bronze badges
answered May 30, 2016 at 7:42
1
I prefer to use windowed functions(MySQL 8.0+) to find duplicates because I could see entire row:
WITH cte AS (
SELECT *
,COUNT(*) OVER(PARTITION BY col_name) AS num_of_duplicates_group
,ROW_NUMBER() OVER(PARTITION BY col_name ORDER BY col_name2) AS pos_in_group
FROM table
)
SELECT *
FROM cte
WHERE num_of_duplicates_group > 1;
DB Fiddle Demo
answered Jul 12, 2018 at 17:40
![]()
Lukasz SzozdaLukasz Szozda
159k23 gold badges221 silver badges263 bronze badges
SELECT t.*,(select count(*) from city as tt
where tt.name=t.name) as count
FROM `city` as t
where (
select count(*) from city as tt
where tt.name=t.name
) > 1 order by count desc
Replace city with your Table.
Replace name with your field name
![]()
AbsoluteƵERØ
7,8162 gold badges24 silver badges35 bronze badges
answered Jan 25, 2013 at 5:59
![]()
0
SELECT ColumnA, COUNT( * )
FROM Table
GROUP BY ColumnA
HAVING COUNT( * ) > 1
![]()
AsgarAli
2,2011 gold badge20 silver badges32 bronze badges
answered Mar 27, 2009 at 4:28
![]()
Scott FergusonScott Ferguson
7,6707 gold badges41 silver badges64 bronze badges
1
I improved from this:
SELECT
col,
COUNT(col)
FROM
table_name
GROUP BY col
HAVING COUNT(col) > 1;
answered Oct 29, 2020 at 22:57
![]()
As a variation on Levik’s answer that allows you to find also the ids of the duplicate results, I used the following:
SELECT * FROM table1 WHERE column1 IN (SELECT column1 AS duplicate_value FROM table1 GROUP BY column1 HAVING COUNT(*) > 1)
answered Feb 24, 2021 at 1:07
![]()
SELECT
t.*,
(SELECT COUNT(*) FROM city AS tt WHERE tt.name=t.name) AS count
FROM `city` AS t
WHERE
(SELECT count(*) FROM city AS tt WHERE tt.name=t.name) > 1 ORDER BY count DESC
![]()
Moseleyi
2,5161 gold badge22 silver badges45 bronze badges
answered Feb 21, 2013 at 8:37
![]()
1
CREATE TABLE tbl_master
(`id` int, `email` varchar(15));
INSERT INTO tbl_master
(`id`, `email`) VALUES
(1, 'test1@gmail.com'),
(2, 'test2@gmail.com'),
(3, 'test1@gmail.com'),
(4, 'test2@gmail.com'),
(5, 'test5@gmail.com');
QUERY : SELECT id, email FROM tbl_master
WHERE email IN (SELECT email FROM tbl_master GROUP BY email HAVING COUNT(id) > 1)
![]()
kodabear
3401 silver badge14 bronze badges
answered Mar 4, 2016 at 7:55
![]()
SELECT DISTINCT a.email FROM `users` a LEFT JOIN `users` b ON a.email = b.email WHERE a.id != b.id;
![]()
answered Jul 1, 2013 at 18:17
![]()
Pawel FurmaniakPawel Furmaniak
4,6203 gold badges29 silver badges33 bronze badges
5
For removing duplicate rows with multiple fields , first cancate them to the new unique key which is specified for the only distinct rows, then use «group by» command to removing duplicate rows with the same new unique key:
Create TEMPORARY table tmp select concat(f1,f2) as cfs,t1.* from mytable as t1;
Create index x_tmp_cfs on tmp(cfs);
Create table unduptable select f1,f2,... from tmp group by cfs;
answered Feb 4, 2016 at 9:58
2
One very late contribution… in case it helps anyone waaaaaay down the line… I had a task to find matching pairs of transactions (actually both sides of account-to-account transfers) in a banking app, to identify which ones were the ‘from’ and ‘to’ for each inter-account-transfer transaction, so we ended up with this:
SELECT
LEAST(primaryid, secondaryid) AS transactionid1,
GREATEST(primaryid, secondaryid) AS transactionid2
FROM (
SELECT table1.transactionid AS primaryid,
table2.transactionid AS secondaryid
FROM financial_transactions table1
INNER JOIN financial_transactions table2
ON table1.accountid = table2.accountid
AND table1.transactionid <> table2.transactionid
AND table1.transactiondate = table2.transactiondate
AND table1.sourceref = table2.destinationref
AND table1.amount = (0 - table2.amount)
) AS DuplicateResultsTable
GROUP BY transactionid1
ORDER BY transactionid1;
The result is that the DuplicateResultsTable provides rows containing matching (i.e. duplicate) transactions, but it also provides the same transaction id’s in reverse the second time it matches the same pair, so the outer SELECT is there to group by the first transaction ID, which is done by using LEAST and GREATEST to make sure the two transactionid’s are always in the same order in the results, which makes it safe to GROUP by the first one, thus eliminating all the duplicate matches. Ran through nearly a million records and identified 12,000+ matches in just under 2 seconds. Of course the transactionid is the primary index, which really helped.
![]()
answered Sep 6, 2016 at 13:52
![]()
0
Select column_name, column_name1,column_name2, count(1) as temp from table_name group by column_name having temp > 1
answered Dec 18, 2015 at 18:21
![]()
Vipin JainVipin Jain
3,67816 silver badges35 bronze badges
If you want to remove duplicate use DISTINCT
Otherwise use this query:
SELECT users.*,COUNT(user_ID) as user FROM users GROUP BY user_name HAVING user > 1;
![]()
benc
1,3435 gold badges31 silver badges39 bronze badges
answered Jan 14, 2019 at 7:21
![]()
Thanks to @novocaine for his great answer and his solution worked for me. I altered it slightly to include a percentage of the recurring values, which was needed in my case. Below is the altered version. It reduces the percentage to two decimal places. If you change the ,2 to 0, it will display no decimals, and to 1, then it will display one decimal place, and so on.
SELECT GROUP_CONCAT(id), name, COUNT(*) c,
COUNT(*) OVER() AS totalRecords,
CONCAT(FORMAT(COUNT(*)/COUNT(*) OVER()*100,2),'%') as recurringPecentage
FROM table
GROUP BY name
HAVING c > 1
answered Sep 21, 2021 at 14:36
![]()
Iwan RossIwan Ross
1962 silver badges10 bronze badges
Try using this query:
SELECT name, COUNT(*) value_count FROM company_master GROUP BY name HAVING value_count > 1;
![]()
answered Nov 15, 2018 at 9:16
![]()
![]()
- Updated: June 12, 2022
- Initial: September 8, 2021

Aah…. duplicates! They are everywhere! Look around you – multiple charger cables, headphones, pictures in your smartphone! But we are not here to talk about those duplicates. No, Sir! We are here to address the duplicates in sql, how to find them and possibly resolve them in your SQL code.
In this SQL find duplicates post, let us look at 3 ways to identify duplicate rows/columns and then conclude by looking at 2 ways to mitigate them.
- Using Count
- MINUS Function
- Analytic Functions
Let us start by looking at a very simple database table, USER_DIET. The below listed table shows the Fruit consumption of Sam and John over two days.
Just by looking at the data can you tell if there are duplicates in the table, say for the column “NAME”?
| NAME | FRUIT | DAY |
| John | Apple | Monday |
| Sam | Orange | Monday |
| John | Orange | Tuesday |
| Sam | Banana | Tuesday |
| John | Peach | Wednesday |
| Sam | Banana | Wednesday |
The most obvious answer is YES! John occurs 3 times and so does Sam.
How about if we were to look at columns NAME and FRUIT? Once again, the answer would be YES, because “Sam” and “Banana” occurs twice. Apparently, Sam loves bananas, while John prefers a different fruit every day.
Finally, let’s look at columns NAME, FRUIT and DAY. Do you see any duplicates now?
The answer is NO. There are no duplicates because both Sam and John had a different fruit on each day.
The point I would like to drive home is this! To truly understand if data is duplicate, you need to understand the context and the functionality behind it.
Note: All SQL examples below use Oracle SQL syntax. However, they should work across most relational databases with minimal changes.
Related post: Apache Spark SQL date functions
1. SQL Find Duplicates using Count
The most common method to find duplicates in sql is using the count function in a select statement. There are two other clauses that are key to finding duplicates: GROUP BY and HAVING.
Let us continue using the database table (USER_DIET) from the previous example and see if we can find duplicates for the NAME column.
a. Duplicates in a single column
SELECT name,count(*)
FROM user_diet
GROUP BY name
HAVING count(*)>1;
Output from SQL statement:
NAME COUNT(*)
John 3
Sam 3
In this second example, let us look at finding duplicates in multiple columns: NAME and FRUIT.
Lets think this thru and put things in context before diving into our select statement. As yourself, what am I trying to find here ?
We are trying to find if any of the users, in this case, Sam/John had the same fruit twice. That it ! This context is based on the two fields NAME and FRUIT.
b. Duplicates in multiple columns
SELECT name, fruit, count(*)
FROM user_diet
GROUP BY name, fruit
HAVING count(*)>1;
Output from SQL statement:
NAME FRUIT COUNT(*)
Sam Banana 2
Key to remember, the columns in the select statement, excluding the count(*) should be the exact same in the group by clause as well.
Also note that using the count(*) function gives you a count of the number of occurrences of a value. In this case, “Sam” + “Banana” occurs twice in the table, but in actuality we only have one duplicate row.
c. SQL to find duplicate rows
The SQL to find duplicate rows in a table is not the same as checking for duplicates in a column.
Ideally, if the database table has the right combination of key columns, you should not have duplicate rows. Regardless, if you are suspicious that your table has duplicate rows, perform the below steps.
- Determine they Key columns on your table.
- If the table does not have keys defined, determine which column(s) makes a row unique. Often times this depends on the functional use case of the data.
- Add the fields from Step 1 or Step 2 to your SQL COUNT(*) clause.
Using the USER_DIET table above, lets assume no keys were defined on the table. Our next option would be determining which column(s) makes a row unique.
Note that the table has 3 rows. If Sam or Jon had the same fruit more than once on the same day, this would create a duplicate row.
Could Sam or Jon eating different fruits on the same day be considered a duplicate row?
The answer – Maybe! It depends on the functional use case of the data.
The SQL to find duplicate rows syntax is as shown below.
SELECT name, fruit, day, count(*) from user_diet GROUP BY name, fruit, day HAVING count(*)>1;
2. SQL Find Duplicates using MINUS function
The MINUS function works on two tables ( or datasets) and returns rows from the first table that does not belong in the second table. This option using the MINUS function in SQL, to find duplicates, is specific to Oracle. Use it for awareness and to validate your results using the count(*) method.
Find duplicates using MINUS function and rowid
SELECT name, rowid FROM user_diet
MINUS
SELECT name, MIN(rowid) FROM user_diet
GROUP BY name;
Output from SQL statement:
NAME COUNT(*)
Sam 2
ROWID is a pseudo column in Oracle and contains a distinct ID for each row in a table.
The first select statement (before the MINUS function) returns 6 rows containing NAME and a distinct value for the ROWID column. The second select statement on the other hand returns 2 rows, one for Sam and one for John. Why do you think that is ?
It’s because of the min function on the ROWID column.
The final output contains the “actual” number of duplicate rows, and not the total number of rows like the count(*) function.
Find duplicates using MINUS function and rownum
SELECT name, rownum FROM user_diet
MINUS
SELECT name, rownum FROM
(SELECT DISTINCT name FROM user_diet);
Output from SQL statement:
NAME COUNT(*)
Sam 2
In this second example, we used ROWNUM, which is a pseudo column used to uniquely identify the order of each row in a select statement.
So, what’s the difference between ROWNUM and ROWID in our example?
They are both pseudo columns in Oracle.
ROWNUM is a number and is generated on the result of the SQL statement. ROWID on the other hand is associated with each row of a table.
3. Find Duplicates in SQL using Analytic functions
Analytic functions are used to perform calculations on a grouping of data, normally called a “window”. This technique can be a bit confusing if you are just starting off with SQL, but it’s definitely worth knowing.
SELECT name, ROW_NUMBER() OVER ( PARTITION BY ssn ORDER BY ssn) AS rnum
FROM user_diet;
Output from SQL statement:
NAME RNUM
John 1
John 2
John 3
Sam 1
Sam 2
Sam 3
What are we doing here?
We are attempting to find if any duplicates exist for the column NAME.
Let’s break down this SQL and make sense of it.
The function ROW_NUMBER() assigns a number starting at 1 to the rows returned by the PARTITION window.
In our case, since we partitioned our dataset on the NAME column, we have 2 datasets: one for Sam and one for John. ROW_NUMBER() now assigns a unique number to each of the 3 rows for Sam, resets the counter and then does the same for John.
The resulting output is as shown on the right side of the query.
One of the reasons I love this technique is because I can turn the above SQL into a nested subquery and get a distinct set of records as shown below.
SELECT name FROM (
SELECT name, ROW_NUMBER() OVER ( PARTITION BY name ORDER BY name) AS rnum FROM user_diet)
WHERE rnum = 1;
Conclusion
A final tidbit, SQL is not limited to transactional databases.
Apache Spark has a module called Spark SQL to handle structured data. AWS Athena even lets you write SQL against files!
The demand for SQL skills is endless. So play around with what you learned here. Try selecting multiple columns, switch the PARTITIONS, change the SORT order. Practice is the best way to master something !
SQL helpful links
Table of Contents
Interested in our services ?
email us at : info@obstkel.com
Copyright 2022 © OBSTKEL LLC. All rights Reserved
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.

Время от времени возникает такая задача как поиск дубликатов в выборке в SQL.
Добиться этого можно следующим образом.
Допустим у нас есть некая таблица со значениями, которые могут повторяться.
Тогда делаем следующее:
-- выбираем значение и считаем сколько раз такое значение всречается в таблице
SELECT
value, COUNT(value)
FROM
table
-- группируем выборку по значению
GROUP BY
value
-- фильтруем выборку по количеству
HAVING
COUNT(value) > 1
Вот так можно найти дупликаты в выборке с помощью SQL.
-

Создано 20.08.2019 10:59:59
-
Михаил Русаков

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
Она выглядит вот так:
-
Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
