Содержание:
Точечные оценки:
Пусть случайная величина имеет неизвестную характеристику а. Такой характеристикой может быть, например, закон распределения, математическое ожидание, дисперсия, параметр закона распределения, вероятность определенного значения случайной величины и т.д. Пронаблюдаем случайную величину n раз и получим выборку из ее возможных значений 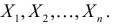
Существует два подхода к решению этой задачи. Можно по результатам наблюдений вычислить приближенное значение характеристики, а можно указать целый интервал ее значений, согласующихся с опытными данными. В первом случае говорят о точечной оценке, во втором – об интервальной.
Определение. Функция результатов наблюдений 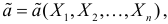
Для одной и той же характеристики можно предложить разные точечные оценки. Необходимо иметь критерии сравнения оценок, для суждения об их качестве. Оценка 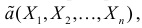 как функция случайных результатов наблюдений
как функция случайных результатов наблюдений 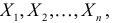 сама является случайной величиной. Значения
сама является случайной величиной. Значения 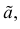 найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики
найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики 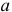 в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
Определение. Оценка называется несмещенной, если ее математическое ожидание равно оцениваемой величине: 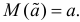 В противном случае оценку называют смещенной.
В противном случае оценку называют смещенной.
Определение. Оценка называется состоятельной, если при увеличении числа наблюдений она сходится по вероятности к оцениваемой величине, т.е. для любого сколь угодно малого 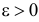
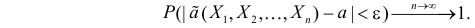
Если известно, что оценка 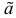 несмещенная, то для ее состоятельности достаточно, чтобы
несмещенная, то для ее состоятельности достаточно, чтобы
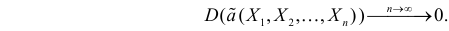
Последнее условие удобно для проверки. В качестве меры разброса значений оценки относительно 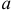 можно рассматривать величину
можно рассматривать величину 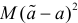 Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по
Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по 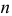 наблюдениям, то оценку называют эффективной.
наблюдениям, то оценку называют эффективной.
Следует отметить, что несмещенность и состоятельность являются желательными свойствами оценок, но не всегда разумно требовать наличия этих свойств у оценки. Например, может оказаться предпочтительней оценка хотя и обладающая небольшим смещением, но имеющая значительно меньший разброс значений, нежели несмещенная оценка. Более того, есть характеристики, для которых нет одновременно несмещенных и состоятельных оценок.
Оценки для математического ожидания и дисперсии
Пусть случайная величина имеет неизвестные математическое ожидание и дисперсию, причем 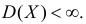 Если
Если 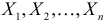 – результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений
– результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений 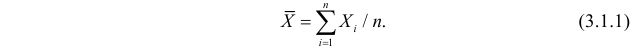
Несмещенность такой оценки следует из равенств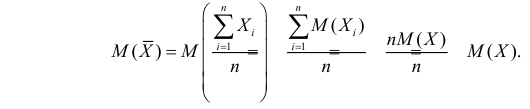
В силу независимости наблюдений 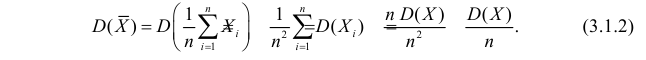
При условии 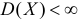 имеем
имеем 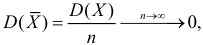 что означает состоятельность оценки
что означает состоятельность оценки 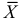 .
.
Доказано, что для математического ожидания нормально распределенной случайной величины оценка 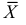 еще и эффективна.
еще и эффективна.
Оценка математического ожидания посредством среднего арифметического наблюдаемых значений наводит на мысль предложить в качестве оценки для дисперсии величину

Преобразуем величину 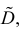 обозначая для краткости
обозначая для краткости 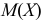 через
через 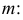
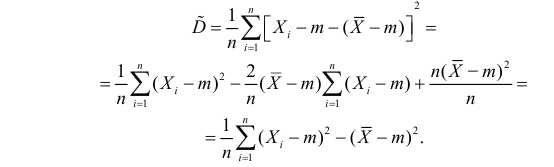
В силу (3.1.2) имеем 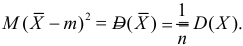 Поэтому
Поэтому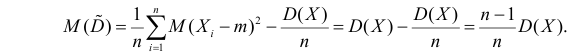
Последняя запись означает, что оценка 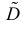 имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя
имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя 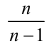 и полученную оценку обозначим через
и полученную оценку обозначим через 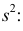
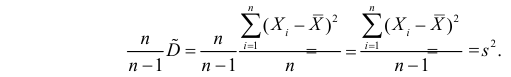
Величина
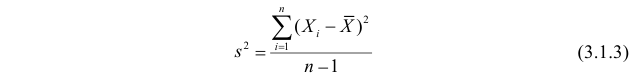
является несмещенной и состоятельной оценкой дисперсии.
Пример:
Оценить математическое ожидание и дисперсию случайной величины Х по результатам ее независимых наблюдений: 7, 3, 4, 8, 4, 6, 3.
Решение. По формулам (3.1.1) и (3.1.3) имеем 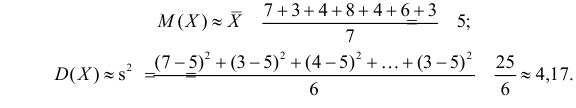
Ответ. 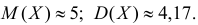
Пример:
Данные 25 независимых наблюдений случайной величины представлены в сгруппированном виде: 
Требуется оценить математическое ожидание и дисперсию этой случайной величины.
Решение. Представителем каждого интервала можно считать его середину. С учетом этого формулы (3.1.1) и (3.1.3) дают следующие оценки: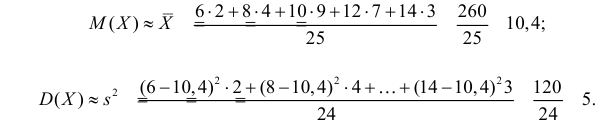
Ответ. 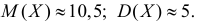
Метод наибольшего правдоподобия для оценки параметров распределений
В теории вероятностей и ее приложениях часто приходится иметь дело с законами распределения, которые определяются некоторыми параметрами. В качестве примера можно назвать нормальный закон распределения 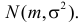 Его параметры
Его параметры 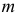 и
и 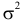 имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью
имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью 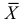 и
и 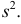 В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
Пусть случайная величина Х имеет функцию распределения 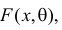 причем тип функции распределения F известен, но неизвестно значение параметра
причем тип функции распределения F известен, но неизвестно значение параметра 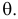 По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
Продемонстрируем идею метода наибольшего правдоподобия на упрощенном примере. Пусть по результатам наблюдений, отмеченных на рис. 3.1.1 звездочками, нужно отдать предпочтение одной из двух функций плотности вероятности 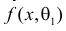 или
или 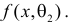
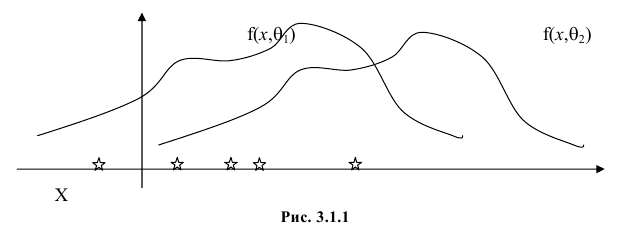
Из рисунка видно, что при значении параметра 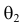 такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же
такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же 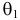 эти результаты наблюдений вполне возможны. Поэтому значение параметра
эти результаты наблюдений вполне возможны. Поэтому значение параметра 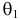 более правдоподобно, чем значение
более правдоподобно, чем значение 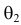 . Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
. Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
Этот принцип приводит к следующему способу действий. Пусть закон распределения случайной величины Х зависит от неизвестного значения параметра 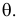 Обозначим через
Обозначим через 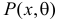 для непрерывной случайной величины плотность вероятности в точке
для непрерывной случайной величины плотность вероятности в точке 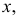 а для дискретной случайной величины – вероятность того, что
а для дискретной случайной величины – вероятность того, что 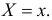 Если в
Если в 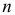 независимых наблюдениях реализовались значения случайной величины
независимых наблюдениях реализовались значения случайной величины 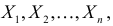 то выражение
то выражение 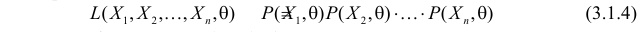
называют функцией правдоподобия. Величина 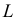 зависит только от параметра
зависит только от параметра 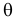 при фиксированных результатах наблюдений
при фиксированных результатах наблюдений 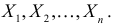 При каждом значении параметра
При каждом значении параметра 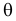 функция
функция 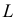 равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства
равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства 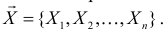
Сформулированный принцип предлагает в качестве оценки значения параметра выбрать такое 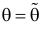 при котором принимает наибольшее значение. Величина
при котором принимает наибольшее значение. Величина 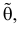 будучи функцией от результатов наблюдений
будучи функцией от результатов наблюдений 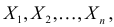 называется оценкой наибольшего правдоподобия.
называется оценкой наибольшего правдоподобия.
Во многих случаях, когда дифференцируема, оценка наибольшего правдоподобия находится как решение уравнения 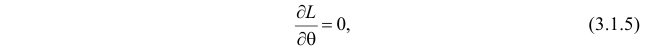
которое следует из необходимого условия экстремума. Поскольку 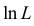 достигает максимума при том же значении
достигает максимума при том же значении 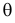 , что и , то можно решать относительно
, что и , то можно решать относительно 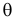 эквивалентное уравнение
эквивалентное уравнение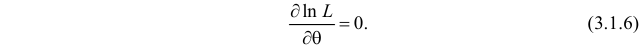
Это уравнение называют уравнением правдоподобия. Им пользоваться удобнее, чем уравнением (3.1.5), так как функция равна произведению, а – сумме, а дифференцировать проще.
Если параметров несколько (многомерный параметр), то следует взять частные производные от функции правдоподобия по всем параметрам, приравнять частные производные нулю и решить полученную систему уравнений.
Оценку, получаемую в результате поиска максимума функции правдоподобия, называют еще оценкой максимального правдоподобия.
Известно, что оценки максимального правдоподобия состоятельны. Кроме того, если для q существует эффективная оценка, то уравнение правдоподобия имеет единственное решение, совпадающее с этой оценкой. Оценка максимального правдоподобия может оказаться смещенной.
Метод моментов
Начальным моментом 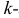 го порядка случайной величины Х называется математическое ожидание
го порядка случайной величины Х называется математическое ожидание 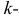 й степени этой величины, т.е.
й степени этой величины, т.е. 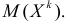 Само математическое ожидание считается начальным моментом первого порядка.
Само математическое ожидание считается начальным моментом первого порядка.
Центральным моментом 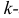 го порядка называется
го порядка называется 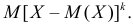 Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Для оценки параметров распределения по методу моментов находят на основе опытных данных оценки моментов в количестве, равном числу оцениваемых параметров. Эти оценки приравнивают к соответствующим теоретическим моментам, величины которых выражены через параметры. Из полученной системы уравнений можно определить искомые оценки.
Например, если Х имеет плотность распределения 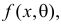 то
то 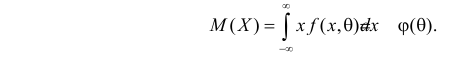
Если воспользоваться величиной 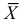 как оценкой для
как оценкой для 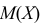 на основе опытных данных, то оценкой по методу моментов будет решение уравнения
на основе опытных данных, то оценкой по методу моментов будет решение уравнения 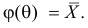
Пример:
Найти оценку параметра показательного закона распределения по методу моментов.
Решение. Плотность вероятности показательного закона распределения имеет вид 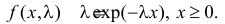 Поэтому
Поэтому 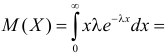
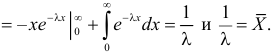 Откуда
Откуда 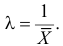
Ответ. 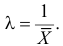
Пример:
Пусть имеется простейший поток событий неизвестной интенсивности 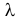 . Для оценки параметра
. Для оценки параметра 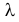 проведено наблюдение потока и зарегистрированы
проведено наблюдение потока и зарегистрированы 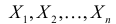 – длительности
– длительности 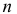 последовательных интервалов времени между моментами наступления событий. Найти оценку для
последовательных интервалов времени между моментами наступления событий. Найти оценку для 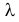 .
.
Решение. В простейшем потоке интервалы времени между последовательными моментами наступления событий потока имеют показательный закон распределения 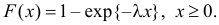 Так как плотность вероятности показательного закона распределения равна
Так как плотность вероятности показательного закона распределения равна 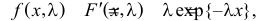 то функция правдоподобия (3.1.4) имеет вид
то функция правдоподобия (3.1.4) имеет вид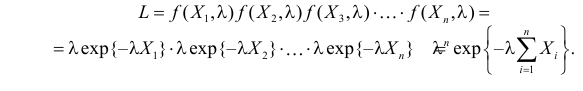
Тогда 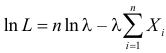 и уравнение правдоподобия
и уравнение правдоподобия 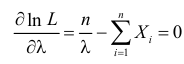 имеет решение
имеет решение 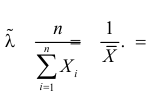
При таком значении 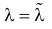 функция правдоподобия действительно достигает наибольшего значения, так как
функция правдоподобия действительно достигает наибольшего значения, так как 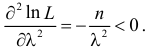
Ответ. 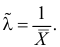
Определение. Пусть 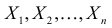 – результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:
– результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:

В этой записи 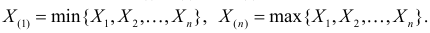
Величины 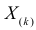 называют порядковыми статистиками.
называют порядковыми статистиками.
Пример:
Случайная величина Х имеет равномерное распределение на отрезке 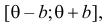 где
где 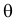 и
и 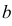 неизвестны. Пусть
неизвестны. Пусть 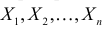 – результаты независимых наблюдений. Найти оценку параметра .
– результаты независимых наблюдений. Найти оценку параметра .
Решение. Функция плотности вероятности величины Х имеет вид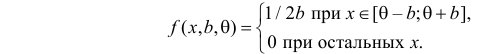
В этом случае функция правдоподобия 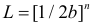 от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в
от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в 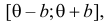 поэтому можно записать:
поэтому можно записать:
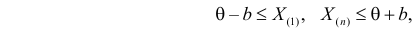
где 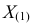 – наименьший, а
– наименьший, а 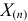 – наибольший из результатов наблюдений. При минимально возможном
– наибольший из результатов наблюдений. При минимально возможном
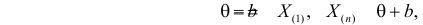
откуда 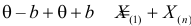 или
или 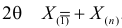
Оценкой наибольшего правдоподобия для параметра будет величина
Ответ. 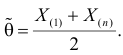
Пример:
Случайная величина X имеет функцию распределения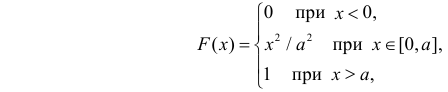
где 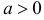 неизвестный параметр.
неизвестный параметр.
Пусть 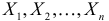 – результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра
– результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра 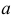 и найти оценку для M(X).
и найти оценку для M(X).
Решение. Для построения функции правдоподобия найдем сначала функцию плотности вероятности
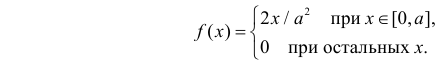
Тогда функция правдоподобия: 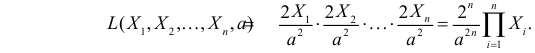
Логарифмическая функция правдоподобия: 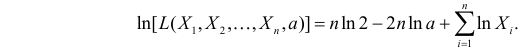
Уравнение правдоподобия

не имеет решений. Критических точек нет. Наибольшее и наименьшее значения находятся на границе допустимых значений 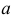 .
.
По виду функции можно заключить, что значение тем больше, чем меньше величина . Но не может быть меньше 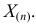 Поэтому наиболее правдоподобное значение
Поэтому наиболее правдоподобное значение 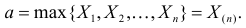
Так как 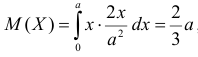 , то оценкой наибольшего правдоподобия для
, то оценкой наибольшего правдоподобия для 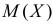 будет величина
будет величина 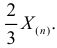
Ответ. 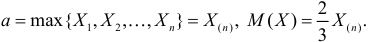
Пример:
Случайная величина Х имеет нормальный закон распределения 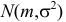 c неизвестными параметрами
c неизвестными параметрами 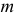 и
и 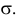 По результатам независимых наблюдений
По результатам независимых наблюдений 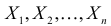 найти наиболее правдоподобные значения этих параметров.
найти наиболее правдоподобные значения этих параметров.
Решение. В соответствии с (3.1.4) функция правдоподобия имеет вид 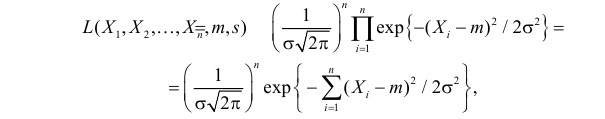
а логарифмическая функция правдоподобия: 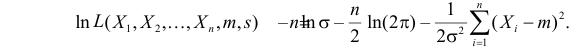
Необходимые условия экстремума дают систему двух уравнений: 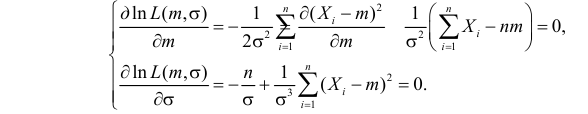
Решения этой системы имеют вид: 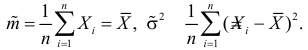
Отметим, что обе оценки являются состоятельными, причем оценка для 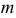 несмещенная, а для
несмещенная, а для 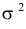 смещенная (сравните с формулой (3.1.3)).
смещенная (сравните с формулой (3.1.3)).
Ответ. 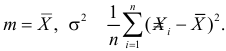
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. 1) Число экспериментальных данных вычисляется по формуле:
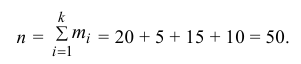
Значит, объем выборки n = 50.
2) Вычислим среднее арифметическое значение эксперимента:
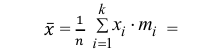
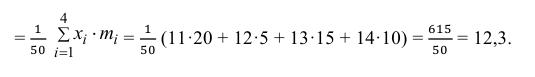
Значит, найдена оценка математического ожидания 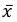 = 12,3.
= 12,3.
3) Вычислим исправленную выборочную дисперсию:
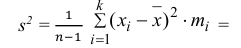
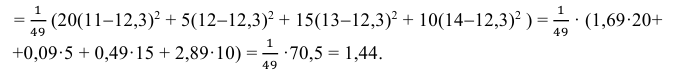
Значит, найдена оценка дисперсии: 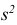 = 1,44.
= 1,44.
5) Вычислим оценку среднего квадратического отклонения:
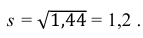
Ответ: 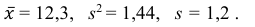
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. По формуле
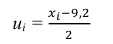
перейдем к условным вариантам:

Для них произведем расчет точечных оценок параметров:
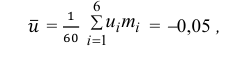
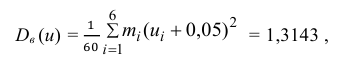
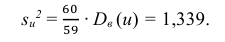
Следовательно, вычисляем искомые точечные оценки:
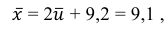
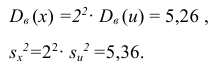
Ответ: 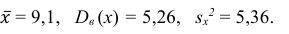
Пример:
По данным эксперимента построен интервальный статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения.
Решение. 1) От интервального ряда перейдем к статистическому ряду, заменив интервалы их серединами 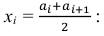

2) Объем выборки вычислим по формуле:
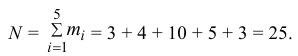
3) Вычислим среднее арифметическое значений эксперимента:
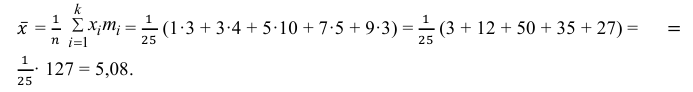
3) Вычислим исправленную выборочную дисперсию:
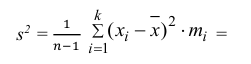
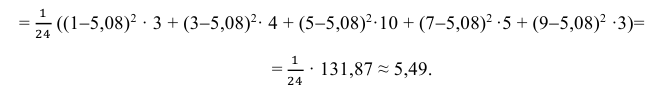
Можно было воспользоваться следующей формулой:
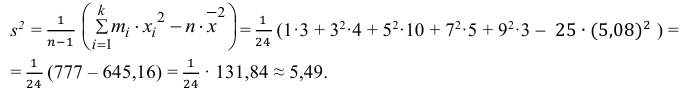
5) Вычислим оценку среднего квадратического отклонения:
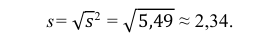
Ответ: 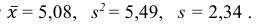
Пример:
Найти доверительный интервал с надежностью 0,95 для оценки математического ожидания M(X) нормально распределенной случайной величины X, если известно среднее квадратическое отклонение σ = 2, оценка математического ожидания 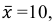 объем выборки n = 25.
объем выборки n = 25.
Решение. Доверительный интервал для истинного математического ожидания с доверительной вероятностью 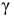 = 0,95 при известной дисперсии σ находится по формуле:
= 0,95 при известной дисперсии σ находится по формуле:
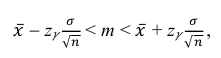
где m = M(X) – истинное математическое ожидание; 𝑥̅ − оценка M(X) по выборке; n – объем выборки; 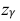 – находится по доверительной вероятности
– находится по доверительной вероятности 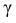 = 0,95 из равенства:
= 0,95 из равенства:
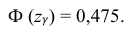
Из табл. П 2.2 приложения 2 находим: 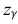 = 1,96. Следовательно, найден доверительный интервал для M(X):
= 1,96. Следовательно, найден доверительный интервал для M(X):
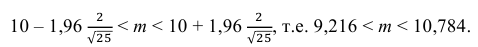
Ответ: (9,216 ; 10,784).
Пример:
По данным эксперимента построен статистический ряд:

Найти доверительный интервал для математического ожидания M (X) с надежностью 0,95.
Решение. Воспользуемся формулой для доверительного интервала математического ожидания при неизвестной дисперсии:
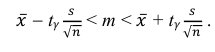
где n – объем выборки; 𝑥̅ оценка M(X); s – оценка среднего квадратического отклонения; 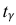 − находится по доверительной вероятности
− находится по доверительной вероятности 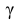 = 0,95.
= 0,95.
По числам 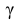 = 0,95 и n = 20 находим:
= 0,95 и n = 20 находим: 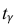 = 2,093.
= 2,093.
Теперь вычисляем оценки для M(X) и D(X):
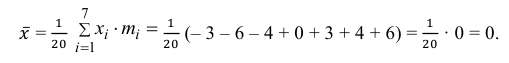
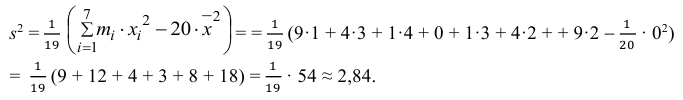
Следовательно, s ≈ 1,685. Поэтому искомый доверительный интервал математического ожидания задается формулой:
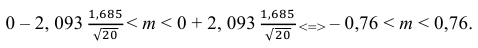
Ответ: (– 0,76; 0,76).
Пример:
По данным десяти независимых измерений найдена оценка квадратического отклонения 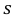 = 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
= 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
Решение. Задача сводится к нахождению доверительного интервала для истинного квадратического отклонения, так как точность прибора характеризуется средним квадратическим отклонением случайных ошибок измерений.
Доверительный интервал для среднего квадратического отклонения находим по формуле:
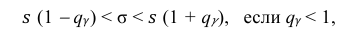
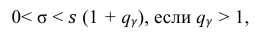
где  = 0,5 − оценка среднего квадратического отклонения;
= 0,5 − оценка среднего квадратического отклонения; 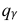 – число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности
– число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности 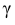 = 0,99 и заданному объему выборки n = 10.
= 0,99 и заданному объему выборки n = 10.
Находим: 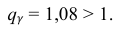
Тогда можно записать:
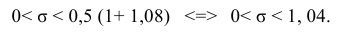
Ответ: (0; 1,04).
- Доверительный интервал для вероятности события
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Системы случайных величин
- Вероятность и риск
- Определения вероятности событий
- Предельные теоремы теории вероятностей
Мы уже упоминали, что оценивать вероятности классов как $softmax(f_w(x_i))$ для какой-то произвольной функции $f_w$ – это дело подозрительное. В этом разделе мы поговорим о том, как это делать хорошо и правильно.
Что же такое вероятность класса, если объект либо принадлежит этому классу, либо нет?
Ограничимся пока случаем двуклассовой классификации с классами 0 и 1. Пожалуй, если утверждается, что мы предсказываем корректную вероятность класса 1 (обозначим её $q(x_i)$), то прогноз «объект $x_i$ принадлежит классу 1 с вероятностью $frac23$» должен сбываться в $frac23$ случаев. То есть, условно говоря, если мы возьмём все объекты, которым мы предсказали вероятностью $frac23$, то среди них что-то около двух третей действительно имеет класс 1. На математическом языке это можно сформулировать так: Если $widehat{p}$ – предсказанная вероятность класса 1, то $P(y_i = 1 vert q(x_i) = widehat{p}) = widehat{p}$.
К сожалению, в реальной жизни $widehat{p}$ – это скорее всего вещественные числа, которые будут различными для различных $y_i$, и никаких вероятностей мы не посчитаем, но мы можем разбить отрезок $[0,1]$ на бины, внутри каждого из которых уже вычислить, каковая там доля объектов класса 1, и сравнить эту долю со средним значением вероятности в бине:
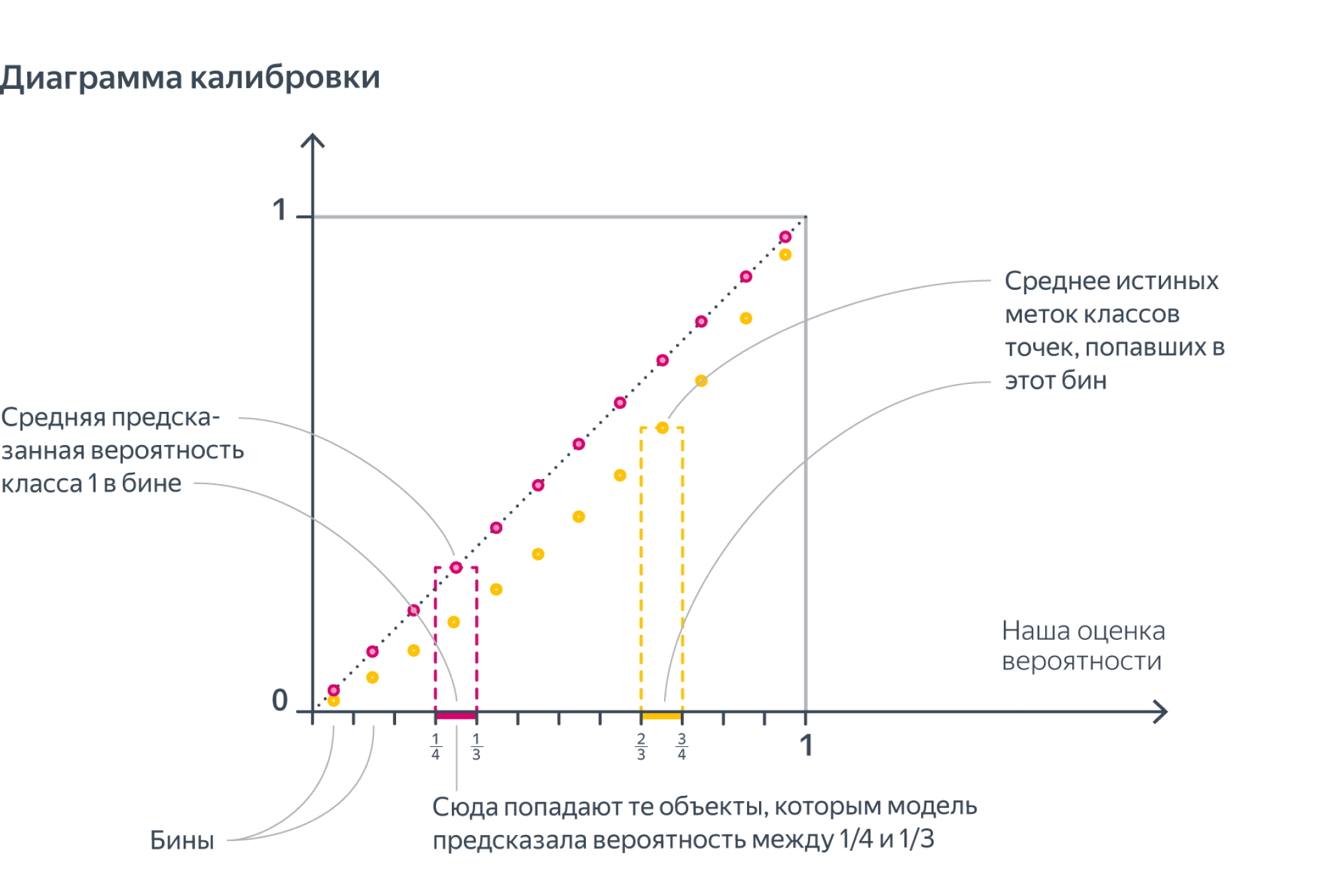
У модели, которая идеально предсказывает вероятности (как обычно говорят, у идеально калиброванной модели) жёлтые точки на диаграме калибровки должны совпадать с розовыми.
А вот на картинке выше это не так: жёлтые точки всегда ниже розовых. Давайте поймём, что это значит. Получается, что наша модель систематически завышает предсказанную вероятность (розовые точки), и порог отсечения нам, выходит, тоже надо было бы сдвинуть вправо:
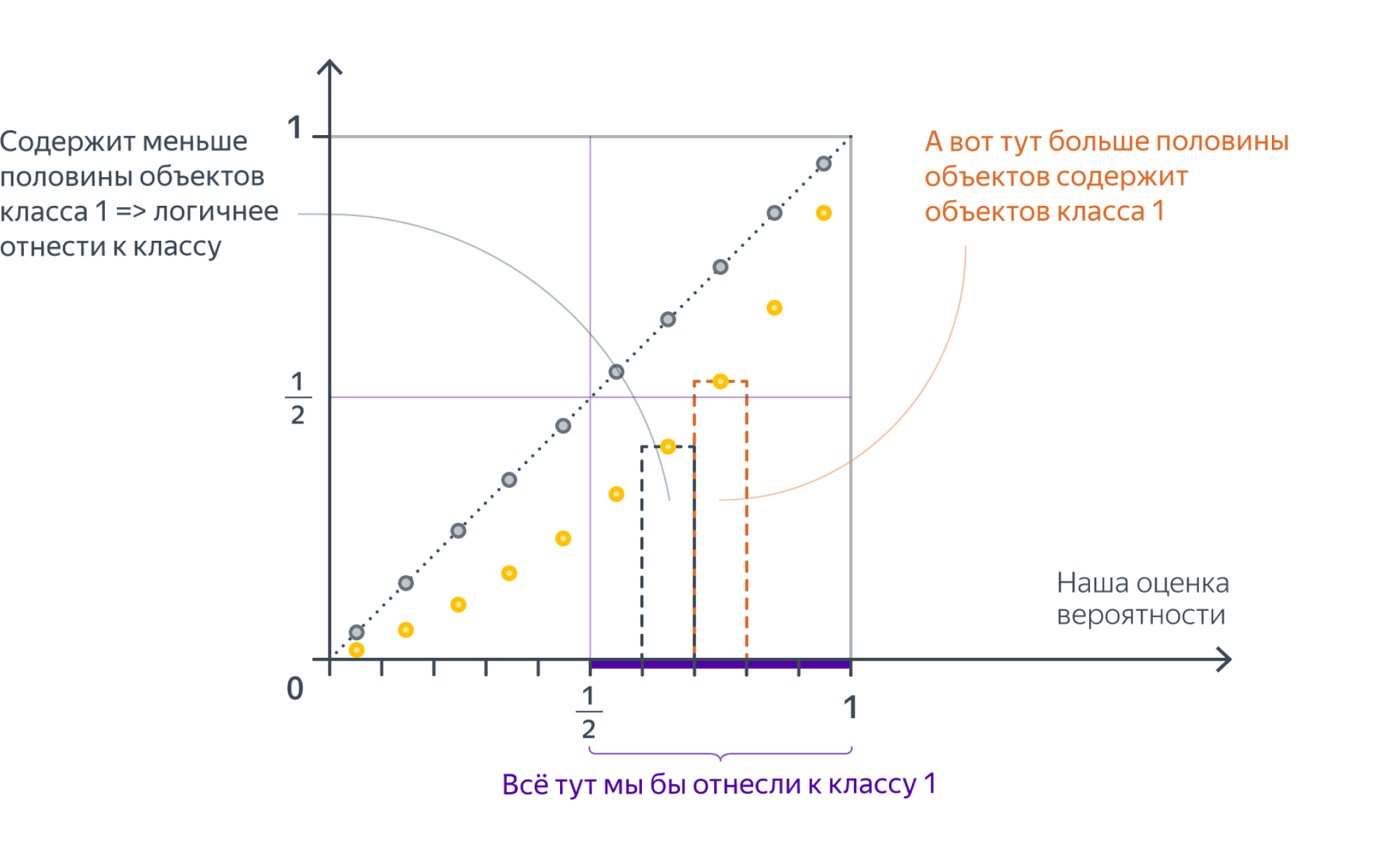
Но такая картинка, пожалуй, говорит о какой-то серьёзной патологии классификатора; гораздо чаще встречаются следующие две ситуации:
-
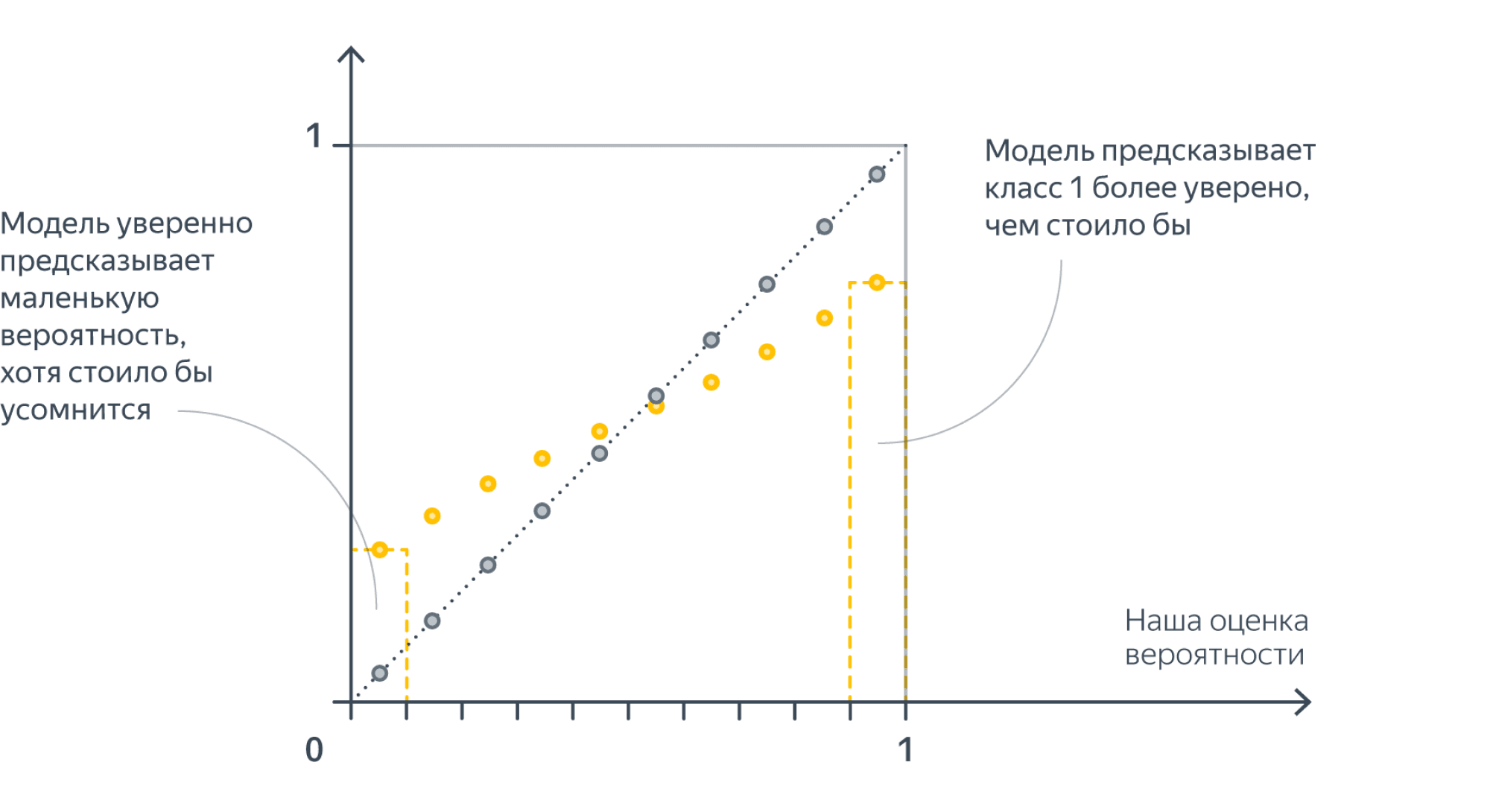
Слишком уверенный (overconfident) классификатор:
 Такое случается с сильными классификаторыми (например, нейросетями), которые учились на метки классов, а не на вероятности: тем самым процесс обучения стимулировал их всегда давать как можно более близкий к 0 или 1 ответ.
Такое случается с сильными классификаторыми (например, нейросетями), которые учились на метки классов, а не на вероятности: тем самым процесс обучения стимулировал их всегда давать как можно более близкий к 0 или 1 ответ. -
Неуверенный (underconfident) классификатор:
 Такое случается с сильными классификаторыми (например, нейросетями), которые учились на метки классов, а не на вероятности: тем самым процесс обучения стимулировал их всегда давать как можно более близкий к 0 или 1 ответ.
Такое случается с сильными классификаторыми (например, нейросетями), которые учились на метки классов, а не на вероятности: тем самым процесс обучения стимулировал их всегда давать как можно более близкий к 0 или 1 ответ.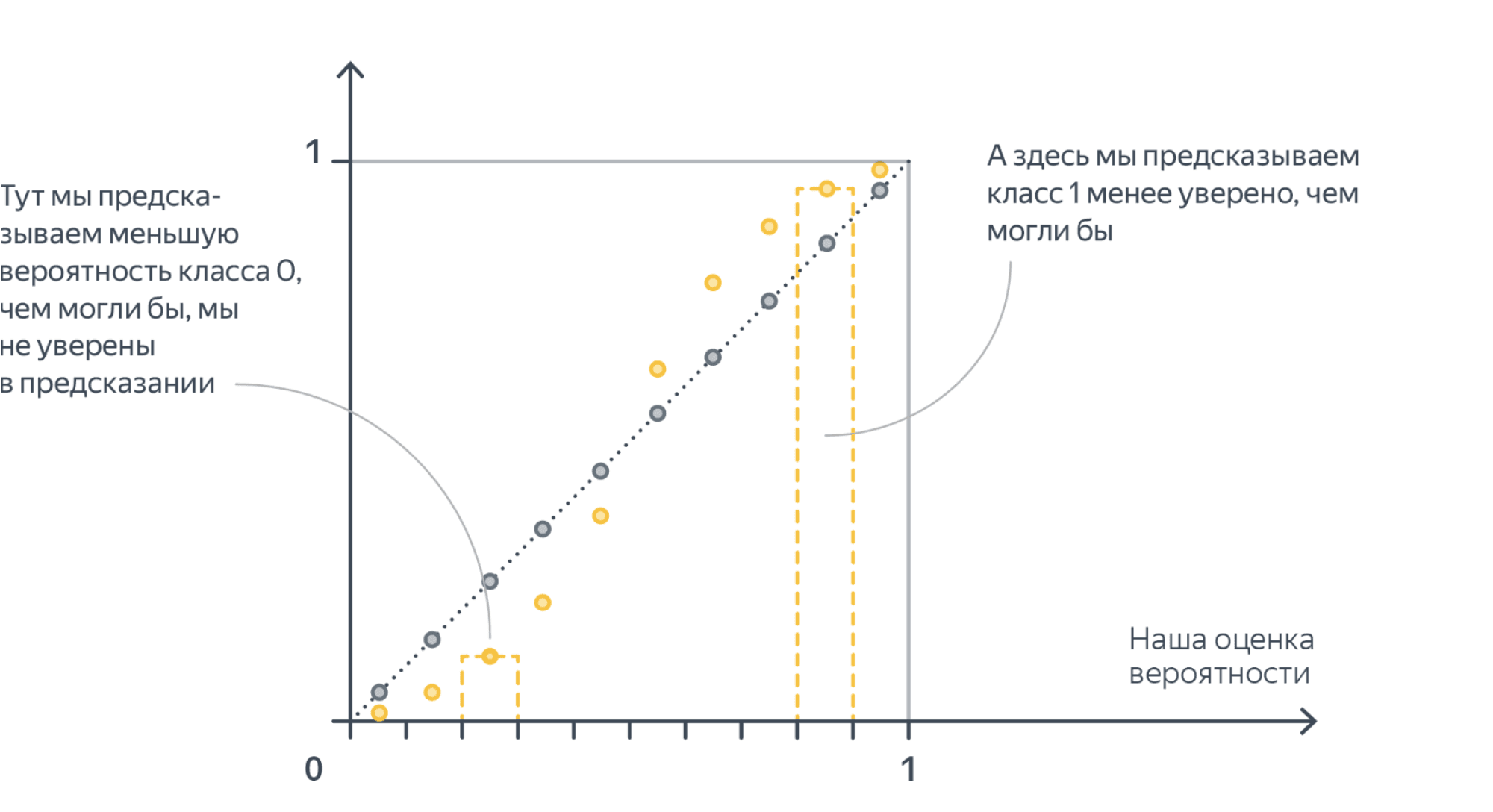
Такое может случиться, например, если мы слишком много обращаем внимания на трудные для классификации объекты на границе классов (как, скажем, в SVM), в каком-то смысле в ущерб более однозначно определяемым точкам. Этим же могут и грешить модели на основе бэггинга (например, случайный лес). Грубо говоря, среднее нескольких моделей предскажет что-то близкое к единице только если все слагаемые предскажут что-то, близкое к единице – но из-за дисперсии моделей это будет случаться реже, чем могло бы. См. статью.
Вам скажут: логистическая регрессия корректно действительно предсказывает вероятности
Вам даже будут приводить какие-то обоснования. Важно понимать, что происходит на самом деле, и не дать ввести себя в заблуждение. В качестве противоядия от иллюзий предлагаем рассмотреть два примера.
- Рассмотрим датасет c двумя классами (ниже на картинке обучающая выборка)
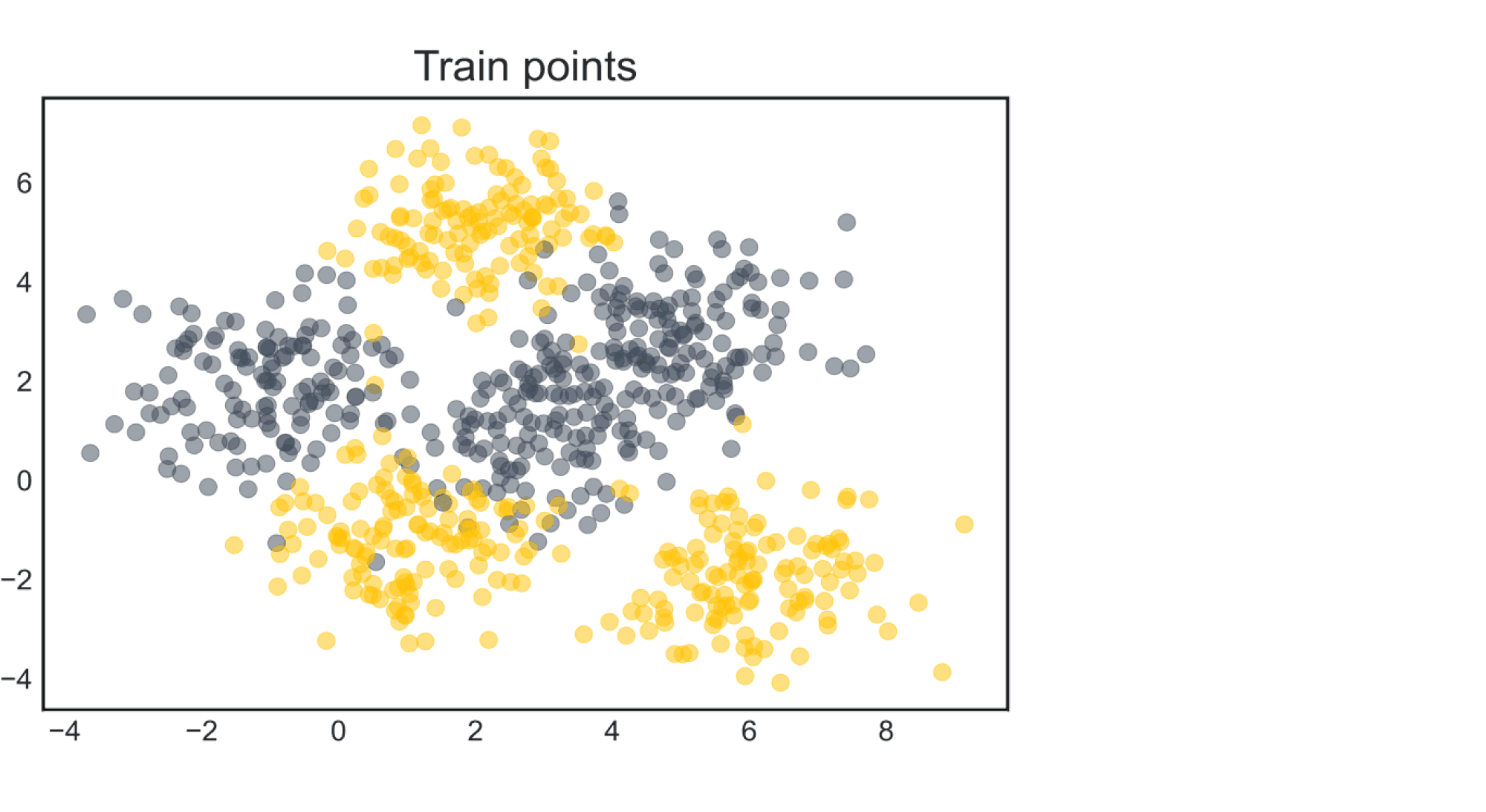
Обучим на нём логистическую регрессию из sklearn безо всяких параметров (то есть $L^2$-регуляризованную, но это не так важно). Классы не так-то просто разделить, вот и логистическая регрессия так себе справляется. Ниже изображена часть тестовой выборки вместе с предсказанными вероятностями классов для всех точек области
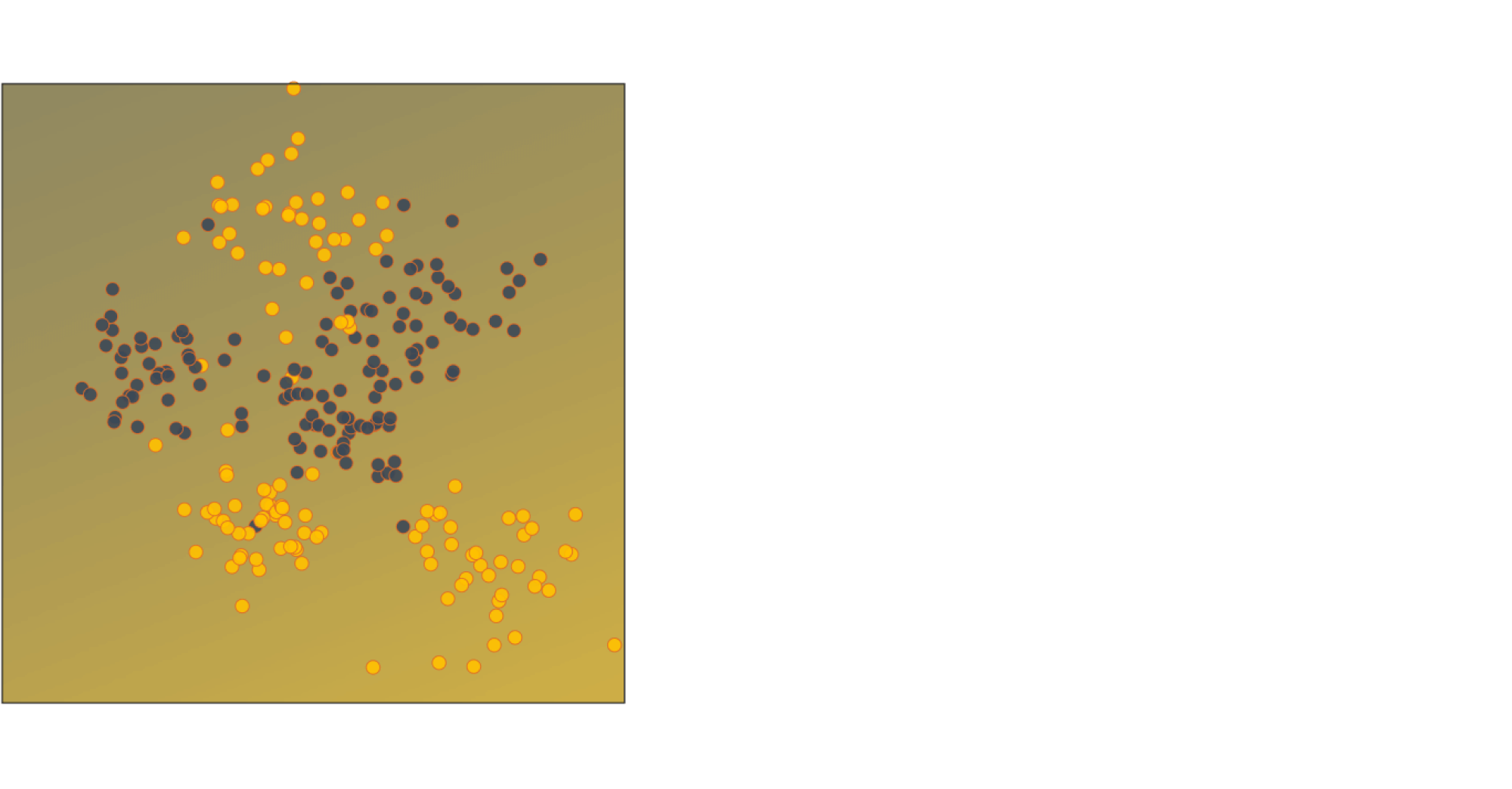
Видим, что модель не больно-то уверена в себе, и ясно почему: признаковое описание достаточно бедное и не позволяет нам хорошо разделить классы, хотя, казалось бы, это можно довольно неплохо сделать.
- Попробуем поправить дело, добавив полиномиальные фичи, то есть все $x^jy^k$ для $0leqslant j,kleqslant 5$ в качестве признаков, и обучив поверх этих данных логистическую регрессию. Снова нарисуем некоторые точки тестовой выборки и предсказания вероятностей для всех точек области:

Видим, что имеет место сочетание двух проблем: неуверенности посередине и очень уверенных ошибок по краям.
Нарисуем теперь калибровочные кривые для обеих моделей:
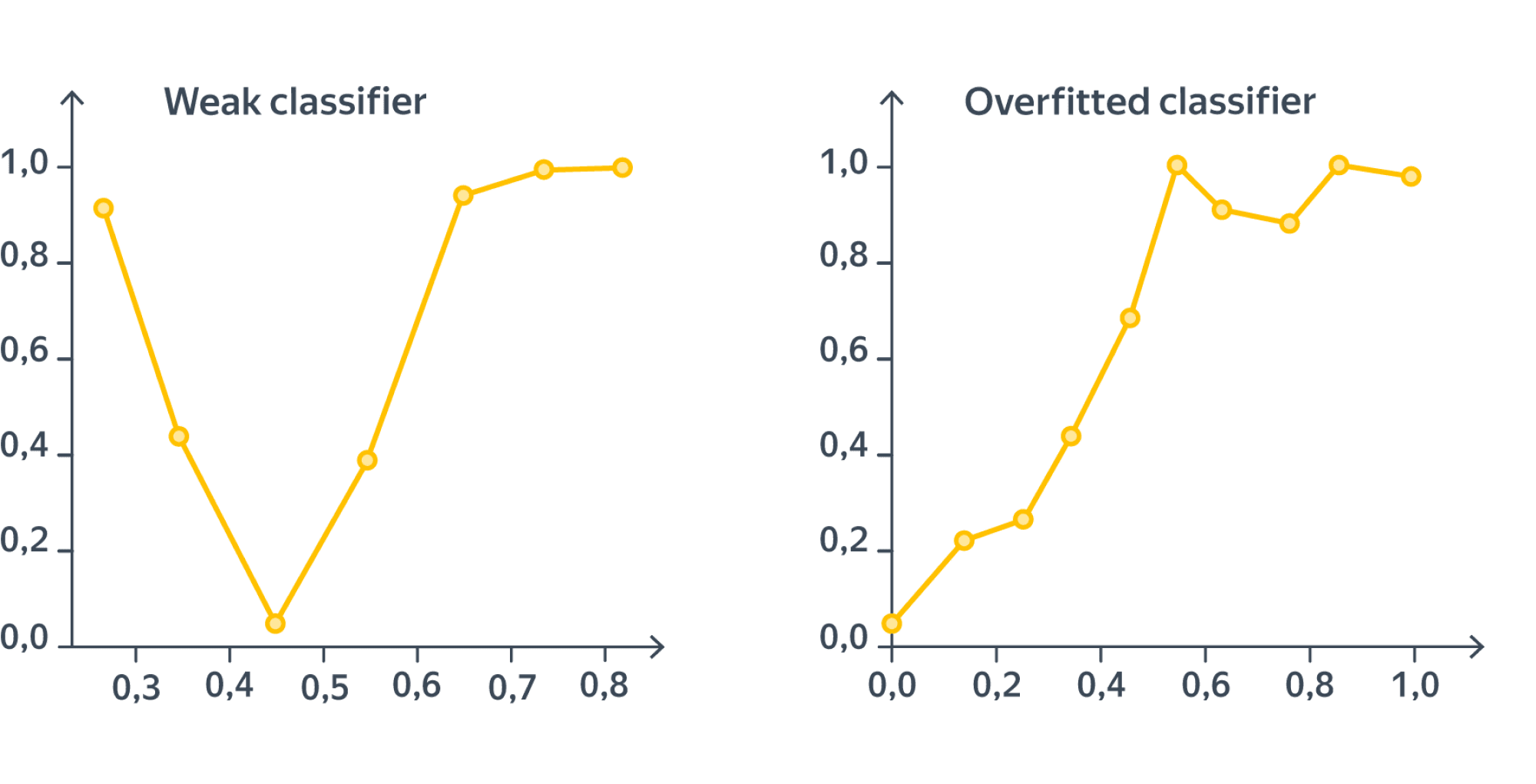
Калибровочные кривые весьма примечательны; в любом случае ясно, что с предсказанием вероятностей всё довольно плохо. Посмотрим ещё, какие вероятности наши классификаторы чаще приписывают объектам:
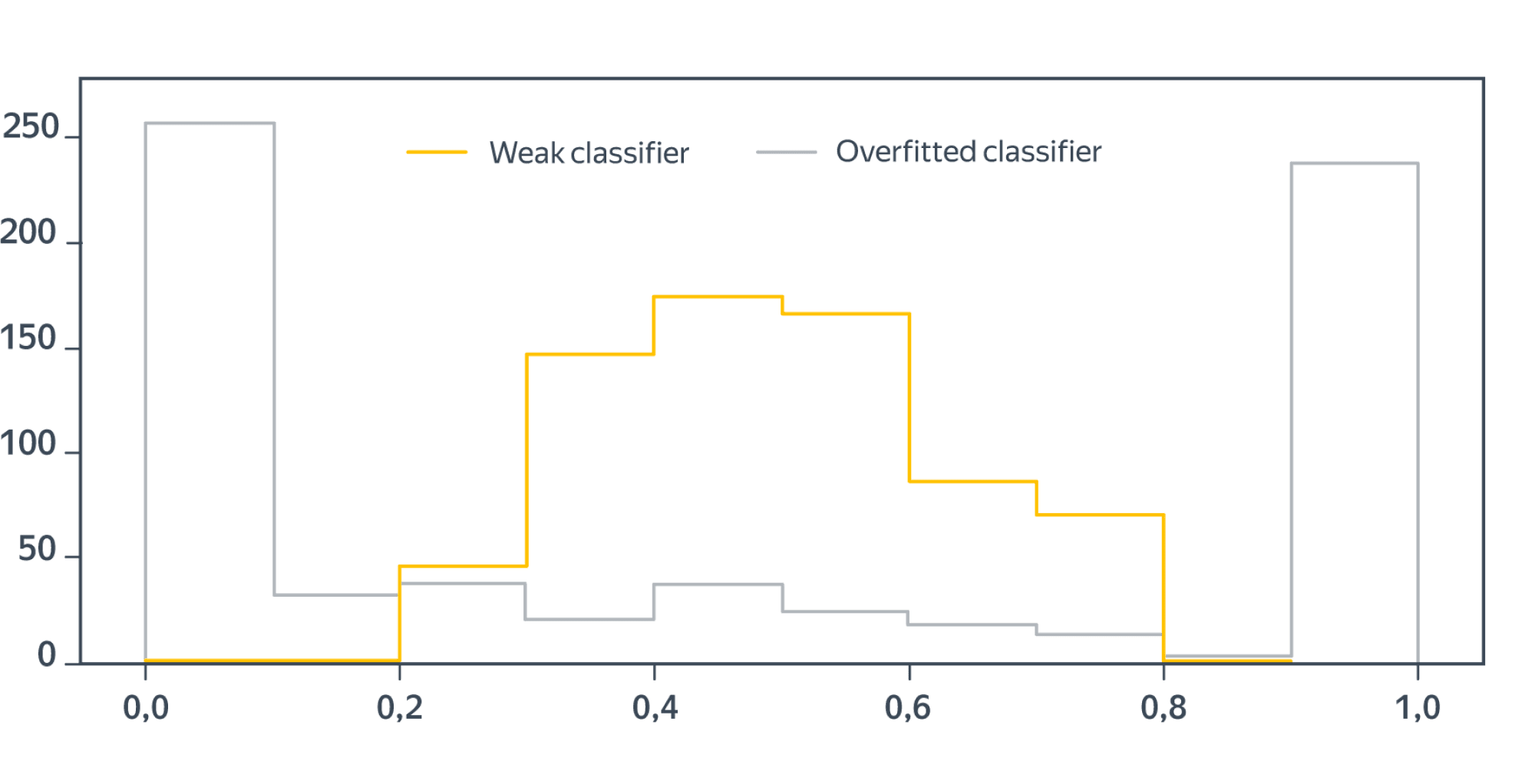
Как и следовало ожидать, предсказания слабого классификатора тяготеют к серединке (та самая неуверенность), а среди предсказаний переобученного очень много крайне уверенных (и совсем не всегда правильных).
Но почему же все твердят, что логистическая регрессия хорошо калибрована?!
Попробуем понять и простить её.
Как мы помним, логистическая регрессия учится путём минимизации функционала
$$l(X, y) = -sum_{i=1}^N(y_ilog(sigma(langle w, x_irangle)) + (1 — y_i)log(1 — sigma(langle w, x_irangle)))$$
Отметим между делом, что каждое слагаемое – это кроссэнтропия распределения $P$, заданного вероятностями $P(0) = 1 — sigma(langle w, x_irangle)$ и $P(1) = sigma(langle w, x_irangle)$, и тривиального распределения, которое равно $y_i$ с вероятностью $1$.
Допустим, что мы обучили по всему универсуму данных $mathbb{X}$ идеальную логистическую регрессию с идеальными весами $w^{ast}$. Пусть, далее, оказалось, что у нас есть $n$ объектов $x_1,ldots,x_n$ с одинаковым признаковым описанием (то есть по сути представленных одинаковыми векторами $x_i$), но, возможно, разными истинными метками классов $y_1,ldots,y_n$. Тогда соответствующий им кусок функции потерь имеет вид
$$-left(sum_{i=1}^ny_iright)log(sigma(langle w, x_1rangle)) -left(sum_{i=1}^n (1 — y_i)right)log(1 — sigma(langle w, x_1rangle)) =$$
$$=-nleft(vphantom{frac12}p_0log(sigma(langle w, x_1rangle)) + p_1log(1 — sigma(langle w, x_1rangle))right)$$
где $p_j$ – частота $j$-го класса среди истинных меток. В скобках также стоит кросс-энтропия распределения, задаваемого частотой меток истинных классов, и распределения, предсказываемого логистической регрессией. Минимальное значение кросс-энтропии (и минимум функции потерь) достигается, когда
$$sigma(langle w, x_1rangle) = p_0,quad 1 — sigma(langle w, x_1rangle) = p_1$$
Теперь, если признаковое описание данных достаточно хорошее (то есть классы не перемешаны как попало и всё-таки близки к разделимым) и в то же время модель не переобученная (то есть, в частности, предсказания вероятностей не скачут очень уж резко – вспомните второй пример), то результат, полученный для $n$ совпадающих точек будет приблизительно верным и для $n$ достаточно близких точек: на всех них модель будет выдавать примерно долю положительных, то есть тоже хорошую оценку вероятности.
Как же всё-таки предсказать вероятности: методы калибровки
Пусть наша модель (бинарной классификации) для каждого объекта $x_i$ выдаёт некоторое число $q(x_i)in[0,1]$. Как же эти числа превратить в корректные вероятности?
- Гистограммная калибровка. Мы разбиваем отрезок $[0,1]$ на бины $mathbb{B}_1,ldots,mathbb{B}_k$ (одинаковой ширины или равномощные) и хотим на каждом из них предсказывать всегда одну и ту же вероятность: $theta_j$, если $q(x_i)in mathbb{B}_j$. Вероятности $theta_i$ подбираются так, чтобы они как можно лучше приближали средние метки классов на соответствующих бинах; иными словами, мы решаем задачу
$$sum_{j=1}^kleft|frac{sum_{i=1}^Nmathbb{I}{q(x_i)inmathbb{B}_j}y_i}{ vert mathbb{B}_j vert } — theta_jright|longrightarrowminlimits_{(theta_1,ldots,theta_k)}$$
Вместо разности модулей можно рассматривать и разность квадратов.
Метод довольно простой и понятный, но требует подбора числа бинов и предсказывает лишь дискретное множество вероятностей.
**Изотоническая регрессия**. Этот метод похож на предыдущий, только мы будем, во-первых, настраивать и границы $0=b_0,b_1,ldots,b_k = 1$ бинов $mathbb{B}_j = {t vert b_{j-1}leqslant b_j}$, а кроме того, накладываем условие $theta_1leqslantldotsleqslanttheta_k$. Искать $b_j$ и $theta_j$ мы будем, приближая $y_i$ кусочно постоянной функцией $g$ от $q(x_i)$:
$$sum_{i=1}^N(y_i — g(q(x_i)))^2longrightarrowmin_{g}$$
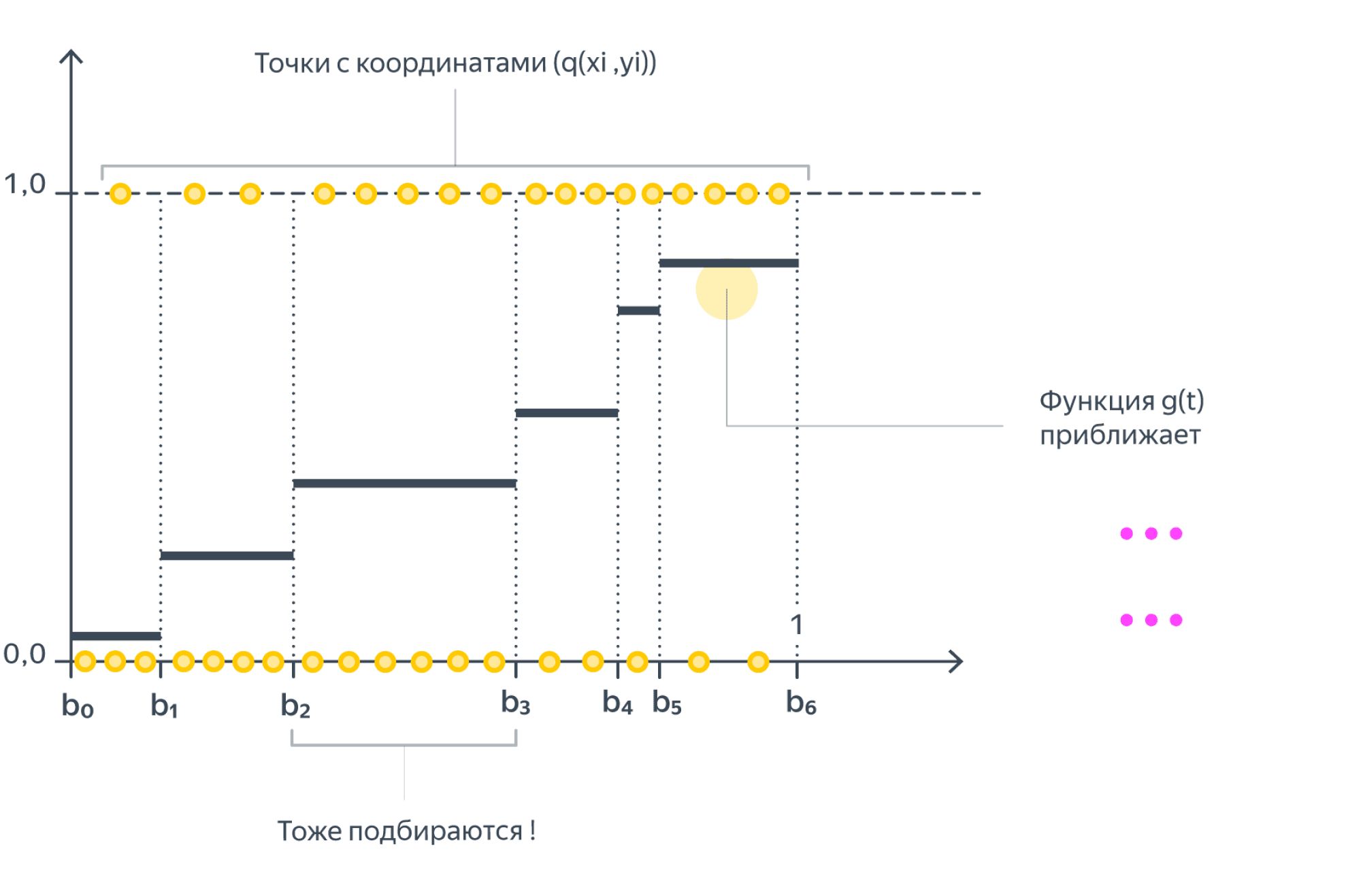
Минимизация осуществляется при помощи pool adjacent violators algorithm, и эти страницы слишком хрупки, чтобы выдержать его формулировку.
- Калибровка Платта представляет собой по сути применение сигмоиды поверх другой модели (то есть самый наивный способ получения »вероятностей»). Более точно, если $q(x_i)$ – предсказанная вероятность, то мы полагаем
$$P(y_i = 1mid x_i) = sigma(aq(x_i) + b) = frac1{1 + e^{-aq(x_i) — b}}$$
где $a$ и $b$ подбираются методом максимального правдоподобия на отложенной выборке:
$$-sum_{i=1}^N(vphantom{frac12}y_ilog(sigma(q(x_i))) + (1 — y_i)log(1 — sigma(q(x_i))))longrightarrowminlimits_{a,b}$$
Для избежания переобучения Платт предлагал также заменить метки $y_i$ и $(1 — y_i)$ на регуляризованные вероятности таргетов:
$$t_0 = frac1{#{i vert y_i = 0} + 2},quad t_1 = frac{#{i vert y_i = 1} + 1}{#{i vert y_i = 0} + 2}$$
Калибровка Платта неплохо справляется с выколачиванием вероятностей из SVM, но для более хитрых классификаторов может спасовать. В целом, можно показать, что этот метод хорошо работает, если для каждого из истинных классов предсказанные вероятности $q(x_i)$ распределы нормально с одинаковыми дисперсиями. Подробнее об этом вы можете почитать в этой статье. Там же описано обобщение данного подхода – бета-калибровка.
С большим количеством других методов калибровки вы можете познакомиться в этой статье
Как измерить качество калибровки
Калибровочные кривые хорошо показывают, что есть проблемы, но как оценить наши потуги по улучшению предсказания вероятностей? Хочется иметь какую-то численную метрику. Мы упомянем две разновидности, которые по сути являются прямым воплощением описанных выше идей.
- Expected/Maximum calibration error. Самый простой способ, впрочем, является наследником идеи с калибровочной кривой. А именно, разобьём отрезок $[0,1]$ на бины $mathbb{B}_1,ldots,mathbb{B}_k$ по предсказанным вероятностям и вычислим
$$sum_{j=1}^kfrac{#mathbb{B}_j}{N}left|overline{y}(mathbb{B}_j) — overline{q}(mathbb{B}_j)right|$$
или
$$maxlimits_{j=1,ldots,k}left|overline{y}(mathbb{B}_j) — overline{q}(mathbb{B}_j)right|$$
где $overline{y}(mathbb{B}_j)$ – среднее значение $y_i$, а $overline{q}(mathbb{B}_j)$ – среднее значение $q(x_i)$ для $x_i$, таких что $q(x_i)inmathbb{B}_j$. Проблема этого способа в том, что мы можем очень по-разному предсказывать в каждом из бинов вероятности (в том числе константой) без ущерба для метрики.
- Одна из популярных метрик – это Brier score, которая попросту измеряет разницу между предсказанными вероятностями и $ y_i $:
$$sum_{i=1}^N(y_i — q(x_i))^2$$
Казалось бы, в чём смысл? Немного подрастить мотивацию помогает следующий пример. Допустим, наши таргеты совершенно случайны, то есть $P(y_i = 1 vert x_i) = P(y_i)$. Тогда хорошо калиброванный классификатор должен для каждого $x_i$ предсказывать вероятность $frac12$; соответственно, его brier score равен $frac14$. Если же классификатор хоть в одной точке выдаёт вероятность $p>frac12$, то в маленькой окрестности он должен выдавать примерно такие же вероятности; поскольку же таргет случаен, локальный кусочек суммы из brier score будет иметь вид $frac{N’}{2}p^2 + frac{N’}{2}(1-p)^2 < frac{N’}2$, что хуже, чем получил бы всегда выдающий $frac12$ классификатор.
Не обязательно брать квадратичную ошибку; сгодится и наш любимый log-loss:
$$sum_{i=1}^Nleft(vphantom{frac12}y_ilog{q(x_i)} + (1 — y_i)log(1 — q(x_i))right)$$
Это же и помогает высветить ограничения подхода, если вспомнить рассуждения о калиброванности логистической регрессии. Для достаточно гладких классификатора и датасета briar score и log-loss будут адекватными средствами оценки, но если нет – возможно всякое.
Вопрос на засыпку: а как быть, если у нас классификация не бинарная, а многоклассовая? Что такое хорошо калиброванный классификатор? Как это определить численно? Как заставить произвольный классификатор предсказывать вероятности?
Мы не будем про это рассказывать, но призываем читателя подумать над этим самостоятельно или, например, посмотреть туториал с ECML KDD 2020.
Пусть
производятся независимые испытания с
неизвестной вероятностью p
появления события A
в каждом испытании. Требуется оценить
неизвестную вероятность p
по относительной частоте, т. е. надо
найти ее точечную и интервальную оценки.
Точечная
оценка.
В качестве точечной оценки неизвестной
вероятности p
принимают относительную частоту:
W
= т/п,
где
т—число
появлений события
A,
п—число
испытаний.
Эта
оценка несмещенная, т. е. ее математическое
ожидание
равно оцениваемой вероятности.
Действительно, учитывая, что
М (т)= пр,
получим:
M
(W)
=
M
[m/п]
= М (т)/п = пр/п = р.
Найдем
дисперсию
оценки,
приняв во внимание, что D(m)=
npq:
D
(W)
=
D
[т/п] = D
(т)/п2
= npq/n2
= pq/n,
тогда
среднее
квадратическое отклонение
находим по формуле:
σ=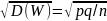
Интервальная
оценка.
Найдем доверительный интервал для
оценки вероятности по относительной
частоте.
Формула,
позволяющая найти вероятность того,
что абсолютная величина отклонения
не превысит
положительного
числа б:
Р
(|Х —а | <
б) = 2Ф (б/а)
(*),
где
X
—нормальная
случайная
величина с математическим ожиданием
М (Х) = а.
Если
п
достаточно велико и вероятность р
не очень близка к нулю и к единице, то
можно считать M(W)
= p.
Таким
образом, заменив в соотношении (*)
случайную величину
X
и ее математическое ожидание
а
соответственно случайной величиной
W
и ее математическим ожиданием
р,
получим приближенное равенство
P
(| W—р
| <
б) = Ф(б/σ).
Построим
доверительный интервал с надежностью
γ:
P
(| W—р
| <
б) = Ф(б/σ) = γ
Заменим
σ
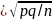
,
Тогда
P
(| W—р
| <
б) = Ф(б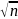
/
)
= Ф(t)
= γ,
Где
t
= б
/
),
откуда б = t
/
Заменим
в неравенстве случайную величину W
на неслучайную наблюдаемую относительную
частоту ω и заменим q=1-p,
подставим
выражение для б, получим:
|ω
— p|
< t
/
,
раскрываем модуль, оценивая ω<
p
и ω>p
получим p1
и p2
— промежутки для доверительного
интервала.
Доверительный
интервал.
Θ
– Исследуемый параметр, Θ
* — статистическая характеристика
исследуемого параметра
|
Θ
— Θ
*|<б – точность оценки
P
(|Θ-Θ*|<б)
= γ
– точность( доверительная вероятность)
Доверительным
называют интервал (Θ*
— б; Θ*
+ б), который покрывает неизвестный
параметр с заданной надежностью.
60. Оценка параметров в статистике
Пусть
нам нужно изучить к-либо признак
генеральной совокупности и мы теоретически
знаем его тип распределения.
Обычно
имеем: данные выборки (например, значения
признака x1,x2,xn
в результате n
независимых испытаний).

61. Дисперсионный анализ. Однофакторный комплекс.

Основная
идея: сравнения «факторной» дисперсии
и «остаточной» (вызванная в результате
случайных причин).

62. Корреляционный анализ. Регрессия.
Корреляционный
анализ — метод, позволяющий обнаружить
зависимость между несколькими с.в.
Допустим,
проводится независимое измерение
различных параметров у одного типа
объектов. Из этих данных можно получить
качественно новую информацию — о
взаимосвязи этих параметров.
Н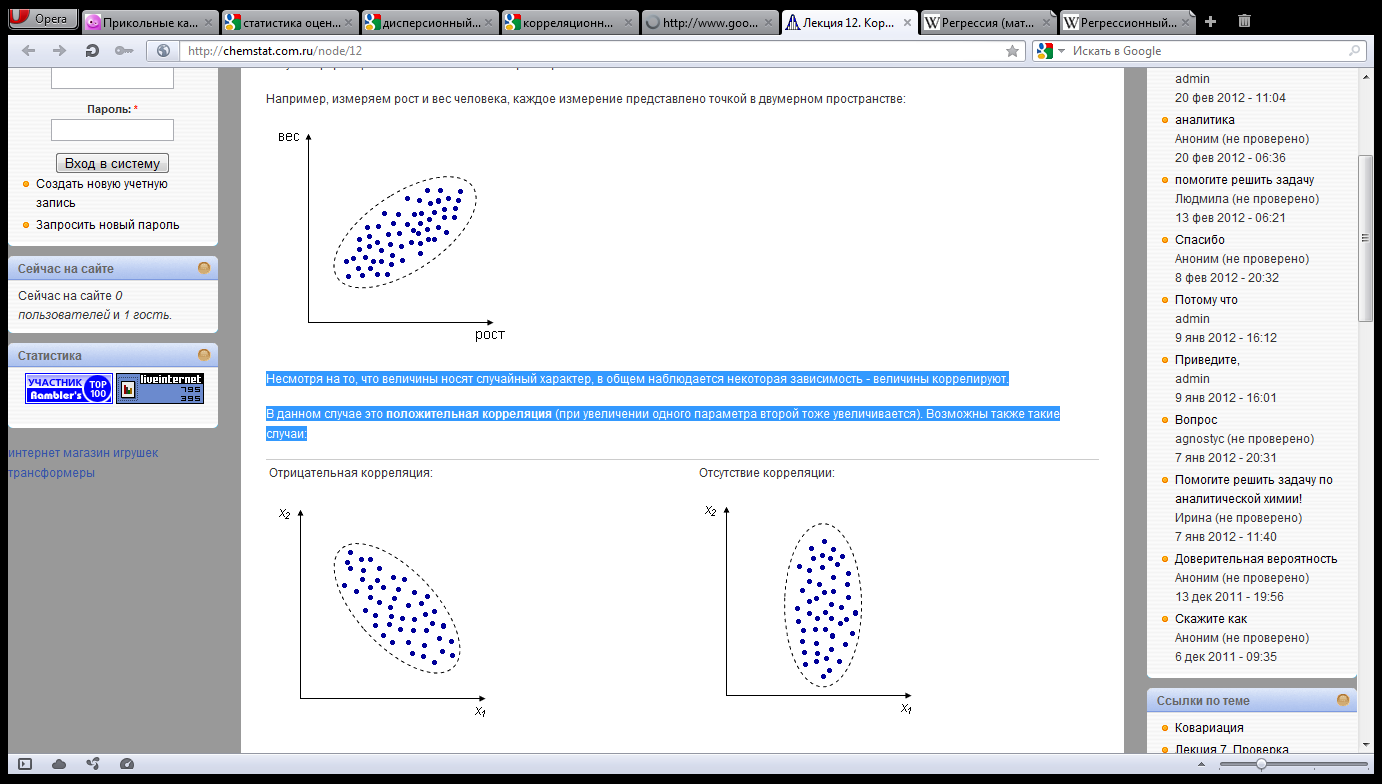
апример,
измеряем рост и вес человека, каждое
измерение представлено точкой в двумерном
пространстве:
Н
есмотря
на то, что величины носят случайный
характер, в общем наблюдается некоторая
зависимость — величины коррелируют.
В
данном случае это положительная
корреляция (при увеличении одного
параметра второй тоже увеличивается).
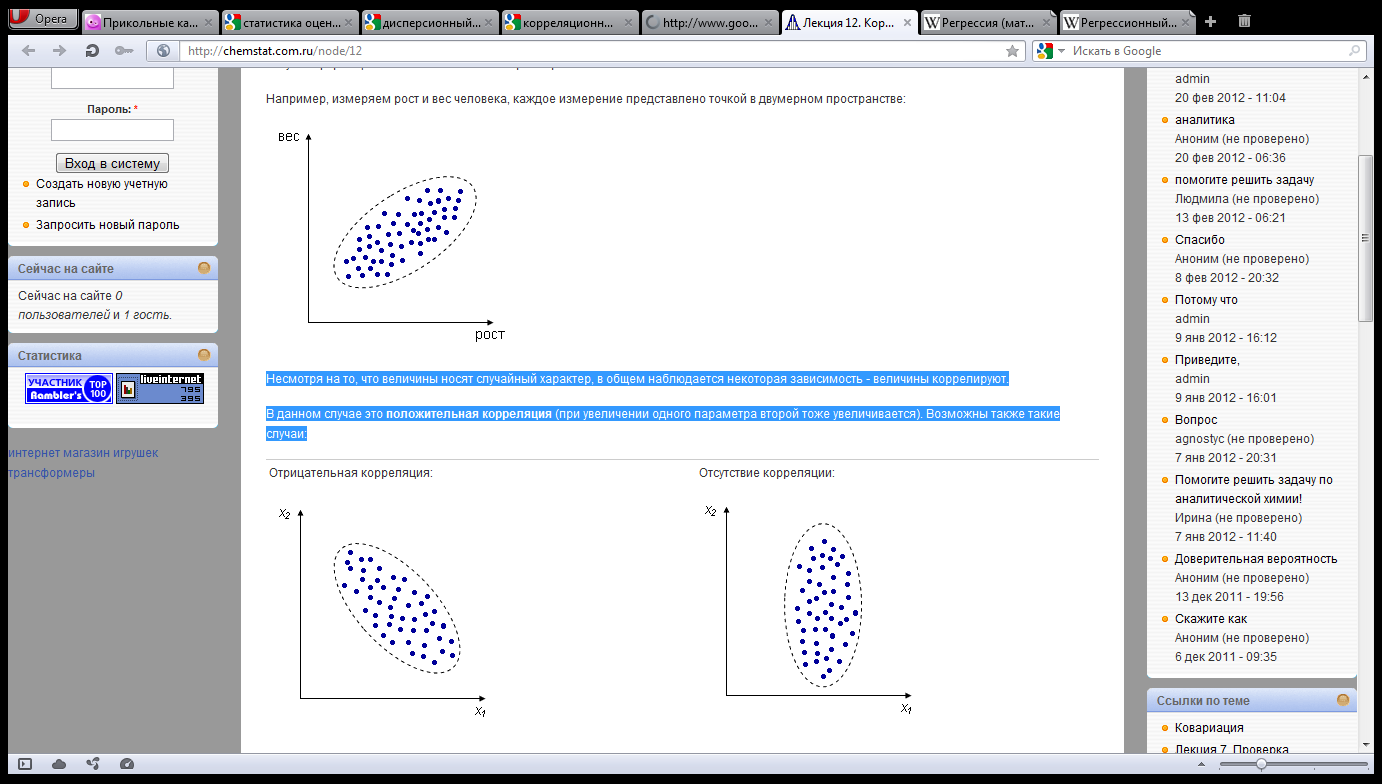
Возможны
также такие случаи:
Регре́ссия
— зависимость среднего значения к-либо
величины от некоторой другой величины
или от нескольких величин. В отличие от
чисто функциональной зависимости
y=f(x), при регрессионной связи одному и
тому же значению x могут соответствовать
в зависимости от случая различные
значения величины y. Если при каждом
значении x=xi
наблюдается
ni
значений yi1…yin1
величины y, то зависимость средних
арифметических
![]()
и
является регрессией.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Так же как и теория вероятностей, математическая статистика имеет свои ключевые понятия, к которым относятся: генеральная совокупность, теоретическая функция распределения, выборка, эмпирическая функция распределения, статистика. Именно с определения этих понятий, а также с установления связи между ними и объектами, изучаемыми в теории вероятностей, мы начнем изложение математической статистики, предварительно дав краткое описание задач, которые собираемся решать. Кроме того, в последнем параграфе главы остановимся на некоторых распределениях, наиболее часто встречающихся в математической статистике.
Задачи математической статистики
Математическая статистика, являясь частью общей прикладной математической дисциплины «Теория вероятностей и математическая статистика», изучает, как и теория вероятностей, случайные явления, использует одинаковые с ней определения, понятия и методы и основана на той же самой аксиоматике А.Н. Колмогорова.
Однако задачи, решаемые математической статистикой, носят специфический характер. Теория вероятностей исследует явления, заданные полностью их моделью, и выявляет еще до опыта те статистические закономерности, которые будут иметь место после его проведения. В математической статистике вероятностная модель явления определена с точностью до неизвестных параметров. Отсутствие сведений о параметрах компенсируется тем, что нам позволено проводить «пробные» испытания и на их основе восстанавливать недостающую информацию.
Попытаемся показать различие этих двух взаимосвязанных дисциплин на простейшем примере — последовательности независимых одинаковых испытаний, или схеме Бернулли (часть 1, гл.4). Схему Бернулли можно трактовать как подбрасывание несимметричной монеты с вероятностью выпадения «герба» (успеха) р и «цифры» (неудачи) 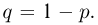 В теории вероятностей р и q задаются «извне» (например, для симметричной монеты
В теории вероятностей р и q задаются «извне» (например, для симметричной монеты 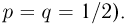 Методы теории вероятностей позволяют, зная р и q, определить вероятность выпадения т «гербов» при п подбрасываниях монеты (биномиальное распределение, часть 1, гл.4, параграф 1), найти асимптотику этой вероятности при увеличении числа подбрасываний (теоремы Пуассона и Муавра-Лапласа,
Методы теории вероятностей позволяют, зная р и q, определить вероятность выпадения т «гербов» при п подбрасываниях монеты (биномиальное распределение, часть 1, гл.4, параграф 1), найти асимптотику этой вероятности при увеличении числа подбрасываний (теоремы Пуассона и Муавра-Лапласа,
часть 1, гл.4, параграфы 2-4) и т.д. В математической статистике значения р и q неизвестны заранее, но мы можем произвести серию подбрасываний монеты. Цель проведения испытаний как раз и заключается либо в определении р и q, либо в проверке некоторых априорных суждений относительно их значений. Таким образом, судя уже по этому простейшему примеру, задачи математической статистики являются в некотором смысле обратными задачам теории вероятностей.
В математической статистике обычно принято выделять два основных направления исследований.
Первое направление связано с оценкой неизвестных параметров. Возвращаясь к нашему примеру, предположим, что мы произвели п подбрасываний монеты и установили, что в 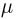 из них выпал «герб». Тогда наиболее естественной оценкой вероятности р является наблюденная частота
из них выпал «герб». Тогда наиболее естественной оценкой вероятности р является наблюденная частота 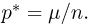 Как известно из закона больших чисел Бернулли (часть 1, гл. 4, параграф 5), с увеличением числа испытаний частота
Как известно из закона больших чисел Бернулли (часть 1, гл. 4, параграф 5), с увеличением числа испытаний частота 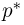 стремится к вероятности р, т. е. является состоятельной оценкой вероятности р. Оказывается, наряду с простотой и естественностью оценка будет и наилучшей с многих точек зрения, т. е. она обладает свойством эффективности. Однако если нам заранее определено число п подбрасываний монеты, то сказать со 100%-й гарантией что-либо об истинном значении р мы не можем (за исключением разве что тривиальных суждений типа «если выпадет хотя бы один „герб» то вероятность выпадения „герба» не может равняться нулю»). Поэтому наряду с точечными оценками в математической статистике принято определять интервальные оценки или, иными словами, доверительные интервалы, опираясь при этом на «уровень доверия», или доверительную вероятность.
стремится к вероятности р, т. е. является состоятельной оценкой вероятности р. Оказывается, наряду с простотой и естественностью оценка будет и наилучшей с многих точек зрения, т. е. она обладает свойством эффективности. Однако если нам заранее определено число п подбрасываний монеты, то сказать со 100%-й гарантией что-либо об истинном значении р мы не можем (за исключением разве что тривиальных суждений типа «если выпадет хотя бы один „герб» то вероятность выпадения „герба» не может равняться нулю»). Поэтому наряду с точечными оценками в математической статистике принято определять интервальные оценки или, иными словами, доверительные интервалы, опираясь при этом на «уровень доверия», или доверительную вероятность.
Второе направление в математической статистике связано с проверкой некоторых априорных предположений, или статистических гипотез. Так, до опыта мы можем предположить, что монета симметрична, т.е. высказать гипотезу о равенстве 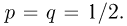 Противоположное предположение, естественно, будет состоять в том, что
Противоположное предположение, естественно, будет состоять в том, что 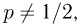 и тоже представляет собой гипотезу. Принято называть одну из этих гипотез (как правило, более важную с практической точки зрения) основной
и тоже представляет собой гипотезу. Принято называть одну из этих гипотез (как правило, более важную с практической точки зрения) основной 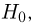 а вторую — альтернативной или конкурирующей
а вторую — альтернативной или конкурирующей 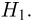 В приведенном выше примере нужно проверить основную гипотезу
В приведенном выше примере нужно проверить основную гипотезу 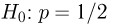 против конкурирующей гипотезы
против конкурирующей гипотезы 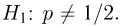 Заметим, что в нашем случае основная гипотеза полностью определяет вероятностную модель подбрасывания монеты, т.е. является простой (состоит из одной точки), в отличие от конкурирующей гипотезы являющейся сложной (состоит из более чем одной точки). Задача проверки статистических гипотез состоит в выборе правила или критерия, позволяющего по результатам наблюдений проверить (по возможности, наилучшим образом) справедливость этих гипотез и принять одну из них. Так же, как и при оценке неизвестных параметров, мы не застрахованы от неверного решения; в математической статистике они подразделяются
Заметим, что в нашем случае основная гипотеза полностью определяет вероятностную модель подбрасывания монеты, т.е. является простой (состоит из одной точки), в отличие от конкурирующей гипотезы являющейся сложной (состоит из более чем одной точки). Задача проверки статистических гипотез состоит в выборе правила или критерия, позволяющего по результатам наблюдений проверить (по возможности, наилучшим образом) справедливость этих гипотез и принять одну из них. Так же, как и при оценке неизвестных параметров, мы не застрахованы от неверного решения; в математической статистике они подразделяются
на ошибки первого и второго рода. Ошибка первого рода состоит в том, что мы принимаем конкурирующую гипотезу 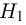 в то время как справедлива основная гипотеза
в то время как справедлива основная гипотеза 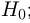 аналогично определяется ошибка второго рода. Возвращаясь к примеру с монетой, приведем следующий критерий проверки двух перечисленных гипотез: основную гипотезу
аналогично определяется ошибка второго рода. Возвращаясь к примеру с монетой, приведем следующий критерий проверки двух перечисленных гипотез: основную гипотезу 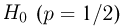 будем принимать в том случае, если наблюденная частота удовлетворяет неравенству
будем принимать в том случае, если наблюденная частота удовлетворяет неравенству 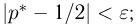 в противном случае считаем верной конкурирующую гипотезу
в противном случае считаем верной конкурирующую гипотезу 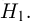 Вероятность ошибки первого рода (принять симметричную монету за несимметричную) в этом случае определяется как вероятность выполнения неравенства
Вероятность ошибки первого рода (принять симметричную монету за несимметричную) в этом случае определяется как вероятность выполнения неравенства 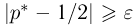 в схеме Бернулли с равновероятными исходами. Вероятность ошибки второго рода (принять несимметричную монету за симметричную) также определяется из схемы Бернулли, но с неравновероятными исходами и будет зависеть от истинного значения р.
в схеме Бернулли с равновероятными исходами. Вероятность ошибки второго рода (принять несимметричную монету за симметричную) также определяется из схемы Бернулли, но с неравновероятными исходами и будет зависеть от истинного значения р.
Далее мы увидим, что задача проверки статистических гипотез наиболее полно решается для случая двух простых гипотез. Можно поставить и задачу проверки нескольких гипотез (в примере с монетой можно взять, например, три гипотезы: 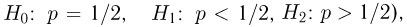 однако мы такие задачи рассматривать не будем.
однако мы такие задачи рассматривать не будем.
Условно математическую статистику можно подразделить на исследование байесовских и небайесовских моделей.
Байесовские модели возникают тогда, когда неизвестный параметр является случайной величиной и имеется априорная информация о его распределении. При байесовском подходе на основе опытных данных априорные вероятности пересчитываются в апостериорные. Применение байесовского подхода фактически сводится к использованию формулы Байеса (см. часть 1, гл. 3, параграф 5), откуда, собственно говоря, и пошло его название. Байесовский подход нами будет применяться только как вспомогательный аппарат при доказательстве некоторых теорем.
Небайесовские модели появляются тогда, когда неизвестный параметр нельзя считать случайной величиной и все статистические выводы приходится делать, опираясь только на результаты «пробных» испытаний. Именно такие модели мы будем рассматривать в дальнейшем изложении.
В заключение этого параграфа отметим, что в математической статистике употребляют также понятия параметрических и непараметрических моделей. Параметрические модели возникают тогда, когда нам известна с точностью до параметра (скалярного или векторного) функция распределения наблюдаемой характеристики и необходимо по результатам испытаний определить этот параметр (задача оценки неизвестного параметра) или проверить гипотезу о принадлежности его некоторому заранее выделенному множеству значений (задача проверки статистических гипотез). Все приведенные выше примеры с подбрасыванием монеты представляют собой параметрические модели. Примеры непараметрических моделей мы рассмотрим позже.
Основные понятия математической статистики
Основными понятиями математической статистики являются: генеральная совокупность, выборка, теоретическая функция распределения.
Генеральная совокупность. Будем предполагать, что у нас имеются N объектов, каждому из которых присуще определенное значение некоторой числовой характеристики X. Характеристика X, вообще говоря, может быть и векторной (например, линейные размеры объекта), однако для простоты изложения мы ограничимся только скалярным случаем, тем более что переход к векторному случаю никаких трудностей не вызывает. Совокупность этих N объектов назовем генеральной совокупностиью.
Поскольку все наши статистические выводы мы будем делать, основываясь только на значениях числовой характеристики X, естественно абстрагироваться от физической природы самих объектов и отождествить каждый объект с присущей ему характеристикой X. Таким образом, с точки зрения математической статистики генеральная совокупность представляет собой N чисел, среди которых, конечно, могут быть и одинаковые.
Выборка. Для того чтобы установить параметры генеральной совокупности, нам позволено произвести некоторое число п испытаний. Каждое испытание состоит в том, что мы случайным образом выбираем один объект генеральной совокупности и определяем его значение X. Полученный таким образом ряд чисел  будем называть (случайной) выборкой объема п, а число
будем называть (случайной) выборкой объема п, а число  элементом выборки.
элементом выборки.
Заметим, что сам процесс выбора можно осуществлять различными способами: выбрав объект и определив его значение, изымать этот объект и не допускать к последующим испытаниям (выборка без возвращения); после определения его значения объект возвращается в генеральную совокупность и может полноправно участвовать в дальнейших испытаниях (выборка с возвращением) и т.д.
Разумеется, если бы мы смогли провести сплошное обследование всех объектов генеральной совокупности, то не нужно было бы применять никакие статистические методы и саму математическую статистику можно было бы отнести к чисто теоретическим наукам. Однако такой полный контроль невозможен по следующим причинам. Во-первых, часто испытание сопровождается разрушением испытуемого объекта; в этом случае мы имеем выборку без возвращения. Во-вторых, обычно необходимо исследовать весьма большое количество объектов, что просто невозможно физически. Наконец, может возникнуть такое положение, когда многократно измеряется один и тот же объект, но каждый замер производится со случайной ошибкой, и цель последующей статистической обработки заключается именно в уточнении характеристик объекта на основе многократных наблюдений; при этом результат каждого наблюдения надо считать новым объектом генеральной совокупности (простейшим примером такой ситуации является многократное подбрасывание монеты с целью определения вероятности выпадения «герба»). Следует помнить также, что выборка обязательно должна удовлетворять условию репрезентативности или, говоря более простым языком, давать обоснованное представление о генеральной совокупности.
С ростом объема N генеральной совокупности исчезает различие между выборками с возвращением и без возвращения. Мы, как обычно это делается в математической статистике, будем рассматривать случай бесконечно большого объема генеральной совокупности и поэтому, употребляя слово «выборка», не будем указывать, какая она — с возвращением или без него.
Теоретическая функция распределения. Пусть 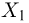 — выборка единичного объема из заданной генеральной совокупности. Поскольку сам процесс выбора производится случайным образом, то является случайной величиной и, как и всякая случайная величина, имеет функцию распределения
— выборка единичного объема из заданной генеральной совокупности. Поскольку сам процесс выбора производится случайным образом, то является случайной величиной и, как и всякая случайная величина, имеет функцию распределения 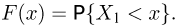 Нетрудно видеть, что если объем N генеральной совокупности конечен, то при случайном выборе объекта мы находимся в рамках схемы классической вероятности (часть 1, гл.2, параграф 1) и значение функции распределения F(x) совпадает с отношением
Нетрудно видеть, что если объем N генеральной совокупности конечен, то при случайном выборе объекта мы находимся в рамках схемы классической вероятности (часть 1, гл.2, параграф 1) и значение функции распределения F(x) совпадает с отношением 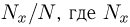 — число тех объектов генеральной совокупности, значения которых меньше х.
— число тех объектов генеральной совокупности, значения которых меньше х.
В случае выборки  произвольного объема п каждый элемент
произвольного объема п каждый элемент 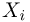 выборки также будет иметь функцию распределения F(x), причем для выборки с возвращением наблюдения
выборки также будет иметь функцию распределения F(x), причем для выборки с возвращением наблюдения  будут независимы между собой (чего нельзя сказать о выборке без возвращения). Поскольку, как уже говорилось, мы будем рассматривать выборки из генеральной совокупности бесконечно большого объема, а в этом случае исчезает различие между выборками разного типа, мы приходим к интерпретации (с точки зрения теории вероятностей) выборки как п независимых одинаково распределенных с функцией распределения F(x) случайных величин или, допуская некоторую вольность речи, как п независимых реализаций наблюдаемой случайной величины X, имеющей функцию распределения F(x). Функция распределения F(x) называется теоретической функцией распределения. Однако теоретическая функция распределения F(x) либо неизвестна, либо известна не полностью, и именно относительно F(x) мы будем делать наши статистические выводы. Заметим, что в соответствии с общими положениями теории вероятностей совместная функция распределения
будут независимы между собой (чего нельзя сказать о выборке без возвращения). Поскольку, как уже говорилось, мы будем рассматривать выборки из генеральной совокупности бесконечно большого объема, а в этом случае исчезает различие между выборками разного типа, мы приходим к интерпретации (с точки зрения теории вероятностей) выборки как п независимых одинаково распределенных с функцией распределения F(x) случайных величин или, допуская некоторую вольность речи, как п независимых реализаций наблюдаемой случайной величины X, имеющей функцию распределения F(x). Функция распределения F(x) называется теоретической функцией распределения. Однако теоретическая функция распределения F(x) либо неизвестна, либо известна не полностью, и именно относительно F(x) мы будем делать наши статистические выводы. Заметим, что в соответствии с общими положениями теории вероятностей совместная функция распределения 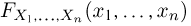 выборки задается формулой
выборки задается формулой
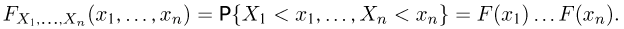
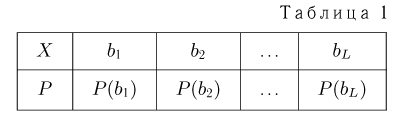
В дальнейшем, как правило, мы будем предполагать, что F(x) является функцией распределения либо дискретной, либо непрерывной наблюдаемой случайной величины X. В первом случае будем оперировать рядом распределения случайной величины X, записанным в виде табл. 1, а во втором — плотностью распределения 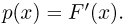
Простейшие статистические преобразования
Прежде чем переходить к детальному анализу наблюденных статистических данных, обычно проводят их предварительную обработку. Иногда результаты такой обработки уже сами по себе дают наглядную картину исследуемого явления, в большинстве же случаев они служат исходным материалом для получения более подробных статистических выводов.
Вариационный и статистический ряды. Часто бывает удобно пользоваться не самой выборкой 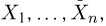 а некоторой ее модификацией, называемой вариационным рядом. Вариационный ряд
а некоторой ее модификацией, называемой вариационным рядом. Вариационный ряд 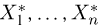 представляет собой ту же самую выборку но расположенную в порядке возрастания элементов:
представляет собой ту же самую выборку но расположенную в порядке возрастания элементов: 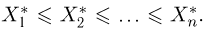 Такое преобразование не приводит к потере информации относительно теоретической функции распределения F(x), поскольку, переставив элементы вариационного ряда
Такое преобразование не приводит к потере информации относительно теоретической функции распределения F(x), поскольку, переставив элементы вариационного ряда  в случайном порядке, мы получим новый набор случайных величин
в случайном порядке, мы получим новый набор случайных величин 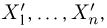 совместная функция распределения
совместная функция распределения 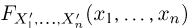 которых в точности совпадает с функцией распределения
которых в точности совпадает с функцией распределения 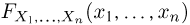 первоначальной выборки
первоначальной выборки 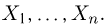
Для 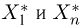 употребляют название «крайние члены вариационного ряда».
употребляют название «крайние члены вариационного ряда».
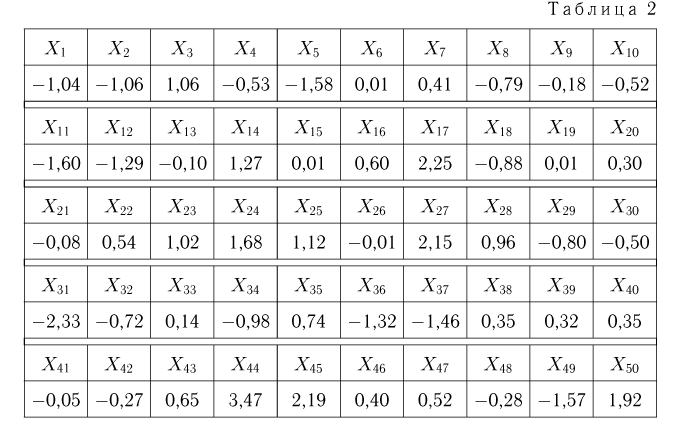
Пример 1. Измерение проекции вектора скорости молекул водорода на одну из осей координат дало (с учетом направления вектора) результаты 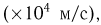 представленные в табл.2.
представленные в табл.2.
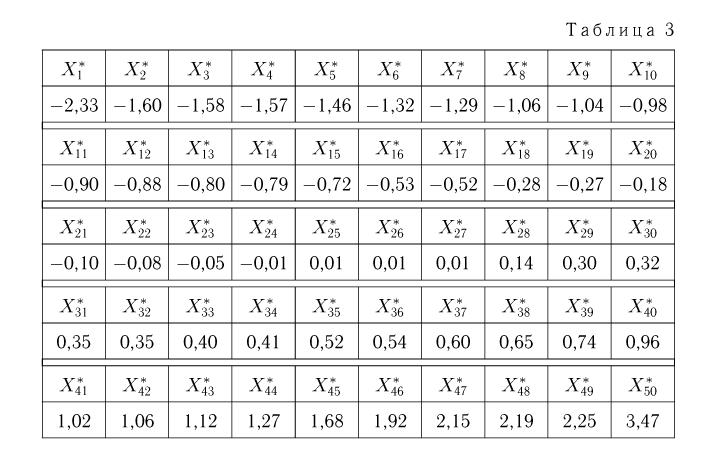
Вариационный ряд этой выборки приведен в табл. 3. Крайними членами вариационного ряда 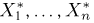 являются
являются 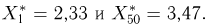
Если среди элементов выборки (а значит, и среди элементов вариационного ряда  имеются одинаковые, что происходит при наблюдении дискретной случайной величины, а также довольно часто встречается при наблюдении непрерывной случайной величины с округлением значений, то наряду с вариационным рядом используют представление выборки в виде статистического
имеются одинаковые, что происходит при наблюдении дискретной случайной величины, а также довольно часто встречается при наблюдении непрерывной случайной величины с округлением значений, то наряду с вариационным рядом используют представление выборки в виде статистического
ряда (табл.4), в котором  представляют собой расположенные в порядке возрастания различные значения элементов выборки
представляют собой расположенные в порядке возрастания различные значения элементов выборки  — числа элементов выборки, значения которых равны соответственно
— числа элементов выборки, значения которых равны соответственно 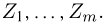
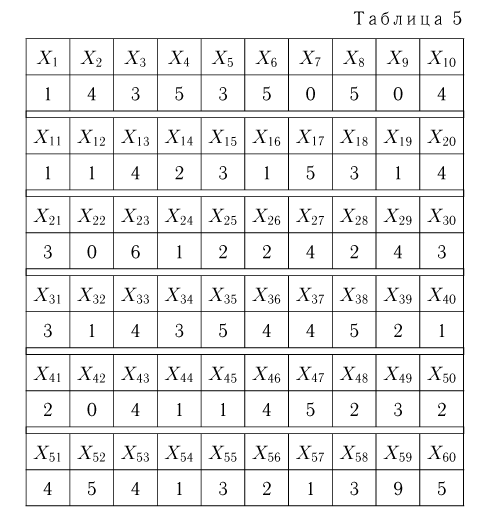
Пример 2. В течение минуты каждую секунду регистрировалось число попавших в счетчик Гейгера частиц. Результаты наблюдений приведены в табл. 5.
Статистический ряд выборки представлен в табл. 6.

Статистики. Для получения обоснованных статистических выводов необходимо проводить достаточно большое число испытаний, т.е. иметь выборку достаточно большого объема п. Ясно, что не только использование такой выборки, но и хранение ее весьма затруднительно. Чтобы избавиться от этих трудностей, а также для других целей, полезно ввести понятие статистики, общее определение которой формулируется следующим образом. Назовем статистикой 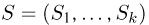 произвольную (измеримую) k-мерную функцию от выборки
произвольную (измеримую) k-мерную функцию от выборки 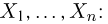
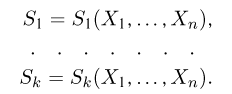
Как функция от случайного вектора  статистика S также будет случайным вектором (см. часть 1, гл.6, параграф 7), и ее функция распределения
статистика S также будет случайным вектором (см. часть 1, гл.6, параграф 7), и ее функция распределения
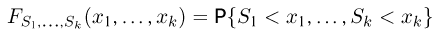
определяется для дискретной наблюдаемой случайной величины X формулой
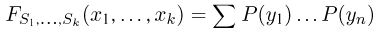
и для непрерывной — формулой
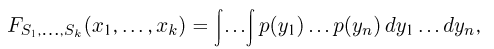
где суммирование или интегрирование производится по всем возможным значениям  (в дискретном случае каждое
(в дискретном случае каждое 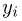 принадлежит множеству
принадлежит множеству 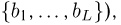 для которых выполнена система неравенств
для которых выполнена система неравенств
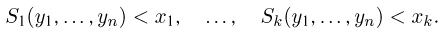
Пример 3. Пусть выборка 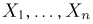 произведена из генеральной совокупности с теоретической функцией распределения
произведена из генеральной совокупности с теоретической функцией распределения 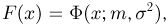 являющейся нормальной с математическим ожиданием (средним значением) т и дисперсией
являющейся нормальной с математическим ожиданием (средним значением) т и дисперсией 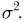 Рассмотрим двумерную статистику
Рассмотрим двумерную статистику 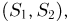 где
где
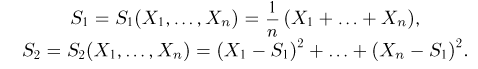
Тогда
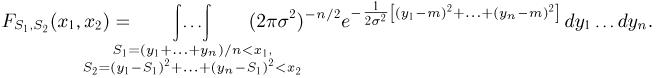
Мы, однако, не будем вычислять записанный интеграл, а воспользуемся тем фактом (см. пример 29, часть 1, гл.6, параграф 7), что любое линейное преобразование переводит нормально распределенный вектор в вектор, снова имеющий нормальное распределение, причем ортогональное преобразование переводит вектор с независимыми координатами, имеющими одинаковые дисперсии, в вектор с также независимыми и имеющими те же самые дисперсии координатами.
Из курса теории вероятностей известно, что статистика 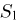 имеет нормальное распределение со средним га и дисперсией
имеет нормальное распределение со средним га и дисперсией 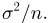 Положим
Положим
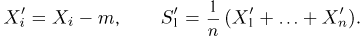
Очевидно, что
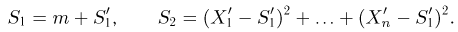
Пусть теперь А — линейное ортогональное преобразование пространства  ставящее в соответствие каждому вектору
ставящее в соответствие каждому вектору 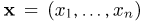 вектор
вектор 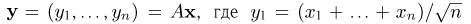 (как известно из курса линейной алгебры, такое преобразование всегда существует). Тогда, если
(как известно из курса линейной алгебры, такое преобразование всегда существует). Тогда, если 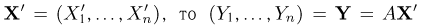 будет нормально распределенным случайным вектором, имеющим независимые координаты
будет нормально распределенным случайным вектором, имеющим независимые координаты 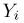 с нулевым средним и дисперсией
с нулевым средним и дисперсией 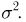 Кроме того,
Кроме того, 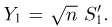 Далее, рассмотрим
Далее, рассмотрим 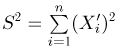 — квадрат длины вектора
— квадрат длины вектора 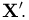 Простейшие преобразования показывают, что
Простейшие преобразования показывают, что
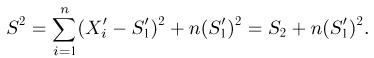
С другой стороны, в силу ортогональности преобразования А
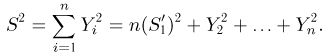
Отсюда, в частности, следует, что
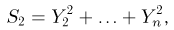
т.е. 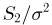 представляет собой сумму квадратов п — 1 независимых случайных величин, распределенных по стандартному нормальному закону. Вспоминая теперь, что случайные величины
представляет собой сумму квадратов п — 1 независимых случайных величин, распределенных по стандартному нормальному закону. Вспоминая теперь, что случайные величины 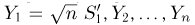 независимы, получаем окончательный ответ: статистики
независимы, получаем окончательный ответ: статистики 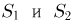 независимы
независимы 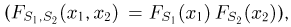 статистика
статистика 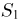 распределена по нормальному закону с параметрами
распределена по нормальному закону с параметрами 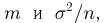 а случайная величина
а случайная величина 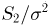 (в том случае, когда дисперсия неизвестна, отношение не является статистикой, поскольку зависит от неизвестного параметра
(в том случае, когда дисперсия неизвестна, отношение не является статистикой, поскольку зависит от неизвестного параметра 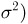 — по закону
— по закону 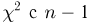 степенями свободы (см. также параграф 4).
степенями свободы (см. также параграф 4).
Отметим, что проведенные рассуждения будут нами постоянно использоваться в гл. 4, посвященной статистическим задачам, связанным с нормально распределенными наблюдениями.
Важный класс статистик составляют так называемые достаточные статистики. Не давая пока строгого математического определения, скажем, что статистика S является достаточной, если она содержит всю ту информацию относительно теоретической функции распределения F(x), что и исходная выборка 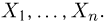 В частности, вариационный ряд всегда представляет собой достаточную статистику. Более сложными примерами достаточных статистик являются число успехов в схеме Бернулли и двумерная статистика S из примера 3 для выборки из генеральной совокупности с нормальной теоретической функцией распределения. В современной математической статистике достаточные статистики играют очень важную роль.
В частности, вариационный ряд всегда представляет собой достаточную статистику. Более сложными примерами достаточных статистик являются число успехов в схеме Бернулли и двумерная статистика S из примера 3 для выборки из генеральной совокупности с нормальной теоретической функцией распределения. В современной математической статистике достаточные статистики играют очень важную роль.
Эмпирическая функция распределения. Пусть мы имеем выборку объема п из генеральной совокупности с теоретической функцией распределения F(x). Построим по выборке аналог теоретической функции распределения F(x). Положим
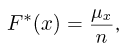
где 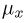 — число элементов выборки, значения которых
— число элементов выборки, значения которых 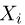 меньше х. Поскольку каждое меньше х с вероятностью
меньше х. Поскольку каждое меньше х с вероятностью 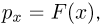 а сами независимы, то
а сами независимы, то 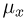 является целочисленной случайной величиной, распределенной по биномиальному закону:
является целочисленной случайной величиной, распределенной по биномиальному закону:
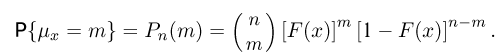
Функция 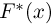 носит название эмпирической (выборочной) функции распределения. Ясно, что при каждом х значение эмпирической функции распределения является случайной величиной, принимающей значения
носит название эмпирической (выборочной) функции распределения. Ясно, что при каждом х значение эмпирической функции распределения является случайной величиной, принимающей значения 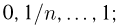 если же рассматривать как функцию от х, то представляет собой случайный процесс.
если же рассматривать как функцию от х, то представляет собой случайный процесс.
Построение эмпирической функции распределения удобно производить с помощью вариационного ряда 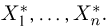 Функция постоянна на каждом интервале
Функция постоянна на каждом интервале 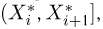 а в точке
а в точке 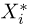 увеличивается на 1 /п.
увеличивается на 1 /п.
Пример 4. График эмпирической функции распределения, построенной по вариационному ряду из табл. 3, приведен на рис. 1.
Если выборка задана статистическим рядом (см. табл. 4), то эмпирическая функция распределения также постоянна на интервалах 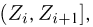 но ее значение в точке
но ее значение в точке 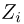 увеличивается на
увеличивается на  а не на 1/n
а не на 1/n
Пример 5. График эмпирической функции распределения, построенной по статистическому ряду из табл. 6, приведен на рис. 2.
Гистограмма, полигон. Для наглядности выборку иногда преобразуют следующим образом. Всю ось абсцисс делят на интервалы 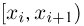 длиной
длиной 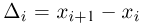 и определяют функцию
и определяют функцию 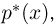 постоянную на i-м интервале и принимающую на этом интервале значение
постоянную на i-м интервале и принимающую на этом интервале значение 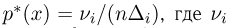 — число элементов выборки, попавших в интервал
— число элементов выборки, попавших в интервал 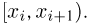 Функция
Функция 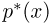 называется гистограммой.
называется гистограммой.
При наблюдении дискретной случайной величины вместо гистограммы часто используют полигон частот. Для этого по оси абсцисс откладывают все возможные значения 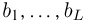 наблюдаемой величины X, а по оси ординат, пользуясь статистическим рядом, либо числа
наблюдаемой величины X, а по оси ординат, пользуясь статистическим рядом, либо числа  элементов выборки, принявших значения
элементов выборки, принявших значения  (полигон частот), либо соответствующие наблюденные частоты
(полигон частот), либо соответствующие наблюденные частоты
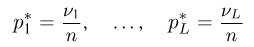
(полигон относительных частот). Для большей наглядности соседние точки соединяются отрезками прямой.
Для непрерывной наблюдаемой случайной величины полигоном относительных частот иногда называют ломаную линию, соединяющую середины отрезков, составляющих гистограмму.
Пример 6. Построим гистограмму и полигон относительных частот выборки, представленной в табл. 2. Для этого выберем интервалы одинаковой длины  Числа
Числа  и значения
и значения 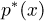 на каждом интервале приведены в табл. 7. Гистограмма выборки показана на рис. 3 сплошной линией, а полигон относительных частот — штриховой линией.
на каждом интервале приведены в табл. 7. Гистограмма выборки показана на рис. 3 сплошной линией, а полигон относительных частот — штриховой линией.
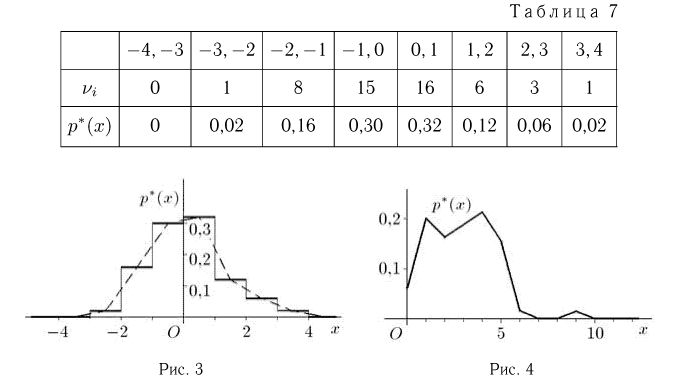
Пример 7. Построим полигон относительных частот выборки, приведенной в табл. 5. Возможные значения наблюдаемой случайной величины X (числа частиц, попавших в счетчик Гейгера) представляют собой неотрицательные целые числа. Воспользовавшись статистическим рядом из табл. 6, получаем полигон относительных частот, изображенный на рис. 4.
Предельное поведение эмпирической функции распределения.
Предположим, что по выборке 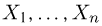 мы построили эмпирическую функцию распределения
мы построили эмпирическую функцию распределения 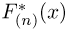 (здесь и в дальнейшем в том случае, когда нам важна зависимость какой-то характеристики от объема выборки п, будем снабжать ее дополнительным нижним индексом (n)). Как мы уже говорили, число
(здесь и в дальнейшем в том случае, когда нам важна зависимость какой-то характеристики от объема выборки п, будем снабжать ее дополнительным нижним индексом (n)). Как мы уже говорили, число 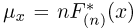 элементов выборки, принявших значение, меньшее х, распределено по биномиальному закону с вероятностью успеха
элементов выборки, принявших значение, меньшее х, распределено по биномиальному закону с вероятностью успеха 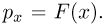 Тогда при
Тогда при 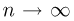 в силу усиленного закона больших чисел (часть 1, гл.8, параграф 2) значения эмпирических функций распределения
в силу усиленного закона больших чисел (часть 1, гл.8, параграф 2) значения эмпирических функций распределения 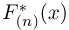 сходятся при каждом х к значению теоретической функции распределения F(x). В. И. Гливенко и Ф. П. Кантелли обобщили этот факт и доказали следующую теорему.
сходятся при каждом х к значению теоретической функции распределения F(x). В. И. Гливенко и Ф. П. Кантелли обобщили этот факт и доказали следующую теорему.
Теорема Гливенко-Кантелли. При с вероятностью, равной единице
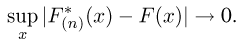
Смысл теоремы Гливенко-Кантелли заключается в том, что при увеличении объема выборки п у эмпирической функции распределения исчезают свойства случайности и она приближается к теоретической функции распределения.
Аналогично, если п велико, то значение гистограммы 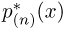 в точке х приближенно равно
в точке х приближенно равно
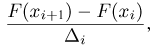
где 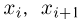 — концы интервала, в котором находится х, а
— концы интервала, в котором находится х, а 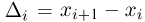 есть длина этого интервала. Если теоретическая функция распределения имеет плотность распределения р(х) и при этом длины интервалов
есть длина этого интервала. Если теоретическая функция распределения имеет плотность распределения р(х) и при этом длины интервалов 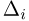 малы, то гистограмма
малы, то гистограмма 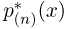 достаточно хорошо воспроизводит эту плотность.
достаточно хорошо воспроизводит эту плотность.
Выборочные характеристики. Эмпирическая функция распределения 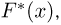 построенная по фиксированной выборке
построенная по фиксированной выборке 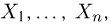 обладает всеми свойствами обычной функции распределения (дискретной случайной величины). В частности, по ней можно найти математическое ожидание (среднее)
обладает всеми свойствами обычной функции распределения (дискретной случайной величины). В частности, по ней можно найти математическое ожидание (среднее)
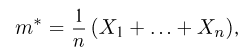
второй момент
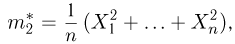
дисперсию
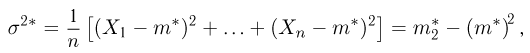
момент k-го порядка
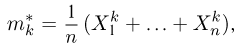
центральный момент k-го порядка
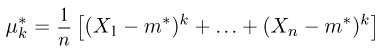
и т.д. Соответствующие характеристики называются выборочными (выборочное среднее, выборочный второй момент, выборочная дисперсия и т.п.). Ясно, что выборочные характеристики как функции от случайных величин сами являются случайными величинами, причем их распределения определяются в соответствии с общими положениями теории вероятностей (см. часть 1, гл.6, параграф 7). Так, функция распределения выборочного среднего 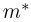 для случая дискретной наблюдаемой случайной величины определяется формулой
для случая дискретной наблюдаемой случайной величины определяется формулой
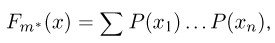
где суммирование ведется по всем  принимающим значения
принимающим значения 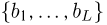 и удовлетворяющим неравенству
и удовлетворяющим неравенству 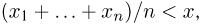 а функция распределения выборочного второго момента
а функция распределения выборочного второго момента 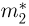 для непрерывного случая — формулой
для непрерывного случая — формулой
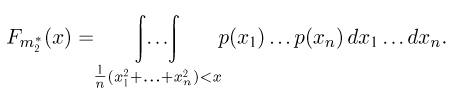
Наряду с выборочной дисперсией 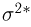 часто используют и другую характеристику разброса выборки вокруг среднего:
часто используют и другую характеристику разброса выборки вокруг среднего:
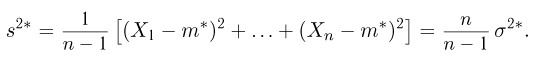
Характеристику 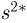 также будем называть выборочной дисперсией, а для того чтобы не путать
также будем называть выборочной дисперсией, а для того чтобы не путать 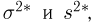 каждый раз будем указывать, о какой именно выборочной дисперсии идет речь. Выборочная дисперсия отличается от выборочной дисперсии только лишь наличием множителя
каждый раз будем указывать, о какой именно выборочной дисперсии идет речь. Выборочная дисперсия отличается от выборочной дисперсии только лишь наличием множителя 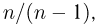 который с увеличением объема выборки п стремится к единице, и, казалось бы, нет смысла вводить две практически одинаковые величины. Однако, как мы увидим из дальнейшего, является несмещенной оценкой теоретической дисперсии
который с увеличением объема выборки п стремится к единице, и, казалось бы, нет смысла вводить две практически одинаковые величины. Однако, как мы увидим из дальнейшего, является несмещенной оценкой теоретической дисперсии 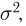 чего нельзя сказать о выборочной дисперсии хотя стандартные методы приводят именно к
чего нельзя сказать о выборочной дисперсии хотя стандартные методы приводят именно к
Пример 8. Подсчитаем выборочное среднее и выборочные дисперсии для выборки, приведенной в табл. 2:
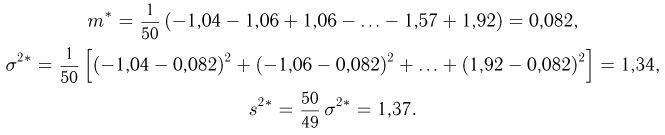
Для подсчета выборочной дисперсии можно было бы воспользоваться также формулой 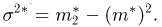
Основные распределения математической статистики
Наиболее часто в математической статистике используются: нормальное распределение, 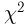 распределение (распределение Пирсона), t-распределение (распределение Стьюдента), F-распределение (распределение Фишера), распределение Колмогорова и
распределение (распределение Пирсона), t-распределение (распределение Стьюдента), F-распределение (распределение Фишера), распределение Колмогорова и 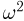 -распределение. Все эти распределения связаны с нормальным. В свою очередь, широкое распространение нормального распределения обусловлено исключительно центральной предельной теоремой (см. часть 1, гл.8, параграф 4). Ввиду их особой важности все названные распределения затабулированы и содержатся в различных статистических таблицах, а также, частично, в большинстве учебников по теории вероятностей и математической статистике. Наиболее полными из известных и доступных читателю в нашей стране являются таблицы Л.Н. Большева и Н. В. Смирнова [1], на которые мы и будем ссылаться в дальнейшем.
-распределение. Все эти распределения связаны с нормальным. В свою очередь, широкое распространение нормального распределения обусловлено исключительно центральной предельной теоремой (см. часть 1, гл.8, параграф 4). Ввиду их особой важности все названные распределения затабулированы и содержатся в различных статистических таблицах, а также, частично, в большинстве учебников по теории вероятностей и математической статистике. Наиболее полными из известных и доступных читателю в нашей стране являются таблицы Л.Н. Большева и Н. В. Смирнова [1], на которые мы и будем ссылаться в дальнейшем.
Нормальное распределение. Одномерное стандартное нормальное распределение (стандартный нормальный закон) задается своей плотностью распределения (см. часть 1, гл.5, параграф 4)
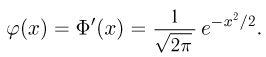
Значения функции Ф(x) и плотности 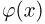 стандартного нормального распределения, а также квантилей
стандартного нормального распределения, а также квантилей 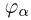 (функции обратной функции стандартного нормального распределения) приведены в [1], табл. 1.1-1.3 (см. также табл.2 и 3 приложения).
(функции обратной функции стандартного нормального распределения) приведены в [1], табл. 1.1-1.3 (см. также табл.2 и 3 приложения).
Общее одномерное нормальное распределение характеризуется двумя параметрами: средним (математическим ожиданием) т и дисперсией 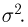 Его можно трактовать как распределение случайной величины
Его можно трактовать как распределение случайной величины
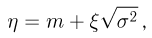
где случайная величина 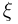 подчинена стандартному нормальному закону. Плотность распределения и функцию распределения общего нормального закона будем обозначать через
подчинена стандартному нормальному закону. Плотность распределения и функцию распределения общего нормального закона будем обозначать через 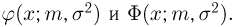 Многомерное (k-мерное) нормальное распределение (часть 1, гл.6, параграф 4) определяется вектором средних
Многомерное (k-мерное) нормальное распределение (часть 1, гл.6, параграф 4) определяется вектором средних 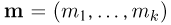 и матрицей ковариаций
и матрицей ковариаций 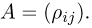
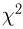 -распределение (см. часть 1, гл.5, параграф 4, а также примеры 28 и 30, часть 1, гл.6, параграф 7). Пусть
-распределение (см. часть 1, гл.5, параграф 4, а также примеры 28 и 30, часть 1, гл.6, параграф 7). Пусть 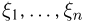 — независимые случайные величины, распределенные по стандартному нормальному закону. Распределение случайной величины
— независимые случайные величины, распределенные по стандартному нормальному закону. Распределение случайной величины
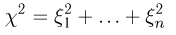
носит название —распределения с п степенями свободы, -распределение имеет плотность распределения
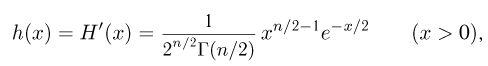
где  введено в параграфе 4 гл. 5.
введено в параграфе 4 гл. 5.
Значения функции -распределения и а-процентных точек (а-про-центная точка -распределения представляет собой  -квантиль
-квантиль  -распределения приведены в [1], табл. 2.1а и 2.2а. В дальнейшем нам будет полезно следующее свойство. Пусть
-распределения приведены в [1], табл. 2.1а и 2.2а. В дальнейшем нам будет полезно следующее свойство. Пусть  независимые случайные величины, распределенные по нормальному закону с одинаковыми параметрами
независимые случайные величины, распределенные по нормальному закону с одинаковыми параметрами  Положим
Положим
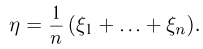
Тогда случайная величина
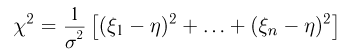
имеет -распределение, но с п-1 степенями свободы. Доказательство этого факта содержится в примере 3.
Еще одна схема, в которой появляется -распределение — полиномиальная схема (см. часть 1, гл.4, параграф 7). Пусть производится п независимых одинаковых испытаний, в каждом из которых с вероятностью  может произойти одно из событий
может произойти одно из событий  Обозначим через
Обозначим через 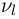 число появлений события
число появлений события 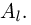 Тогда из многомерного аналога интегральной теоремы Муавра-Лапласа следует, что случайная величина
Тогда из многомерного аналога интегральной теоремы Муавра-Лапласа следует, что случайная величина
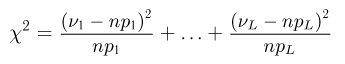
при асимптотически распределена по закону 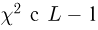 степенями свободы.
степенями свободы.
t-распределение. Пусть 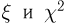 — независимые случайные величины, причем
— независимые случайные величины, причем 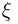 распределена по стандартному нормальному закону, а имеет -распределение с п степенями свободы. Распределение случайной величины
распределена по стандартному нормальному закону, а имеет -распределение с п степенями свободы. Распределение случайной величины
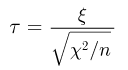
называется t-распределением с п степенями свободы, t-распределение имеет плотность распределения
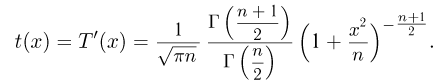
Значения функции t-распределения и 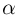 -процентных точек
-процентных точек 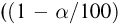 квантилей
квантилей 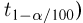 t-распределения приведены в [1], табл. 3.1а и 3.2.
t-распределения приведены в [1], табл. 3.1а и 3.2.
Далее, пусть  — независимые одинаково распределенные случайные величины, подчиненные нормальному закону со средним т. Положим
— независимые одинаково распределенные случайные величины, подчиненные нормальному закону со средним т. Положим
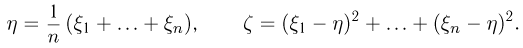
Тогда случайные величины 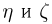 независимы, а случайная величина
независимы, а случайная величина
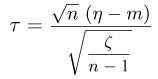
имеет t-распределение с n-1 степенями свободы (доказательство этого см. в примере 3).
F-распределение. Пусть 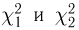 две независимые случайные величины, имеющие
две независимые случайные величины, имеющие 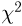 -распределения с
-распределения с 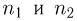 степенями свободы. Распределение случайной величины
степенями свободы. Распределение случайной величины
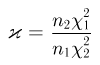
носит название F-распределения с параметрами 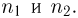 F-распределение имеет плотность распределения
F-распределение имеет плотность распределения
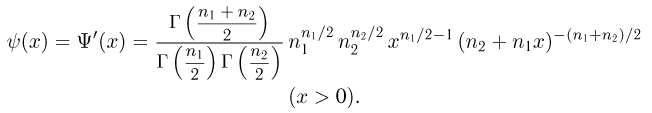
Значения -процентных точек 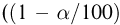 -квантилей
-квантилей 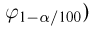 -распределения приведены в [1], табл. 3.5.
-распределения приведены в [1], табл. 3.5.
Распределение Колмогорова. Функция распределения Колмогорова имеет вид
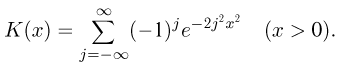
Распределение Колмогорова является распределением случайной величины
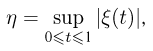
где 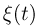 — броуновский мостик, т. е. винеровский процесс с закрепленными концами
— броуновский мостик, т. е. винеровский процесс с закрепленными концами 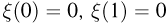 на отрезке
на отрезке 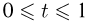 (см. [11]).
(см. [11]).
Значения функции распределения Колмогорова приведены в [1], табл.6.1. Квантили распределения Колмогорова будем обозначать через 
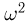 -распределение. Функция —распределения задается формулой
-распределение. Функция —распределения задается формулой
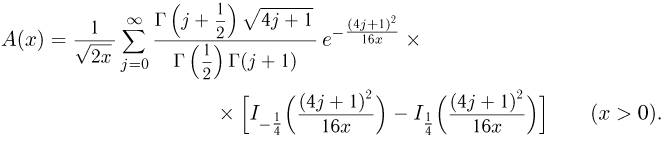
Здесь 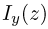 — модифицированная функция Бесселя, -распределение представляет собой распределение случайной величины
— модифицированная функция Бесселя, -распределение представляет собой распределение случайной величины
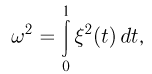
где 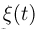 — броуновский мостик.
— броуновский мостик.
Значения функции -распределения приведены в [1], табл. 6.4а. Квантили -распределения будем обозначать через 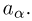
Оценки неизвестных параметров
Как уже говорилось в гл. 1, одним из двух основных направлений в математической статистике является оценивание неизвестных параметров. В этой главе мы дадим определение оценки, опишем те свойства, которые желательно требовать от оценки, и приведем основные методы построения оценок. Завершается глава изложением метода построения доверительных интервалов для неизвестных параметров.
Статистические оценки и их свойства
Предположим, что в результате наблюдений мы получили выборку 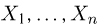 из генеральной совокупности с теоретической функцией распределения F(x). Относительно F(x) обычно бывает известно только, что она принадлежит определенному параметрическому семейству
из генеральной совокупности с теоретической функцией распределения F(x). Относительно F(x) обычно бывает известно только, что она принадлежит определенному параметрическому семейству 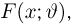 зависящему от числового или векторного параметра
зависящему от числового или векторного параметра 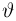 Как правило, для простоты изложения будем рассматривать случай числового параметра и лишь иногда обращаться к векторному параметру
Как правило, для простоты изложения будем рассматривать случай числового параметра и лишь иногда обращаться к векторному параметру 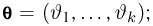 в векторном случае будем использовать запись
в векторном случае будем использовать запись 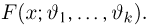 Для большей наглядности будем все неизвестные параметры (за исключением теоретических моментов
Для большей наглядности будем все неизвестные параметры (за исключением теоретических моментов 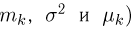 обозначать буквой (снабжая их при необходимости индексами), хотя в теории вероятностей для них обычно приняты другие обозначения. Наша цель состоит в том, чтобы, опираясь только на выборку
обозначать буквой (снабжая их при необходимости индексами), хотя в теории вероятностей для них обычно приняты другие обозначения. Наша цель состоит в том, чтобы, опираясь только на выборку 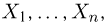 оценить неизвестный параметр
оценить неизвестный параметр
Оценкой неизвестного параметра построенной по выборке назовем произвольную функцию
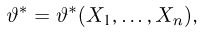
зависящую только от выборки Ясно, что как функция от случайной величины 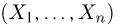 оценка
оценка 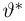 сама будет являться случайной величиной и, как всякая случайная величина, будет иметь функцию распределения
сама будет являться случайной величиной и, как всякая случайная величина, будет иметь функцию распределения 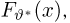 определяемую в дискретном случае формулой
определяемую в дискретном случае формулой
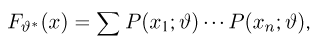
где суммирование ведется по всем переменным 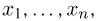 принимающим значения
принимающим значения  из ряда распределения наблюдаемой случайной величины X и удовлетворяющим неравенству
из ряда распределения наблюдаемой случайной величины X и удовлетворяющим неравенству 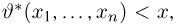 и в непрерывном случае — формулой
и в непрерывном случае — формулой
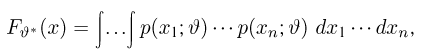
где интегрирование ведется по области, выделяемой неравенством 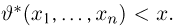 Как уже говорилось, иногда для того, чтобы подчеркнуть зависимость оценки от объема выборки п, будем наряду с обозначением
Как уже говорилось, иногда для того, чтобы подчеркнуть зависимость оценки от объема выборки п, будем наряду с обозначением  употреблять обозначение
употреблять обозначение 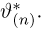 Нужно четко представлять себе, что зависимость оценки от неизвестного параметра осуществляется только через зависимость от выборки
Нужно четко представлять себе, что зависимость оценки от неизвестного параметра осуществляется только через зависимость от выборки 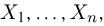 что в свою очередь реализуется зависимостью от функции распределения
что в свою очередь реализуется зависимостью от функции распределения 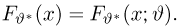 Приведенное выше определение отождествляет понятие оценки (вектора оценок
Приведенное выше определение отождествляет понятие оценки (вектора оценок 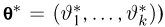 с одномерной (k-мерной) статистикой.
с одномерной (k-мерной) статистикой.
Пример:
Предположим, что проведено п испытаний в схеме Бернулли с неизвестной вероятностью успеха В результате наблюдений получена выборка где 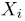 — число успехов i-м испытании. Ряд распределения наблюдаемой величины X — числа успехов в одном испытании представлен в табл. 1.
— число успехов i-м испытании. Ряд распределения наблюдаемой величины X — числа успехов в одном испытании представлен в табл. 1.
В качестве оценки рассмотрим наблюденную частоту успехов
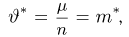
где
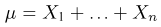
представляет собой суммарное число успехов в п испытаниях Бернулли. Статистика 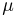 распределена по биномиальному закону с параметром поэтому ряд распределения оценки имеет вид, приведенный в табл. 2.
распределена по биномиальному закону с параметром поэтому ряд распределения оценки имеет вид, приведенный в табл. 2.

Пример:
Выборка  произведена из генеральной совокупности с теоретической функцией распределения
произведена из генеральной совокупности с теоретической функцией распределения 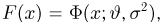 являющейся нормальной с неизвестным средним В качестве оценки снова рассмотрим выборочное среднее
являющейся нормальной с неизвестным средним В качестве оценки снова рассмотрим выборочное среднее
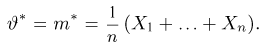
Функция распределения 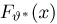 задается формулой
задается формулой
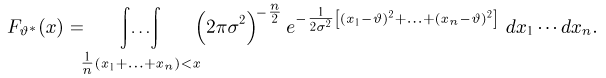
Однако вместо непосредственного вычисления написанного n-мерного интеграла заметим, что статистика
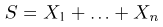
распределена по нормальному закону с параметрами 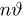 (математической ожидание) и
(математической ожидание) и 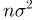 (дисперсия). Значит, оценка
(дисперсия). Значит, оценка 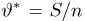 распределена также по нормальному закону с параметрами
распределена также по нормальному закону с параметрами 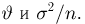
Разумеется, на практике имеет смысл использовать далеко не любую оценку.
Пример:
Как и в примере 1, рассмотрим испытания в схеме Бернулли. Однако теперь в качестве оценки неизвестной вероятности успеха 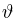 возьмем
возьмем
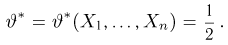
Такая оценка будет хороша лишь в том случае, когда истинное значение 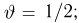 ее качество ухудшается с увеличением отклонения от 1 /2.
ее качество ухудшается с увеличением отклонения от 1 /2.
Приведенный пример показывает, что желательно употреблять только те оценки, которые по возможности принимали бы значения, наиболее близкие к неизвестному параметру. Однако в силу случайности выборки в математической статистике мы, как правило, не застрахованы полностью от сколь угодно большой ошибки. Значит, гарантировать достаточную близость оценки 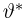 к оцениваемому параметру можно только с некоторой вероятностью и для того, чтобы увеличить эту вероятность, приходится приносить необходимую жертву — увеличивать объем выборки п.
к оцениваемому параметру можно только с некоторой вероятностью и для того, чтобы увеличить эту вероятность, приходится приносить необходимую жертву — увеличивать объем выборки п.
Опишем теперь те свойства, которые мы хотели бы видеть у оценки.
Главное свойство любой оценки, оправдывающее само название «оценка», — возможность хотя бы ценой увеличения объема выборки до бесконечности получить точное значение неизвестного параметра . Оценка называется состоятельной, если с ростом объема выборки она сходится к оцениваемому параметру Можно рассматривать сходимость различных типов: по вероятности, с вероятностью единица, в среднем квадратичном и т.д. Обычно рассматривается сходимость по вероятности, т.е. состоятельной называется такая оценка 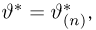 которая для любого
которая для любого  при всех возможных значениях неизвестного параметра удовлетворяет соотношению
при всех возможных значениях неизвестного параметра удовлетворяет соотношению
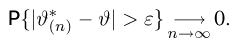
Отметим, что правильнее было бы говорить о состоятельности последовательности оценок 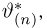 поскольку для каждого значения п объема выборки оценка
поскольку для каждого значения п объема выборки оценка  может определяться по своему правилу. Однако в дальнейшем мы будем употреблять понятие состоятельности только для оценок, построенных по определенным алгоритмам, поэтому будем говорить просто о состоятельности оценки.
может определяться по своему правилу. Однако в дальнейшем мы будем употреблять понятие состоятельности только для оценок, построенных по определенным алгоритмам, поэтому будем говорить просто о состоятельности оценки.
Пример:
Оценка из примера 1 является состоятельной оценкой неизвестной вероятности успеха . Это является прямым следствием закона больших чисел Бернулли.
Пример:
Пусть выборка  произведена из генеральной совокупности с неизвестной теоретической функцией распределения F(x). Тогда в силу закона больших чисел выборочный момент
произведена из генеральной совокупности с неизвестной теоретической функцией распределения F(x). Тогда в силу закона больших чисел выборочный момент
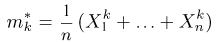
сходится к теоретическому моменту 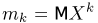 значит, представляет собой состоятельную оценку
значит, представляет собой состоятельную оценку 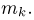 Аналогично, выборочные дисперсии
Аналогично, выборочные дисперсии 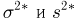 и выборочные центральные моменты
и выборочные центральные моменты 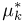 являются состоятельными оценками теоретической дисперсии
являются состоятельными оценками теоретической дисперсии 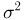 и теоретических центральных моментов
и теоретических центральных моментов 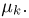 Отметим, что поскольку в этом примере не предполагается принадлежность теоретической функции распределения F(x) какому-либо параметрическому семейству, то мы имеем дело с задачей оценки неизвестных моментов теоретической функции распределения в непараметрической модели.
Отметим, что поскольку в этом примере не предполагается принадлежность теоретической функции распределения F(x) какому-либо параметрическому семейству, то мы имеем дело с задачей оценки неизвестных моментов теоретической функции распределения в непараметрической модели.
Пример:
Выборка 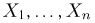 произведена из генеральной совокупности с теоретической функцией распределения F(x), имеющей плотность распределения Коши
произведена из генеральной совокупности с теоретической функцией распределения F(x), имеющей плотность распределения Коши
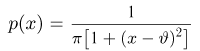
с неизвестным параметром Поскольку плотность распределения Коши симметрична относительно то казалось бы естественным в качестве оценки параметра взять выборочное среднее
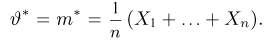
Однако 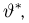 как и сама наблюдаемая случайная величина X, имеет распределение Коши с тем же параметром (это легко установить с помощью характеристических функций, см. часть 1, гл.8, параграф 3), т.е. не сближается с параметром а значит, не является состоятельной оценкой параметра
как и сама наблюдаемая случайная величина X, имеет распределение Коши с тем же параметром (это легко установить с помощью характеристических функций, см. часть 1, гл.8, параграф 3), т.е. не сближается с параметром а значит, не является состоятельной оценкой параметра
Из курса теории вероятностей известно (см. часть 1, гл.7, параграф 1), что мерой отклонения оценки от параметра служит разность 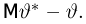 В математической статистике разность
В математической статистике разность
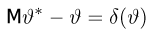
называется смещением оценки Ясно, что
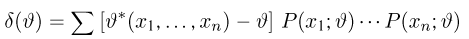
в дискретном случае и
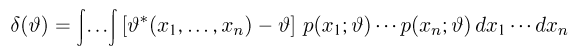
в непрерывном, где суммирование или интегрирование ведется по всем возможным значениям 
Оценка называется несмещенной, если
при всех е. ее среднее значение 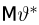 совпадает с оцениваемым параметром
совпадает с оцениваемым параметром
Пример:
Оценка  неизвестной вероятности успеха из примера 1 является несмещенной. Действительно,
неизвестной вероятности успеха из примера 1 является несмещенной. Действительно,
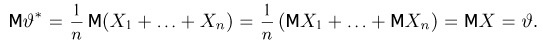
Пример:
Выборочные моменты  являются несмещенными оценками теоретических моментов
являются несмещенными оценками теоретических моментов 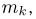 поскольку
поскольку
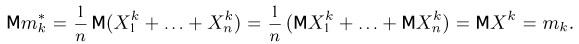
Вычислим теперь математическое ожидание выборочной дисперсии 
Таким образом, 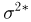 является смещенной (хотя и состоятельной, см. пример 5) оценкой дисперсии
является смещенной (хотя и состоятельной, см. пример 5) оценкой дисперсии 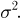 Поскольку
Поскольку
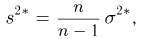
то
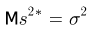
и 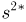 представляет собой уже несмещенную оценку
представляет собой уже несмещенную оценку 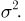 Можно показать также, что выборочные центральные моменты
Можно показать также, что выборочные центральные моменты 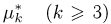 являются смещенными оценками теоретических центральных моментов
являются смещенными оценками теоретических центральных моментов 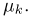
Пример:
Пусть  — выборка из генеральной совокупности с теоретической функцией распределения
— выборка из генеральной совокупности с теоретической функцией распределения 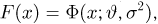 являющейся нормальной с неизвестным средним Поскольку
являющейся нормальной с неизвестным средним Поскольку 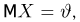 то оценка
то оценка
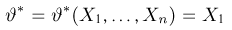
является несмещенной. Очевидно, однако, что она не является состоятельной.
Примеры 8 и 9 показывают, что состоятельная оценка может быть сметенной и, наоборот, несмещенная оценка не обязана быть состоятельной.
Рассматривая несколько оценок неизвестного параметра мы, разумеется, хотели бы выбрать из них ту, которая имела бы наименьший разброс, причем при любом значении неизвестного параметра . Мерой разброса оценки как и всякой случайной величины, является дисперсия
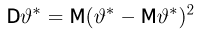
(дисперсия, как и распределение оценки, зависит от неизвестного параметра ). Однако для смещенной оценки дисперсия служит мерой близости не к оцениваемому параметру а к математическому ожиданию 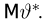 Поэтому естественно искать оценки с наименьшей дисперсией не среди всех оценок, а только среди несмещенных, что мы и будем делать в дальнейшем. Для несмещенных оценок дисперсия определяется также формулой
Поэтому естественно искать оценки с наименьшей дисперсией не среди всех оценок, а только среди несмещенных, что мы и будем делать в дальнейшем. Для несмещенных оценок дисперсия определяется также формулой
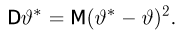
Имеется несколько подходов к нахождению несмещенных оценок с минимальной дисперсией. Это связано с тем, что такие оценки существуют не всегда, а найти их бывает чрезвычайно сложно. Здесь мы изложим понятие эффективности оценки, основанное на неравенстве Рао-Крамера.
Теорема:
Неравенство Рао-Крамера. Пусть  — несмещенная оценка неизвестного параметра
— несмещенная оценка неизвестного параметра  построенная по выборке объема п. Тогда (при некоторых дополнительных условиях регулярности, наложенных на семейство
построенная по выборке объема п. Тогда (при некоторых дополнительных условиях регулярности, наложенных на семейство 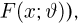
где 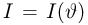 — информация Фишера, определяемая в дискретном случае формулой
— информация Фишера, определяемая в дискретном случае формулой
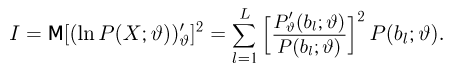
а в непрерывном — формулой
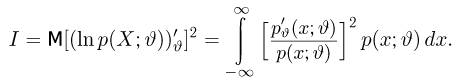
Прежде чем переходить к доказательству теоремы, заметим, что по неравенству Рао-Крамера дисперсия любой несмещенной оценки не может быть меньше 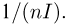 Назовем эффективностью
Назовем эффективностью 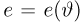 несмещенной оценки
несмещенной оценки 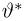 величину
величину
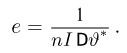
Ясно, что эффективность любой оценки при каждом заключена между нулем и единицей, причем чем она ближе к единице при каком-либо тем лучше оценка при этом значении неизвестного параметра.
Несмещенная оценка называется эффективной (по Рао-Краме-ру), если 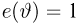 при любом
при любом 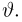
Доказательство теоремы 1. Доказательство этой и всех остальных теорем будем проводить (если не сделано специальной оговорки) для непрерывного случая. Это связано с тем, что непрерывный случай, как правило, более сложен, и читатель, усвоивший доказательство для непрерывного случая, легко проведет его для дискретного.
Как мы увидим из хода доказательства, условия регулярности семейства 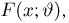 упомянутые в формулировке теоремы, есть не что иное, как условия, гарантирующие законность дифференцирования под знаком интеграла в формулах (1) и (3). В разных книгах сформулированы различные достаточные условия. Мы упомянем одно из них, приведенное в [11]:
упомянутые в формулировке теоремы, есть не что иное, как условия, гарантирующие законность дифференцирования под знаком интеграла в формулах (1) и (3). В разных книгах сформулированы различные достаточные условия. Мы упомянем одно из них, приведенное в [11]:
функция 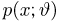 для всех (точнее, для почти всех) х непрерывно дифференцируема по информация Фишера
для всех (точнее, для почти всех) х непрерывно дифференцируема по информация Фишера 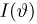 конечна, положительна и непрерывна по
конечна, положительна и непрерывна по
Приступим теперь к собственно доказательству теоремы. Заметим прежде всего, что, дифференцируя тождество
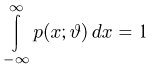
(в силу сформулированного условия это можно делать), получаем
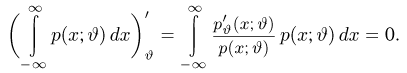
Далее, в силу несмещенности оценки 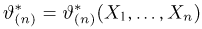 имеем
имеем
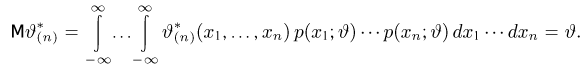
Дифференцируя это равенство по и учитывая очевидное тождество
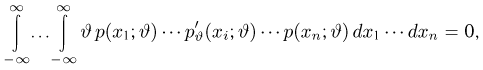
полученное из (1) и (2), находим
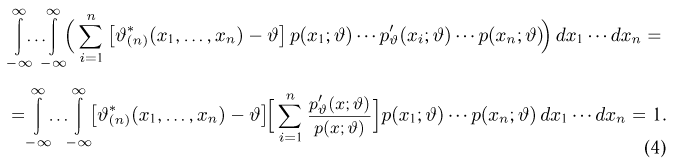
Воспользовавшись неравенством Коши-Буняковского
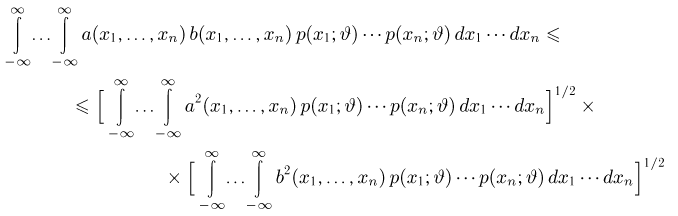
при
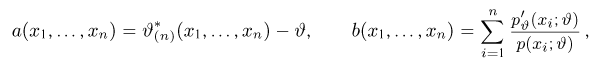
имеем
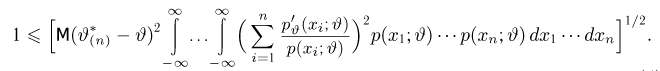
Заметим теперь, что в силу тождества (2)
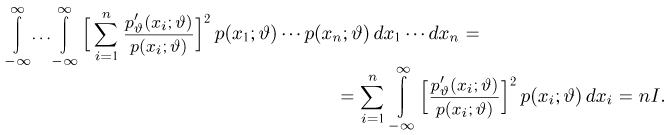
Тогда неравенство (5) можно переписать в виде 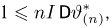 откуда и следует неравенство Рао-Крамера.
откуда и следует неравенство Рао-Крамера.
Замечание:
Для превращения используемого при доказательстве теоремы 1 неравенства Коши-Буняковского, в равенство необходимо и достаточно существование таких функций 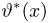 аргумента х и
аргумента х и 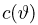 аргумента что ,
аргумента что ,
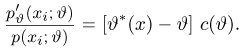
При этом оценка 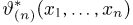 должна иметь вид
должна иметь вид
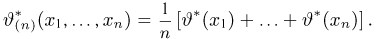
Обозначая
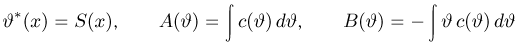
и интегрируя уравнение (6), получаем, что необходимым условием существования эффективной оценки является возможность представления плотности распределения  в виде
в виде
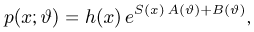
где 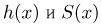 — функции, зависящие только от
— функции, зависящие только от 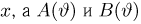 функции, зависящие только от
функции, зависящие только от
Аналогичное представление для ряда распределения 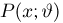 должно иметь место и в дискретном случае. Семейство плотностей или рядов распределения такого вида носит название экспоненциального.
должно иметь место и в дискретном случае. Семейство плотностей или рядов распределения такого вида носит название экспоненциального.
Экспоненциальные семейства играют в математической статистике важную роль. В частности, как мы показали, только для этих семейств могут существовать эффективные оценки, которые к тому же определяются формулой
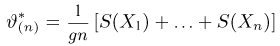
(появление множителя 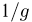 связано с неоднозначностью определения функций
связано с неоднозначностью определения функций 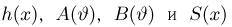 в представлении (7)). Однако следует помнить, что не для всякого экспоненциального семейства существует эффективная оценка (в принятом нами смысле), поскольку эффективная оценка по определению должна быть несмещенной, что, вообще говоря, нельзя сказать об оценке (8) в случае произвольного экспоненциального семейства. Впрочем, из тождества (1) вытекает весьма простой способ проверки несмещенности (8) непосредственно по
в представлении (7)). Однако следует помнить, что не для всякого экспоненциального семейства существует эффективная оценка (в принятом нами смысле), поскольку эффективная оценка по определению должна быть несмещенной, что, вообще говоря, нельзя сказать об оценке (8) в случае произвольного экспоненциального семейства. Впрочем, из тождества (1) вытекает весьма простой способ проверки несмещенности (8) непосредственно по 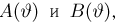 заключающийся в выполнении равенства
заключающийся в выполнении равенства 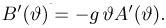
Замечание:
Неравенство Рао-Крамера можно обобщить на случай смещенных оценок:
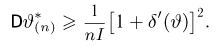
И в этом случае неравенство превращается в равенство только тогда, когда семейство распределений экспоненциально.
Пример:
Рассмотрим оценку 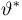 неизвестной вероятности успеха в схеме Бернулли из примера 1. Как показано в примере 7, эта оценка несмещенная. Дисперсия имеет вид
неизвестной вероятности успеха в схеме Бернулли из примера 1. Как показано в примере 7, эта оценка несмещенная. Дисперсия имеет вид
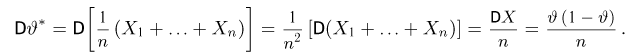
Найдем информацию Фишера (напомним, что в данном случае наблюдаемая величина X принимает всего два значения 0 и 1 с вероятностями 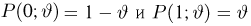 соответственно):
соответственно):
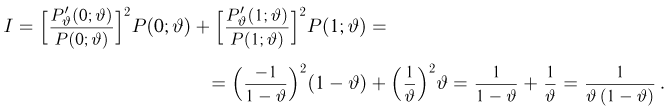
Таким образом, 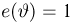 и, значит, оценка эффективная.
и, значит, оценка эффективная.
Пример:
Рассмотрим оценку неизвестного среднего нормального закона из примера 2. Поскольку эта оценка представляет собой выборочное среднее, то в соответствии с результатами, полученными в примере 8, она является несмещенной. Найдем ее эффективность. Для этого прежде всего заметим, что
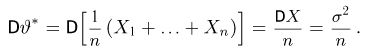
Далее,
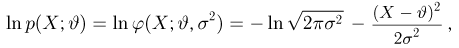
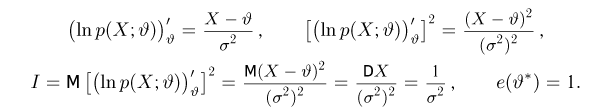
И в этом примере оценка является эффективной.
Пример:
Оценим неизвестную дисперсию 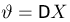 нормального закона при известном среднем т. Плотность нормального распределения представима в виде
нормального закона при известном среднем т. Плотность нормального распределения представима в виде
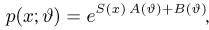
где
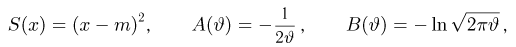
т.е. по отношению к неизвестной дисперсии принадлежит экспоненциальному семейству. Поэтому эффективная оценка дисперсии должна по формуле (8) иметь вид
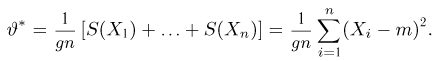
С другой стороны, нетрудно видеть, что 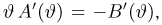 откуда следует несмещенность оценки
откуда следует несмещенность оценки
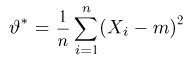
и, значит, ее эффективность. Впрочем, эффективность оценки легко установить и на основе неравенства Рао-Крамера.
Пусть теперь мы оцениваем не дисперсию, а среднее квадратичное отклонение 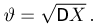 И в этом случае имеет место представление (7), только теперь
И в этом случае имеет место представление (7), только теперь
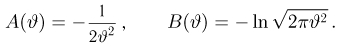
Поэтому равенство 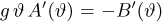 не превращается в тождество ни при каком выборе g, и, значит, эффективной (в смысле Рао-Крамера) оценки среднего квадратичного отклонения нормального закона не существует. Рассмотрим оценку
не превращается в тождество ни при каком выборе g, и, значит, эффективной (в смысле Рао-Крамера) оценки среднего квадратичного отклонения нормального закона не существует. Рассмотрим оценку
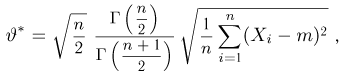
равную корню квадратному из оценки дисперсии с точностью до постоянного множителя 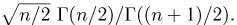 Читателю предлагается проверить, что оценка несмещенная. Кроме того, в следующем параграфе будет показано, что среди всех несмещенных оценок среднего квадратичного отклонения
Читателю предлагается проверить, что оценка несмещенная. Кроме того, в следующем параграфе будет показано, что среди всех несмещенных оценок среднего квадратичного отклонения 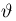 она имеет минимальную дисперсию (хотя и не является эффективной).
она имеет минимальную дисперсию (хотя и не является эффективной).
Пример:
Пусть выборка  произведена из генеральной совокупности с равномерным на интервале
произведена из генеральной совокупности с равномерным на интервале 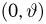 теоретическим распределением. Оценим неизвестный параметр Обозначим через
теоретическим распределением. Оценим неизвестный параметр Обозначим через 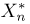 максимальный член вариационного ряда. В качестве оценки параметра возьмем
максимальный член вариационного ряда. В качестве оценки параметра возьмем
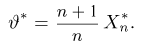
Функция распределения 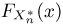 статистики
статистики 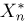 задается формулой
задается формулой
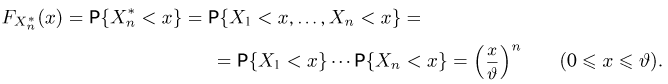
Тогда
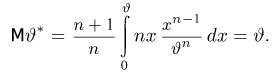
Значит, оценка несмещенная. Далее,
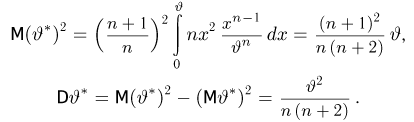
Мы видим, что дисперсия оценки при  убывает, как
убывает, как  Такая оценка оказалась более эффективной, поскольку дисперсия эффективной оценки убывает только, как 1 /п. Разгадка парадокса чрезвычайно проста: для данного семейства не выполнены условия регулярности, необходимые при доказательстве неравенства Рао-Крамера. Используя понятие достаточной статистики, в следующем параграфе мы докажем минимальность дисперсии данной оценки.
Такая оценка оказалась более эффективной, поскольку дисперсия эффективной оценки убывает только, как 1 /п. Разгадка парадокса чрезвычайно проста: для данного семейства не выполнены условия регулярности, необходимые при доказательстве неравенства Рао-Крамера. Используя понятие достаточной статистики, в следующем параграфе мы докажем минимальность дисперсии данной оценки.
В заключение этого параграфа отметим, что эффективные по Рао-Крамеру оценки существуют крайне редко. Правда, как мы увидим в параграфе 4, эффективность по Рао-Крамеру играет существенную роль в асимптотическом анализе оценок, получаемых методом максимального правдоподобия. Кроме того, существуют обобщения неравенства Рао-Крамера (например, неравенство Бхаттачария [7]), позволяющие доказывать оптимальность более широкого класса оценок.
В следующем параграфе мы рассмотрим другой подход к определению оценок с минимальной дисперсией, базирующийся на достаточных статистиках.
Наиболее распространенные методы нахождения оценок приводятся в параграфах 3-6.
Наконец, в параграфе 7 описан подход к построению доверительных интервалов для неизвестных параметров.
Достаточные оценки
Первый шаг в поисках другого (не основанного на неравенстве Рао-Крамера) принципа построения оценок с минимальной дисперсией состоит во введении понятия достаточной статистики (отметим, что достаточные статистики играют в современной математической статистике весьма важную роль, причем как при оценке неизвестных
параметров, так и при проверке статистических гипотез). Назовем k-мерную статистику
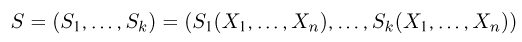
достаточной для параметра если условное распределение 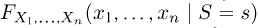 выборки
выборки 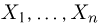 при условии
при условии 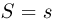 не зависит от параметра
не зависит от параметра
Пример:
Пусть 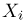 — число успехов в i-м испытании Бернулли (см. пример 1). Рассмотрим статистику
— число успехов в i-м испытании Бернулли (см. пример 1). Рассмотрим статистику
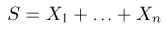
— общее число успехов в п испытаниях Бернулли. Покажем, что она является достаточной для вероятности успеха Для этого найдем условное распределение 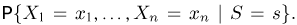 Воспользовавшись определением условной вероятности, получаем
Воспользовавшись определением условной вероятности, получаем
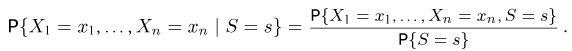
Если 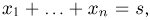 то вероятность
то вероятность 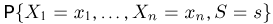 совпадает с вероятностью
совпадает с вероятностью 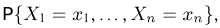 т.е.
т.е.
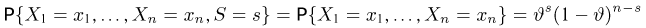
(напомним еще раз, что каждое 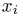 может принимать здесь только значение О или 1, причем
может принимать здесь только значение О или 1, причем 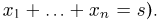 Поскольку вероятность
Поскольку вероятность 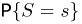 определяется формулой Бернулли
определяется формулой Бернулли
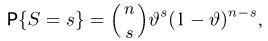
то из (9) получаем, что
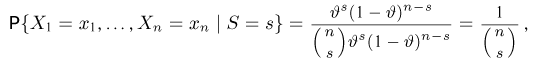
т. е. не зависит от Если же 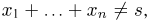 то
то
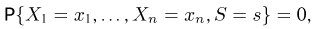
откуда
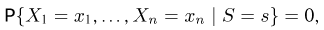
т. е. опять-таки не зависит от Таким образом, S — достаточная статистика.
Очевидно, что использовать приведенное выше определение для проверки достаточности конкретных статистик весьма сложно, особенно в непрерывном случае. Простой критерий достаточности задается следующей теоремой.
Теорема:
Факторизационная теорема Неймана-Фишера. Для того чтобы статистика 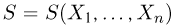 была достаточной для параметра необходимо и достаточно, чтобы ряд распределения
была достаточной для параметра необходимо и достаточно, чтобы ряд распределения
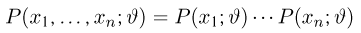
в дискретном случае или плотность распределения
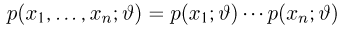
в непрерывном случае выборки были представимы в виде
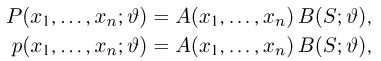
где функция  зависит только от
зависит только от 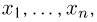 а функция
а функция 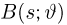 — только от
— только от 
Доказательство:
Для простоты изложения ограничимся только дискретным случаем. По определению условной вероятности,
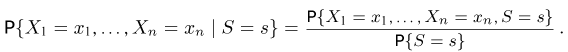
Очевидно, что числитель в правой части (II) совпадает с вероятностью  в том случае, когда
в том случае, когда 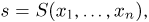 и равен нулю в противном. Поскольку событиями нулевой вероятности можно пренебречь, то ограничимся случаем
и равен нулю в противном. Поскольку событиями нулевой вероятности можно пренебречь, то ограничимся случаем 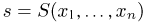 и запишем (11) в виде
и запишем (11) в виде
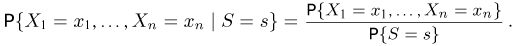
Теперь, если S — достаточная статистика, то левая часть (12) не зависит от Обозначая ее через 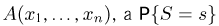 — через
— через 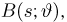 приходим к (10), что доказывает необходимость (10). И наоборот, пусть выполнено (10). Тогда
приходим к (10), что доказывает необходимость (10). И наоборот, пусть выполнено (10). Тогда
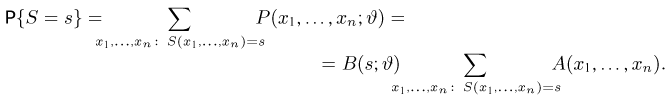
Подставляя последнее равенство в (12), имеем
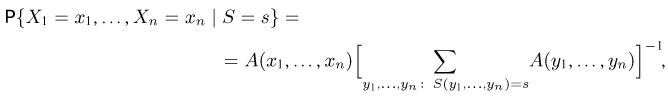
т.е. не зависит от а значит, статистика S является достаточной.
Замечание к теореме 2. Очевидно, что представление (10) справедливо с точностью до функции 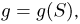 зависящей только от
зависящей только от 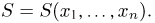
Пример:
Пусть  — выборка из генеральной совокупности с теоретической функцией распределения, являющейся нормальной со средним
— выборка из генеральной совокупности с теоретической функцией распределения, являющейся нормальной со средним 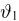 и дисперсией
и дисперсией 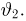 Покажем, что (двумерная) статистика
Покажем, что (двумерная) статистика  где
где
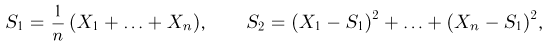
является достаточной для (двумерного) параметра 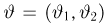 (см. также пример 3 из гл. 1). Действительно, плотность распределения
(см. также пример 3 из гл. 1). Действительно, плотность распределения 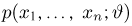 выборки
выборки  представима в виде
представима в виде
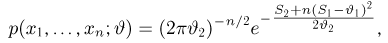
т.е. имеет вид (10), где
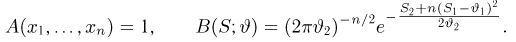
Пример:
Пусть  — выборка из генеральной совокупности с равномерным на интервале
— выборка из генеральной совокупности с равномерным на интервале 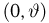 теоретическим распределением (см. пример 13). Покажем, что максимальный член вариационного ряда
теоретическим распределением (см. пример 13). Покажем, что максимальный член вариационного ряда
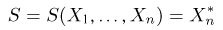
является (одномерной) достаточной статистикой для  Действительно, вспоминая, что плотность
Действительно, вспоминая, что плотность 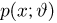 равномерно распределенной на интервале
равномерно распределенной на интервале 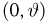 величины равна
величины равна 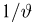 при
при 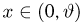 и нулю в противном случае, получаем для плотности распределения выборки
и нулю в противном случае, получаем для плотности распределения выборки  выражение
выражение
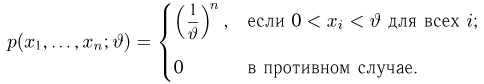
В частности, область изменения каждого аргумента 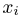 при отличной от нуля плотности распределения зависит от параметра
при отличной от нуля плотности распределения зависит от параметра 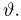 Рассмотрим функцию
Рассмотрим функцию
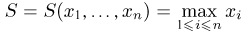
и положим
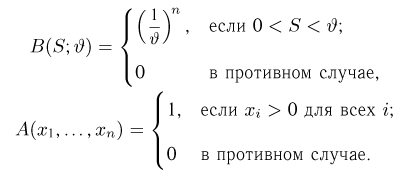
С учетом введенных функций.
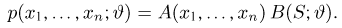
Здесь уже при определении функции 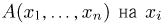 сверху не наложено никаких ограничений, поскольку они автоматически ограничены своим максимальным значением S, которое в свою очередь не превосходит Но это означает, что функция
сверху не наложено никаких ограничений, поскольку они автоматически ограничены своим максимальным значением S, которое в свою очередь не превосходит Но это означает, что функция  не зависит от параметра и в соответствии с теоремой 2 статистика
не зависит от параметра и в соответствии с теоремой 2 статистика

является достаточной для параметра
Пример:
Покажем, что для экспоненциального семейства (7) существует одномерная достаточная статистика. Этот факт легко установить, если подставить выражение (7) в формулу для плотности распределения выборки
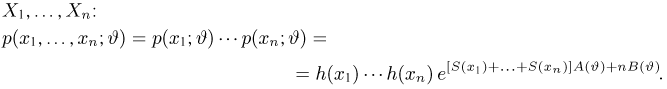
Полагая теперь
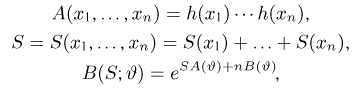
видим, что одномерная статистика
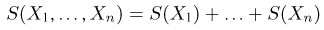
является достаточной для параметра
Как уже говорилось в гл. 1, смысл достаточной статистики S заключается в том, что она включает в себя всю ту информацию о неизвестном параметре которая содержится в исходной выборке  Интуиция подсказывает нам: оценка с наименьшей дисперсией (если она существует) должна зависеть только от достаточной статистики S. И действительно, следующий наш шаг будет заключаться в переходе от произвольной оценки к оценке
Интуиция подсказывает нам: оценка с наименьшей дисперсией (если она существует) должна зависеть только от достаточной статистики S. И действительно, следующий наш шаг будет заключаться в переходе от произвольной оценки к оценке 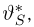 зависящей только от достаточной статистики S, причем этот переход совершится таким образом, чтобы дисперсия оценки
зависящей только от достаточной статистики S, причем этот переход совершится таким образом, чтобы дисперсия оценки 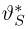 не превосходила дисперсии исходной оценки
не превосходила дисперсии исходной оценки 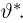
Начиная с этого момента и до конца параграфа будем для простоты предполагать, что неизвестный параметр является одномерным.
Пусть имеется некоторая оценка 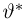 этого параметра, а также (произвольная) статистика S. Рассмотрим условное математическое ожидание
этого параметра, а также (произвольная) статистика S. Рассмотрим условное математическое ожидание 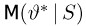 случайной величины при условии S (см. часть 1, гл. 7, параграф 5). Следующее утверждение, играющее основную роль в наших рассуждениях, было получено независимо Д. Блекуэлом, М.М. Рао и А.Н. Колмогоровым.
случайной величины при условии S (см. часть 1, гл. 7, параграф 5). Следующее утверждение, играющее основную роль в наших рассуждениях, было получено независимо Д. Блекуэлом, М.М. Рао и А.Н. Колмогоровым.
Теорема:
Улучшение оценки по достаточной статистике. Пусть S — достаточная статистика, а — несмещенная оценка параметра Тогда условное математическое ожидание 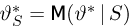 является несмещенной оценкой параметра
является несмещенной оценкой параметра 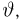 зависящей только от достаточной статистики S и удовлетворяющей неравенству
зависящей только от достаточной статистики S и удовлетворяющей неравенству
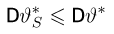
при всех 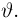
Доказательство:
В силу достаточности статистики 5 условное распределение, а значит, и условное математическое ожидание оценки при условии S не зависит от неизвестного параметра (для произвольной статистики S функция вообще говоря, может зависеть от т.е. 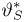 представляет собой оценку параметра причем зависящую только от S. Далее, из равенства
представляет собой оценку параметра причем зависящую только от S. Далее, из равенства
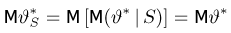
для условного математического ожидания немедленно следует несмещенность оценки
Наконец,
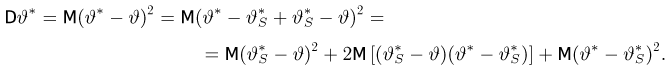
Используя опять свойство условного математического ожидания, получаем
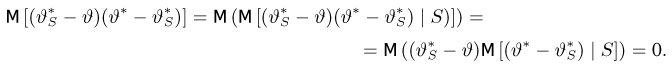
Поэтому
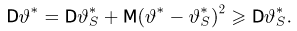
Замечание:
Неравенство (13) превращается для некоторого  в равенство тогда и только тогда, когда
в равенство тогда и только тогда, когда 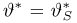 (почти всюду по мере
(почти всюду по мере 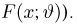
Замечание:
Утверждение теоремы остается в силе и для смещенной оценки В частности, 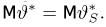
Смысл теоремы 3 заключается в том, что взятие условного математического ожидания, т. е. переход к оценке зависящей только от достаточной статистики S, не ухудшает любую оценку при всех значениях неизвестного параметра
Пример:
Пусть 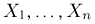 — выборка из нормально распределенной генеральной совокупности с неизвестным средним и известной дисперсией
— выборка из нормально распределенной генеральной совокупности с неизвестным средним и известной дисперсией 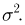 В примере 9 было показано, что оценка
В примере 9 было показано, что оценка 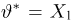 даже не является состоятельной оценкой хотя она и несмещенная. Рассмотрим статистику
даже не является состоятельной оценкой хотя она и несмещенная. Рассмотрим статистику
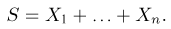
Нетрудно показать, что статистика S является достаточной для параметра Поэтому мы можем определить новую оценку 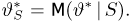 Для ее вычисления заметим, что величины
Для ее вычисления заметим, что величины 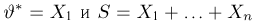 имеют двумерное нормальное распределение со средними
имеют двумерное нормальное распределение со средними 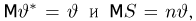 дисперсиями
дисперсиями 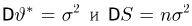 и ковариацией
и ковариацией 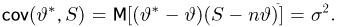 Но тогда, как известно из курса теории вероятностей, условное распределение при условии S = s также является нормальным со средним значением
Но тогда, как известно из курса теории вероятностей, условное распределение при условии S = s также является нормальным со средним значением 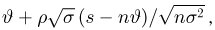 как раз и представляющим собой значение
как раз и представляющим собой значение 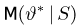 при S = s. Поскольку коэффициент корреляции
при S = s. Поскольку коэффициент корреляции 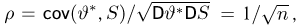 то среднее значение условного распределения совпадает с s/n и окончательно получаем
то среднее значение условного распределения совпадает с s/n и окончательно получаем
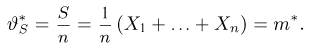
Иными словами, мы из совсем плохой оценки 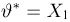 получили эффективную (см. пример 11) оценку
получили эффективную (см. пример 11) оценку 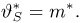
Рассмотренный пример приоткрывает нам те возможности, которые несет с собой теорема 3. Однако, прежде чем сделать последний шаг, введем еще одно определение. Назовем статистику 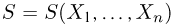 полной для семейства распределений
полной для семейства распределений 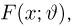 если из того, что
если из того, что
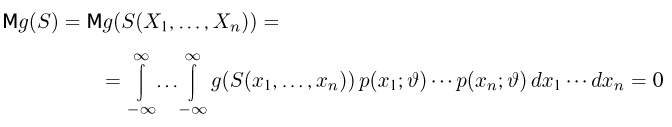
при всех (мы для простоты предположили существование плотности распределения 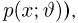 следует, что функция
следует, что функция  тождественно равна нулю. Теперь мы в состоянии сформулировать окончательный итог наших поисков.
тождественно равна нулю. Теперь мы в состоянии сформулировать окончательный итог наших поисков.
Теорема:
Минимальность дисперсии оценки, зависящей от полной достаточной статистики. Пусть S — полная достаточная статистика, — несмещенная оценка неизвестного параметра Тогда
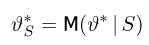
является единственной несмещенной оценкой с минимальной дисперсией.
Доказательство теоремы немедленно вытекает из предыдущих результатов. Действительно, в силу теоремы 3 оценка с минимальной дисперсией обязательно должна находиться среди оценок, зависящих только от достаточной статистики S; в противном случае ее можно было бы улучшить с помощью условного математического ожидания. Но среди оценок, зависящих только от S, может быть максимум одна несмещенная. В самом деле, если таких оценок две: 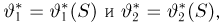 то функция
то функция
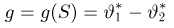
имеет при всех значениях математическое ожидание
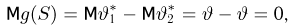
что в силу полноты статистики S влечет за собой равенство 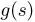 нулю. Само же существование несмещенной оценки
нулю. Само же существование несмещенной оценки 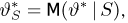 зависящей только от S, гарантируется существованием просто несмещенной оценки
зависящей только от S, гарантируется существованием просто несмещенной оценки 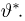
Перейдем к обсуждению полученных результатов.
Условие полноты статистики S, как мы видим, сводится к единственности несмещенной оценки зависящей только от статистики S. Нам не известно общих теорем, которые давали бы простые правила проверки полноты произвольной статистики S. Однако, как мы увидим из примеров, в конкретных случаях кустарные способы обычно дают хорошие результаты.
Сравнение размерностей полной статистики S и оцениваемого параметра дает право говорить, что, как правило, статистика S должна иметь ту же размерность, что и а поскольку мы ограничились одномерным параметром то S также должна быть одномерной. Это приводит к следующим полезным определениям. Оценка называется достаточной, если она является достаточной как одномерная статистика. Аналогично, назовем оценку полной, если она является полной статистикой.
Сформулируем очевидное следствие из теоремы 4. которое удобно применять во многих частных случаях.
Следствие из теоремы 4. Если оценка несмещенная и зависит только от полной достаточной статистики S, то она имеет минимальную дисперсию.
Пример:
Пусть  — выборка из генеральной совокупности, распределенной по нормальному закону с известным средним m и неизвестным средним квадратичным отклонением
— выборка из генеральной совокупности, распределенной по нормальному закону с известным средним m и неизвестным средним квадратичным отклонением 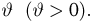 Нетрудно показать, что статистика
Нетрудно показать, что статистика
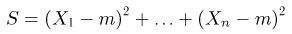
является достаточной для параметра Покажем, что она также полная. Для этого вспомним (см. параграф 4 гл. 1), что случайная величина 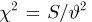 имеет
имеет 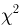 -распределение с п степенями свободы, а значит, статистика
-распределение с п степенями свободы, а значит, статистика 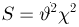 имеет плотность распределения
имеет плотность распределения
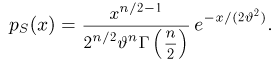
Пусть теперь 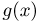 — такая функция, что
— такая функция, что 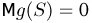 при всех Положим
при всех Положим
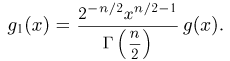
Тогда
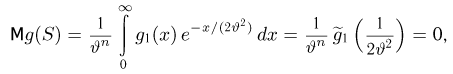
что 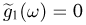 для всех
для всех 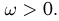 Но из теории преобразований Лапласа известно, что в этом случае оригинал
Но из теории преобразований Лапласа известно, что в этом случае оригинал 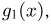 а значит, и функция
а значит, и функция 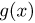 также должны тождественно равняться нулю, что и доказывает полноту статистики S.
также должны тождественно равняться нулю, что и доказывает полноту статистики S.
Рассмотрим теперь оценку
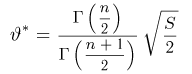
(см. пример 12) неизвестного среднего квадратичного отклонения 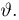 Эта оценка несмещенная и зависит только от полной достаточной статистики S. Поэтому по следствию из теоремы 4 она имеет минимальную дисперсию, хотя, как было показано в примере 12, и не является эффективной по Рао-Крамеру.
Эта оценка несмещенная и зависит только от полной достаточной статистики S. Поэтому по следствию из теоремы 4 она имеет минимальную дисперсию, хотя, как было показано в примере 12, и не является эффективной по Рао-Крамеру.
Пример:
Рассмотрим оценку
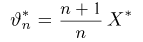
параметра равномерного на интервале 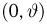 распределения (см. пример 13). В примере 13 показано, что эта оценка несмещенная. Статистика
распределения (см. пример 13). В примере 13 показано, что эта оценка несмещенная. Статистика 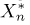 является достаточной (см. пример 16). Покажем, наконец, что — полная статистика. Действительно, для любой функции
является достаточной (см. пример 16). Покажем, наконец, что — полная статистика. Действительно, для любой функции
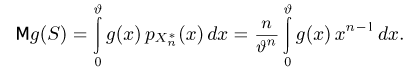
Отсюда, в частности, следует, что если 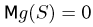 при всех то
при всех то
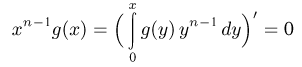
при всех х. Поэтому 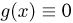 и статистика полная.
и статистика полная.
Таким образом, в силу следствия из теоремы 4 и в этом примере оценка имеет минимальную дисперсию.
Метод моментов
Пусть мы имеем выборку  из генеральной совокупности с теоретической функцией распределения F(x), принадлежащей k-параметрическому семейству
из генеральной совокупности с теоретической функцией распределения F(x), принадлежащей k-параметрическому семейству 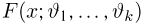 с неизвестными параметрами
с неизвестными параметрами 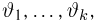 которые нужно оценить. Поскольку нам известен вид теоретической функции распределения, мы можем вычислить первые k теоретических моментов. Эти моменты, разумеется, будут зависеть от k неизвестных параметров
которые нужно оценить. Поскольку нам известен вид теоретической функции распределения, мы можем вычислить первые k теоретических моментов. Эти моменты, разумеется, будут зависеть от k неизвестных параметров 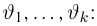
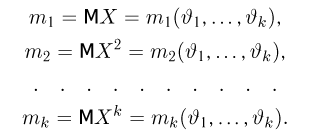
Суть метода моментов заключается в следующем: так как выборочные моменты являются состоятельными оценками теоретических моментов (см. пример 8), мы можем в написанной системе равенств при большом объеме выборки п теоретические моменты  заменить на выборочные
заменить на выборочные 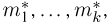 а затем, решая эту систему относительно
а затем, решая эту систему относительно 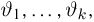 найти оценки неизвестных параметров. Таким образом, в методе моментов оценки
найти оценки неизвестных параметров. Таким образом, в методе моментов оценки  неизвестных параметров
неизвестных параметров  определяются из системы уравнений
определяются из системы уравнений
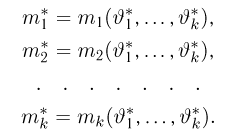
Можно показать, что при условии непрерывной зависимости решения этой системы от начальных условий 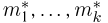 оценки, полученные методом моментов, будут состоятельными. Более того, справедлива следующая теорема.
оценки, полученные методом моментов, будут состоятельными. Более того, справедлива следующая теорема.
Теорема:
Асимптотическая нормальность оценок, полученных методом моментов. При некоторых условиях, наложенных на семейство 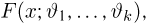 совместное распределение случайных величин
совместное распределение случайных величин
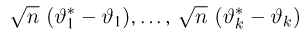
при 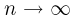 сходится к (многомерному) нормальному закону с нулевыми средними и матрицей ковариаций, зависящей от теоретических моментов
сходится к (многомерному) нормальному закону с нулевыми средними и матрицей ковариаций, зависящей от теоретических моментов  и матрицы
и матрицы 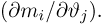
Доказательство:
Будем полагать, что выполнены следующие условия: а) параметры  однозначно определяются своими моментами
однозначно определяются своими моментами 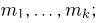
б) существует теоретический момент 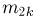 порядка 2k (это эквивалентно существованию дисперсий у выборочных моментов
порядка 2k (это эквивалентно существованию дисперсий у выборочных моментов 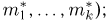
в) функция
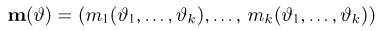
дифференцируема по 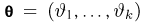 с отличным от нуля якобианом
с отличным от нуля якобианом 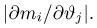
Доказательство теоремы проведем для одномерного случая, предоставляя общий случай читателю. Оно является комбинацией следующих результатов: теоремы о дифференцируемости обратного отображения и центральной предельной теоремы. Действительно, поскольку существует дисперсия DX, то при каждом истинном значении 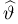 параметра
параметра 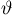 в силу центральной предельной теоремы выборочное среднее
в силу центральной предельной теоремы выборочное среднее
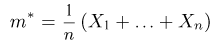
асимптотически при 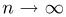 распределено по нормальному закону с параметрами
распределено по нормальному закону с параметрами 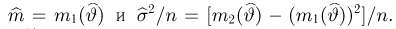 С другой стороны, сама оценка записывается в виде
С другой стороны, сама оценка записывается в виде
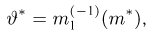
где 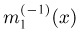 — обратная к
— обратная к 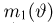 функция. В силу сделанных предположений обратное отображение
функция. В силу сделанных предположений обратное отображение 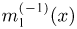 в окрестности точки
в окрестности точки 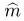 приближенно представляет собой линейную функцию
приближенно представляет собой линейную функцию
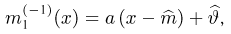
причем 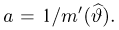 Но тогда и случайная величина
Но тогда и случайная величина 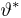 как приближенно линейное преобразование приближенно нормальной случайной величины
как приближенно линейное преобразование приближенно нормальной случайной величины 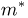 распределена приближенно по нормальному закону со средним
распределена приближенно по нормальному закону со средним 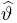 и дисперсией
и дисперсией 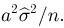 Это доказывает утверждение теоремы.
Это доказывает утверждение теоремы.
Пример:
Найдем методом моментов оценку неизвестной вероятности успеха 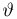 в схеме Бернулли. Поскольку в схеме Бернулли только один неизвестный параметр, для его определения необходимо приравнять теоретическое математическое ожидание числа успехов в одном испытании
в схеме Бернулли. Поскольку в схеме Бернулли только один неизвестный параметр, для его определения необходимо приравнять теоретическое математическое ожидание числа успехов в одном испытании 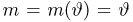 выборочному среднему
выборочному среднему 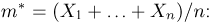
Итак, оценка 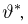 полученная методом моментов, представляет собой наблюденную частоту успехов. Свойства этой оценки были нами достаточно полно исследованы в примерах 1, 4, 7 и 10.
полученная методом моментов, представляет собой наблюденную частоту успехов. Свойства этой оценки были нами достаточно полно исследованы в примерах 1, 4, 7 и 10.
Пример:
Выборка  произведена из генеральной совокупности с теоретической функцией распределения, имеющей гамма-плотность
произведена из генеральной совокупности с теоретической функцией распределения, имеющей гамма-плотность
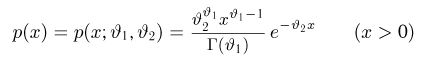
с двумя неизвестными параметрами 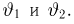 Первые два момента случайной величины X, имеющей гамма-распределение, задаются формулами:
Первые два момента случайной величины X, имеющей гамма-распределение, задаются формулами:
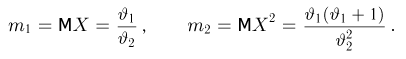
Отсюда для определения оценок 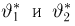 неизвестных параметров
неизвестных параметров 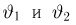 получаем систему двух уравнений:
получаем систему двух уравнений:
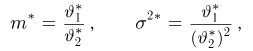
решение которой имеет вид
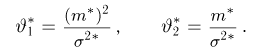
Вообще говоря, в методе моментов не обязательно использовать первые k моментов. Более того, можно рассматривать моменты не обязательно целого порядка. Иногда для использования в методе моментов привлекают более или менее произвольные функции  сравнивая выборочные средние
сравнивая выборочные средние
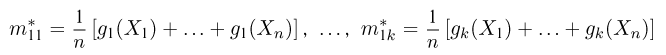
функций 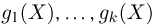 с теоретическими средними
с теоретическими средними
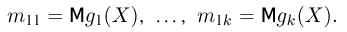
Пример:
Пусть выборка 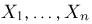 произведена из нормальной генеральной совокупности с известным средним т и неизвестной дисперсией Попробуем для оценивания применить метод моментов, взяв выборочное среднее
произведена из нормальной генеральной совокупности с известным средним т и неизвестной дисперсией Попробуем для оценивания применить метод моментов, взяв выборочное среднее 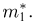 Но теоретическое среднее
Но теоретическое среднее 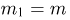 не зависит от параметра Это означает, что использование выборочного среднего для оценивания неизвестной дисперсии неправомочно и нужно привлекать моменты других порядков. В частности, применяя второй выборочный момент
не зависит от параметра Это означает, что использование выборочного среднего для оценивания неизвестной дисперсии неправомочно и нужно привлекать моменты других порядков. В частности, применяя второй выборочный момент 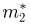 и вспоминая, что
и вспоминая, что 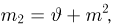 получаем оценку
получаем оценку
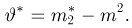
Следует отметить, что оценки, полученные методом моментов, обычно имеют эффективность существенно меньше единицы и даже являются смещенными. Иногда из-за своей простоты они используются в качестве начального приближения для нахождения более эффективных оценок.
Метод максимального правдоподобия
Метод максимального правдоподобия является наиболее распространенным методом нахождения оценок. Пусть по-прежнему выборка 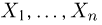 произведена из генеральной совокупности с неизвестной теоретической функцией распределения F(x), принадлежащей известному однопараметрическому семейству
произведена из генеральной совокупности с неизвестной теоретической функцией распределения F(x), принадлежащей известному однопараметрическому семейству 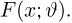 Функция
Функция
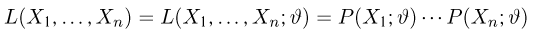
в дискретном случае и
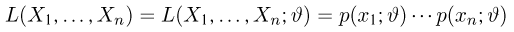
в непрерывном называется функцией правдоподобия. Отметим,что в функции правдоподобия 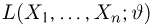 элементы выборки
элементы выборки  являются фиксированными параметрами, а
являются фиксированными параметрами, а 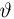 — аргументом (а не истинным значением неизвестного параметра). Функция правдоподобия по своей сути представляет собой не что иное, как вероятность (в непрерывном случае плотность распределения) получить именно ту выборку
— аргументом (а не истинным значением неизвестного параметра). Функция правдоподобия по своей сути представляет собой не что иное, как вероятность (в непрерывном случае плотность распределения) получить именно ту выборку  которую мы реально имеем, если бы значение неизвестного параметра равнялось Естественно поэтому в качестве оценки неизвестного параметра выбрать
которую мы реально имеем, если бы значение неизвестного параметра равнялось Естественно поэтому в качестве оценки неизвестного параметра выбрать 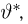 доставляющее наибольшее значение функции правдоподобия
доставляющее наибольшее значение функции правдоподобия 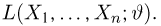 Оценкой максимального правдоподобия называется такое значение
Оценкой максимального правдоподобия называется такое значение 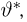 для которого
для которого
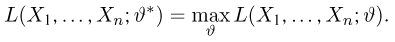
При практической реализации метода максимального правдоподобия удобно пользоваться не самой функцией правдоподобия, а ее логарифмом.
Уравнением правдоподобия называется уравнение
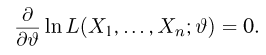
Если функция правдоподобия дифференцируема по в каждой точке, то оценку максимального правдоподобия следует искать среди значений удовлетворяющих уравнению правдоподобия или принадлежащих границе области допустимых значений . Для наиболее важных семейств 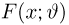 уравнение правдоподобия имеет единственное решение которое и является оценкой максимального правдоподобия.
уравнение правдоподобия имеет единственное решение которое и является оценкой максимального правдоподобия.
Пример:
Найдем оценку неизвестной вероятности успеха в схеме Бернулли, но теперь уже в отличие от примера 21 методом максимального правдоподобия. Поскольку 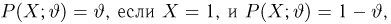 если X = 0, то функцию правдоподобия можно записать так:
если X = 0, то функцию правдоподобия можно записать так:
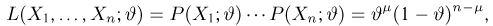
где 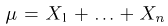 — суммарное число успехов в п испытаниях. Тогда уравнение правдоподобия принимает вид
— суммарное число успехов в п испытаниях. Тогда уравнение правдоподобия принимает вид
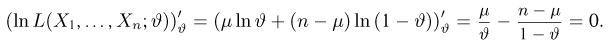
Решая это уравнение, имеем
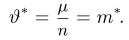
Поскольку
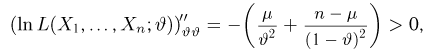
то  представляет собой выпуклую вверх функцию Значит, доставляет максимум функции правдоподобия
представляет собой выпуклую вверх функцию Значит, доставляет максимум функции правдоподобия 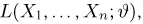 т.е. является оценкой максимального правдоподобия. Эта оценка представляет собой, как и в примере 21, наблюденную частоту успехов.
т.е. является оценкой максимального правдоподобия. Эта оценка представляет собой, как и в примере 21, наблюденную частоту успехов.
Оказывается, имеется тесная связь между эффективными оценками и оценками, полученными методом максимального правдоподобия. А именно, справедлива следующая теорема.
Теорема:
Совпадение эффективной оценки с оценкой максимального правдоподобия. Если (естественно, при условиях регулярности теоремы 1) существует эффективная оценка 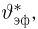 то она является оценкой максимального правдоподобия
то она является оценкой максимального правдоподобия 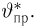
Доказательство теоремы 6 представляет собой дальнейшее уточнение доказательства теоремы 1. Действительно, как следует из замечания 1 к теореме 1, из существования эффективной оценки 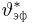 вытекает (6) и (8)
вытекает (6) и (8) 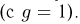 Отсюда и из (4) следует равенство
Отсюда и из (4) следует равенство
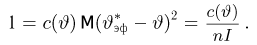
Поэтому из условия строгой положительности информации I вытекает строгая положительность 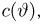 которая в свою очередь влечет за собой единственность решения
которая в свою очередь влечет за собой единственность решения
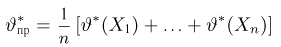
уравнения правдоподобия
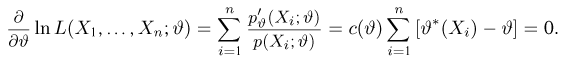
Это решение совпадает с эффективной оценкой  и задает единственный максимум функции правдоподобия
и задает единственный максимум функции правдоподобия 
В общем случае оценка максимального правдоподобия может быть не только неэффективной, но и смещенной. Тем не менее она обладает свойством асимптотической эффективности в следующем смысле.
Теорема:
Асимптотическая эффективность оценки максимального правдоподобия. При некоторых условиях на семейство  уравнение правдоподобия имеет решение, при
уравнение правдоподобия имеет решение, при 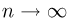 асимптотически распределенное по нормальному закону со средним и дисперсией
асимптотически распределенное по нормальному закону со средним и дисперсией 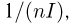 где I — информация Фишера.
где I — информация Фишера.
Доказательство:
Сначала сформулируем условия теоремы (см. [9]), которые, как мы увидим далее, гарантируют возможность дифференцируемости под знаком интеграла и разложения 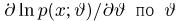 в ряд Тейлора до первого члена:
в ряд Тейлора до первого члена:
а) для (почти) всех х существуют производные
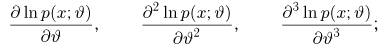
б) при всех справедливы неравенства
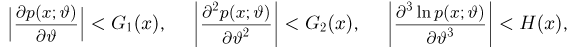
где функции 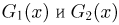 интегрируемы на
интегрируемы на 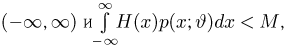 причем M не зависит от
причем M не зависит от
в) информация I конечна и положительна для всех
Обозначим через 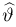 истинное значение неизвестного параметра
истинное значение неизвестного параметра 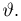 В силу условий теоремы справедливо следующее разложение
В силу условий теоремы справедливо следующее разложение 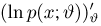 в окрестности
в окрестности 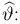
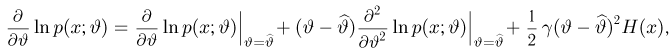
причем 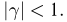 Тогда после умножения на
Тогда после умножения на 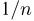 уравнение правдоподобия можно записать в виде
уравнение правдоподобия можно записать в виде
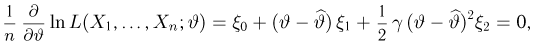
где случайные величины  определяются выражениями
определяются выражениями
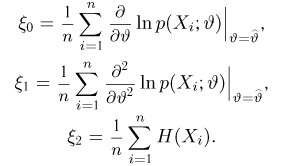
Рассмотрим поведение  при больших п. Дифференцируя (1) по
при больших п. Дифференцируя (1) по  получаем
получаем
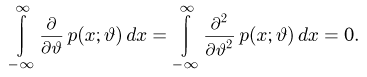
Поэтому
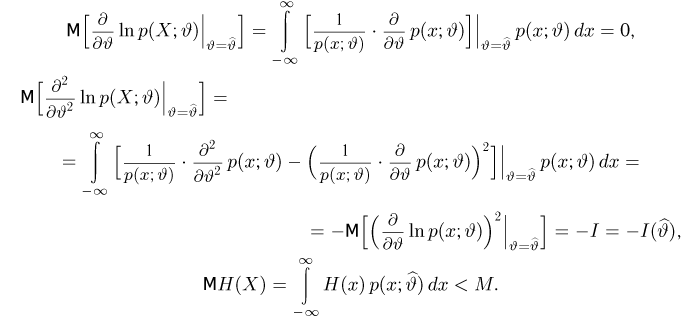
Вернемся к уравнению (14) и воспользуемся сначала тем фактом, что при 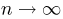 в силу закона больших чисел
в силу закона больших чисел  причем, согласно условиям теоремы,
причем, согласно условиям теоремы,  Тогда можно показать, что уравнение (14) будет в некоторой окрестности
Тогда можно показать, что уравнение (14) будет в некоторой окрестности 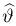 иметь асимптотически единственное решение
иметь асимптотически единственное решение 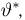 которое к тому же определяется приближенной формулой
которое к тому же определяется приближенной формулой
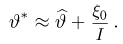
Величина 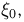 по центральной предельной теореме, при имеет асимптотически нормальное распределение с нулевым средним и дисперсией
по центральной предельной теореме, при имеет асимптотически нормальное распределение с нулевым средним и дисперсией 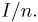
Поэтому оценка 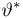 также асимптотически распределена по нормальному закону с параметрами
также асимптотически распределена по нормальному закону с параметрами 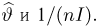
Замечание:
Доказанная теорема гарантирует, что среди всех решений уравнения правдоподобия существует по крайней мере одно обладающее свойством асимптотической эффективности в указанном смысле. Более того, такое решение асимптотически единственно в некоторой окрестности точки 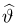 (т. е. вероятность того, что в этой окрестности имеется другое решение уравнения правдоподобия, с ростом п стремится к нулю) и именно оно доставляет локальный максимум функции правдоподобия в этой окрестности. Но с самого начала мы назвали оценкой максимального правдоподобия оценку, доставляющую глобальный максимум функции правдоподобия. Такая оценка, вообще говоря, может не совпадать с и даже быть неединственной. Однако если семейство распределений
(т. е. вероятность того, что в этой окрестности имеется другое решение уравнения правдоподобия, с ростом п стремится к нулю) и именно оно доставляет локальный максимум функции правдоподобия в этой окрестности. Но с самого начала мы назвали оценкой максимального правдоподобия оценку, доставляющую глобальный максимум функции правдоподобия. Такая оценка, вообще говоря, может не совпадать с и даже быть неединственной. Однако если семейство распределений 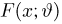 удовлетворяет естественному свойству разделимости, смысл которого сводится к тому, что для достаточно удаленных друг от друга
удовлетворяет естественному свойству разделимости, смысл которого сводится к тому, что для достаточно удаленных друг от друга 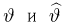 распределения
распределения 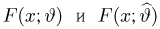 также достаточно хорошо отличаются друг от друга, то любая оценка максимального правдоподобия будет состоятельной, т.е. стремиться к оцениваемому параметру. Вкупе с доказанной теоремой это означает асимптотическую единственность оценки максимального правдоподобия и совпадение ее с что позволяет при асимптотическом анализе свойств оценки максимального правдоподобия говорить не об одном из решений уравнения правдоподобия или даже не об одной из оценок максимального правдоподобия, а просто об оценке максимального правдоподобия Детальный разбор этого явления можно найти в [И]. Там же показано, что для оценки близости распределений удобно использовать расстояние Кульбака-Лейблера
также достаточно хорошо отличаются друг от друга, то любая оценка максимального правдоподобия будет состоятельной, т.е. стремиться к оцениваемому параметру. Вкупе с доказанной теоремой это означает асимптотическую единственность оценки максимального правдоподобия и совпадение ее с что позволяет при асимптотическом анализе свойств оценки максимального правдоподобия говорить не об одном из решений уравнения правдоподобия или даже не об одной из оценок максимального правдоподобия, а просто об оценке максимального правдоподобия Детальный разбор этого явления можно найти в [И]. Там же показано, что для оценки близости распределений удобно использовать расстояние Кульбака-Лейблера
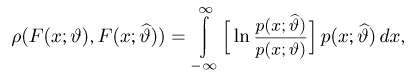
поскольку в силу закона больших чисел именно к расстоянию Кульбака-Лейблера при 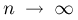 сходится с точностью до знака, постоянной
сходится с точностью до знака, постоянной
здесь 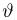 — аргумент функции правдоподобия, а
— аргумент функции правдоподобия, а 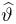 — истинное значение неизвестного параметра.
— истинное значение неизвестного параметра.
В случае, когда семейство 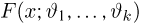 зависит от нескольких неизвестных параметров
зависит от нескольких неизвестных параметров 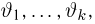 при использовании метода максимального правдоподобия нужно искать максимум функции правдоподобия или ее логарифма по k аргументам
при использовании метода максимального правдоподобия нужно искать максимум функции правдоподобия или ее логарифма по k аргументам 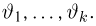 Уравнение правдоподобия превращается в систему уравнений
Уравнение правдоподобия превращается в систему уравнений
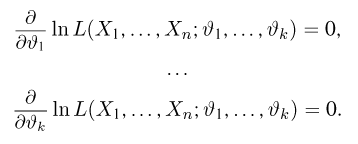
Пример:
Выборка  произведена из нормальной генеральной совокупности с неизвестными параметрами
произведена из нормальной генеральной совокупности с неизвестными параметрами 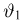 (среднее) и
(среднее) и 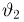 (дисперсия). Найдем их оценки
(дисперсия). Найдем их оценки 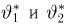 методом максимального правдоподобия. Логарифм функции правдоподобия задается формулой
методом максимального правдоподобия. Логарифм функции правдоподобия задается формулой
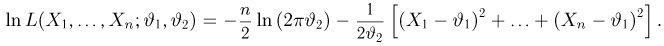
Система уравнений правдоподобия имеет вид
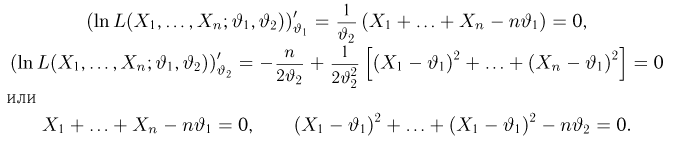
Таким образом,
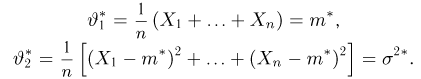
Читателю предлагается самостоятельно показать, что 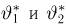 доставляют максимум функции правдоподобия
доставляют максимум функции правдоподобия 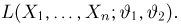 Оценки
Оценки 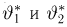 параметров
параметров 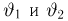 совпадают с выборочным средним
совпадают с выборочным средним 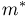 и выборочной дисперсией
и выборочной дисперсией 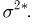 Отметим, что оценка
Отметим, что оценка 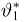 неизвестного математического ожидания
неизвестного математического ожидания 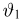 является эффективной (см. пример 11), чего нельзя сказать об оценке
является эффективной (см. пример 11), чего нельзя сказать об оценке 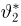 неизвестной дисперсии
неизвестной дисперсии 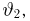 которая, как мы знаем, является даже смещенной.
которая, как мы знаем, является даже смещенной.
Оказывается, однако, что если мы в качестве оценки параметра 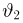 рассмотрим выборочную дисперсию
рассмотрим выборочную дисперсию 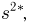 то эта оценка будет уже не только несмещенной, но и иметь минимальную дисперсию среди всех несмещенных оценок параметра
то эта оценка будет уже не только несмещенной, но и иметь минимальную дисперсию среди всех несмещенных оценок параметра 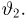 Последний факт вытекает из неравенства Бхаттачария [7], обобщающего неравенство Рао-Крамера, а также может быть установлен из свойств многомерных достаточных оценок [11].
Последний факт вытекает из неравенства Бхаттачария [7], обобщающего неравенство Рао-Крамера, а также может быть установлен из свойств многомерных достаточных оценок [11].
Метод минимального расстояния
Суть этого метода заключается в следующем. Предположим, что любым двум функциям распределения 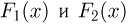 поставлено в соответствие число
поставлено в соответствие число
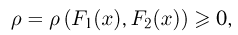
называемое расстоянием, причем 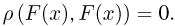 Пусть теперь, как обычно, задана выборка
Пусть теперь, как обычно, задана выборка  из генеральной совокупности с теоретической функцией распределения F(x), принадлежащей параметрическому семейству
из генеральной совокупности с теоретической функцией распределения F(x), принадлежащей параметрическому семейству  Вычислим расстояние между эмпирической функцией распределения
Вычислим расстояние между эмпирической функцией распределения 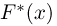 и функциями распределения
и функциями распределения 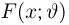 из данного семейства. Оценкой, полученной методом минимального расстояния, называется такое значение
из данного семейства. Оценкой, полученной методом минимального расстояния, называется такое значение 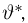 для которого
для которого
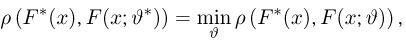
т. е. такое значение 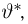 которое определяет ближайшую к
которое определяет ближайшую к 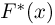 в смысле расстояния р функцию распределения из семейства
в смысле расстояния р функцию распределения из семейства 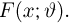
Приведем примеры некоторых наиболее часто встречающихся в математической статистике расстояний.
Равномерное расстояние (расстояние Колмогорова) определяется формулой
Расстояние 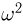 имеет вид
имеет вид
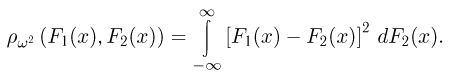
Расстояние  употребляется для функций распределения
употребляется для функций распределения  дискретных случайных величин
дискретных случайных величин 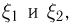 принимающих одинаковые значения
принимающих одинаковые значения 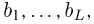 и задается выражением
и задается выражением
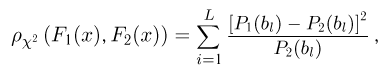
где вероятности 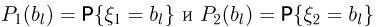 определяются рядами распределения случайных величин
определяются рядами распределения случайных величин 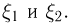
Использование приведенных выше расстояний для получения оценок весьма сложно в вычислительном плане, и поэтому они употребляются крайне редко. Здесь мы упомянули об этих расстояниях только потому, что применение оценок, полученных с их помощью, позволяет упростить вычисление уровней значимости критериев при проверке сложных непараметрических статистических гипотез, поскольку такие оценки естественным образом связаны с соответствующими критериями (см. параграф 5 гл. 3).
Метод номограмм
Еще одним методом, позволяющим, пользуясь только номограммами (специальным образом разлинованными листами бумаги, которые в математической статистике носят название вероятностной бумаги), весьма просто и быстро оценить неизвестные параметры, является метод номограмм. Его сущность состоит в следующем. Пусть мы имеем выборку  из генеральной совокупности с неизвестной теоретической функцией распределения, принадлежащей двухпараметрическому семейству
из генеральной совокупности с неизвестной теоретической функцией распределения, принадлежащей двухпараметрическому семейству 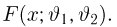 Предположим теперь, что каким-то чрезвычайно простым способом удалось построить функцию распределения
Предположим теперь, что каким-то чрезвычайно простым способом удалось построить функцию распределения 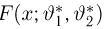 из семейства
из семейства 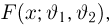 достаточно хорошо приближающую эмпирическую функцию распределения
достаточно хорошо приближающую эмпирическую функцию распределения 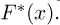 Тогда
Тогда 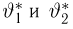 будут являться оценками неизвестных параметров
будут являться оценками неизвестных параметров 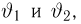 причем в силу теоремы Гливенко-Кантелли состоятельными при весьма слабых условиях, накладываемых на семейство
причем в силу теоремы Гливенко-Кантелли состоятельными при весьма слабых условиях, накладываемых на семейство 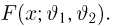
Казалось бы, мы пришли к не менее сложной задаче: найти «чрезвычайно простой» способ приближения эмпирической функции распределения функцией распределения из семейства 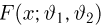 Оказывается, однако, что графики функций распределения тех семейств в которых
Оказывается, однако, что графики функций распределения тех семейств в которых 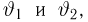 по сути дела, связаны с параметрами «сдвига» и «масштаба» (к таким семействам относятся, например, нормальное, логнормальное и т.д.), можно с помощью некоторых нелинейных преобразований координат превратить в семейство прямых линий. Тогда, построив в этих новых координатах график эмпирической функции распределения
по сути дела, связаны с параметрами «сдвига» и «масштаба» (к таким семействам относятся, например, нормальное, логнормальное и т.д.), можно с помощью некоторых нелинейных преобразований координат превратить в семейство прямых линий. Тогда, построив в этих новых координатах график эмпирической функции распределения 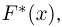 нетрудно визуально провести прямую, которая достаточно хорошо приближает
нетрудно визуально провести прямую, которая достаточно хорошо приближает 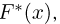 а затем уже по коэффициентам проведенной прямой найти оценки
а затем уже по коэффициентам проведенной прямой найти оценки 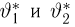 и неизвестных параметров
и неизвестных параметров 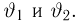
Практическая реализация метода номограмм происходит следующим образом. Сначала выборку 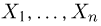 преобразуют в вариационный ряд
преобразуют в вариационный ряд 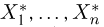 и на номограмме для соответствующего семейства
и на номограмме для соответствующего семейства 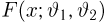 откладывают точки
откладывают точки 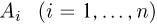 с координатами
с координатами 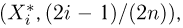 абсциссы которых
абсциссы которых 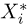 представляют собой точки скачков эмпирической функции распределения
представляют собой точки скачков эмпирической функции распределения 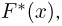 а ординаты
а ординаты 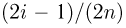 — середины этих скачков. Затем «на глаз» проводят прямую линию, проходящую как можно ближе ко всем точкам
— середины этих скачков. Затем «на глаз» проводят прямую линию, проходящую как можно ближе ко всем точкам 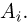 Наконец, с помощью пояснений к номограмме по коэффициентам прямой находят оценки
Наконец, с помощью пояснений к номограмме по коэффициентам прямой находят оценки 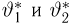 неизвестных параметров
неизвестных параметров 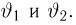
Пример 26. Предполагая в примере 1 из гл. 1, что проекция вектора скорости молекул водорода распределена по нормальному закону, оценим с помощью метода номограмм неизвестное математическое ожидание 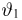 и дисперсию
и дисперсию 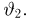 Воспользовавшись вариационным рядом выборки, найдем координаты точек
Воспользовавшись вариационным рядом выборки, найдем координаты точек 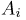 (табл.3). Отложим точки на номограмме для нормального распределения (на нормальной вероятностной бумаге) и проведем «на глаз» прямую А, задаваемую уравнением
(табл.3). Отложим точки на номограмме для нормального распределения (на нормальной вероятностной бумаге) и проведем «на глаз» прямую А, задаваемую уравнением 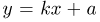 (рис. 1).
(рис. 1).
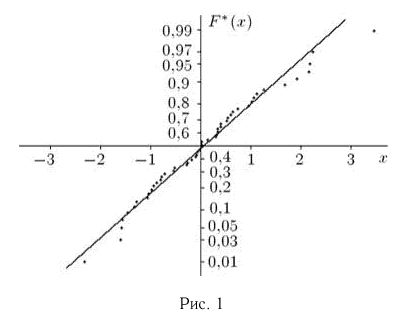
Оценка  математического ожидания совпадает с точкой пересечения прямой А с осью абсцисс, т. е.
математического ожидания совпадает с точкой пересечения прямой А с осью абсцисс, т. е.  Для того чтобы найти оценку дисперсии
Для того чтобы найти оценку дисперсии 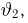 определим значение коэффициента
определим значение коэффициента 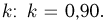 Тогда
Тогда 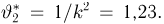 Для сравнения приведем значения оценок этих же параметров, полученные методом максимального
Для сравнения приведем значения оценок этих же параметров, полученные методом максимального
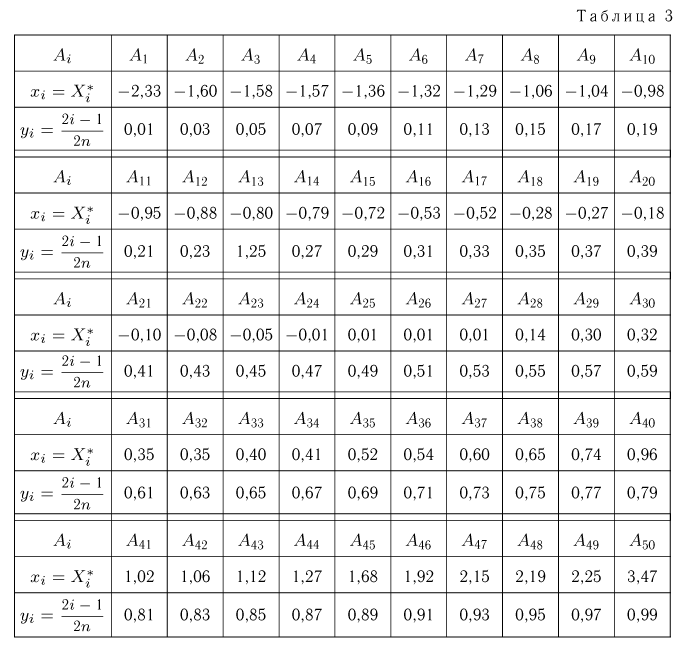
правдоподобия (см. пример 18, а также пример 8 из гл. 1): 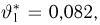
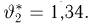 Как видим, оценки весьма близки.
Как видим, оценки весьма близки.
Следует отметить, что с помощью метода номограмм можно судить также о правильности выбора семейства 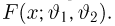 Действительно, по множеству точек
Действительно, по множеству точек  сразу видно, группируются они вокруг некоторой прямой или нет. Если нет, то возникают серьезные сомнения в принадлежности теоретического распределения F(x) семейству
сразу видно, группируются они вокруг некоторой прямой или нет. Если нет, то возникают серьезные сомнения в принадлежности теоретического распределения F(x) семейству 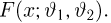
Доверительные интервалы
Полученные в предыдущих параграфах оценки неизвестных параметров естественно называть точечными, поскольку они оценивают неизвестный параметр одним числом или точкой. Однако, как мы знаем, точечная оценка не совпадает с оцениваемым параметром и более разумно было бы указывать те допустимые границы, в которых может находиться неизвестный параметр 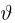 при наблюденной выборке
при наблюденной выборке 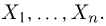 К сожалению, в подавляющем большинстве важных для практики случаев при любой выборке
К сожалению, в подавляющем большинстве важных для практики случаев при любой выборке  достоверная область, в которой может находиться неизвестный параметр
достоверная область, в которой может находиться неизвестный параметр 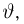 совпадает со всей возможной областью изменения этого параметра, поскольку такую выборку мы можем получить с ненулевой вероятностью (или плотностью распределения) при каждом значении
совпадает со всей возможной областью изменения этого параметра, поскольку такую выборку мы можем получить с ненулевой вероятностью (или плотностью распределения) при каждом значении 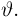 Поэтому приходится ограничиваться нахождением границ изменения неизвестного параметра с некоторой наперед заданной степенью доверия или доверительной вероятностью.
Поэтому приходится ограничиваться нахождением границ изменения неизвестного параметра с некоторой наперед заданной степенью доверия или доверительной вероятностью.
Доверительной вероятностью назовем такую вероятность 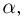 что событие вероятности
что событие вероятности 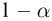 можно считать невозможным. Разумеется, выбор доверительной вероятности полностью зависит от исследователя, причем во внимание принимаются не только его личные наклонности, но и физическая суть рассматриваемого явления. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки. В математической статистике обычно используют значения доверительной вероятности 0,9, 0,95, 0,99, реже 0,999, 0,9999 и т. д.
можно считать невозможным. Разумеется, выбор доверительной вероятности полностью зависит от исследователя, причем во внимание принимаются не только его личные наклонности, но и физическая суть рассматриваемого явления. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки. В математической статистике обычно используют значения доверительной вероятности 0,9, 0,95, 0,99, реже 0,999, 0,9999 и т. д.
Задавшись доверительной вероятностью 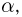 мы уже можем по выборке определить интервал
мы уже можем по выборке определить интервал 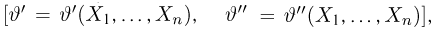 в котором будет находиться неизвестный параметр Такой интервал называется доверительным интервалом (иногда также говорят «интервальная оценка») доверительной вероятности для неизвестного параметра Отметим, что доверительная вероятность а ни в коей мере не является вероятностью неизвестному параметру
в котором будет находиться неизвестный параметр Такой интервал называется доверительным интервалом (иногда также говорят «интервальная оценка») доверительной вероятности для неизвестного параметра Отметим, что доверительная вероятность а ни в коей мере не является вероятностью неизвестному параметру 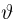 принадлежать доверительному интервалу
принадлежать доверительному интервалу 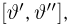 поскольку, как мы предположили с самого начала, априорные сведения о параметре в частности о его распределении, отсутствуют. Когда говорят, что неизвестный параметр не может выйти за границу доверительного интервала
поскольку, как мы предположили с самого начала, априорные сведения о параметре в частности о его распределении, отсутствуют. Когда говорят, что неизвестный параметр не может выйти за границу доверительного интервала 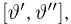 констатируют только, что если при любом истинном значении в результате эксперимента получена выборка а затем по ней построен доверительный интервал то этот интервал с вероятностью накроет значение
констатируют только, что если при любом истинном значении в результате эксперимента получена выборка а затем по ней построен доверительный интервал то этот интервал с вероятностью накроет значение
Доверительные интервалы определим, следуя Ю. Нейману, опираясь на точечные оценки. По заданной оценке 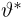 доверительные интервалы доверительной вероятности а можно построить различными способами. На практике обычно используют два типа доверительных интервалов: симметричные и односторонние. Ограничимся описанием процедуры построения симметричных доверительных интервалов. Односторонние доверительные интервалы находятся совершенно аналогично.
доверительные интервалы доверительной вероятности а можно построить различными способами. На практике обычно используют два типа доверительных интервалов: симметричные и односторонние. Ограничимся описанием процедуры построения симметричных доверительных интервалов. Односторонние доверительные интервалы находятся совершенно аналогично.
Итак, пусть у нас имеется выборка  из генеральной совокупности с неизвестной теоретической функцией распределения F(x), принадлежащей однопараметрическому семейству
из генеральной совокупности с неизвестной теоретической функцией распределения F(x), принадлежащей однопараметрическому семейству 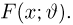 Предположим также, что нами выбрана некоторая оценка по которой мы хотим построить симметричный доверительный интервал доверительной вероятности
Предположим также, что нами выбрана некоторая оценка по которой мы хотим построить симметричный доверительный интервал доверительной вероятности  Для этого возьмем произвольное значение и найдем функцию распределения
Для этого возьмем произвольное значение и найдем функцию распределения 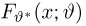 оценки Определим
оценки Определим 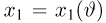 и
и 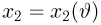 из решения уравнений (см. рис. 2):
из решения уравнений (см. рис. 2):
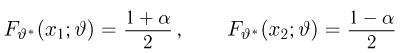
(напомним, что  носят название
носят название 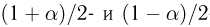 -квантилей функции распределения
-квантилей функции распределения 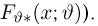 Таким образом, при заданном оценка будет с вероятностью заключена в интервале
Таким образом, при заданном оценка будет с вероятностью заключена в интервале  причем вероятность попадания как влево, так и вправо от интервала
причем вероятность попадания как влево, так и вправо от интервала  имеет одно и то же значение
имеет одно и то же значение 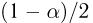 (отсюда происходит название «симметричный»). Откладывая теперь на графике рис. 3 по оси абсцисс значение параметра а по оси ординат — соответствующие ему значения
(отсюда происходит название «симметричный»). Откладывая теперь на графике рис. 3 по оси абсцисс значение параметра а по оси ординат — соответствующие ему значения 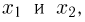 получим кривые
получим кривые 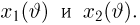 В силу принципа невозможности события, происходящего с вероятностью 1 — а, заключаем, что все возможные пары
В силу принципа невозможности события, происходящего с вероятностью 1 — а, заключаем, что все возможные пары 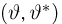 могут находиться только внутри области G между кривыми
могут находиться только внутри области G между кривыми 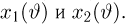 Для окончания построения доверительного интервала остается заметить, что, получив по выборке
Для окончания построения доверительного интервала остается заметить, что, получив по выборке  оценку
оценку 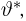 мы вправе сделать вывод: неизвестный параметр в обязан лежать внутри интервала где
мы вправе сделать вывод: неизвестный параметр в обязан лежать внутри интервала где 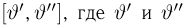 определяются из решения уравнений
определяются из решения уравнений

Именно интервал 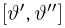 и является симметричным доверительным интервалом доверительной вероятности
и является симметричным доверительным интервалом доверительной вероятности
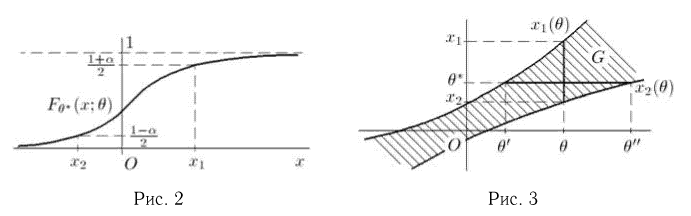
Пример 27. Построим симметричный доверительный интервал доверительной вероятности а для неизвестной вероятности успеха в схеме Бернулли. Естественно в качестве оценки взять наблюденную частоту
где  — суммарное наблюденное число успехов (см. пример 24).
— суммарное наблюденное число успехов (см. пример 24).
При малом объеме выборки п процедура построения доверительных интервалов трудоемка, поскольку она практически сводится к перебору значений неизвестного параметра. Поэтому существуют специальные таблицы (см. [1], табл. 5.2), которые по наблюденным значениям числа успехов и числа неудач  дают границы доверительного интервала доверительной вероятности а.
дают границы доверительного интервала доверительной вероятности а.
При больших объемах выборки п пользуются тем фактом, что в силу интегральной теоремы Муавра-Лапласа оценка распределена приближенно по нормальному закону со средним и дисперсией 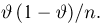 Тогда решения уравнений
Тогда решения уравнений
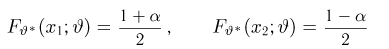
связаны с 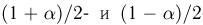 -квантилями
-квантилями 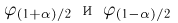 (см. [1], табл. 1.3) стандартного нормального закона формулами
(см. [1], табл. 1.3) стандартного нормального закона формулами
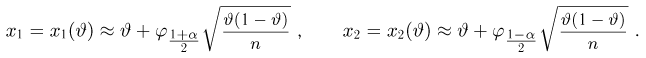
Учитывая, что 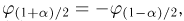 уравнения кривых
уравнения кривых  можно записать в единой эквивалентной форме
можно записать в единой эквивалентной форме
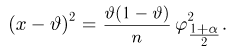
Последнее уравнение, как нетрудно видеть, представляет собой уравнение эллипса (рис. 4) (физически непонятный выход эллипса за полосу 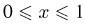 связан с тем, что при близких к нулю или единице, необходимо в соответствии с теоремой Пуассона использовать не нормальную, а пуассоновскую аппроксимацию оценки
связан с тем, что при близких к нулю или единице, необходимо в соответствии с теоремой Пуассона использовать не нормальную, а пуассоновскую аппроксимацию оценки 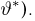 Уравнение для определения границ
Уравнение для определения границ 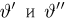 доверительного интервала имеет вид
доверительного интервала имеет вид
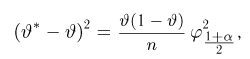
откуда окончательно получаем
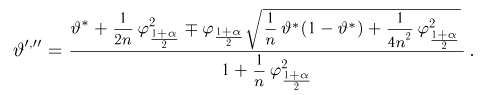
Пример:
Построим симметричный доверительный интервал доверительной вероятности а для неизвестного среднего нормального закона при известной дисперсии 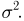 Эффективной оценкой
Эффективной оценкой 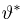 параметра как мы знаем (пример 18), является выборочное среднее
параметра как мы знаем (пример 18), является выборочное среднее
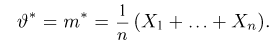
Оценка 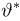 также распределена по нормальному закону с параметрами
также распределена по нормальному закону с параметрами  Поэтому
Поэтому
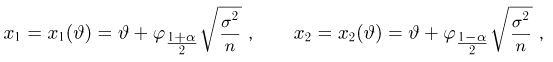
т.е.  представляют собой уравнения двух параллельных прямых (рис. 5). Решая уравнения получаем границы доверительного интервала
представляют собой уравнения двух параллельных прямых (рис. 5). Решая уравнения получаем границы доверительного интервала 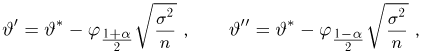 или, учитывая, что
или, учитывая, что 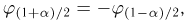
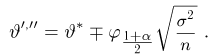
Пример:
Как и в предыдущем примере, предположим, что выборка  произведена из нормальной генеральной совокупности, но с неизвестной дисперсией
произведена из нормальной генеральной совокупности, но с неизвестной дисперсией 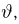 а среднее известно и равно т. В качестве оценки
а среднее известно и равно т. В качестве оценки 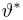 неизвестной дисперсии возьмем выборочную дисперсию
неизвестной дисперсии возьмем выборочную дисперсию
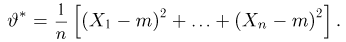
Тогда случайная величина 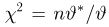 будет иметь
будет иметь 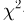 -распределение с п степенями свободы, а значит, решения уравнений
-распределение с п степенями свободы, а значит, решения уравнений
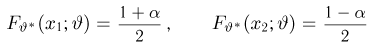
определяются формулами
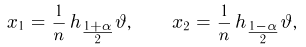
где  — а-квантиль -распределения с п степенями свободы (см. [1], табл. 2.26). Уравнения
— а-квантиль -распределения с п степенями свободы (см. [1], табл. 2.26). Уравнения
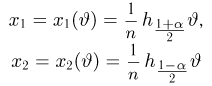
представляют собой уравнения двух лучей, исходящих из начала координат (рис.6), и, значит, границы симметричного доверительного интервала доверительной вероятности а для неизвестной дисперсии 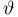 задаются формулами
задаются формулами
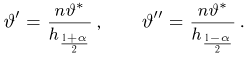
Пример:
Рассмотрим, наконец, случай, когда в выборке из нормальной генеральной совокупности неизвестны оба параметра: среднее 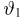 и дисперсия
и дисперсия  В качестве их оценок воспользуемся выборочным средним
В качестве их оценок воспользуемся выборочным средним
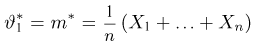
и выборочной дисперсией
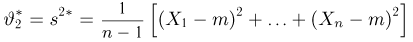
(см. пример 25).
Построение доверительного интервала  для неизвестного среднего начнем с определения случайной величины
для неизвестного среднего начнем с определения случайной величины
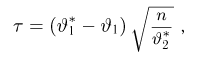
которая, как говорилось в параграфе 4 гл. 1, имеет t-распределение с п — 1 степенями свободы. Обозначим через 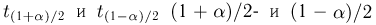 -квантили t-распределения (см. [1], табл. 3.2). Тогда значение оценки среднего с вероятностью а будет лежать в пределах
-квантили t-распределения (см. [1], табл. 3.2). Тогда значение оценки среднего с вероятностью а будет лежать в пределах
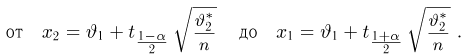
Продолжая рассуждения, как и в случае известной дисперсии, и учитывая равенство  получаем окончательные выражения для границ
получаем окончательные выражения для границ 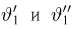 симметричного доверительного интервала доверительной вероятности a:
симметричного доверительного интервала доверительной вероятности a:
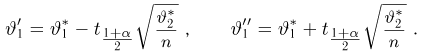
Доверительный интервал 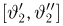 доверительной вероятности а для неизвестной дисперсии
доверительной вероятности а для неизвестной дисперсии 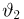 строится точно так же, как и в примере 29:
строится точно так же, как и в примере 29:
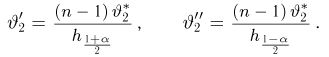
При этом нужно учитывать, что квантили 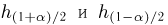 берутся для
берутся для 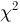 -распределения с
-распределения с 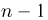 степенями свободы, поскольку одна степень свободы уходит на определение неизвестного среднего
степенями свободы, поскольку одна степень свободы уходит на определение неизвестного среднего 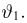
В заключение отметим, что в современной математической статистике доверительные интервалы строят так же, основываясь на критериях значимости.
Решение заданий и задач по предметам:
- Теория вероятностей
- Математическая статистика
Дополнительные лекции по теории вероятностей:
- Случайные события и их вероятности
- Случайные величины
- Функции случайных величин
- Числовые характеристики случайных величин
- Законы больших чисел
- Статистические оценки
- Статистическая проверка гипотез
- Статистическое исследование зависимостей
- Теории игр
- Вероятность события
- Теорема умножения вероятностей
- Формула полной вероятности
- Теорема о повторении опытов
- Нормальный закон распределения
- Определение законов распределения случайных величин на основе опытных данных
- Системы случайных величин
- Нормальный закон распределения для системы случайных величин
- Вероятностное пространство
- Классическое определение вероятности
- Геометрическая вероятность
- Условная вероятность
- Схема Бернулли
- Многомерные случайные величины
- Предельные теоремы теории вероятностей
- Генеральная совокупность
