Двумерной называют случайную величину
, возможные значения
которой есть пары чисел
. Составляющие
и
, рассматриваемые
одновременно, образуют систему двух случайных величин. Двумерную величину
геометрически можно истолковать как случайную точку
на плоскости
либо как случайный вектор
.
Дискретной называют двумерную величину, составляющие которой дискретны.
Закон распределения дискретной двумерной СВ.
Безусловные и условные законы распределения составляющих
Законом распределения вероятностей двумерной случайной величины называют соответствие
между возможными значениями и их вероятностями.
Закон
распределения дискретной двумерной случайной величины может быть задан:
а) в
виде таблицы с двойными входом, содержащей возможные значения и их вероятности;
б) аналитически, например в виде функции распределения.
Зная
закон распределения двумерной дискретной случайной величины, можно найти законы
каждой из составляющих. В общем случае, для того чтобы найти вероятность
, надо просуммировать
вероятности столбца
. Аналогично сложив
вероятности строки
получим вероятность
.
Пусть
составляющие
и
дискретны и имеют соответственно следующие
возможные значения:
;
.
Условным распределением составляющей
при
(j сохраняет одно и то же
значение при всех возможных значениях
) называют совокупность
условных вероятностей:
Аналогично
определяется условное распределение
.
Условные
вероятности составляющих
и
вычисляют соответственно по формулам:
Для
контроля вычислений целесообразно убедиться, что сумма вероятностей условного
распределения равна единице.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Ковариация (корреляционный момент)
Ковариация двух случайных величин характеризует степень зависимости случайных величин, так
и их рассеяние вокруг точки
.
Ковариацию
(корреляционный момент) можно найти по формуле:
Свойства ковариации
Свойство 1.
Ковариация двух независимых случайных величин равна нулю.
Свойство 2.
Ковариация двух случайных величин равна математическому ожиданию их
произведение математических ожиданий.
Свойство 3.
Ковариация двухмерной случайной величины по абсолютной случайной величине не
превосходит среднеквадратических отклонений своих компонентов.
Коэффициент корреляции
Коэффициент корреляции – отношение ковариации двухмерной случайной
величины к произведению среднеквадратических отклонений.
Формула коэффициента корреляции:
Две
случайные величины
и
называют коррелированными, если их коэффициент
корреляции отличен от нуля.
и
называют некоррелированными величинами, если
их коэффициент корреляции равен нулю
Свойства коэффициента корреляции
Свойство 1.
Коэффициент корреляции двух независимых случайных величин равен нулю. Отметим,
что обратное утверждение неверно.
Свойство 2.
Коэффициент корреляции двух случайных величин не превосходит по абсолютной
величине единицы.
Свойство 3.
Коэффициент корреляции двух случайных величин равен по модулю единице тогда и
только тогда, когда между величинами существует линейная функциональная
зависимость.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Линейная регрессия
Рассмотрим
двумерную случайную величину
, где
и
– зависимые случайные величины. Представим
одну из величины как функцию другой. Ограничимся приближенным представлением
величины
в виде линейной функции величины
:
где
и
– параметры, подлежащие определению. Это можно
сделать различными способами и наиболее употребительный из них – метод
наименьших квадратов.
Линейная
средняя квадратическая регрессия
на
имеет вид:
Коэффициент
называют
коэффициентом регрессии
на
, а прямую
называют
прямой среднеквадратической регрессии
на
.
Аналогично
можно получить прямую среднеквадратической регрессии
на
:
Смежные темы решебника:
- Двумерная непрерывная случайная величина
- Линейный выборочный коэффициент корреляции
- Парная линейная регрессия и метод наименьших квадратов
Задача 1
Закон
распределения дискретной двумерной случайной величины (X,Y) задан таблицей.
Требуется:
—
определить одномерные законы распределения случайных величин X и Y;
— найти
условные плотности распределения вероятностей величин;
—
вычислить математические ожидания mx и my;
—
вычислить дисперсии σx и σy;
—
вычислить ковариацию μxy;
—
вычислить коэффициент корреляции rxy.
| xy | 3 | 5 | 8 | 10 | 12 |
| -1 | 0.04 | 0.04 | 0.03 | 0.03 | 0.01 |
| 1 | 0.04 | 0.07 | 0.06 | 0.05 | 0.03 |
| 3 | 0.05 | 0.08 | 0.09 | 0.08 | 0.05 |
| 6 | 0.03 | 0.04 | 0.04 | 0.06 | 0.08 |
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 2
Задана
дискретная двумерная случайная величина (X,Y).
а) найти
безусловные законы распределения составляющих; б) построить регрессию случайной
величины Y на X; в) построить регрессию случайной величины X на Y; г) найти коэффициент ковариации; д) найти
коэффициент корреляции.
| Y | X | ||||
| 1 | 2 | 3 | 4 | 5 | |
| 30 | 0.05 | 0.03 | 0.02 | 0.01 | 0.01 |
| 40 | 0.03 | 0.02 | 0.02 | 0.04 | 0.01 |
| 50 | 0.05 | 0.03 | 0.02 | 0.02 | 0.01 |
| 70 | 0.1 | 0.03 | 0.04 | 0.03 | 0.01 |
| 90 | 0.1 | 0.04 | 0.01 | 0.07 | 0.2 |
Задача 3
Двумерная случайная величина (X,Y) задана
таблицей распределения. Найти законы распределения X и Y, условные
законы, регрессию и линейную регрессию Y на X.
|
x y |
1 | 2 | 3 |
| 1.5 | 0.03 | 0.02 | 0.02 |
| 2.9 | 0.06 | 0.13 | 0.03 |
| 4.1 | 0.4 | 0.07 | 0.02 |
| 5.6 | 0.15 | 0.06 | 0.01 |
Задача 4
Двумерная
случайная величина (X,Y) распределена по закону
| XY | 1 | 2 |
| -3 | 0,1 | 0,2 |
| 0 | 0,2 | 0,3 |
| -3 | 0 | 0,2 |
Найти
законы распределения случайных величины X и Y, условный закон
распределения Y при X=0 и вычислить ковариацию.
Исследовать зависимость случайной величины X и Y.
Задача 5
Случайные
величины ξ и η имеют следующий совместный закон распределения:
P(ξ=1,η=1)=0.14
P(ξ=1,η=2)=0.18
P(ξ=1,η=3)=0.16
P(ξ=2,η=1)=0.11
P(ξ=2,η=2)=0.2
P(ξ=2,η=3)=0.21
1)
Выписать одномерные законы распределения случайных величин ξ и η, вычислить
математические ожидания Mξ, Mη и дисперсии Dξ, Dη.
2) Найти
ковариацию cov(ξ,η) и коэффициент корреляции ρ(ξ,η).
3)
Выяснить, зависимы или нет события {η=1} и {ξ≥η}
4)
Составить условный закон распределения случайной величины γ=(ξ|η≥2) и найти Mγ и
Dγ.
Задача 6
Дан закон
распределения двумерной случайной величины (ξ,η):
| ξ=-1 | ξ=0 | ξ=2 | |
| η=1 | 0,1 | 0,1 | 0,1 |
| η=2 | 0,1 | 0,2 | 0,1 |
| η=3 | 0,1 | 0,1 | 0,1 |
1) Выписать одномерные законы
распределения случайных величин ξ и η, вычислить математические ожидания Mξ,
Mη и дисперсии Dξ, Dη
2) Найти ковариацию cov(ξ,η) и
коэффициент корреляции ρ(ξ,η).
3) Являются ли случайные события |ξ>0|
и |η> ξ | зависимыми?
4) Составить условный закон
распределения случайной величины γ=(ξ|η>0) и найти Mγ и Dγ.
Задача 7
Дано
распределение случайного вектора (X,Y). Найти ковариацию X и Y.
| XY | 1 | 2 | 4 |
| -2 | 0,25 | 0 | 0,25 |
| 1 | 0 | 0,25 | 0 |
| 3 | 0 | 0,25 | 0 |
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 8
Случайные
приращения цен акций двух компаний за день имеют совместное распределение,
заданное таблицей. Найти ковариацию этих случайных величин.
| YX | -1 | 1 |
| -1 | 0,4 | 0,1 |
| 1 | 0,2 | 0,3 |
Задача 9
Найдите
ковариацию Cov(X,Y) для случайного дискретного вектора (X,Y),
распределенного по закону:
| X=-3 | X=0 | X=1 | |
| Y=-2 | 0,3 | ? | 0,1 |
| Y=1 | 0,1 | 0,1 | 0,2 |
Задача 10
Совместный
закон распределения пары
задан таблицей:
| xh | -1 | 0 | 1 |
| -1 | 1/12 | 1/4 | 1/6 |
| 1 | 1/4 | 1/12 | 1/6 |
Найти
закон распределения вероятностей случайной величины xh и вычислить cov(2x-3h,x+2h).
Исследовать вопрос о зависимости случайных величин x и h.
Задача 11
Составить двумерный закон распределения случайной
величины (X,Y), если известны законы независимых составляющих. Чему равен коэффициент
корреляции rxy?
| X | 20 | 25 | 30 | 35 |
| P | 0.1 | 0.1 | 0.4 | 0.4 |
и
Задача 12
Задано
распределение вероятностей дискретной двумерной случайной величины (X,Y):
| XY | 0 | 1 | 2 |
| -1 | ? | 0,1 | 0,2 |
| 1 | 0,1 | 0,2 | 0,3 |
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 13
Совместное
распределение двух дискретных случайных величин ξ и η задано таблицей:
| ξη | -1 | 1 | 2 |
| 0 | 1/7 | 2/7 | 1/7 |
| 1 | 1/7 | 1/7 | 1/7 |
Вычислить
ковариацию cov(ξ-η,η+5ξ). Зависимы ли ξ и η?
Задача 14
Рассчитать
коэффициенты ковариации и корреляции на основе заданного закона распределения
двумерной случайной величины и сделать выводы о тесноте связи между X и Y.
| XY | 2,3 | 2,9 | 3,1 | 3,4 |
| 0,2 | 0,15 | 0,15 | 0 | 0 |
| 2,8 | 0 | 0,25 | 0,05 | 0,01 |
| 3,3 | 0 | 0,09 | 0,2 | 0,1 |
Задача 15
Задан
закон распределения случайного вектора (ξ,η). Найдите ковариацию (ξ,η)
и коэффициент корреляции случайных величин.
| xy | 1 | 4 |
| -10 | 0,1 | 0,2 |
| 0 | 0,3 | 0,1 |
| 20 | 0,2 | 0,1 |
Задача 16
Для
случайных величин, совместное распределение которых задано таблицей
распределения. Найти:
а) законы
распределения ее компонент и их числовые характеристики;
b) условные законы распределения СВ X при условии Y=b и СВ Y при
условии X=a, где a и b – наименьшие значения X и Y.
с)
ковариацию и коэффициент корреляции случайных величин X и Y;
d) составить матрицу ковариаций и матрицу корреляций;
e) вероятность попадания в область, ограниченную линиями y=16-x2 и y=0.
f) установить, являются ли случайные величины X и Y зависимыми;
коррелированными.
| XY | -1 | 0 | 1 | 2 |
| -1 | 0 | 1/6 | 0 | 1/12 |
| 0 | 1/18 | 1/9 | 1/12 | 1/9 |
| 2 | 1/6 | 0 | 1/9 | 1/9 |
Задача 17
Совместный
закон распределения случайных величин X и Y задан таблицей:
|
XY |
0 |
1 |
3 |
|
0 |
0,15 |
0,05 |
0,3 |
|
-1 |
0 |
0,15 |
0,1 |
|
-2 |
0,15 |
0 |
0,1 |
Найдите:
а) закон
распределения случайной величины X и закон распределения
случайной величины Y;
б) EX, EY, DX, DY, cov(2X+3Y, X-Y), а
также математическое ожидание и дисперсию случайной величины V=6X-8Y+3.
Задача 18
Известен
закон распределения двумерной случайной величины (X,Y).
а) найти
законы распределения составляющих и их числовые характеристики (M[X],D[X],M[Y],D[Y]);
б)
составить условные законы распределения составляющих и вычислить
соответствующие мат. ожидания;
в)
построить поле распределения и линию регрессии Y по X и X по Y;
г)
вычислить корреляционный момент (коэффициент ковариации) μxy и
коэффициент корреляции rxy.
|
|
5 | 20 | 35 |
| 100 | — | — | 0.05 |
| 115 | — | 0.2 | 0.15 |
| 130 | 0.15 | 0.35 | — |
| 145 | 0.1 | — | —- |
Содержание:
Ковариация:
Важную информацию о системе случайных величин 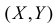
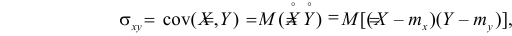
которая называется ковариацией или ковариационным моментом. Заметим, что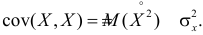 Из определения ковариации следует, что
Из определения ковариации следует, что 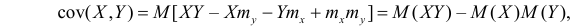
откуда
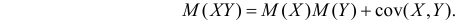
Кроме того, 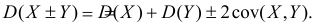
Если случайные величины X и Y независимы, то их ковариация равна нулю и тогда
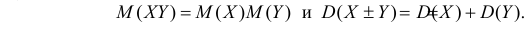
Ковариация содержит информацию о зависимости между величинами. Но значение 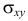 изменяется при изменении единиц измерения X и Y. Поэтому для характеристики зависимости между величинами удобно рассматривать величину
изменяется при изменении единиц измерения X и Y. Поэтому для характеристики зависимости между величинами удобно рассматривать величину
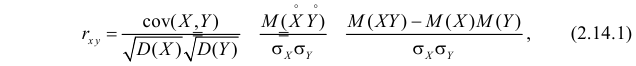
которая называется коэффициентом корреляции величин X и Y.
Величины 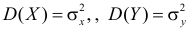 и
и 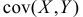 характеризуют разброс положений случайной точка на плоскости. Эти числовые характеристики принято записывать в виде матрицы
характеризуют разброс положений случайной точка на плоскости. Эти числовые характеристики принято записывать в виде матрицы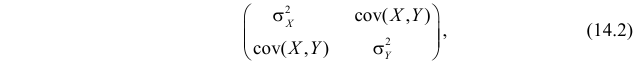
которую называют ковариационной матрицей системы случайных величин (X,Y).
Корреляционная зависимость
Наиболее простой и известной формой зависимости между величинами является функциональная зависимость, при которой каждому значению аргумента соответствует строго определенное значение функции. Функциональная зависимость может быть и между случайными величинами. Существует иной, широко распространенный в природе, тип зависимости между случайными величинами. Эта зависимость проявляется в том, что закон распределения одной случайной величины изменяется при изменении другой. Такая зависимость называется статистической.
Следует заметить, что функциональная зависимость бывает лишь в теоретических построениях или в условиях специально подготовленных опытов. Физический опыт в том и состоит, что исследователь старается по возможности исключить влияние всех посторонних факторов и наблюдать зависимость в чистом виде.
Явления окружающего нас мира взаимосвязаны и воздействие одной переменной на другую происходит при одновременном воздействии множества других переменных, поэтому даже функциональные зависимости проявляются как зависимости статистические.
Итак, при статистической зависимости изменение одной величины приводит к изменению закона распределения другой. Если Y – дискретная случайная величина, то это означает, что при каждом фиксированном значении 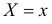 имеется набор возможных значений
имеется набор возможных значений 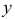 и соответствующих им вероятностей
и соответствующих им вероятностей 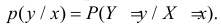 Последним обозначением подчеркивается, что речь идет о событии
Последним обозначением подчеркивается, что речь идет о событии 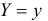 при условии, что произошло событие .
при условии, что произошло событие .
Набор возможных значений и соответствующих им условных вероятностей образует условный закон распределения 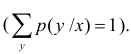
Для непрерывной случайной величины можно ввести понятие условной функции распределения или условной плотности вероятности. Если рассмотреть вероятности событий 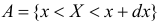 и
и 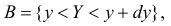 то по аналогии с теоремой умножения вероятностей событий можно получить для условной плотности вероятности
то по аналогии с теоремой умножения вероятностей событий можно получить для условной плотности вероятности 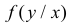 соотношение
соотношение 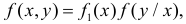 где
где 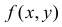 – плотность вероятности системы
– плотность вероятности системы 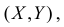 а
а 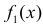 – маргинальная плотность вероятности случайной величины X. Из этого соотношения
– маргинальная плотность вероятности случайной величины X. Из этого соотношения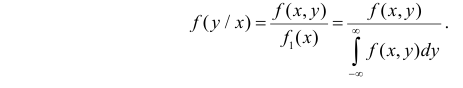
На протяжении этого раздела будем проводить выкладки только для дискретных случайных величин. Для непрерывных случайных величин все рассуждения и выводы останутся в силе, если заменить суммы на интегралы, а вероятности на плотности вероятности.
Статистическая зависимость сложна для изучения. Трудно проследить за изменением всего закона распределения сразу. Проще сосредоточиться на изучении изменения числовых характеристик, в первую очередь математического ожидания. Условный закон распределения имеет числовые характеристики такие же, как и обычные законы распределения. В частности, 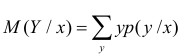 – для дискретной случайной величины называют условным математическим ожиданием, или средним значением Y при заданном значении . Для непрерывной случайной величины его вычисляют в виде
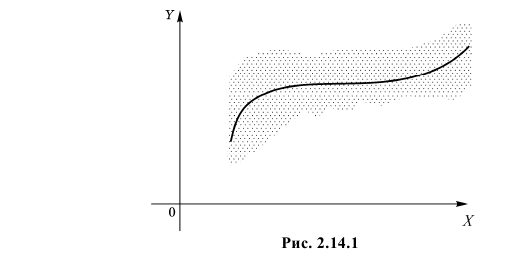
– для дискретной случайной величины называют условным математическим ожиданием, или средним значением Y при заданном значении . Для непрерывной случайной величины его вычисляют в виде 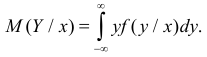 Если условные математические ожидания при разных значениях X соединить, то получится линия, называемая линией регрессии Y на X. Уравнение этой линии называют уравнением регрессии Y на X (см. рис. 2.14.1, на котором точками показаны возможные значения двумерной случайной величины ).
Если условные математические ожидания при разных значениях X соединить, то получится линия, называемая линией регрессии Y на X. Уравнение этой линии называют уравнением регрессии Y на X (см. рис. 2.14.1, на котором точками показаны возможные значения двумерной случайной величины ).
Корреляционной зависимостью Y от X называется функциональная зависимость условного среднего значения Y от X. Графиком корреляционной зависимости служит линия регрессии. Например, рост человека X и его вес Y связаны статистической зависимостью. Для каждого значения роста существует целое распределение возможных значений веса. Между этими величинами существует и корреляционная зависимость, которая для людей зрелого возраста выражается известной формулой:

Вместе с изменением условного среднего значения может изменяться и разброс Y относительно условного среднего значения. При каждом 142 значении можно вычислить дисперсию соответствующих значений Y. Эту дисперсию называют условной дисперсией. Например, для дискретной случайной величины условная дисперсия равна 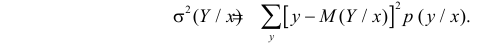
Всякую зависимость изучают для того, чтобы уметь по известному значению одной величины предсказывать значение другой. При статистической зависимости между величинами можно использовать для прогноза линию регрессии. Если стало известно, что , то в качестве предполагаемого значения Y можно назвать соответствующее условное среднее значение 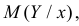 т.е. ординату линии регрессии при данном
т.е. ординату линии регрессии при данном 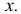 Если Y принимает значение
Если Y принимает значение 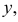 то
то 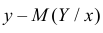 будет ошибкой прогноза и величину
будет ошибкой прогноза и величину 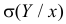 можно рассматривать как среднюю квадратическую ошибку прогноза Y по значению X при указанном способе действий.
можно рассматривать как среднюю квадратическую ошибку прогноза Y по значению X при указанном способе действий.
Представление о среднем квадрате ошибки прогноза Y по линии регрессии дает средняя из условных дисперсий
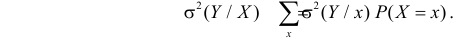
Здесь значения 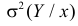 взяты с учетом вероятности каждого значения
взяты с учетом вероятности каждого значения 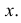 Величина
Величина 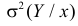 равна среднему квадрату отклонения значений Y от линии регрессии. Ее можно записать в виде
равна среднему квадрату отклонения значений Y от линии регрессии. Ее можно записать в виде 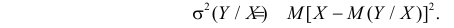
Заметим, что при прогнозе Y по любой другой линии средний квадрат ошибки прогноза будет больше. В самом деле, для любой постоянной 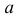
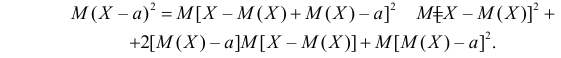
Второе слагаемое в правой части равно нулю, так как 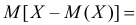
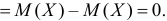 Третье слагаемое, очевидно, неотрицательно. Поэтому
Третье слагаемое, очевидно, неотрицательно. Поэтому 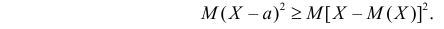
Равенство возможно лишь при 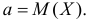 Это означает, что средняя квадратическая ошибка прогноза будет наименьшей, если случайную величину прогнозировать по ее среднему значению. Линия регрессии проходит через условные средние значения Y. Поэтому можно утверждать, что линия регрессии минимизирует среднюю квадратическую ошибку прогноза случайной величины Y по наблюдаемому значению величины X.
Это означает, что средняя квадратическая ошибка прогноза будет наименьшей, если случайную величину прогнозировать по ее среднему значению. Линия регрессии проходит через условные средние значения Y. Поэтому можно утверждать, что линия регрессии минимизирует среднюю квадратическую ошибку прогноза случайной величины Y по наблюдаемому значению величины X.
Линейная корреляция
Корреляция называется линейной, если линия регрессии одной величины на другую является прямой. В противном случае говорят о нелинейной корреляции.
Пусть линия регрессии имеет вид 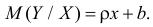 Согласно свойству линии регрессии, должен быть минимален средний квадрат отклонений Y от этой линии, т.е. минимальной должна быть величина
Согласно свойству линии регрессии, должен быть минимален средний квадрат отклонений Y от этой линии, т.е. минимальной должна быть величина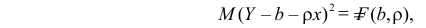
причем ее минимальное значение равно 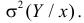
Параметры 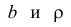 можно найти из условия минимума функции
можно найти из условия минимума функции 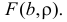 Необходимые условия экстремума дают систему уравнений
Необходимые условия экстремума дают систему уравнений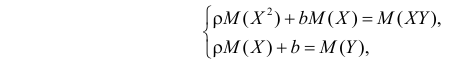
решения которой имеют вид 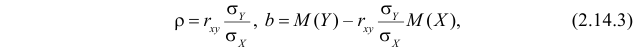
где 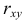 – коэффициент корреляции (2.14.1). Если выражения (2.14.3) подставить в
– коэффициент корреляции (2.14.1). Если выражения (2.14.3) подставить в 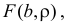 то после ряда преобразований получается, что
то после ряда преобразований получается, что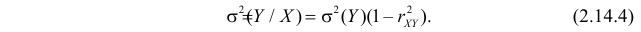
Из соотношений (2.14.3) и (2.14.4) можно извлечь информацию о свойствах коэффициента корреляции.
1. Так как 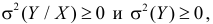 то
то 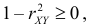 откуда
откуда 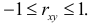
2. Если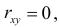 то в силу (2.14.3) и угловой коэффициент линии регрессии равен нулю. Линия регрессии параллельна оси ОX. В этом случае говорят, что величины некоррелированы, так как среднее значение Y не изменяется при изменении X. Отсутствие корреляционной зависимости не всегда означает независимость величин. Например, при постоянном среднем значении Y может изменяться разброс значений относительно среднего (см. рис. 2.14.2, на котором точками изображены возможные положения случайной точки).
то в силу (2.14.3) и угловой коэффициент линии регрессии равен нулю. Линия регрессии параллельна оси ОX. В этом случае говорят, что величины некоррелированы, так как среднее значение Y не изменяется при изменении X. Отсутствие корреляционной зависимости не всегда означает независимость величин. Например, при постоянном среднем значении Y может изменяться разброс значений относительно среднего (см. рис. 2.14.2, на котором точками изображены возможные положения случайной точки).
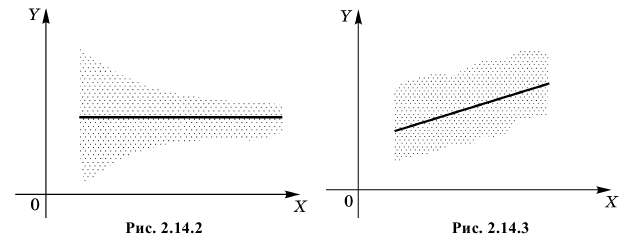
3. Из (2.14.3) следует, что угловой коэффициент линии регрессии 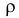 и коэффициент корреляции имеют одинаковые знаки. Если
и коэффициент корреляции имеют одинаковые знаки. Если 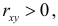 то говорят, что величины коррелированы положительно. В этом случае большему значению величины X соответствует большее среднее значение Y (см. рис. 2.14.3). Еще раз подчеркнем, что речь идет именно об увеличении среднего значения Y. В отдельных опытах большему X может соответствовать меньшее Y. Например, положительно коррелированы рост и вес человека, возраст и высота дерева, качество сырья и качество продукции и т.д.
то говорят, что величины коррелированы положительно. В этом случае большему значению величины X соответствует большее среднее значение Y (см. рис. 2.14.3). Еще раз подчеркнем, что речь идет именно об увеличении среднего значения Y. В отдельных опытах большему X может соответствовать меньшее Y. Например, положительно коррелированы рост и вес человека, возраст и высота дерева, качество сырья и качество продукции и т.д.
Если  то говорят, что величины коррелированы отрицательно. Это означает, что большему значению одной величины соответствует в среднем меньшее значение другой. Например, число пропусков занятий и успеваемость коррелированы отрицательно.
то говорят, что величины коррелированы отрицательно. Это означает, что большему значению одной величины соответствует в среднем меньшее значение другой. Например, число пропусков занятий и успеваемость коррелированы отрицательно.
4. Если  то из (2.14.4) следует, что
то из (2.14.4) следует, что 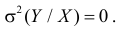 В этом случае разброса относительно линии регрессии нет. Между величинами существует линейная функциональная зависимость.
В этом случае разброса относительно линии регрессии нет. Между величинами существует линейная функциональная зависимость.
5. Из (2.14.4) следует, что 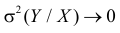 при
при 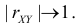 Значит, чем больше по модулю коэффициент корреляции, тем теснее прилегают значения Y к линии регрессии, тем меньше средний квадрат ошибки прогноза Y по наблюдаемому значению X. На рис. 2.14.4 для сравнения показан разброс положений случайной точки
Значит, чем больше по модулю коэффициент корреляции, тем теснее прилегают значения Y к линии регрессии, тем меньше средний квадрат ошибки прогноза Y по наблюдаемому значению X. На рис. 2.14.4 для сравнения показан разброс положений случайной точки 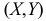 относительно линии регрессии при двух разных значениях коэффициента корреляции
относительно линии регрессии при двух разных значениях коэффициента корреляции 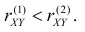
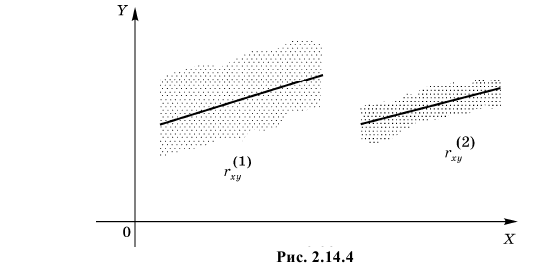
Коэффициент корреляции служит мерой линейной зависимости между величинами. Он показывает насколько статистическая зависимость близка к функциональной.
Отметим, что в силу (2.14.3) уравнение линии регрессии можно записать в виде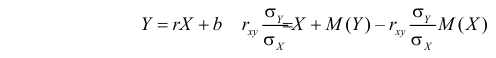
или
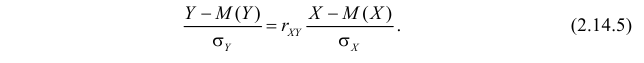
Пример №1
Случайные величины X и Y независимы и имеют одинаковое распределение с математическим ожиданием 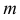 и дисперсией
и дисперсией 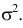
1) Найти коэффициент корреляции случайных величин 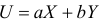 и
и 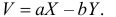
2) Найти коэффициент корреляции между случайными величинами 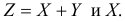
Решение. 1) По определению 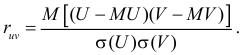 Найдем необходимые для вычисления
Найдем необходимые для вычисления  величины. По свойствам математического ожидания и дисперсии имеем:
величины. По свойствам математического ожидания и дисперсии имеем:
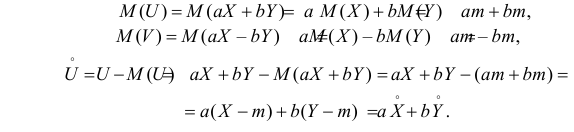
Аналогично, 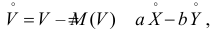
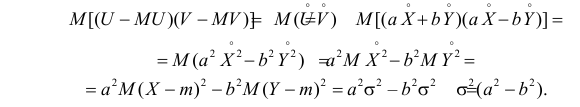
Так как X и Y независимы, то 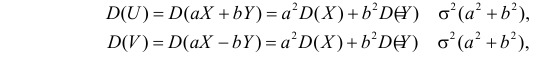
В результате имеем
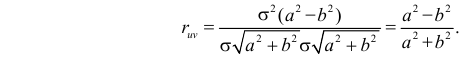
2) Вычислим величины, которые необходимы для использования формулы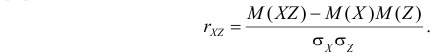
Так как X и Y независимы, то 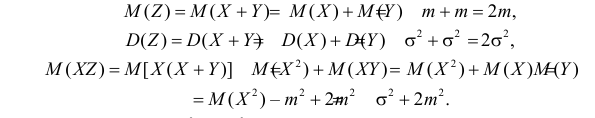
Поэтому 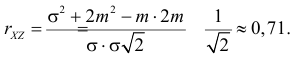
Ответ. 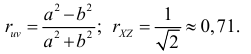
Пример №2
Равновозможны все положения случайной точки 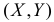 в треугольнике D с вершинами А(0,0), В(0,1) и С(2,1). Найти коэффициент корреляции случайных величин X и Y. Найти линию регрессии Y на X и оценить точность прогноза величины Y по наблюдаемому значению X.
в треугольнике D с вершинами А(0,0), В(0,1) и С(2,1). Найти коэффициент корреляции случайных величин X и Y. Найти линию регрессии Y на X и оценить точность прогноза величины Y по наблюдаемому значению X.
Решение. Равновозможность всех положений случайной точки 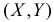 в треугольнике АВС (см. рис. 2.14.5) означает, что плотность вероятности
в треугольнике АВС (см. рис. 2.14.5) означает, что плотность вероятности 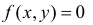 вне этого треугольника, а в точках треугольника постоянна.
вне этого треугольника, а в точках треугольника постоянна.
Площадь треугольника АВС равна 1. В точках треугольника положим 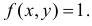 Тем самым соблюдено условие равенства единице объема, заключенного между функцией плотности вероятности и координатной плоскостью (напомним, что это является одним из отличительных свойств функции плотности вероятности системы двух случайных величин).
Тем самым соблюдено условие равенства единице объема, заключенного между функцией плотности вероятности и координатной плоскостью (напомним, что это является одним из отличительных свойств функции плотности вероятности системы двух случайных величин).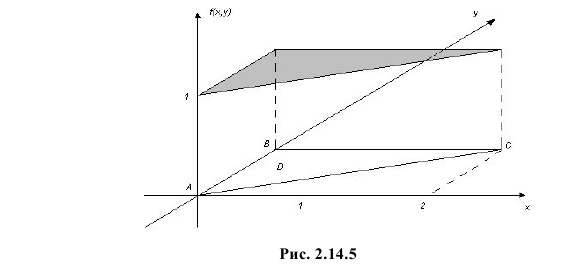
Маргинальные функции плотности вероятности величин X и Y равны соответственно:
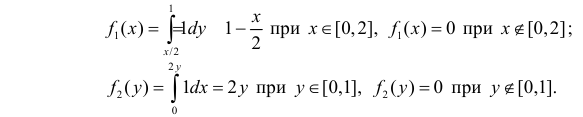
Вычислим величины, необходимые для использования формул (2.14.3) и (2.14.5): 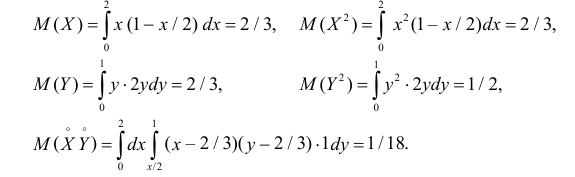
Тогда 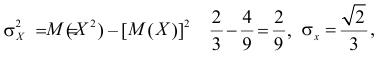
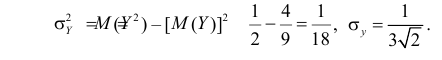
По формулам (2.14.3), (2.14.5) находим коэффициент корреляции 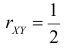 и уравнение линии регрессии
и уравнение линии регрессии 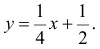 Если использовать эту линию регрессии для прогноза Y по известному значению X, то средний квадрат ошибки прогноза по формуле (2.14.4) равен
Если использовать эту линию регрессии для прогноза Y по известному значению X, то средний квадрат ошибки прогноза по формуле (2.14.4) равен 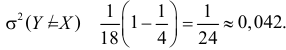
Ответ. 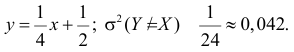
Пример №3
Подбрасывают два игральных кубика. Пусть X – число выпавших «пятерок», а Y – число нечетных очков. Найдите закон 149 распределения случайного вектора 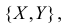 его математическое ожидание и дисперсионную матрицу. Найдите коэффициент корреляции
его математическое ожидание и дисперсионную матрицу. Найдите коэффициент корреляции 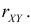
Решение. Если кубики однородны и симметричны, то вероятность выпадения каждой грани равна 1/6. Запишем сначала закон распределения случайного вектора 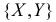 . Каждая из компонент вектора может принимать только значения 0, 1 и 2. Поэтому закон распределения можно представить в виде таблицы:
. Каждая из компонент вектора может принимать только значения 0, 1 и 2. Поэтому закон распределения можно представить в виде таблицы: 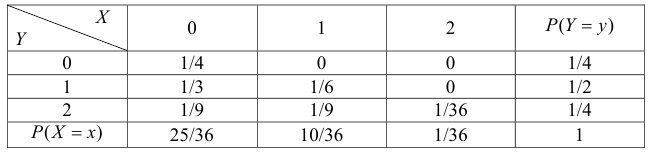
В клетках таблицы записаны вероятности 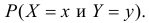 Например, 1
Например, 1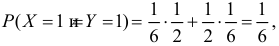 так как с вероятностью
так как с вероятностью 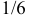 на первом кубике появится «5», а на втором кубике с вероятностью
на первом кубике появится «5», а на втором кубике с вероятностью 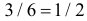 выпадет четное число, либо наоборот, на первом кубике – четное число, а на втором – «5». Или, например,
выпадет четное число, либо наоборот, на первом кубике – четное число, а на втором – «5». Или, например, 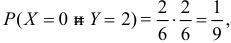 так как на каждом кубике должна выпасть нечетная цифра, но не «5». Вычислим числовые характеристики случайного вектора:
так как на каждом кубике должна выпасть нечетная цифра, но не «5». Вычислим числовые характеристики случайного вектора:
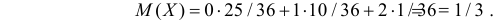
Заметим, что X имеет биномиальное распределение. Поэтому математическое ожидание можно было подсчитать проще: 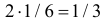 – произведение числа опытов на вероятность появления события в одном опыте. Аналогично,
– произведение числа опытов на вероятность появления события в одном опыте. Аналогично,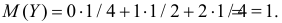 Для вычисления дисперсий вычислим предварительно математические ожидания квадратов величин:
Для вычисления дисперсий вычислим предварительно математические ожидания квадратов величин: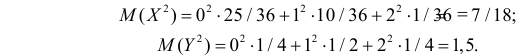
Тогда 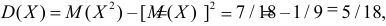
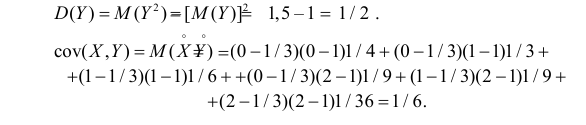
Дисперсионная матрица случайного вектора имеет вид 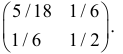
Коэффициент корреляции равен
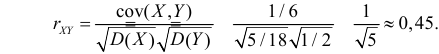
Ответ. 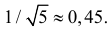
Замечание. Рассмотрим индикатор события A:
Известно, что 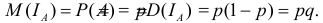 Силу зависимости между событиями A и B можно оценить по величине коэффициента корреляции индикаторов этих событий. По формуле (2.14.1) имеем
Силу зависимости между событиями A и B можно оценить по величине коэффициента корреляции индикаторов этих событий. По формуле (2.14.1) имеем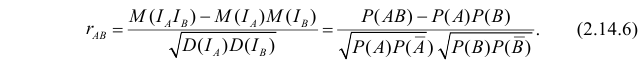
Коэффициент 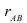 принимает значения в [-1;1], но есть некоторые особенности в трактовке значений коэффициента.
принимает значения в [-1;1], но есть некоторые особенности в трактовке значений коэффициента.
Если 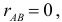 то события независимы и наоборот (вспомните, для случайных величин факт равенства коэффициента корреляции нулю не означал независимость случайных величин). Положительные значения коэффициента корреляции говорят о том, что появление одного события увеличивает вероятность появления другого. Например, из рис. 2.14.6 видно, что отношение площади области B к площади прямоугольника меньше, чем отношение площади области AB к площади области A. Поэтому факт появления события A увеличивает вероятность появления события B.
то события независимы и наоборот (вспомните, для случайных величин факт равенства коэффициента корреляции нулю не означал независимость случайных величин). Положительные значения коэффициента корреляции говорят о том, что появление одного события увеличивает вероятность появления другого. Например, из рис. 2.14.6 видно, что отношение площади области B к площади прямоугольника меньше, чем отношение площади области AB к площади области A. Поэтому факт появления события A увеличивает вероятность появления события B.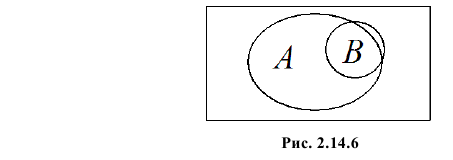
Чем ближе к плюс единице значение , тем в большей степени проявляется это увеличение. При 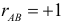 появление одного события всегда влечет появление другого. Если же
появление одного события всегда влечет появление другого. Если же 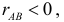 то появление одного события уменьшает вероятность появления другого. Например, из рис. 2.14.7 видно, что отношение площади области B к площади прямоугольника больше, чем отношение площади области AB к площади области A. Поэтому факт появления события A уменьшает вероятность появления события B. Значение
то появление одного события уменьшает вероятность появления другого. Например, из рис. 2.14.7 видно, что отношение площади области B к площади прямоугольника больше, чем отношение площади области AB к площади области A. Поэтому факт появления события A уменьшает вероятность появления события B. Значение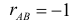 свидетельствует о том, что появление одного события исключает появление другого.
свидетельствует о том, что появление одного события исключает появление другого. 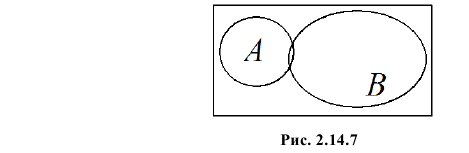
Пример №4
В одной урне четыре белых и два черных шара, а во второй два белых и три черных. Обозначим через A и B выбор белого шара соответственно из первой и второй урны. Ясно, что 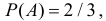 а 152 P( ) 2 / 5 B = и события независимы. Пусть при выборе из первой урны белого шара, его перекладывают во вторую урну и только потом выбирают из нее шар. Оценить силу зависимости между событиями A и B.
а 152 P( ) 2 / 5 B = и события независимы. Пусть при выборе из первой урны белого шара, его перекладывают во вторую урну и только потом выбирают из нее шар. Оценить силу зависимости между событиями A и B.
Решение. Для вычисления коэффициента корреляции воспользуемся формулой (2.14.6):
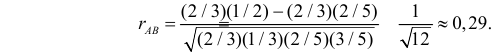
Заметим, что в случае добавлении не одного, а двух белых шаров во вторую урну этот коэффициент равен
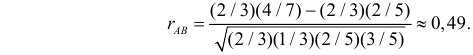
Ответ. 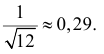
- Функциональные преобразования двухмерных случайных величин
- Правило «трех сигм» в теории вероятности
- Производящие функции
- Теоремы теории вероятностей
- Основные законы распределения вероятностей
- Асимптотика схемы независимых испытаний
- Функции случайных величин
- Центральная предельная теорема
Ковариации двух случайных величин
Содержание:
- Ковариации двух случайных величин. Коэффициент корреляции
Ковариации двух случайных величин. Коэффициент корреляции
1. Пусть с испытанием связаны случайные величины  с числовыми характеристиками
с числовыми характеристиками 
 Ковариацией случайных величин
Ковариацией случайных величин  называется число
называется число

Из определения следует: в дискретном случае
 (22)
(22)
в непрерывном случае
 (23)
(23)
Укажем основные свойства ковариации.
1°. 
2°. 
3″. Если  независимы, то
независимы, то 
4°.  .
.
5°. Если в 4° имеет место равенство:  то между
то между  имеется линейная функциональная связь:
имеется линейная функциональная связь:
 при некоторых А,В,С.
при некоторых А,В,С.
Геометрически это означает, что реализации случайной точки  с достоверностью ложатся на прямую
с достоверностью ложатся на прямую 

Докажем свойства 1° — 4°.
1. 
2.



3. Из независимости  следует независимость случайных величин
следует независимость случайных величин  Так как математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий, то имеем
Так как математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий, то имеем


 .
.
4. Доказательство этого свойства проведем для непрерывного случая. Представим указанную в начале параграфа интегральную формулу для ковариации в виде

где обозначено

(для удобства записи пределы интегрирования опущены).
Воспользуемся известным фактом математического анализа — неравенством Буняковского: для любых непрерывных  и любой области D
и любой области D

Отсюда следует:


Имеем:


В этом вычислении учтено свойство 5° плотности вероятности  и определение дисперсии непрерывной случайной величины. Аналогично найдем
и определение дисперсии непрерывной случайной величины. Аналогично найдем

Таким образом

что и требовалось.
2. На практике при изучении совместных свойств случайных величин, как правило, пользуются нормированной ковариацией или коэффициентом корреляции:
 (24)
(24)
Из свойств ковариации вытекают следующие свойства коэффициента корреляции.
1°. 
2°. Если  , то между
, то между  имеется линейная функциональная связь (рис.26). Уравнение прямой вычисляется по параметрам
имеется линейная функциональная связь (рис.26). Уравнение прямой вычисляется по параметрам 

3°. Если  независимы, то
независимы, то  .
.
Замечание 1. Из 1°-3° следует, что коэффициент корреляции (и, соответственно, ковариации) является некой мерой связи между  Более подробные рассмотрения показывают следующее. Если
Более подробные рассмотрения показывают следующее. Если  , то связь между
, то связь между  близка к линейной функциональной: реализации случайной точки
близка к линейной функциональной: реализации случайной точки  с практической достоверностью ложатся вблизи заранее прогнозируемой прямой
с практической достоверностью ложатся вблизи заранее прогнозируемой прямой  . Если
. Если  то либо
то либо  независимы, либо связь между ними имеется, но далека от линейной связи.
независимы, либо связь между ними имеется, но далека от линейной связи.
Помнить: коэффициент корреляции является мерой линейной связи между случайными величинами.
Замечание 2. В силу свойства 3° из независимости случайных величин  следует
следует  . Обратное утверждение неверно: имеются примеры, когда
. Обратное утверждение неверно: имеются примеры, когда  и при этом
и при этом  зависимы. Укажем важный частный случай, когда из следует независимость
зависимы. Укажем важный частный случай, когда из следует независимость  Будем говорить, что случайные величины
Будем говорить, что случайные величины  имеют совместное нормальное распределение с параметрами
имеют совместное нормальное распределение с параметрами  , если плотность вероятности случайной точки
, если плотность вероятности случайной точки  дается формулой
дается формулой
 (25)
(25)
где

 Можно показать, что
Можно показать, что  — математические ожидания,
— математические ожидания, 
 — СКО случайных величин r — коэффициент корреляции.
— СКО случайных величин r — коэффициент корреляции.
 (26)
(26)
где

Нетрудно показать, используя свойство 5° плотности вероятности  что
что  — плотности вероятности случайных величин
— плотности вероятности случайных величин  поэтому в силу свойства 6°
поэтому в силу свойства 6° 
 независимы.
независимы.
Помнить: в нормальном случае коэффициент корреляции является точной мерой связи между 
Замечание 3. Числа  называются числовыми характеристиками случайной точки
называются числовыми характеристиками случайной точки  Пары
Пары  характеризуют отдельно
характеризуют отдельно  является мерой связи между
является мерой связи между  В непрерывном случае параметр r вычисляется по формулам (23), (24), остальные параметры по формулам
В непрерывном случае параметр r вычисляется по формулам (23), (24), остальные параметры по формулам

Задача пример №15.
Найти числовые характеристики случайной точки  в ситуации примера Гл.4, §2.
в ситуации примера Гл.4, §2.
Решение:
Имеем




Коэффициент корреляции найдем по формулам (22), (24) с учетом свойства 2° для ковариации. Имеем



откуда

Задача пример №16.
Найти числовые характеристики случайной точки  в ситуации примера на Гл. 4, §2.
в ситуации примера на Гл. 4, §2.
Решение:
Имеем

Коэффициент корреляции найдем по формулам (23), (24)





откуда

Эта лекция взята из полного курса лекци по предмету «теория вероятностей», там вы найдёте другие лекци по всем темам теории вероятности:
Другие темы которые вам помогут понять математику:
Лекции:
- Совместное распределение нескольких случайных величин. Многомерный нормальный закон
- Закон больших чисел в форме Чебышева
- Теорема Бернулли
- Центральная предельная теорема
- Теория случайных процессов и теория массового обслуживания
- Закон Пуассона
- Показательный закон
- Нормальный закон
- Закон распределения случайной точки дискретного типа на плоскости
- Закон распределения случайной точки непрерывною типа на плоскости
Ковариация
Характеристикой
зависимости между случайными величинами
X
и Y
служит математическое ожидание
произведения отклонений X
и Y от их
центров распределений (так иногда
называют математическое ожидание
случайной величины), которое называется
коэффициентом ковариации или просто
ковариацией.
Cov(X;Y) = E((X–EX)(Y–EY))
Пусть
X = x1,
x2,
x3,,
xn,
Y= y1,
y2,
y3,,yn.
Тогда
Cov(X;Y)=![]()
Эту
формулу можно интерпретировать так.
Если при больших значениях Х
более вероятны большие значения Y,
а при малых значениях X
более вероятны малые значения Y,
то в правой части формулы ковариации
положительные слагаемые
доминируют, и ковариация принимает
положительные значения.
Если
же более вероятны произведения
(xi – EX)(yj – EY),
состоящие из сомножителей разного
знака, то есть исходы случайного
эксперимента, приводящие к большим
значениям X
в основном приводят к малым значениям
Y и наоборот,
то ковариация принимает большие по
модулю отрицательные значения.
В
первом случае принято говорить о прямой
связи: с ростом X
случайная величина Y
имеет тенденцию к возрастанию.
Во
втором случае говорят об обратной связи:
с ростом X
случайная величина Y
имеет тенденцию к уменьшению или падению.
Если
примерно одинаковый вклад в сумму дают
и положительные и отрицательные
произведения (xi – EX)(yj – EY)pij,
то можно сказать, что в сумме они будут
“гасить” друг друга и ковариация будет
близка к нулю. В этом случае не
просматривается зависимость одной
случайной величины от другой.
Легко
показать, что если
P((X = xi)∩(Y = yj)) = P(X = xi)P(Y = yj)
(i = 1,2,,n;
j = 1,2,,k),
то
cov(X;Y)=
0.
Действительно
из (2) следует
![]()
![]()
![]()
Здесь
использовано очень важное свойство
математического ожидания: математическое
ожидание отклонения случайной величины
от ее математического ожидания равно
нулю.
Ковариацию
удобно представлять в виде
Cov(X;Y)=E(XY–XEY–YEX+EXEY)=E(XY)–E(XEY)–E(YEX)+E(EXEY)=
=E(XY)–EXEY–EXEY+EXEY=E(XY)–EXEY
Ковариация
двух случайных величин равна математическому
ожиданию их произведения минус
произведение математических ожиданий.
Поскольку
для независимых случайных величин EXY
= EXEY,
то, очевидно, что для
независимых случайных величин X
и Y cov(X;Y)=0.
Определение.
Случайные величины, ковариация которых
равна нулю, называют некоррелированными.
!!!
Замечание.
Как было
показано выше, из независимости случайных
величин следует их некоррелированность,
то есть равенство нулю корреляции.
Обратное
неверно! Рассмотрим
соответствующий пример:
Пусть
случайная величина Х имеет равномерное
распределение на интервале (-1, 1), а
случайная величина Y
связана со случайной величиной Х
функциональной зависимостью Y=X2
. Покажем, что cov
(X,Y)=0,
хотя налицо функциональная зависимость
.
Учитывая
, что ЕХ=0 (середина интервала (-1,1)),
получаем:
cov
(X,Y)=EXY-EXEY=EX3
=

Итак,
из некоррелированности случайных
величин не следует их независимость.
Ковариация
случайных величин отражает степень
близости зависимости случайных величин
к линейной, то есть, к зависимости вида
Y=aX+b.
Рассмотрим
теперь еще одну меру линейной зависимости
– коэффициент
корреляции
случайных величин Х и Y
r(X,Y)
=
![]()
Может
возникнуть вопрос, зачем вводить еще
одну меру линейной зависимости?
-
Коэффициент
корреляции меняется от -1 до 1, а не по
всей числовой оси -
Коэффициент
корреляции, в отличие от ковариации,
нечувствителен к смене единиц измерения -
Если
случайные величины независимы, то
коэффициент корреляции, как и ковариация,
равен нулю. -
Если
случайные величины линейно зависимы,
то r=1
– прямая зависимость , r=-1,
обратная. И наоборот, из равенства по
модулю 1 следует линейная зависимость.
Пусть
распределение случайных величин задано
таблицей

ЕХ1![]()
ЕХ2![]()
DX1
= EX1
2
– (EX1)2=
0,59
DX2
= EX2
2
– (EX2)2=
0,2475
Cov
(X1
,X2
)= E (X1
,X2
)–E X1
EX2
E
(X1
,X2
) =
![]()

Замечание.
Ковариационная и корреляционная матрицы
– это таблицы, состоящие соответственно
из ковариаций и коэффициентов корреляций
соответствующих случайных величин.
(Заметим, что по главной диагонали
корреляционной матрицы стоят 1 –
случайная величина, очевидно, находится
сама с собой в линейной зависимости).
Используются эти матрицы для наглядного
представления данных о связи величин
и в статистике.
Соседние файлы в папке Модуль 1. Лекции
- #
- #
- #
- #
- #
- #
- #
![]()
Download Article
![]()
Download Article
Covariance is a statistical calculation that helps you understand how two sets of data are related to each other. For example, suppose anthropologists are studying the heights and weights of a population of people in some culture. For each person in the study, the height and weight can be represented by an (x,y) data pair. These values can be used with a standard formula to calculate the covariance relationship. This article will first explain the calculations that go into finding the covariance of a data set. It will then address two more automated ways to find the result.
-

1
Learn the standard covariance formula and its parts. The standard formula for calculating covariance is
. To use this formula, you need to understand the meaning of the variables and symbols:[1]
-
2
Set up your data table. Before you begin working, it is helpful to collect your data. You should make a table that consists of five columns. You should label each column as follows:
Advertisement
-
3
Calculate the average of the x-data points. This sample data set contains 9 numbers. To find the average, add them together and divide the sum by 9. This gives you the result of 1+3+2+5+8+7+12+2+4=44. When you divide by 9, the average is 4.89. This is the value that you will use as x(avg) for the coming calculations.[3]
-
4
Calculate the average of the y-data points. Similarly, the y-column should consist of 9 data points that coincide with the x-data points. Find the average of these. For this sample data set, this will be 8+6+9+4+3+3+2+7+7=49. Divide this sum by 9 to get an average of 5.44. You will use 5.44 as the value of y(avg) for the coming calculations.[4]
-
5
Calculate the
values. For each item in the x column, you need to find the difference between that number and the average value. For this sample problem, this means subtracting 4.89 from each x-data point. If the original data point is less than the average, then your result will be negative. If the original data point is greater than the average, then your result will be positive. Make sure that you keep track of the negative signs.[5]
- For example, the first data point in the x column is 1. The value to enter on the first line of the column is 1-4.89, which is -3.89.
- Repeat the process for each data point. Therefore, the second line will be 3-4.89, which is -1.89. The third line will be 2-4.89, or -2.89. Continue the process for all the data points. The nine numbers in this column should be -3.89, -1.89, -2.89, 0.11, 3.11, 2.11, 7.11, -2.89, -0.89.
- For example, the first data point in the x column is 1. The value to enter on the first line of the
-
6
Calculate the
values. In this column, you will perform similar subtractions, using the y-data points and the y average. If the original data point is less than the average, then your result will be negative. If the original data point is greater than the average, then your result will be positive. Make sure that you keep track of the negative signs.[6]
- For the first line, therefore, your calculation will be 8-5.44, which is 2.56.
- The second line will be 6-5.44, which is 0.56.
- Continue these subtractions to the end of the data list. When you finish, the nine values in this column should be 2.56, 0.56, 3.56, -1.44, -2.44, -2.44, -3.44, 1.56, 1.56.
-
7
Calculate the products for each data row. You will fill in the rows of the final column by multiplying the numbers that you calculated in the two previous columns of
and . Be careful to work row by row, and multiply the two numbers for the corresponding data points. Keep track of any negative signs as you go.[7]
- On the first row of this data sample, the that you calculated is -3.89, and the value is 2.56. The product of these two numbers is -3.89*2.56=-9.96.
- For the second row, you will multiply the two numbers -1.88*0.56=-1.06.
- Continue multiplying row by row to the end of the data set. When you finish, the nine values in this column should be -9.96, -1.06, -10.29, -0.16, -7.59, -5.15, -24.46, -4.51, -1.39.
- On the first row of this data sample, the
-
8
Find the sum of the values in the last column. This is where the Σ symbol comes into play. After conducting all the calculations that you have done so far, you will add the results. For this sample data set, you should have nine values in the final column. Add those nine numbers together. Pay careful attention to whether each number is positive or negative.
- For this sample data set, the sum should be -64.57. Write this total in the space at the bottom of the column. This represents the value of the numerator of the standard covariance formula.
-
9
Calculate the denominator for the covariance formula. The numerator for the standard covariance formula is the value that you have just completed calculating. The denominator is represented by (n-1), which is just one less than the number of data pairs in your data set.
- For this sample problem, there are nine data pairs, so n is 9. The value of (n-1), therefore, is 8.
-
10
Divide the numerator by the denominator. The final step in calculating the covariance is to divide your numerator,
by your denominator, . The quotient is the covariance of your data.[8]
- For this sample data set, this calculation is -64.57/8, which gives the result of -8.07.















Advertisement
-
1
Notice the repetitive calculations. Covariance is a calculation that you should perform a few times by hand, so you understand the meaning of the result. However, if you are going to be using covariance values routinely in interpreting data, you will want to find a faster and more automated way to get your results. You should notice by now that for our relatively small data set of only nine pairs of data, the calculations included finding two averages, performing eighteen individual subtractions, nine separate multiplications, one addition, and a final division. That is 31 relatively minor calculations in order to find one solution. Along the way, you risk dropping negative signs or copying your results incorrectly, thereby ruining the result.
-
2
Create a spreadsheet to calculate covariance. If you are comfortable using Excel (or some other spreadsheet with calculation abilities), you can easily set up a table to find covariance. Label the headings of five columns as for the hand calculations: x, y, (x(i)-x(avg)), (y(i)-y(avg)) and Product.[9]
- To simplify your labelling, you could call the third column something like “x difference” and the fourth column “y difference,” as long as you remember the meaning of the data.
- If you begin your table in the top left corner of the spreadsheet, then cell A1 will be the x label, with the other labels going across to cell E1.
-
3
Fill in the data points. Enter your data values in the two columns labelled x and y. Remember that the order of the data points matters, so you need to pair each y with its corresponding x value.[10]
- Your x values will begin in cell A2 and will continue down for as many data points as you need.
- Your y values will begin in cell B2 and will continue down for as many data points as you need.
-
4
Find the averages of the x and y values. Excel will calculate the averages for you very quickly. In the first vacant cell below each column of data, enter the formula =AVG(A2:A___). Fill in the blank space with the number of the cell that corresponds to your last data point.[11]
- For example, if you have 100 data points, they will fill in cells A2 through A101, so you will enter =AVG(A2:A101).
- For the y data, enter the formula =AVG(B2:B101).
- Remember that you begin a formula in Excel with an = sign.
-
5
Enter the formula for the (x(i)-x(avg)) column. In cell C2, you will need to enter the formula to calculate the first subtraction. This formula will be =A2-____. You will fill in the blank space with the cell address that contains the average of your x data.[12]
- For the example of 100 data points, the average would be in cell A103, so your formula will be =A2-A103.
-
6
Repeat the formula for the (y(i)-y(avg)) data points. Following the same example, this would go into cell D2. The formula will be =B2-B103.
-
7
Enter the formula for the “Product” column. In the fifth column, into cell E2, you will need to enter the formula to calculate the product of the two prior cells. This would simply be =C2*D2.[13]
-
8
Copy the formulas down to fill the table. So far, you have only programmed the first pair of data points in row 2. Using your mouse, highlight cells C2, D2 and E2. Then position your cursor over the small box in lower right-hand corner until a plus-sign appears. Click your mouse button, hold it down, and drag the mouse downward to expand the highlighted box to fill your entire data table. This step will automatically copy the three formulas from cells C2, D2 and E2 into the whole table. You should see the table automatically fill with all the calculations.[14]
-
9
Program the sum of the last column. You need to find the sum of the items in the “Product” column. In the vacant cell immediately under the last data point in that column, enter the formula =sum(E2:E___). Fill in the blank space with the cell address of the last data point.[15]
- For the example of 100 data points, this formula will go into cell E103. You will enter =sum(E2:E102).
-
10
Find the covariance. You can have Excel perform the final calculation for you as well. The last calculation, in cell E103 in our example, represents the numerator of the covariance formula. Immediately below that cell, you can enter the formula =E103/___. Fill in the blank space with the number of data points that you have. In our example, this will be 100. The result will be the covariance of your data.[16]










Advertisement
-
1
Search the Internet for covariance calculators. Several schools, programming companies or other sources have created websites that will very easily calculate covariance values for you. Using any search engine, enter the search term “covariance calculator.”
-
2
Enter your data. Read the instructions on the website carefully to make sure that you enter your data properly. It is important that your data pairs are kept in order, or you will generate an incorrect covariance result. Different websites have different styles for entering your data.
- For example, at the website http://ncalculators.com/statistics/covariance-calculator.htm, there is a horizontal box for entering x-values and a second horizontal box for entering y-values. You are instructed to enter your terms, separated only by commas. Thus, the x-data set that was calculated earlier in this article would be entered as 1,3,2,5,8,7,12,2,4. The y-data set would be 8,6,9,4,3,3,2,7,7.
- At another site, https://www.thecalculator.co/math/Covariance-Calculator-705.html, you are prompted to enter your x-data in the first box. Data is entered vertically, with one item per line. Therefore, the entry on this site would look like:
- 1
- 3
- 2
- 5
- 8
- 7
- 12
- 2
- 4
-
3
Calculate your results. The attraction of these calculation sites is that after you enter your data, you generally need only to click on the button that says “Calculate,” and the results will appear automatically. Most sites will provide you with the intermediate calculations of the x(avg), y(avg), and n.



Advertisement
-
1
Look for a positive or negative relationship. The covariance is a single statistical figure that represents how one data set relates to another. In the example mentioned in the introduction, height and weight are being measured. You would expect that as individuals grow taller, their weight would also increase, leading to a positive covariance figure. As another example, suppose data is collected representing the number of hours someone practices golf and the score he or she may earn. In this case, you would expect a negative covariance, which means that as the number of practice hours increases, the golf score will decrease. (In golf, a lower score is better.)
- Consider the sample data set that was calculated above. The resulting covariance is -8.07. The negative sign here means that as the x-values increase, the y-values will tend to decrease. In fact, you can see that this is true by looking at a few of the values. For example, the x-values of 1 and 2 correspond to y-values of 7, 8 and 9. The x-values of 8 and 12 are paired respectively with y-values of 3 and 2.
-
2
Interpret the magnitude of the covariance. If the number of the covariance score is large, either a large positive number or a large negative number, then you can interpret this as meaning that the two data elements are very strongly connected, either in a positive or negative way.
- For the sample data set, the covariance of -8.07 is fairly large. Notice that the data values range from 1 through 12, so 8 is a pretty high number. This indicates a strong connection between the x and y data sets.
-
3
Understand a lack of relationship. If you wind up with a covariance equal to or very near 0, you can conclude that the data points are relatively unrelated. That is, an increase in one value may or may not lead to an increase in the other. The two terms are almost randomly connected.
- For example, suppose you are comparing shoes sizes against SAT scores. Because there are so many factors that affect a student’s SAT scores, we would expect a covariance score of near 0. This would indicate almost no connection between the two values.
-
4
View the relationship graphically. To understand covariance visually, you can plot your data points on the x-y coordinate plane. When you do that, you should see fairly easily that the points, although not in an exactly straight line, tend to form a cluster that approximates a diagonal line from the upper left to the lower right. This is the description of a negative covariance. Also, notice that the covariance value is -8.07. This is a fairly large number compared to the data points. The high number suggests that the covariance is fairly strong, which you can see by the linear appearance of the data points.
- To review plotting points on the coordinate plane, see Graph Points on the Coordinate Plane.




Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
-
Covariance has a limited application in statistics. It is often a step toward calculating correlation coefficients or other terms. Be cautious about interpreting too much based on a covariance score.
Advertisement
Video
References
About This Article
Article SummaryX
To calculate covariance, start by subtracting the average of the x-data points from each of the x-data points. Then, repeat with the y-data points. Next, multiply the results for each x-y pair of data points and add all of the products together. Finally, divide that number by the total number of data pairs minus 1 to get the covariance. To learn how to calculate covariance using an Excel spreadsheet, scroll down!
Did this summary help you?
Thanks to all authors for creating a page that has been read 596,442 times.
Reader Success Stories
-

«I liked the step-by-step approach linking with each formula. It gave me more confidence in solving covariance…» more