Интервальная оценка дисперсии нормального распределения
Построим доверительный
интервал для дисперсии D=σ2наблюдаемой случайной величины![]() ~
~![]() по случайной выборке
по случайной выборке![]() при неизвестном математическом ожидании.
при неизвестном математическом ожидании.
Введем случайную
величину (статистику)
![]() ,
,
(3.36)
которая согласно
утверждению 2 теоремы Фишера имеет
распределение
![]() с
с![]() степенями свободы. Поскольку плотность
степенями свободы. Поскольку плотность
распределения этого закона асимметрична,
доверительный интервал, соответствующий
надежности β, найдем из формулы (3.31) в
виде:
![]() .
.
(3.37)
Обычно доверительный
интервал
![]() для случайной величины
для случайной величины![]() выбирают так, чтобы вероятность ее
выбирают так, чтобы вероятность ее
попадания за пределы этого интервала
влево и вправо была одинаковой ( рис.
3.9):
![]() .
.
Тогда условия для
определения значений
![]() и
и
![]() будут иметь вид:
будут иметь вид:
![]() ,
,
![]() .
.
(3.38)
По таблице квантилей
![]() —
—
распределения ( табл. С Приложения)
найдем
![]() ,
,
![]() .
.
(3.39)
 Рис.
Рис.
3.9.
Неравенства ![]() эквивалентны неравенствам
эквивалентны неравенствам
![]() ,
,
поэтому
 .
.
Следовательно,
интервал

(3.40)
является доверительным
интервалом дисперсии, соответствующим
доверительной вероятности β.
Пример
3.3. По
данным выборочного контроля найти
выборочное математическое ожидание и
несмещенную оценку дисперсии нормальной
случайной величиныξ.Найти доверительные интервалы для них,
соответствующие доверительной вероятностиβ=0,98.
Таблица 3.4
|
|
42 |
43 |
45 |
46 |
48 |
51 |
52 |
54 |
|
|
1 |
2 |
3 |
6 |
4 |
3 |
1 |
1 |
Решение.
Выборочное математическое ожидание
найдем по формуле (3.14), используя табл.3.4
При
![]()
![]() .
.
Несмещенную
выборочную дисперсию вычислим по формуле
(3.19):
![]() ,
,![]() .
.
Доверительный
интервал для математического ожидания
определим по формуле (3.35). При
![]() из таблицы А Приложения находим квантиль
из таблицы А Приложения находим квантиль
распределения Стьюдента![]() .
.
Вычислив предельную ошибку![]() ,
,
получим искомый
доверительный интервал для математического
ожидания:
![]() .
.
Границы доверительного
интервала для дисперсии определим по
формуле (3.20). По таблице квантилей
распределения χ2(см. табл. С Приложения) при![]() определим квантили:
определим квантили:
![]() ,
,
![]() .
.
Подставив эти
значения, а также
![]() и
и
![]() в формулу (3.20), получим искомый доверительный
в формулу (3.20), получим искомый доверительный
интервал для дисперсии
![]() .
.
Вопросы для
самопроверки
-
Что называется
выборкой? -
Как произвести
оценку выборочного математического
ожидания и выборочной дисперсии? -
Как найти функцию
распределения для дискретной случайной
величины? -
Что такое несмещенная
оценка параметра? -
Дайте определение
состоятельной оценки. -
Что такое
интервальная оценка?
Заключение
В
результате изучения выше приведенного
материала студент может приступить к
выполнению контрольной работы и проверить
свои ответы на вопросы самоконтроля.
Затем после выполнения лабораторных
работ может приступить к ответам на
вопросы экзаменационного теста и
получить оценку за проделанную работу.
Глоссарий
Биномиальное
распределение
с параметрами n
и
p
– вычисление
вероятности того, что случайная величина
принимает значения
m=0,
1,…, n.
Вариационный
ряд – последовательность элементов
выборки, расположенных в неубывающем
порядке (одинаковые элементы записываются
последовательно друг за другом).
Вероятность
произведения двух независимых событий
–
произведение
вероятностей этих событий.
Вероятность
события — отношение
числа исходов m
события А
к общему числу элементарных событий
N.
Возможные значения
случайной величины –
числа .
Выборка –
последовательность значений из
генеральной совокупности;
— объема k
— часть, состоящая изkэлементов генеральной совокупности;
— репрезентативная
–позволяет адекватно описать
случайную величину
— случайная объема
n –
последовательность n
независимых случайных величин из
генеральной совокупности.
Выборочная
дисперсия– величина, равная сумме
квадратов разностей между значением
случайной величины и ее математическим
ожиданием, деленная на объем выборки.
Выборочноесреднее – число, равное сумме
значений случайной величины, деленной
на объем выборки.
Генеральная
совокупность – конечная или бесконечная
совокупность наблюдений над случайной
величиной.
Геометрическое
определение вероятности –
отношение
площади S(A),
соответствующей событию A,
к площади всей области .
Гипергеометрическое
распределение – вычисление вероятности
того, что случайная величина примет
заданное значение через число сочетаний.
Гипотеза
альтернативная – гипотеза, конкурирующая
с основной;
-основная –
гипотеза, которая проверяется;
-статистическая
– предположение относительно
параметров или закона распределения
случайной величины.
Гистограмма –
представление статистического ряда
на плоскости.
Дискретная
случайная величина — множество
возможных значений образует конечную
или бесконечную последовательность
чисел, т.е. конечно или счетно.
Дисперсия
случайной величины
–
момент второго порядка случайной
величины (
— M()).
Доверительная
вероятность – вероятность, с которой
производится оценка параметров.
Доверительный
интервал – область значений, при
которых основная гипотеза принимается.
Дополнениемножества A
–разность между всем множествомSи множествомА,
которое является частьюS.
Достоверное
событие
– всегда
наступает в условиях данного эксперимента.
Закон
трех сигм –
значения случайной величины ξ, имеющей
нормальное распределение с параметрами
m
и σ,
содержатся
в интервале
![]()
Кривая распределения
– график плотности вероятности.
Критерий значимости
– вероятность ошибки 1-го рода.
Критерий
— согласия –
правило, в соответствии с которым
принимается решение;
— Колмогорова –
проверка гипотезы о совпадении функций
распределения.
Математическое
ожидание дискретной
случайной величины–сумма ряда из произведений
возможных значенийxiна их вероятностиpi.
Множество –
некоторая совокупность объектов,
называемых элементами множества.
Множество конечное
–состоящие из конечного числа
элементов, в противном случае –бесконечное множество.
Момент второго
порядкаслучайной величины–математическое ожидание квадрата
этой случайной величины.
Моргана формулы
или соотношения двойственности –
правило для записи выражения,
соответствующего «отрицанию» функции.
Невозможное
событие –это такое, которое не
может наступить в условиях данного
эксперимента, т.е. это событие имеет
пустое множество благоприятствующих
исходов.
Независимые
событияAиB–событиеАпроисходит независимо
от того, происходит событие В или нет.
Несовместные
события AиB
– не могут происходить
одновременно.
Нормальное
или гауссовское распределение
–
случайная величина ξ имеет плотность
распределения вероятностей при всех x
![]()
 .
.
— хи-квадрат
(Пирсона) – проверка гипотезы о
совпадении дисперсий.
Относительная
частотасобытия A
– показывает долю опытов,
в которых наступило событиеAприNэкспериментах.
Оценка интервальная
– доверительный интервал:
— несмещенная –
математическое ожидание случайной
величины в этом случае равно оцениваемому
параметру;
— точечная –
произвольная функция элементов
выборки, когда параметр неизвестен.
Ошибка второго
рода – событие, состоящее в
том, что гипотеза принимается, когда на
самом деле она неверна.
Ошибка первого
рода – событие, состоящее в том, что
гипотеза отвергается, когда на самом
деле она верна.
Показательное
распределение
с параметром
![]() –
–
это
такое
распределение,
плотность вероятности которого задается
равенством
![]()
Произведение
или пересечениемножеств A
и B – множество, состоящее из всех общих
элементов этих множеств.
Пространствоэлементарных событий –
множество всех исходов данного
эксперимента.
Противоположное
событие – это событие, которое
происходит в том случае, если не происходит
событиеА.
Пустое множество
–множество, не содержащее
элементов.
Равномерное
распределение — случайная величина
ξ на промежутке[a,b]
имеет постоянную плотность
распределения вероятностей.
Размещение
из n
элементов по
k
элементов
–
упорядоченные
выборки объема k
без возвращения элементов.
Разность множеств
A и B
–множество, состоящее из всех
элементов множестваA, которые не
содержатся в множествеB.
Ряд распределения
– статистический ряд,
записанный в виде таблицы.
Случайная
величина –
функция f,
которая каждому элементарному событию
ставит в соответствие число .
Событие –
некоторое высказывание о результатах
рассматриваемого эксперимента.
Сочетаниеизn элементов
поkэлементов —
неупорядоченные выборки объемаkбез возвращения элементов.
Стандартное или
средне-квадратическое отклонение —
квадратный корень из дисперсии.
Статистика –
результат наблюдения над случайной
величиной.
Статистический
ряд – последовательность различных
значений, расположенных в возрастающем
порядке, с указанием относительных
частот.
Сумма или
объединение множеств A
и B –
множество, состоящее из всех
элементов, принадлежащих хотя бы одному
из этих множеств.
Уровень значимости
статистического критерия – величина,
определяющая степень достоверности
вычислений.
Условие
нормировки –
площадь
криволинейной трапеции под всей кривой
распределения равна 1.
Условная
вероятность –вероятность событияAпри условии, что
событиеB произошло.
Функция Лапласа
—функция распределения стандартного
нормального закона.
Функция
распределения F(x)
случайной величины
— вероятность того, что случайная
величина примет значение, меньшее
заданногох.
Частный случай
– если при каждом осуществлении
событияAпроисходит
и событиеB, то
говорят, что событиеAвлечет событие B.
Частота
события A
–
число экспериментов
mn(A),
в которых наступило событие A.
Элементарные
события –исходы (результаты)
эксперимента.
Эмпирическая
функция распределения –относительная
частота события, заключающегося в том,
что случайная величина примет значение,
меньшее чем заданное число.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
2.9. Эффективность оценки. Нижняя граница дисперсии несмещенной оценки. Неравенство Крамера-Рао
Предположим, что мы производим оценку неизвестного неслучайного параметра Θ и в результате измерений получаем так называемую несмещенную оценку, т.е. такую оценку, математическое ожидание которой равняется значению самого оцениваемого параметра, т.е. 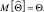 Для того чтобы определить качество оценки, следует определить ее дисперсию, которая вычисляется следующим образом:
Для того чтобы определить качество оценки, следует определить ее дисперсию, которая вычисляется следующим образом:
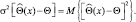
Дисперсия дает меру рассеяния ошибки. Наилучшей оценкой была бы, по-видимому, несмещенная оценка с минимальной дисперсией. Однако регулярной процедуры, которая бы приводила к получению алгоритма, формирующего несмещенную оценку с минимально возможной дисперсией, не существует.
В этой ситуации имеет смысл получить выражение для нижней границы дисперсии любой несмещенной оценки. Знание границы позволит сравнить дисперсию той или иной оценки с этой границей, и в том случае, если будет получено совпадение дисперсии оценки с нижней границей, может быть сделан вывод, что мы получили наилучшую оценку. Если же точное совпадение не обеспечено, то и в этом случае мы можем судить, насколько наша оценка отличается от потенциально достижимой.
Докажем следующее утверждение. Если 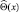 – любая несмещенная оценка величины Θ, то
– любая несмещенная оценка величины Θ, то
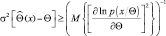 (2.9.1)
(2.9.1)
или, что эквивалентно,
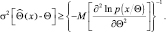 (2.9.2)
(2.9.2)
При этом мы считаем, что производные
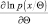 и
и 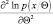
существуют и являются абсолютно интегрируемы.
Неравенства (2.9.1) и (2.9.2) обычно называются границами Крамера-Рао. Любая оценка, удовлетворяющая указанной границе со знаком равенства, называется эффективной оценкой.
Доказательство этого положения основано на использовании неравенства Буняковского-Шварца. Так как по нашему предположению оценка считается несмещенной, запишем
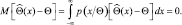 (2.9.3)
(2.9.3)
Дифференцируя обе части по Θ, имеем
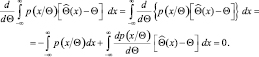 (2.9.4)
(2.9.4)
Первый интеграл равен 1. Кроме того, заметим, что
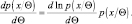 (2.9.5)
(2.9.5)
Подставляя (2.9.5) в (2.9.4), получаем
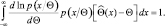
Перепишем подынтегральное выражение в следующем виде:
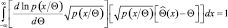
и используем неравенство Буняковского-Шварца:
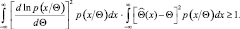 (2.9.6)
(2.9.6)
В связи с тем, что каждый из сомножителей представляет собой математическое ожидание, имеем следующее неравенство:
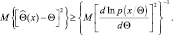
Итак, неравенство (2.9.1) можно считать доказанным. Для доказательства неравенства (2.9.2) заметим, что
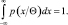
Дифференцируя по Θ, имеем
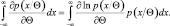 (2.9.7)
(2.9.7)
Вновь дифференцируя по Θ и применяя (2.9.5), получим
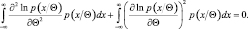
Отсюда следует
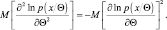
Последнее равенство означает справедливость условия (2.9.2).
Неравенство Крамера-Рао позволяет сделать ряд важных замечаний.
1. Любая несмещенная оценка имеет дисперсию больше, чем некоторое число.
2. Неравенство Буняковского-Шварца (2.9.6) выполняется тогда и только тогда, когда
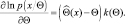 (2.9.8)
(2.9.8)
Если эффективная оценка существует (равенство (2.9.8) выполняется), то эта оценка является оценкой максимального правдоподобия. Действительно, уравнение правдоподобия имеет вид
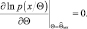
Для того чтобы правая часть равенства (2.9.8) принимала нулевое значение, оценка  должна быть равна
должна быть равна  .
.
3. Если эффективной оценки не существует (равенство (2.9.8) не выполняется), то неизвестно, насколько оптимальной является оценка максимального правдоподобия (насколько близко она приближается к границе). В этой ситуации границу и дисперсию оценки приходится вычислять и полученные величины сравнивать. Однако достаточно обнадеживающим является тот факт, что оценка по максимуму правдоподобия является асимптотически эффективной, иначе говоря, при стремлении размера выборки (размерности вектора x к бесконечности) дисперсия оценки максимального правдоподобия стремится к своей границе.
Доверительный интервал для математического ожидания нормальной случайной
величины при неизвестной дисперсии
Пусть
, причем
и
неизвестны. Необходимо построить доверительный интервал,
накрывающий с надежностью
истинное значение параметра
.
Для этого из генеральной
совокупности СВ
извлекается
выборка объема
:
.
1) В качестве точечной
оценки математического ожидания
используется
выборочное среднее
, а в
качестве оценки дисперсии
–
исправленная выборочная дисперсия
которой соответствует стандартное отклонение
.
2) Для нахождения
доверительного интервала строится статистика
имеющая в этом случае распределение Стьюдента с
числом степеней свободы
независимо
от значений параметров
и
.
3) Задается требуемый
уровень значимости
.
4) Применяется следующая
формула расчета вероятности:
где
–
критическая точка распределения Стьюдента, которая находится по таблице критических точек распределения Стьюдента (односторонняя критическая область).
Тогда:
Это означает, что
интервал:
накрывает неизвестный
параметр
с
надежностью
Доверительный интервал для математического ожидания
нормальной случайной величины при известной дисперсии
Пусть количественный
признак
генеральной
совокупности имеет нормальное распределение
с
заданной дисперсией
и
неизвестным математическим ожиданием
. Построим
доверительный интервал для
.
1) Пусть для оценки
извлечена
выборка
объема
. Тогда
2) Составим случайную
величину:
Нетрудно показать, что случайная величина
имеет стандартизированное нормальное распределение, то есть:
3) Зададим уровень
значимости
.
4) Применяя формулу нахождения
вероятности отклонения нормальной величины от математического ожидания, имеем:
Это означает, что
доверительный интервал
накрывает неизвестный
параметр
с надежностью
. Точность оценки определяется величиной:
Число
определяется
по таблице значений функции Лапласа из равенства
Окончательно получаем:
Доверительный интервал для
дисперсии нормальной случайной величины при неизвестном математическом ожидании
Пусть
, причем
и
–
неизвестны. Пусть для оценки
извлечена выборка объема
:
.
1) В качестве точечной оценки дисперсии
используется
исправленная выборочная дисперсия
:
которой соответствует стандартное отклонение
.
2) При нахождении
доверительного интервала для дисперсии в этом случае вводится статистика
имеющая
–
распределение с числом степеней свободы
независимо
от значения параметра
.
3) Задается требуемый
уровень значимости
.
4) Тогда, используя таблицу критических точек хи-квадрат распределения, нетрудно указать критические
точки
, для которых будет выполняться следующее
равенство:
Подставив вместо
соответствующее значение, получим:
Получаем доверительный
интервал для неизвестной дисперсии:
Доверительный интервал для
дисперсии нормальной случайной величины при известном математическом ожидании
Пусть
, причем
–
известна, а
–
неизвестна. Пусть для оценки
извлечена выборка объема
:
.
1) В качестве точечной оценки дисперсии
используется выборочная дисперсия:
2) При нахождении
доверительного интервала для дисперсии в этом случае вводится статистика
имеющая
–
распределение с числом степеней свободы
независимо
от значения параметра
.
3) Задается требуемый
уровень значимости
.
4) Тогда, используя таблицу критических точек хи-квадрат распределения,
нетрудно указать критические точки
, для которых будет выполняться следующее
равенство:
Подставив вместо
соответствующее значение, получим:
Получаем доверительный
интервал для неизвестной дисперсии:
Доверительный интервал для
среднего квадратического отклонения
Извлекая квадратный корень:
Положив:
Получим следующий
доверительный интервал для среднего квадратического
отклонения:
Для отыскания
по заданным
и
пользуются специальными таблицами.
Для проверки на нормальность заданного распределения случайной величины можно использовать
правило трех сигм.
Задача
Имеется
три независимых реализации нормальной случайной величины: 0.8, 3.2, 2.0.
Построить
доверительные интервалы для среднего и дисперсии с надежностью
Указание:
воспользоваться таблицами Стьюдента и хи-квадрат.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычисление средней и дисперсии
Вычислим среднее и
исправленную дисперсию
:
Нахождение доверительных интервалов для средней и дисперсии
Найдем доверительный интервал для оценки
неизвестного среднего. Он считается по формуле:
По таблице критических точек t-критерия Стьюдента, для уровня значимости
(односторонняя критическая область):
Искомый
доверительный интервал для среднего:
Найдем доверительный интервал для оценки дисперсии.
Он считается по формуле:
Для уровня значимости
и
получаем по таблице значений хи-квадрат:
Искомый доверительный интервал для дисперсии:
Ответ
Кроме этой задачи на другой странице сайта есть
пример расчета доверительного интервала математического ожидания и среднего квадратического отклонения для интервального вариационного ряда
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Для помощи во время экзамена/зачета в онлайн режиме необходимо договариваться заранее.
Как найти дисперсию?
Полезная страница? Сохрани или расскажи друзьям
Дисперсия — это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая — значения сравнительно близки друг к другу, если большая — далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии — среднеквадратическое отклонение $sigma(X)=sqrt{D(X)}$, которое имеет ту же размерность, что и исходная величина и также описывает разброс.
Еще одно формальное определение дисперсии звучит так: «Дисперсия — это второй центральный момент случайной величины» (напомним, что первый начальный момент — это как раз математическое ожидание).
Нужна помощь? Решаем теорию вероятностей на отлично
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле:
$$
D(X)=M(X-M(X))^2,
$$
которую также часто записывают в более удобном для расчетов виде:
$$
D(X)=M(X^2)-(M(X))^2.
$$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2.
$$
Если же речь идет о непрерывной случайной величине (заданной плотностью вероятностей $f(x)$ в общем случае), формула дисперсии Х выглядит следующим образом:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения:
$$
x_i quad 1 quad 2 \
p_i quad 0.5 quad 0.5
$$
и
$$
y_i quad -10 quad 10 \
p_i quad 0.5 quad 0.5
$$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором — дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2 =\
= 1^2cdot 0.5 + 2^2 cdot 0.5 — (1cdot 0.5 + 2cdot 0.5)^2=2.5-1.5^2=0.25.
$$
$$
D(Y)=sum_{i=1}^{n}{y_i^2 cdot p_i}-left(sum_{i=1}^{n}{y_i cdot p_i} right)^2 =\
= (-10)^2cdot 0.5 + 10^2 cdot 0.5 — (-10cdot 0.5 + 10cdot 0.5)^2=100-0^2=100.
$$
Итак, значения случайных величин различались на 1 и 20 единиц, тогда как дисперсия показывает меру разброса в 0.25 и 100. Если перейти к среднеквадратическому отклонению, получим $sigma(X)=0.5$, $sigma(Y)=10$, то есть вполне ожидаемые величины: в первом случае значения отстоят в обе стороны на 0.5 от среднего 1.5, а во втором — на 10 единиц от среднего 0.
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Снова используем формулу для дисперсии дискретной случайной величины:
$$
D(X)=M(X^2)-(M(X))^2.
$$
В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Потом математическое ожидание квадрата случайной величины:
$$
M(X^2)=sum_{i=1}^{n}{x_i^2 cdot p_i}
= (-1)^2cdot 0.1 + 2^2 cdot 0.2 +5^2cdot 0.3 +10^2cdot 0.3+20^2cdot 0.1=78.4.
$$
А потом подставим все в формулу для дисперсии:
$$
D(X)=M(X^2)-(M(X))^2=78.4-6.8^2=32.16.
$$
Дисперсия равна 32.16 квадратных единиц.
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx — left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Вычислим сначала математическое ожидание:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{6} frac{x}{18} cdot x dx = int_{0}^{6} frac{x^2}{18} dx =
left.frac{x^3}{54} right|_0^6=frac{6^3}{54} = 4.
$$
Теперь вычислим
$$
M(X^2)=int_{-infty}^{+infty} f(x) cdot x^2 dx = int_{0}^{6} frac{x}{18} cdot x^2 dx = int_{0}^{6} frac{x^3}{18} dx = left.frac{x^4}{72} right|_0^6=frac{6^4}{72} = 18.
$$
Подставляем:
$$
D(X)=M(X^2)-(M(X))^2=18-4^2=2.
$$
Дисперсия равна 2.
Другие задачи с решениями по ТВ
Подробно решим ваши задачи на вычисление дисперсии
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку «Вычислить».
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Полезная страница? Сохрани или расскажи друзьям
Полезные ссылки
Не забывайте сначала прочитать том, как найти математическое ожидание. А тут можно вычислить также СКО: Калькулятор математического ожидания, дисперсии и среднего квадратического отклонения.
Что еще может пригодиться? Например, для изучения основ теории вероятностей — онлайн учебник по ТВ. Для закрепления материала — еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k — число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) — это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) — середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) — нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) — соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) — нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) — результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | — |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).