Алгоритм Дейкстры. Разбор Задач
Время на прочтение
7 мин
Количество просмотров 36K
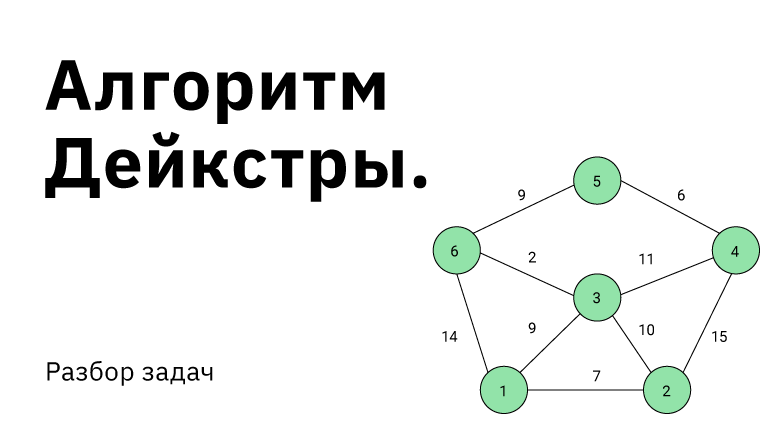
Поиск оптимального пути в графе. Такая задача встречается довольно часто и в повседневной жизни, и в мире технологий. Справиться с такими вызовами помогает подход, который должен быть в арсенале каждого программиста — алгоритм Дейкстры.
Если вы хотите найти ответить на вопросы, чем этот алгоритм лучше BFS (поиска в ширину), при каких условиях алгоритм применим, и какие теоретические и практические задачи можно с его помощью решать, читайте далее.
Введение
Алгоритм Дейкстры работает на ориентированных (с некоторыми дополнениями и на неориентированных) графах, и призван искать кратчайшие пути между заданной вершиной и всеми остальными вершинами в графе.
Как правило, граф обозначают как набор вершин и рёбер  где число рёбер может быть задано
где число рёбер может быть задано  , а вершин числом
, а вершин числом 
Для каждого ребра в графе задан неотрицательный вес  , а также вершина, из которой осуществляется поиск оптимальных путей.
, а также вершина, из которой осуществляется поиск оптимальных путей.
Алгоритм Дейкстры может найти кратчайший путь между вершинами  и
и  в графе, только если существует хотя бы один путь между этими вершинами. Если это условие не выполняется, то алгоритм отработает корректно, вернув значение «бесконечность» для пары несвязанных вершин.
в графе, только если существует хотя бы один путь между этими вершинами. Если это условие не выполняется, то алгоритм отработает корректно, вернув значение «бесконечность» для пары несвязанных вершин.
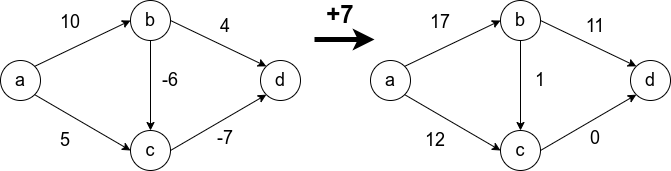
Условие неотрицательности весов рёбер крайне важно и от него нельзя просто избавиться. Не получится свести задачу к решаемой алгоритмом Дейкстры, прибавив наибольший по модулю вес ко всем рёбрам. Это может изменить оптимальный маршрут. На рисунке видно, что в первом случае оптимальный путь между  и
и  (сумма рёбер на пути наименьшая) изменяется при такой манипуляции. В оригинале путь проходит через
(сумма рёбер на пути наименьшая) изменяется при такой манипуляции. В оригинале путь проходит через  , а после добавления семёрки ко всем рёбрам, оптимальный путь проходит через
, а после добавления семёрки ко всем рёбрам, оптимальный путь проходит через 
Как ведёт себя алгоритм Дейкстры на исходном графе, мы разберём, когда выпишем алгоритм. Но для начала зададимся другим вопросом: «почему не применить поиск в ширину для нашего графа?». Известно, что метод BFS находит оптимальный путь от произвольной вершины в ориентированном графе до любой другой вершины, но это справедливо только для рёбер с единичным весом.
Свести задачу к решаемой BFS можно, но если заменить все рёбра неединичной длины  рёбрами длины
рёбрами длины  , то граф очень разрастётся, и это приведёт к огромному числу действий при вычислении оптимального маршрута.
, то граф очень разрастётся, и это приведёт к огромному числу действий при вычислении оптимального маршрута.
Чтобы этого избежать предлагается использовать алгоритм Дейкстры. Опишем его:
Инициализация:
Основный цикл алгоритма:
- Пока все вершины не исследованы (или формально
 ), повторяем:
), повторяем:
 ), повторяем:
), повторяем:
В итоге исполнения этого алгоритма, массив  будет содержать все оптимальные пути, исходящие из .
будет содержать все оптимальные пути, исходящие из .
Примеры работы
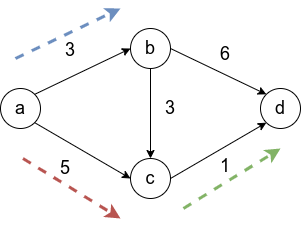
Рассмотрим граф выше, в нём будем искать пути от до всего остального.
Первый шаг алгоритма определит, что кратчайший путь до  проходит по направлению синей стрелки и зафиксирует кратчайший путь. Второй шаг рассмотрит, все возможные варианты
проходит по направлению синей стрелки и зафиксирует кратчайший путь. Второй шаг рассмотрит, все возможные варианты ![inline A[v] + l_{vw}](https://habrastorage.org/getpro/habr/post_images/c10/6ca/2df/c106ca2df0651dd2d791b59d6959e8fb.svg) и окажется, что оптимальный вариант двигаться вдоль красной стрелки, поскольку
и окажется, что оптимальный вариант двигаться вдоль красной стрелки, поскольку  меньше, чем
меньше, чем  и
и  Добавляется длина кратчайшего пути до
Добавляется длина кратчайшего пути до  . И наконец, третьим шагом, когда три вершины
. И наконец, третьим шагом, когда три вершины  уже лежат в
уже лежат в  , остается рассмотреть только два ребра и выбрать, лежащее вдоль зеленой стрелки.
, остается рассмотреть только два ребра и выбрать, лежащее вдоль зеленой стрелки.
Теперь рассмотрим граф с отрицательными весами, упомянутый выше. Напомню, алгоритм Дейкстры на таком графе может работать некорректно.
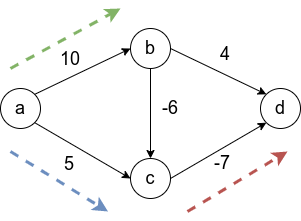
Первым шагом отбирается ребро вдоль синей стрелки, поскольку это ребро наименьшего веса из исходной вершины. Затем выбирается ребро  Это зафиксирует навсегда неверный путь от к , в то время как оптимальный путь проходит через центр с отрицательным весом. Последним шагом, будет добавлена вершина .
Это зафиксирует навсегда неверный путь от к , в то время как оптимальный путь проходит через центр с отрицательным весом. Последним шагом, будет добавлена вершина .
Оценка сложности алгоритма
К этому моменту мы разобрали сам алгоритм, ограничения, накладываемые на его работу и ряд примеров его применения. Давайте упомянем какова вычислительная сложность этого алгоритма, поскольку это пригодится нам для решения задач, ради которых затевалась эта статья.
Базовый подход, основанный на циклах, предполагает проход по всем рёбрам каждого узла, что приводит к сложности  .
.
Эффективная реализация предполагает использование кучи. Об этой структуре данных можно сказать коротко: она позволяет выполнять две операции за логарифмическое время. Первая операция — получение узла в дереве, с наименьшим ключом, и, вторая операция, вставка нового узла в дерево с новым ключом.
Что еще можно сказать о куче:
- это сбалансированное бинарное дерево,
- ключ текущего узла всегда меньше, либо равен ключей дочерних узлов.
Интересную задачу с использованием куч я разбирал ранее в этом посте.
Используя кучу в алгоритме Дейкстры, где в качестве ключей используются расстояния от вершины в неисследованной части графа (в алгоритме это  ), до ближайшей вершины в уже покрытом (это множество вершин ), можно сократить вычислительную сложность до
), до ближайшей вершины в уже покрытом (это множество вершин ), можно сократить вычислительную сложность до  Доказательство справедливости этих оценок я оставляю за пределами этой статьи.
Доказательство справедливости этих оценок я оставляю за пределами этой статьи.
Далее перейдём к разбору задач!
Задача №1
Будем называть узким местом пути в графе ребро максимальной длины в этом пути. Путём с минимальным узким местом назовём такой путь между вершинами и , что не существует другого пути  , чьё узкое место меньше по длине. Требуется построить алгоритм, который вычисляет путь с минимальным узким местом для двух данных вершин в графе. Асимптотическая сложность такого алгоритма должна быть
, чьё узкое место меньше по длине. Требуется построить алгоритм, который вычисляет путь с минимальным узким местом для двух данных вершин в графе. Асимптотическая сложность такого алгоритма должна быть 
Решение
По условию задачи ребро с большим весом трактуется как узкое место. Вес в этом случае можно воспринимать как цену за проход по ребру. В результате решения задачи хотелось бы получить алгоритм, способный строить маршруты между узлами так, чтобы, если мы захотим провести любой другой путь, он будет содержать более тяжелые рёбра.
В случае классической задачи, поиска пути минимальной длины между двумя вершинами графа, мы поддерживаем в каждой посещенной алгоритмом вершине графа минимальную длину пути до этой вершины. Здесь стоит оговориться, что будем именовать множество посещенными вершинами, а часть графа, для которой еще нужно найти величину пути или узкого места.
В отличии от классического алгоритма, решение этой задачи должно поддерживать величину актуального узкого места пути, приводящего в вершину  . А при добавлении новой вершины из , мы должны смотреть не увеличивает ли ребро
. А при добавлении новой вершины из , мы должны смотреть не увеличивает ли ребро  величину узкого места пути, которое теперь приводит в
величину узкого места пути, которое теперь приводит в  .
.
Если ребро увеличивает узкое место, то лучше рассмотреть вершину  , ребро
, ребро  до которой легче . Поиск неувеличивающих узкое место ребёр нужно осуществлять не только среди соседей определенного узла
до которой легче . Поиск неувеличивающих узкое место ребёр нужно осуществлять не только среди соседей определенного узла  , но и среди всех , поскольку отдавая предпочтение вершине, путь в которую имеет наименьшее узкое место в данный момент, мы гарантируем, что мы не ухудшаем ситуацию для других вершин.
, но и среди всех , поскольку отдавая предпочтение вершине, путь в которую имеет наименьшее узкое место в данный момент, мы гарантируем, что мы не ухудшаем ситуацию для других вершин.
Последнее можно проиллюстрировать примером: если путь, оканчивающийся в вершине  имеет узкое место величины
имеет узкое место величины  , и есть вершина
, и есть вершина  с ребром
с ребром  веса
веса  , и
, и  с ребром
с ребром  веса , то предпочтение отдаётся , алгоритм даст верный результат в обоих случая, если существует
веса , то предпочтение отдаётся , алгоритм даст верный результат в обоих случая, если существует  веса или веса
веса или веса  .
.
В результате разбора выше, предлагается руководствоваться следующей формулой при выборе очередной вершины из непосещенных и обновлении величин, которые мы поддерживаем.
![A(u) = min_{v in X}left(max left[A(v), wleft(v,uright)right]right), , u in V - X](https://habrastorage.org/getpro/habr/post_images/6bf/459/cbd/6bf459cbdc59a4ffaf8b7bfe68ed0f27.svg)
Стоит пояснить, что поиск по осуществляется, только для существующих связей  а
а  это вес ребра
это вес ребра  .
.
Задача №2
Предлагается решить более практическую задачу. Пусть городов, между ними существуют пути, заданные массивом edges[i] = [city_a, city_b, distance_ab], а также дано целое число mileage.
Требуется найти такой город из данных, из которого можно добраться до наименьшего числа городов не превысив mileage.
Стоит отметить, что граф неориентированый, т.е. по пути между городами можно двигаться в обе стороны, а длина пути между городами a и c может быть получена как сумма длин путей a -> b и b -> c, если есть маршрут a -> b -> c
Решение
С решением данной проблемы нам поможет алгоритм Дейкстры и описанная выше реализация с помощью кучи. Поставщиком этой структуры данных станет библиотека heapq в Python.
Будем использовать алгоритм Дейкстры для того, чтобы подсчитать количество соседних городов, расстояние до которых меньше mileage, для каждого из городов. Соберем количества соседей в в одном месте и найдем минимум из них.
Поскольку наш граф неориентированный, то из любой его вершины можно добраться до произвольной вершины . Будем использовать алгоритм Дейкстры для того, чтобы для каждого из городов в графе построить кратчайшие пути до всех остальных городов, мы это уже умеем делать в теории. И чтобы, оптимизировать этот процесс, будем в его течении сразу отвергать пути, которые превышают mileage, а не делать постфактум, когда все пути получены.
Давайте опишем функцию решения:
def least_reachable_city(n, edges, mileage):
"""
входные параметры:
n --- количество городов,
edges --- тройки (a, b, distance_ab),
mileage --- максимально допустимое расстояние между городами
для соседства
"""
# заполняем список смежности (adjacency list), в нашем случае это
# словарь, в котором ключи это города, а значения --- пары
# (<другой_город>, <расстояние_до_него>)
graph = {}
for u, v, w in edges:
if graph.get(u, None) is None:
graph[u] = [(v, w)]
else:
graph[u].append((v, w))
if graph.get(v, None) is None:
graph[v] = [(u, w)]
else:
graph[v].append((u, w))
# локально объявим функцию, которая будет считать кратчайшие пути в
# графе от вершины, до всех вершин, удовлетворяющих условию
def num_reachable_neighbors(city):
# создаем кучу, из одного элемента с парой, задающей нулевую
# длину пути до самого исходного города
heap = [(0, city)]
# и массив, содержащий города и кратчайшие
# расстояния до них от исходного
distances = {}
# затем, пока куча не пуста, извлекаем ближайший
# от посещенных городов город
while heap:
currDist, neighb = heapq.heappop(heap)
# если кратчайшее ребро ведет к городу, где мы уже знаем
# оптимальный маршрут, то завершаем итерацию
if neighb in distances:
continue
# в остальных случаях, и если сосед не является отправным
# городом, мы добавляем новую запись в массив кратчайших расстояний
if neighb != city:
distances[neighb] = currDist
# обрабатываем всех смежных городов с соседом, добавляя их в кучу
# но только если: а) до них еще не известен кратчайший маршрут и б) путь до них через neighb не выходит за пределы mileage
for node, d in graph[neighb]:
if node in distances:
continue
if currDist + d <= mileage:
heapq.heappush(heap, (currDist + d, node))
# возвращаем количество городов, прошедших проверку
return len(distances)
# выполним поиск соседей для каждого из городов
cities_neighbors = {num_reachable_neighbors(city): city for city in range(n)}
# вернём номер города, у которого наименьшее число соседей
# в пределах досигаемости
return cities_neighbors[min(cities_neighbors)]
В функции выше, в комментариях, подробно описывается, как метод Дейкстры, реализованный на куче позволяет найти расстояния до всех городов, в пределах `mileage`. Основную сложность для понимания предстваляет цикл, работающий с кучей.
Заключение
Алгоритм Дейкстры это мощный инструмент в мире работы с графами, область применения его крайне широка. С его помощью можно оценить даже целесообразность добавления новой ветки метро, новой дороги или маршрута в компьютерной сети. Он прост в исполнении и интуитивно понятен, как другие жадные (greedy) алгоритмы. Вычислительная сложность решений задач с его помощью зачастую не выше  . При некоторых условиях может достигать линейной сложности (существует алгоритм линейной сложности, решающий первую задачу, при условии, что граф неориентированный).
. При некоторых условиях может достигать линейной сложности (существует алгоритм линейной сложности, решающий первую задачу, при условии, что граф неориентированный).
Стоит еще раз отметить, что алгоритм не работает, когда в графе существуют отрицательные веса. Для этого существует подход динамического программирования — алгоритм Беллмана – Форда, что может послужить темой другой статьи. Несмотря на это, алгоритм Дейкстры является представителем идеального баланса простоты и мощи, для решения прикладных задач.
Статья подготовлена в преддверии старта курса «Алгоритмы для разработчиков». Узнать о курсе подробнее, а также зарегистрироваться на бесплатный демоурок можно по ссылке.
Информация
[1] Условия задач взяты из книги «Algorithms Illuminated: Part 2: Graph Algorithms and Data Structures» от Tim Roughgarden,
[2] и с сайта leetcode.com.
[3] Решения авторские.
Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Задача
Дан ориентированный граф (G = (V, E)), а также вершина (s).
Найти длину кратчайшего пути от (s) до каждой из вершин графа. Длина пути — количество рёбер в нём.
BFS
BFS — breadth-first search, или же поиск в ширину.
Этот алгоритм позволяет решать следующую задачу.
Алгоритм работает следующим образом.
- Создадим массив (dist) расстояний. Изначально (dist[s] = 0) (поскольку расстояний от вершины до самой себя равно (0)) и (dist[v] = infty) для (v neq s).
- Создадим очередь (q). Изначально в (q) добавим вершину (s).
- Пока очередь (q) непуста, делаем следующее:
- Извлекаем вершину (v) из очереди.
- Рассматриваем все рёбра ((v, u) in E). Для каждого такого ребра пытаемся сделать релаксацию: если (dist[v] + 1 < dist[u]), то мы делаем присвоение (dist[u] = dist[v] + 1) и добавляем вершину (u) в очередь.
Визуализации:
-
https://visualgo.net/mn/dfsbfs
-
https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/visualize/
Интуитивное понимание алгоритма
Можно представить, что мы поджигаем вершину (s). Каждый шаг алгоритма — это распространение огня на соседние вершины. Понятно, что огонь доберётся до вершины по кратчайшему пути.
Заметьте, что этот алгоритм очень похож на DFS — достаточно заменить очередь на стек и поиск в ширину станет поиском в глубину. Действительно, оба алгоритма при обработке вершины просто записывают всех непосещенных соседей, в которые из неё есть ребро, в структуру данных, и после этого выбирает следующую вершину для обработки в структуре данных. В DFS это стек (благодаря рекурсии), поэтому мы сначала записываем соседа, идем в обрабатываем его полностью, а потом начинаем обрабатывать следующего соседа. В BFS это очередь, поэтому мы кидаем сразу всех соседей, а потом начинаем обрабатывать вообще другую вершину — ту непосещенную, которую мы положили в очередь раньше всего.
Оба алгоритма позволяют обойти граф целиком — посетить каждую вершину ровно один раз. Поэтому они оба подходят для таких задач как: * поиск компонент связности * проверка графа на двудольность * построение остова
Реализация на C++
n — количество вершин в графе; adj — список смежности
vector<int> bfs(int s) {
// длина любого кратчайшего пути не превосходит n - 1,
// поэтому n - достаточное значение для "бесконечности";
// после работы алгоритма dist[v] = n, если v недостижима из s
vector<int> dist(n, n);
dist[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
for (int u : adj[v]) {
if (dist[u] > dist[v] + 1) {
dist[u] = dist[v] + 1;
q.push(u);
}
}
}
return dist;
}Свойства кратчайших путей
Обозначение: (d(v)) — длина кратчайшего пути от (s) до (v).
Лемма 1. > Пусть ((u, v) in E), тогда (d(v) leq d(u) + 1).
Действительно, существует путь из (s) в (u) длины (d(u)), а также есть ребро ((u, v)), следовательно, существует путь из (s) в (v) длины (d(u) + 1). А значит кратчайший путь из (s) в (v) имеет длину не более (d(u) + 1),
Лемма 2. > Рассмотрим кратчайший путь от (s) до (v). Обозначим его как (u_1, u_2, dots u_k) ((u_1 = s) и (u_k = v), а также (k = d(v) + 1)).
> Тогда (forall (i < k): d(u_i) + 1 = d(u_{i + 1})).
Действительно, пусть для какого-то (i < k) это не так. Тогда, используя лемму 1, имеем: (d(u_i) + 1 > d(u_{i + 1})). Тогда мы можем заменить первые (i + 1) вершин пути на вершины из кратчайшего пути из (s) в (u_{i + 1}). Полученный путь стал короче, но мы рассматривали кратчайший путь — противоречие.
Корректность
Утверждение. > 1. Расстояния до тех вершин, которые были добавлены в очередь, посчитаны корректно. > 2. Вершины лежат в очереди в порядке неубывания расстояния, притом разность между кратчайшими расстояними до вершин в очереди не превосходит (1).
Докажем это по индукции по количеству итераций алгоритма (итерация — извлечение вершины из очереди и дальнейшая релаксация).
База очевидна.
Переход. Сначала докажем первую часть. Предположим, что (dist[v] + 1 < dist[u]), но (dist[v] + 1) — некорректное расстояние до вершины (u), то есть (dist[v] + 1 neq d(u)). Тогда по лемме 1: (d(u) < dist[v] + 1). Рассмотрим предпоследнюю вершину (w) на кратчайшем пути от (s) до (u). Тогда по лемме 2: (d(w) + 1 = d(u)). Следовательно, (d(w) + 1 < dist[v] + 1) и (d(w) < dist[v]). Но тогда по предположению индукции (w) была извлечена раньше (v), следовательно, при релаксации из неё в очередь должна была быть добавлена вершина (u) с уже корректным расстоянием. Противоречие.
Теперь докажем вторую часть. По предположению индукции в очереди лежали некоторые вершины (u_1, u_2, dots u_k), для которых выполнялось следующее: (dist[u_1] leq dist[u_2] leq dots leq dist[u_k]) и (dist[u_k] — dist[u_1] leq 1). Мы извлекли вершину (v = u_1) и могли добавить в конец очереди какие-то вершины с расстоянием (dist[v] + 1). Если (k = 1), то утверждение очевидно. В противном случае имеем (dist[u_k] — dist[u_1] leq 1 leftrightarrow dist[u_k] — dist[v] leq 1 leftrightarrow dist[u_k] leq dist[v] + 1), то есть упорядоченность сохранилась. Осталось показать, что ((dist[v] + 1) — dist[u_2] leq 1), но это равносильно (dist[v] leq dist[u_2]), что, как мы знаем, верно.
Время работы
Из доказанного следует, что каждая достижимая из (s) вершина будет добавлена в очередь ровно (1) раз, недостижимые вершины добавлены не будут. Каждое ребро, соединяющее достижимые вершины, будет рассмотрено ровно (2) раза. Таким образом, алгоритм работает за (O(V+ E)) времени, при условии, что граф хранится в виде списка смежности.
Неориентированные графы
Если дан неориентированный граф, его можно рассматривать как ориентированный граф с двумя обратными друг другу ориентированными рёбрами.
Восстановление пути
Пусть теперь заданы 2 вершины (s) и (t), и необходимо не только найти длину кратчайшего пути из (s) в (t), но и восстановить какой-нибудь из кратчайших путей между ними. Всё ещё можно воспользоваться алгоритмом BFS, но необходимо ещё и поддерживать массив предков (p), в котором для каждой вершины будет храниться предыдущая вершина на кратчайшем пути.
Поддерживать этот массив просто: при релаксации нужно просто запоминать, из какой вершины мы прорелаксировали в данную. Также будем считать, что (p[s] = -1): у стартовой вершины предок — некоторая несуществующая вершина.
Восстановление пути делается с конца. Мы знаем последнюю вершину пути — это (t). Далее, мы сводим задачу к меньшей, переходя к нахождению пути из (s) в (p[t]).
Реализация BFS с восстановлением пути
// теперь bfs принимает 2 вершины, между которыми ищется пути
// bfs возвращает кратчайший путь из s в t, или же пустой vector, если пути нет
vector<int> bfs(int s, int t) {
vector<int> dist(n, n);
vector<int> p(n, -1);
dist[s] = 0;
queue<int> q;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
for (int u : adj[v]) {
if (dist[u] > dist[v] + 1) {
p[u] = v;
dist[u] = dist[v] + 1;
q.push(u);
}
}
}
// если пути не существует, возвращаем пустой vector
if (dist[t] == n) {
return {};
}
vector<int> path;
while (t != -1) {
path.push_back(t);
t = p[t];
}
// путь был рассмотрен в обратном порядке, поэтому его нужно перевернуть
reverse(path.begin(), path.end());
return path;
}Проверка принадлежности вершины кратчайшему пути
Дан ориентированный граф (G), найти все вершины, которые принадлежат хотя бы одному кратчайшему пути из (s) в (t).
Запустим из вершины (s) в графе (G) BFS — найдём расстояния (d_1). Построим транспонированный граф (G^T) — граф, в котором каждое ребро заменено на противоположное. Запустим из вершины (t) в графе (G^T) BFS — найдём расстояния (d_2).
Теперь очевидно, что (v) принадлежит хотя бы одному кратчайшему пути из (s) в (t) тогда и только тогда, когда (d_1(v) + d_2(v) = d_1(t)) — это значит, что есть путь из (s) в (v) длины (d_1(v)), а затем есть путь из (v) в (t) длины (d_2(v)), и их суммарная длина совпадает с длиной кратчайшего пути из (s) в (t).
Кратчайший цикл в ориентированном графе
Найти цикл минимальной длины в ориентированном графе.
Попытаемся из каждой вершины найти кратчайший цикл, проходящий через неё, с помощью BFS. Это делается аналогично обычному BFS: мы должны найти расстояний от вершины до самой себя, при этом не считая, что оно равно (0).
Итого, у нас (|V|) запусков BFS, и каждый запуск работает за (O(|V| + |E|)). Тогда общее время работы составляет (O(|V|^2 + |V| |E|)). Если инициализировать массив (dist) единожды, а после каждого запуска BFS возвращать исходные значения только для достижимых вершин, решение будет работать за (O(|V||E|)).
Задача
Дан взвешенный ориентированный граф (G = (V, E)), а также вершина (s). Длина ребра ((u, v)) равна (w(u, v)). Длины всех рёбер неотрицательные.
Найти длину кратчайшего пути от (s) до каждой из вершин графа. Длина пути — сумма длин рёбер в нём.
Алгоритм Дейкстры
Алгоритм Дейкстры решает приведённую выше задачу. Он работает следующим образом.
- Создать массив (dist) расстояний. Изначально (dist[s] = 0) и (dist[v] = infty) для (v neq s).
- Создать булёв массив (used), (used[v] = 0) для всех вершин (v) — в нём мы будем отмечать, совершалась ли релаксация из вершины.
- Пока существует вершина (v) такая, что (used[v] = 0) и (dist[v] neq infty), притом, если таких вершин несколько, то (v) — вершина с минимальным (dist[v]), делать следующее:
- Пометить, что мы совершали релаксацию из вершины (v), то есть присвоить (used[v] = 1).
- Рассматриваем все рёбра ((v, u) in E). Для каждого ребра пытаемся сделать релаксацию: если (dist[v] + w(v, u) < dist[u]), присвоить (dist[u] = dist[v] + w(v, u)).
Иными словами, алгоритм на каждом шаге находит вершину, до которой расстояние сейчас минимально и из которой ещё не была произведена релаксация, и делает её.
Посчитаем, за сколько работает алгоритм. Мы (V) раз ищем вершину минимальным (dist), поиск минимума у нас линейный за (O(V)), отсюда (O(V^2)). Обработка ребер у нас происходит суммарно за (O(E)), потому что на каждое ребро мы тратим (O(1)) действий. Так мы находим финальную асимптотику: (O(V^2 + E)).
Реализация на C++
Рёбра будем хранить как pair<int, int>, где первое число пары — куда оно ведёт; а второе — длина ребра.
// INF - infinity - бесконечность
const long long INF = (long long) 1e18 + 1;
vector<long long> dijkstra(int s) {
vector<long long> dist(n, INF);
dist[s] = 0;
vector<bool> used(n);
while (true) {
// находим вершину, из которой будем релаксировать
int v = -1;
for (int i = 0; i < n; i++) {
if (!used[i] && (v == -1 || dist[i] < dist[v])) {
v = i;
}
}
// если не нашли подходящую вершину, прекращаем работу алгоритма
if (v == -1) {
break;
}
for (auto &e : adj[v]) {
int u = e.first;
int len = e.second;
if (dist[u] > dist[v] + len) {
dist[u] = dist[v] + len;
}
}
}
return dist;
}Восстановление пути
Восстановление пути в алгоритме Дейкстры делается аналогично восстановлению пути в BFS (и любой динамике).
Дейкстра на сете
Искать вершину с минимальным (dist) можно гораздо быстрее, используя такую структуру данных как очередь с приоритетом. Нам нужно хранить пары ((dist, index)) и уметь делать такие операции: * Извлечь минимум (чтобы обработать новую вершину) * Удалить вершину по индексу (чтобы уменьшить (dist) до какого-то соседа) * Добавить новую вершину (чтобы уменьшить (dist) до какого-то соседа)
Для этого используют, например, кучу или сет. Удобно помимо сета хранить сам массив dist, который его дублирует, но хранит элементы по порядку. Тогда, чтобы заменить значение ((dist_1, u)) на ((dist_2, u)), нужно удалить из сета значение ((dist[u], u)), сделать (dist[u] = dist_2;) и добавить в сет ((dist[u], u)).
Данный алгоритм будет работать за (V O(log V)) извлечений минимума и (O(E log V)) операций уменьшения расстояния до вершины (может быть сделано после каждого ребра). Поэтому алгоритм работает за (O(E log V)).
Заметьте, что этот алгоритм не лучше и не хуже, чем без сета, который работает за (O(V^2 + E)). Ведь если (E = O(V^2)) (граф почти полный), то Дейкстра без сета работает быстрее, а если, наример, (E = O(V)), то Дейкстра на сете работает быстрее. Учитывайте это, когда выбираете алгоритм.
%saved0% Граф — это (упрощенно) множество точек, называемых вершинами, соединенных какими-то линиями, называемыми рёбрами (необязательно все вершины соединены). Можно представлять себе как города, соединенные дорогами.
Любое клетчатое поле можно представить в виде графа. Вершинами будут являться клетки, а ребрами — смежные стороны клеток.
Наглядное представление о работе перечисленных далее алгоритмов можно получить благодаря визуализатору PathFinding.js.
Поиск в ширину (BFS, Breadth-First Search)
Алгоритм был разработан независимо Муром и Ли для разных приложений (поиск пути в лабиринте и разводка проводников соответственно) в 1959 и 1961 годах. Этот алгоритм можно сравнить с поджиганием соседних вершин графа: сначала мы зажигаем одну вершину (ту, из которой начинаем путь), а затем огонь за один элементарный промежуток времени перекидывается на все соседние с ней не горящие вершины. В последствие то же происходит со всеми подожженными вершинами. Таким образом, огонь распространяется «в ширину». В результате его работы будет найден кратчайший путь до нужной клетки.
Алгоритм Дейкстры (Dijkstra)
Этот алгоритм назван по имени создателя и был разработан в 1959 году. В процессе выполнения алгоритм проверит каждую из вершин графа, и найдет кратчайший путь до исходной вершины. Стандартная реализация работает на взвешенном графе — графе, у которого каждый путь имеет вес, т.е. «стоимость», которую надо будет «заплатить», чтобы перейти по этому ребру. При этом в стандартной реализации веса неотрицательны. На клетчатом поле вес каждого ребра графа принимается одинаковым (например, единицей).
А* (А «со звездочкой»)
Впервые описан в 1968 году Питером Хартом, Нильсом Нильсоном и Бертрамом Рафаэлем. Данный алгоритм является расширением алгоритма Дейкстры, ускорение работы достигается за счет эвристики — при рассмотрении каждой отдельной вершины переход делается в ту соседнюю вершину, предположительный путь из которой до искомой вершины самый короткий. При этом существует множество различных методов подсчета длины предполагаемого пути из вершины. Результатом работы также будет кратчайший путь. О реализации алгоритма читайте в здесь.
Поиск по первому наилучшему совпадению (Best-First Search)
Усовершенствованная версия алгоритма поиска в ширину, отличающаяся от оригинала тем, что в первую очередь развертываются узлы, путь из которых до конечной вершины предположительно короче. Т.е. за счет эвристики делает для BFS то же, что A* делает для алгоритма Дейкстры.
IDA* (A* с итеративным углублением)
Расшифровывается как Iterative Deeping A*. Является измененной версией A*, использующей меньше памяти за счет меньшего количества развертываемых узлов. Работает быстрее A* в случае удачного выбора эвристики. Результат работы — кратчайший путь.
Jump Point Search
Самый молодой из перечисленных алгоритмов был представлен в 2011 году. Представляет собой усовершенствованный A*. JPS ускоряет поиск пути, «перепрыгивая» многие места, которые должны быть просмотрены. В отличие от подобных алгоритмов JPS не требует предварительной обработки и дополнительных затрат памяти.
Материалы по более интересным алгоритмам мы обозревали в подборке материалов по продвинутым алгоритмам и структурам данных.
Рассмотрим пример нахождение кратчайшего пути. Дана сеть автомобильных дорог, соединяющих области города. Некоторые дороги односторонние. Найти кратчайшие пути от центра города до каждого города области.
Для решения указанной задачи можно использовать алгоритм Дейкстры — алгоритм на графах, изобретённый нидерландским ученым Э. Дейкстрой в 1959 году. Находит кратчайшее расстояние от одной из вершин графа до всех остальных. Работает только для графов без рёбер отрицательного веса.
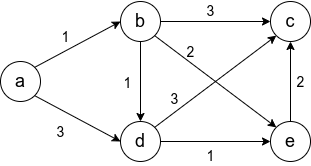
Пусть требуется найти кратчайшие расстояния от 1-й вершины до всех остальных.
Кружками обозначены вершины, линиями – пути между ними (ребра графа). В кружках обозначены номера вершин, над ребрами обозначен их вес – длина пути. Рядом с каждой вершиной красным обозначена метка – длина кратчайшего пути в эту вершину из вершины 1.

Инициализация
Метка самой вершины 1 полагается равной 0, метки остальных вершин – недостижимо большое число (в идеале — бесконечность). Это отражает то, что расстояния от вершины 1 до других вершин пока неизвестны. Все вершины графа помечаются как непосещенные.

Первый шаг
Минимальную метку имеет вершина 1. Её соседями являются вершины 2, 3 и 6. Обходим соседей вершины по очереди.
Первый сосед вершины 1 – вершина 2, потому что длина пути до неё минимальна. Длина пути в неё через вершину 1 равна сумме кратчайшего расстояния до вершины 1 (значению её метки) и длины ребра, идущего из 1-й во 2-ю, то есть 0 + 7 = 7. Это меньше текущей метки вершины 2 (10000), поэтому новая метка 2-й вершины равна 7.

Аналогично находим длины пути для всех других соседей (вершины 3 и 6).
Все соседи вершины 1 проверены. Текущее минимальное расстояние до вершины 1 считается окончательным и пересмотру не подлежит. Вершина 1 отмечается как посещенная.
Второй шаг
Шаг 1 алгоритма повторяется. Снова находим «ближайшую» из непосещенных вершин. Это вершина 2 с меткой 7.
Снова пытаемся уменьшить метки соседей выбранной вершины, пытаясь пройти в них через 2-ю вершину. Соседями вершины 2 являются вершины 1, 3 и 4.
Вершина 1 уже посещена. Следующий сосед вершины 2 — вершина 3, так как имеет минимальную метку из вершин, отмеченных как не посещённые. Если идти в неё через 2, то длина такого пути будет равна 17 (7 + 10 = 17). Но текущая метка третьей вершины равна 9, а 9 < 17, поэтому метка не меняется.

Ещё один сосед вершины 2 — вершина 4. Если идти в неё через 2-ю, то длина такого пути будет равна 22 (7 + 15 = 22). Поскольку 22<10000, устанавливаем метку вершины 4 равной 22.
Все соседи вершины 2 просмотрены, помечаем её как посещенную.
Третий шаг
Повторяем шаг алгоритма, выбрав вершину 3. После её «обработки» получим следующие результаты.

Четвертый шаг

Пятый шаг

Шестой шаг

Таким образом, кратчайшим путем из вершины 1 в вершину 5 будет путь через вершины 1 — 3 — 6 — 5, поскольку таким путем мы набираем минимальный вес, равный 20.
Займемся выводом кратчайшего пути. Мы знаем длину пути для каждой вершины, и теперь будем рассматривать вершины с конца. Рассматриваем конечную вершину (в данном случае — вершина 5), и для всех вершин, с которой она связана, находим длину пути, вычитая вес соответствующего ребра из длины пути конечной вершины.
Так, вершина 5 имеет длину пути 20. Она связана с вершинами 6 и 4.
Для вершины 6 получим вес 20 — 9 = 11 (совпал).
Для вершины 4 получим вес 20 — 6 = 14 (не совпал).
Если в результате мы получим значение, которое совпадает с длиной пути рассматриваемой вершины (в данном случае — вершина 6), то именно из нее был осуществлен переход в конечную вершину. Отмечаем эту вершину на искомом пути.
Далее определяем ребро, через которое мы попали в вершину 6. И так пока не дойдем до начала.
Если в результате такого обхода у нас на каком-то шаге совпадут значения для нескольких вершин, то можно взять любую из них — несколько путей будут иметь одинаковую длину.
Реализация алгоритма Дейкстры
Для хранения весов графа используется квадратная матрица. В заголовках строк и столбцов находятся вершины графа. А веса дуг графа размещаются во внутренних ячейках таблицы. Граф не содержит петель, поэтому на главной диагонали матрицы содержатся нулевые значения.
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 1 | 0 | 7 | 9 | 0 | 0 | 14 |
| 2 | 7 | 0 | 10 | 15 | 0 | 0 |
| 3 | 9 | 10 | 0 | 11 | 0 | 2 |
| 4 | 0 | 15 | 11 | 0 | 6 | 0 |
| 5 | 0 | 0 | 0 | 6 | 0 | 9 |
| 6 | 14 | 0 | 2 | 0 | 9 | 0 |
Реализация на C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#define SIZE 6
int main()
{
int a[SIZE][SIZE]; // матрица связей
int d[SIZE]; // минимальное расстояние
int v[SIZE]; // посещенные вершины
int temp, minindex, min;
int begin_index = 0;
system(«chcp 1251»);
system(«cls»);
// Инициализация матрицы связей
for (int i = 0; i<SIZE; i++)
{
a[i][i] = 0;
for (int j = i + 1; j<SIZE; j++) {
printf(«Введите расстояние %d — %d: «, i + 1, j + 1);
scanf(«%d», &temp);
a[i][j] = temp;
a[j][i] = temp;
}
}
// Вывод матрицы связей
for (int i = 0; i<SIZE; i++)
{
for (int j = 0; j<SIZE; j++)
printf(«%5d «, a[i][j]);
printf(«n»);
}
//Инициализация вершин и расстояний
for (int i = 0; i<SIZE; i++)
{
d[i] = 10000;
v[i] = 1;
}
d[begin_index] = 0;
// Шаг алгоритма
do {
minindex = 10000;
min = 10000;
for (int i = 0; i<SIZE; i++)
{ // Если вершину ещё не обошли и вес меньше min
if ((v[i] == 1) && (d[i]<min))
{ // Переприсваиваем значения
min = d[i];
minindex = i;
}
}
// Добавляем найденный минимальный вес
// к текущему весу вершины
// и сравниваем с текущим минимальным весом вершины
if (minindex != 10000)
{
for (int i = 0; i<SIZE; i++)
{
if (a[minindex][i] > 0)
{
temp = min + a[minindex][i];
if (temp < d[i])
{
d[i] = temp;
}
}
}
v[minindex] = 0;
}
} while (minindex < 10000);
// Вывод кратчайших расстояний до вершин
printf(«nКратчайшие расстояния до вершин: n»);
for (int i = 0; i<SIZE; i++)
printf(«%5d «, d[i]);
// Восстановление пути
int ver[SIZE]; // массив посещенных вершин
int end = 4; // индекс конечной вершины = 5 — 1
ver[0] = end + 1; // начальный элемент — конечная вершина
int k = 1; // индекс предыдущей вершины
int weight = d[end]; // вес конечной вершины
while (end != begin_index) // пока не дошли до начальной вершины
{
for (int i = 0; i<SIZE; i++) // просматриваем все вершины
if (a[i][end] != 0) // если связь есть
{
int temp = weight — a[i][end]; // определяем вес пути из предыдущей вершины
if (temp == d[i]) // если вес совпал с рассчитанным
{ // значит из этой вершины и был переход
weight = temp; // сохраняем новый вес
end = i; // сохраняем предыдущую вершину
ver[k] = i + 1; // и записываем ее в массив
k++;
}
}
}
// Вывод пути (начальная вершина оказалась в конце массива из k элементов)
printf(«nВывод кратчайшего путиn»);
for (int i = k — 1; i >= 0; i—)
printf(«%3d «, ver[i]);
getchar(); getchar();
return 0;
}
Результат выполнения

Назад: Алгоритмизация
-
Нахождение кратчайшего пути
Здесь рассматриваются
алгоритмы нахождения путей в ориентированном
графе. Эти алгоритмы работают на
ориентированном графе, у которого все
дуги имеют неотрицательные метки
(стоимости дуг). Задача алгоритмов
состоит в нахождении кратчайших путей
между вершинами графа. Длина пути здесь
определяется как сумма меток (длин) дуг,
составляющих путь.
-
Алгоритм Дейкстры
Этот алгоритм находит
в графе кратчайший путь из заданной
вершины, определенной как источник, во
все остальные вершины.
В процессе своей работы
алгоритм строит множество S
вершин, для которых кратчайшие пути от
источника уже известны. На каждом шаге
к множеству S добавляется
та из оставшихся вершин, расстояние до
которой от источника меньше, чем для
других оставшихся вершин. При этом
используется массив D,
в который записываются длины кратчайших
путей для каждой вершины. Когда множество
S будет содержать все
вершины графа, тогда массив D будет
содержать длины кратчайших путей от
источника к каждой вершине.
Помимо указанных
массивов, в алгоритме Дейкстры
используется матрица длин C,
где элемент C[i, j]
– метка (длина) дуги (i, j),
если дуги нет, то ее длина полагается
равной бесконечности, то есть больше
любой фактической длины дуг. Фактически,
матрица C представляет собой матрицу
смежности, в которой все нулевые элементы
заменены на бесконечность.
Для определения самого
кратчайшего пути (то есть последовательности
вершин) необходимо ввести еще один
массив P вершин, где
P[v]
содержит вершину, непосредственно
предшествующую вершине v
в кратчайшем пути.
Алгоритм:
procedure
Dijkstra;
begin
S
:= источник;
for
i := 2 to n do begin
D[i]
:= C[источник, i];
P[i]
:= источник;
end;
for
i := 1 to n-1 do begin
выбор
из множества VS такой вершины w,
что
значение D[w] минимально;
добавить
w к множеству S;
for
каждая вершина v из множества VS do begin
D[v]
:= min(D[v], D[w] + C[w, v]);
if
D[w] + C[w, v]< D[v] then P[v] := w;
end;
end;
end
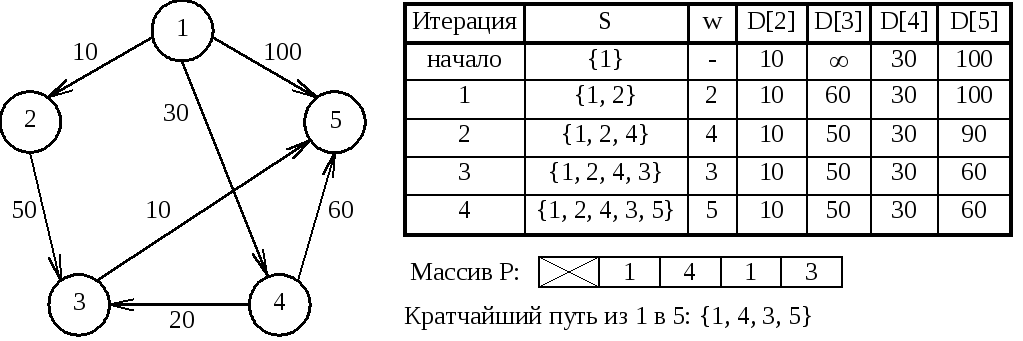
Рисунок 53. Алгоритм Дейкстры
После выполнения
алгоритма кратчайший путь к каждой
вершине можно найти с помощью обратного
прохождения по предшествующим вершинам
массива P, начиная от
конечной вершины к источнику.
Время выполнения этого
алгоритма, если для представления графа
используется матрица смежности, имеет
порядок O(n2),
где n – количество
вершин графа.
-
Алгоритм Флойда
Этот алгоритм решает
задачу нахождения кратчайших путей
между всеми парами вершин графа. Более
строгая формулировка этой задачи
следующая: есть ориентированный граф
G = (V, Е),
каждой дуге (v, w)
этого графа сопоставлена неотрицательная
стоимость C[v, w].
Общая задача нахождения кратчайших
путей заключается в нахождении для
каждой упорядоченной пары вершин (v, w)
любого пути от вершины v
в вершину w, длина
которого минимальна среди всех возможных
путей от v к w.
Можно решить эту
задачу, последовательно применяя
алгоритм Дейкстры для
каждой вершины, объявляемой в качестве
источника. Но существует прямой способ
решения данной задачи, использующий
алгоритм Флойда. Для
определенности положим, что вершины
графа последовательно пронумерованы
от 1 до n. Алгоритм
Флойда использует матрицу
A размера
nn,
в которой вычисляются длины кратчайших
путей. В начале
A[i, j] = C[i, j]
для всех i <> j.
Если дуга (i, j)
отсутствует, то C[i, j] = .
Каждый диагональный элемент матрицы A
равен 0.
Над матрицей A
выполняется n итераций.
После k-й
итерации A[i, j]
содержит значение наименьшей длины
путей из вершины i в
вершину j, которые не
проходят через вершины с номером, большим
k. Другими словами,
между концевыми вершинами пути i
и j могут находиться
только вершины, номера которых меньше
или равны k.
На k-й
итерации для вычисления матрицы A
применяется следующая формула:
Аk[i, j] = min(Ak-1[i, j], Ak-1[i, k]
+ Ak-1[k, j]).
Нижний индекс k
обозначает значение матрицы А
после k-й
итерации, но это не означает, что
существует n различных
матриц, этот индекс используется для
сокращения записи.
Равенства
Ak[i, k] = Ak-1[i, k]
и Ak[k, j] = Ak-1[k, j]
означают, что на k-й
итерации элементы матрицы A,
стоящие в k-й
строке и k-м столбце,
не изменяются. Более того, все вычисления
можно выполнить с применением только
одного экземпляра матрицы A.
Представим алгоритм Флойда
в виде следующей процедуры.
procedure
Floyd (var A: array[1..n, 1..n] of real;
С:
аrrау[1..n, 1..n] of real);
var
i,
j, k: integer;
begin
for
i := 1 to n do
for
j := 1 to n do A[i, j] := C[i, j];
for
i := 1 to n do A[i, i] := 0;
for
k := 1 to n do
for
i := 1 to n do
for
j : = 1 to n do
if
(A[i, k] + A[k, j]) < A[i, j] then
A[i,
j] := A[i, k] + A[k, j];
end;
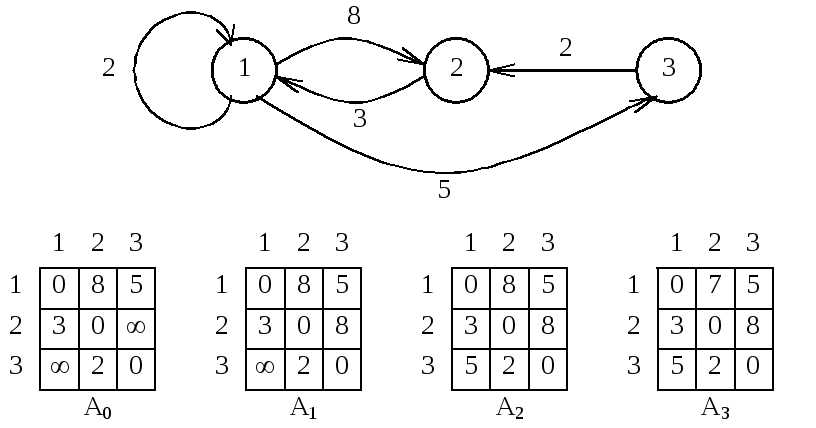
Рисунок 54. Алгоритм Флойда
Следует заметить, что
если в графе существует контур
отрицательной суммарной длины, то вес
любого пути, проходящего через вершину
из этого контура, можно сделать сколь
угодно малой, «прокрутившись» в контуре
необходимое количество раз. Поэтому
поставленная задача разрешима не всегда.
В случае, описанном выше, алгоритм Флойда
не применим. Останавливаясь подробнее
надо заметить, что если граф
неориентированный, то ребро с отрицательным
весом является как раз таким контуром
(проходя по нему в обоих направлениях
столько раз пока не сделаем вес достаточно
малым).
Заметим, что если граф
неориентированный, то все матрицы,
получаемые в результате преобразований
симметричны и, следовательно, достаточно
вычислять только элементы расположенные
выше главной диагонали.
Время выполнения этого
алгоритма, очевидно, имеет порядок
O(n3),
поскольку в нем присутствуют вложенные
друг в друга три цикла.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #