Основными
обобщающими показателями вариации в
статистике являются дисперсии и среднее
квадратическое отклонение.
Дисперсия
это средняя
арифметическая
квадратов отклонений каждого значения
признака от общей средней. Дисперсия
обычно называется средним квадратом
отклонений и обозначается 2.
В зависимости от исходных данных
дисперсия может вычисляться по средней
арифметической простой или взвешенной:
![]()
дисперсия
невзвешенная (простая);

дисперсия
взвешенная.
Среднее
квадратическое отклонение
это обобщающая характеристика абсолютных
размеров вариации
признака в совокупности. Выражается
оно в тех же единицах измерения, что и
признак (в метрах, тоннах, процентах,
гектарах и т. д.).
Среднее
квадратическое отклонение представляет
собой корень квадратный из дисперсии
и обозначается :

среднее
квадратическое отклонение невзвешенное;

среднее
квадратическое отклонение взвешенное.
Среднее
квадратическое отклонение является
мерилом надежности средней. Чем меньше
среднее квадратическое отклонение, тем
лучше средняя арифметическая отражает
всю представляемую совокупность.
Вычислению
среднего квадратического отклонения
предшествует расчет дисперсии.
Порядок
расчета дисперсии взвешенной следующий:
1)
определяют среднюю арифметическую
взвешенную:

2)
рассчитывают отклонения вариантов от
средней:
![]()
3)
возводят в квадрат отклонение каждого
варианта от средней:
![]()
4)
умножают квадраты отклонений на веса
(частоты):
![]()
5)
суммируют полученные произведения:
![]()
6)
полученную сумму делят на сумму весов:

Пример 2.1
Имеются
следующие данные о производительности
труда рабочих:

Исчислим
среднюю арифметическую взвешенную:

Значения
отклонений от средней и их квадратов
представлены в таблице. Определим
дисперсию:

Среднее
квадратическое отклонение будет равно:

Если
исходные данные представлены в виде
интервального ряда
распределения,
то сначала нужно определить дискретное
значение признака, а затем применить
изложенный метод.
Пример 2.2
Покажем
расчет дисперсии для интервального
ряда на данных о распределении посевной
площади колхоза по урожайности пшеницы.

Средняя
арифметическая равна:
![]()
Исчислим
дисперсию:
![]()
6.3. Расчет дисперсии по формуле по индивидуальным данным
Техника
вычисления дисперсии
сложна, а при больших значениях вариантов
и частот может быть громоздкой. Расчеты
можно упростить, используя свойства
дисперсии.
Дисперсия
имеет следующие свойства.
1.
Уменьшение или увеличение весов (частот)
варьирующего признака в определенное
число раз дисперсию не изменяет.
2.
Уменьшение или увеличение каждого
значения признака на одну и ту же
постоянную величину А
дисперсию не изменяет.
3.
Уменьшение или увеличение каждого
значения признака в какое-то число раз
k
соответственно уменьшает или увеличивает
дисперсию в k2
раз, а среднее
квадратическое отклонение
в k
раз.
4.
Дисперсия признака относительно
произвольной величины
![]()
всегда больше дисперсии относительно
средней арифметической на квадрат
разности между средней и произвольной
величинами:
![]()
Если
А
0, то приходим к следующему равенству:
![]()
т.
е. дисперсия признака равна разности
между средним квадратом значений
признака и квадратом средней.
Каждое
свойство при расчете дисперсии может
быть применено самостоятельно или в
сочетании с другими.
Порядок
расчета дисперсии простой:
1)
определяют среднюю
арифметическую:
![]()
2)
возводят в квадрат среднюю арифметическую:

3)
возводят в квадрат отклонение каждого
варианта ряда:
хi2.
4)
находят сумму квадратов вариантов:
![]()
5)
делят сумму квадратов вариантов на их
число, т. е. определяют средний квадрат:
![]()
6)
определяют разность между средним
квадратом признака и квадратом средней:
![]()
Пример 3.1
Имеются
следующие данные о производительности
труда рабочих:

Произведем
следующие расчеты:
![]()

Рассмотрим
расчет дисперсии в интервальном ряду
распределения.
Порядок
расчета дисперсии взвешенной (по формуле
![]() )
)
следующий:
1)
определяют среднюю арифметическую:

2)
возводят в квадрат полученную среднюю:
![]()
3)
возводят в квадрат каждый вариант ряда:
![]()
4)
умножают квадраты вариантов на частоты:
![]()
5)
суммируют полученные произведения:
![]()
6)
делят полученную сумму на сумму весов
и получают средний квадрат признака:

7)
определяют разность между средним
значением квадратов и квадратом средней
арифметической, т. е. дисперсию:
![]()
Пример 3.2
Имеются
следующие данные о распределении
посевной площади колхоза по урожайности
пшеницы:

В
подобных случаях прежде всего определяется
дискретное значение признака в каждом
интервале, а затем применяется
рассмотренный метод расчета:

Средняя
величина
отражает тенденцию развития, т. е.
действие главных причин. Среднее
квадратическое отклонение измеряет
силу воздействия прочих факторов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
18.12.2018130.46 Кб297.docx
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дискретный вариационный ряд и его характеристики
- Классификация рядов распределения
- Дискретный вариационный ряд, полигон частот и кумулята
- Выборочная средняя, мода и медиана
- Степень асимметрии вариационного ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования дискретного вариационного ряда
- Примеры
п.1. Классификация рядов распределения
Статистический ряд распределения – это количественное распределение единиц совокупности на однородные группы по некоторому варьирующему признаку.
В зависимости от природы признака различают атрибутивные и вариационные ряды.
Атрибутивный ряд распределения построен на качественном признаке.
Вариационный ряд распределения построен на количественном признаке.
Например:
Качественными признаками, которые не поддаются измерению, являются: профессия, пол, национальность и т.п.
Количественными признаками, которые можно подсчитать или измерить, являются: количество людей в группе, число повторений в опыте, возраст, вес, рост, скорость, температура и т.п.
По упорядоченности вариационные ряды делятся на упорядоченные (ранжированные) и неупорядоченные. Упорядочить ряд можно по возрастанию или убыванию исследуемого признака.
По характеру непрерывности признака вариационные ряды делятся на дискретные и интервальные.
Например:
Дискретными признаками, которые принимают отдельные значения, являются: количество людей в группе, число детей в семье, количество домов, число опытов и т.п.
Непрерывными признаками, которые могут принимать любые значения в интервале, являются: возраст, вес, рост, скорость, температура и т.п.
Варианты – это отдельные значения признака, которые он принимает в вариационном ряду.
Частоты – это численности отдельных вариант.
Например:
Распределение учеников по оценкам за контрольную работу
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
В данном ряду признак – это оценка, варианты признака (x_i) – это множество {2;3;4;5}, частоты (f_i) – это количество учеников, получивших каждую из оценок.
п.2. Дискретный вариационный ряд, полигон частот и кумулята
Дискретный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся прерывно и принимающему конечное множество значений.
Общий вид дискретного вариационного ряда
| Варианты, (x_i) | (x_1) | (x_2) | … | (x_k) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k — число вариант исследуемого признака.
Тогда общее количество исходов (число единиц в совокупности): (N=sum_{i=1}^k f_i)
Полигон частот – это ломаная, которая соединяет точки ((x_i,f_i)).
Например:
| Для распределения учеников по оценкам из нашего примера получаем такой полигон: |  |
Относительная частота варианты (x_i) — это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$ Относительная частота (w_i) является эмпирической оценкой вероятности варианты (x_i) в исследуемом ряду.
Полигон относительных частот – это ломаная, которая соединяет точки ((x_i,w_i)).
Полигон относительных частот является эмпирическим законом распределения исследуемого признака.
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)).
Ступенчатая кривая (F(x_i)), построенная по точкам ((x_i,S_i)), является эмпирической функцией распределения исследуемого признака.
Например:
Проведем необходимые расчеты и построим полигон относительных частот, кумуляту и эмпирическую функцию распределения учеников по оценкам.
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (w_i) | 0,0909 | 0,4545 | 0,3030 | 0,1515 | 1 |
| (S_i) | 0,0909 | 0,4545 | 0,8485 | 1 | — |
Полигон относительных частот (эмпирический закон распределения)
Кумулята (красная ломаная) и эмпирическая функция распределения (ступенчатая синяя кривая).
Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 2\ 0,0909, 2lt xleq 3\ 0,5455, 3lt xleq 4\ 0,8485, 4lt xleq 5\ 1, xgt 5 end{cases} $$
п.3. Выборочная средняя, мода и медиана
Выборочная средняя дискретного вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Мода дискретного вариационного ряда – это варианта с максимальной частотой: $$ M_o=x*, f(x*)=underset{i=overline{1,k}}{max}f_i $$ Мод может быть несколько. Тогда говорят, что ряд мультимодальный.
На полигоне частот мода – это абсцисса самой высокой точки.
Медиана дискретного вариационного ряда – это значение варианты посредине упорядоченного ряда.
Алгоритм:
1. Отсортировать ряд по возрастанию.
2а. Если общее количество измерений N нечётное, найти (m=lceilfrac N2rceil) и округлить в сторону увеличения. (M_e=x_m) — искомая медиана.
2б. Если общее количество измерений N чётное, найти (m=frac N2) и вычислить медиану как среднее (M_e=frac{x_m+x_{m+1}}{2}).
На графике кумуляты медиана – это абсцисса первой точки слева, ордината которой превысила 0,5.
Например:
1) Найдем выборочную среднюю для распределения учеников по оценкам:
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (x_if_i) | 6 | 45 | 40 | 25 | 116 |
$$ X_{cp}=frac{6+45+40+25}{33}=frac{116}{33}approx 3,5 $$ Средняя оценка за контрольную – 3,5.
2) Найдем моду. Максимальная частота – 15 человек – у троечников. Значит: (M_o=3).
3) Найдем медиану. Общее количество измерений N=33 — нечетное.
Находим: (m=lceilfrac N2rceil=17)
Смотрим на ряд слева направо. Сначала у нас идет 3 двоечника, затем 15 троечников.
Вместе их 18, и 17-й человек в ряду — троечник. Группа троечников является медианной: (M_e=3).
Также, медиану можно найти по графику кумуляты. (3;0,5455) – это первая слева точка, в которой ордината больше 0,5. Значит, медиана равна абсциссе этой точки, т.е. (M_e=3).
п.4. Степень асимметрии вариационного ряда
В рядах с асимметрией или выбросами выборочная средняя не отражает в полной мере особенности исследуемого признака. Типичный случай – значение среднего уровня доходов в странах с высоким индексом Джини, где 5% населения получает 95% доходов. Или анекдотичный случай со «средней температурой по больнице».
Поэтому, кроме средней, в статистическом исследовании всегда следует определять моду и медиану.
Мода, медиана и выборочная средняя совпадут, если вариационный ряд является симметричным: $$ X_{cp}=M_o=M_e $$ Если вершина распределения сдвинута влево и правая часть ветви длиннее левой (длинный правый хвост), такая асимметрия называется правосторонней. При правосторонней асимметрии: $$ M_olt M_elt X_{cp} $$ Если вершина распределения сдвинута вправо и левая часть ветви длиннее правой (длинный левый хвост), такая асимметрия называется левосторонней. При левосторонней асимметрии: $$ M_ogt M_egt X_{cp} $$ Для умеренно асимметричных рядов (по Пирсону) модуль разности между модой и средней не более 3 раз превышает модуль разности между медианой и средней: $$ frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}geq 3 $$
Например:
Для распределения учеников по оценкам мы получили (X_{cp}=3,5; M_o=3; M_e=3).
Т.к. средняя оказалась больше моды и медианы, наше распределение имеет правостороннюю асимметрию (что видно на полигоне частот – правый хвост длиннее).
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{0,5}{0,5}=1lt 3), т.е. распределение умеренно асимметрично.
п.5. Выборочная дисперсия и СКО
Выборочная дисперсия дискретного вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac{(x_1-X_{cp})^2 f_1+(x_2-X_{cp})^2 f_2+…+(x_k-X_{cp})^2 f_k}{N}=\ =frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
1) Найдем выборочную дисперсию для распределения учеников по оценкам:
| Оценка, (x_i) | 2 | 3 | 4 | 5 | Всего |
| К-во учеников, (f_i) | 3 | 15 | 10 | 5 | 33 |
| (x_i^2) | 4 | 9 | 16 | 25 | — |
| (x_i^2 f_i) | 12 | 135 | 160 | 125 | 432 |
$$ D=frac{12+135+160+125}{33}-3,5^2=frac{432}{33}-3,5^2approx 0,73 $$ 2) Значение СКО: (sigma=sqrt{D}approx 0,86)
п.6. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия дискретного вариационного ряда определяется как: begin{gather*} S^2=frac{1}{N-1}sum_{i=1}^k(x_i-X_{cp})^2 f_i=frac{N}{N-1}D end{gather*}
В теоретической статистике доказывается, что выборочная дисперсия D является смещенной оценкой дисперсии при распространении на генеральную совокупность.
А именно, выборочная дисперсия D всегда меньше математического ожидания для дисперсии генеральной совокупности.
Исправленная выборочная дисперсия S2 является несмещенной оценкой.
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Если показатель вариации V<33%, то выборка считается однородной, т.е. большинство полученных в ней вариант находятся недалеко от средней, и выборочная средняя хорошо характеризует среднюю генеральной совокупности.
В противном случае, выборка неоднородна. Варианты в выборке находятся далеко от средней, есть выбросы. А значит, и в генеральной совокупности они возможны. Т.е., распространять результаты выборки на генеральную совокупность нельзя.
Если исследуется не выборка, а вся генеральная совокупность, дисперсию «исправлять» не нужно.
Например:
Для распределения учеников по оценкам получаем:
1) Исправленная выборочная дисперсия $$ S^2=frac{N}{N-1}D=frac{33}{32}cdot 0,73approx 0,76 $$ 2) Стандартное отклонение $$ x=sqrt{S^2}approx 0,87 $$ 3) Коэффициент вариации: $$ V=frac{0,87}{3,5}cdot 100text{%}approx 24,8text{%}lt 33text{%} $$ Выборка является однородной.
Это означает, что согласно коэффициенту вариации полученные результаты контрольной работы можно рассматривать в качестве «типичных» и распространить их на генеральную совокупность, т.е. на всех школьников, которые будут писать эту работу.
п.7. Алгоритм исследования дискретного вариационного ряда
На входе: таблица с вариантами (x_i) и частотами (f_i, i=overline{1,k})
Шаг 1. Составить расчетную таблицу. Найти (w_i,S_i,x_if_i,x_i^2,x_i^2f_i)
Шаг 2. Построить полигон относительных частот (эмпирический закон распределения) и график кумуляты с эмпирической функцией распределения. Записать эмпирическую функцию распределения.
Шаг 3. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 4. Найти выборочную дисперсию и СКО.
Шаг 5. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.8. Примеры
Пример 1. На площадке фриланса была проведена выборка из 100 фрилансеров и подсчитано количество постоянных заказчиков, с которыми они работают.
В результате было получено следующее распределение:
| Число постоянных заказчиков | 0 | 1 | 2 | 3 | 4 | 5 |
| Число фрилансеров | 22 | 35 | 27 | 11 | 3 | 1 |
Исследуйте полученный вариационный ряд.
1) Вариационный ряд является дискретным.
Исследуемый признак – «число постоянных заказчиков».
Варианты признака (x_iinleft{0;1;..;5right}). Количество вариант k=6.
Составим расчетную таблицу:
| (x_i) | 0 | 1 | 2 | 3 | 4 | 5 | ∑ |
| (f_i) | 23 | 35 | 27 | 11 | 3 | 1 | 100 |
| (w_i) | 0,23 | 0,35 | 0,27 | 0,11 | 0,03 | 0,01 | — |
| (S_i) | 0,23 | 0,58 | 0,85 | 0,96 | 0,99 | 1 | — |
| (x_if_i) | 0 | 35 | 54 | 33 | 12 | 5 | 139 |
| (x_i^2) | 0 | 1 | 4 | 9 | 16 | 25 | — |
| (x_i^2f_i) | 0 | 35 | 108 | 99 | 48 | 25 | 315 |
2) Полигон относительных частот (эмпирический закон распределения):
Кумулята и эмпирическая функция распределения:
$$ F(x)= begin{cases} 0, xleq 0\ 0,23, 0lt xleq 1\ 0,58, 1lt xleq 2\ 0,85, 2lt xleq 3\ 0,96, 3lt xleq 4\ 0,99, 4lt xleq 5\ 1, xgt 5 end{cases} $$ 3) Выборочная средняя: $$ X_{cp}=frac1Nsum_{i=1}^k x_if_i= frac{1}{100}cdot 139=1,39 $$ Мода (абсцисса самой высокой точки на полигоне частот): (M_0=1).
Медиана (абсцисса первой слева точки на кумуляте, где значение превысило 0,5): точка (1;0,58), (M_e=1).
(X_{cp}gt M_e=M_0) – распределение асимметрично, с правосторонней асимметрией.
При этом (frac{|M_0-X_{cp}|}{|M_e-X_{cp}|}=frac{0,39}{0,39}=1lt 3), т.е. распределение умеренно асимметрично.
4) Выборочная дисперсия: $$ D=frac1Nsum_{i=1}^k x_i^2f_i-X_{cp}^2=frac{1}{100}cdot 315-1,39^2=1,2179approx 1,218 $$ CKO: $$ sigma=sqrt{D}approx 1,104 $$
5) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{100}{99}cdot 1,218approx 1,230 $$ Стандартное отклонение выборки: $$ s=sqrt{S^2}approx 1,109 $$ Коэффициент вариации: $$ V=frac{s}{X_{cp}}cdot 100text{%}=frac{1,109}{1,39}cdot 100text{%}approx 79,8text{%}gt 33text{%} $$ Представленная выборка неоднородна. Полученное значение средней (X_{cp}=1,39) не может быть распространено на генеральную совокупность всех фрилансеров.
Варианты для выполнения работы
I. Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных — результатов наблюдений.
Почти все встречающиеся в жизни величины (урожайность сельскохозяйственных растений, продуктивности скота, производительность труда и заработная плата рабочих, объем производства продукции и т.д.) принимают неодинаковые значения у различных членов совокупности. Поэтому возникает необходимость в изучении их изменяемости. Это изучение начинается с проведения соответствующих наблюдений, обследований.
В результате наблюдений получают сведения о численной величине изучаемого признака у каждого члена данной совокупности.
Пример. Имеются данные о размере прибыли 100 коммерческих банков. Прибыль, млн. рублей.
| 30,2 | 51,9 | 43,1 | 58,9 | 34,1 | 55,2 | 47,9 | 43,7 | 53,2 | 34,9 |
| 47,8 | 65,7 | 37,8 | 68,6 | 48,4 | 67,5 | 27,3 | 66,1 | 52,0 | 55,6 |
| 54,1 | 26,9 | 53,6 | 42,5 | 59,3 | 44,8 | 52,8 | 42,3 | 55,9 | 48,1 |
| 44,5 | 69,8 | 47,3 | 35,6 | 70,1 | 39,5 | 70,3 | 33,7 | 51,8 | 56,1 |
| 28,4 | 48,7 | 41,9 | 58,1 | 20,4 | 56,3 | 46,5 | 41,8 | 59,5 | 38,1 |
| 41,4 | 70,4 | 31,4 | 52,5 | 45,2 | 52,3 | 40,2 | 60,4 | 27,6 | 57,4 |
| 29,3 | 53,8 | 46,3 | 40,1 | 50,3 | 48,9 | 35,8 | 61,7 | 49,2 | 45,8 |
| 45,3 | 71,5 | 35,1 | 57,8 | 28,1 | 57,6 | 49,6 | 45,5 | 36,2 | 63,2 |
| 61,9 | 25,1 | 65,1 | 49,7 | 62,1 | 46,1 | 39,9 | 62,4 | 50,1 | 33,1 |
| 33,3 | 49,8 | 39,8 | 45,9 | 37,3 | 78,0 | 64,9 | 28,8 | 62,5 | 58,7 |
Из данной таблицы видно, что интересующий нас признак (прибыль банков) меняется от одного члена совокупности к другому, варьирует. Варьирование есть изменяемость признака у отдельных членов совокупности.
Вариационным рядом называется последовательность вариант, записанных в возрастающем порядке и соответствующих им частот.
Число, показывающее, сколько раз повторяется в данной совокупности каждое значение признака, называется частотой.
Составим ранжированный вариационный ряд (выпишем варианты в порядке возрастания):
| 20,4 | 25,1 | 26,9 | 27,3 | 27,6 | 28,1 | 28,4 | 28,8 | 29,3 | 30,2 |
| 31,4 | 33,1 | 33,3 | 33,7 | 34,1 | 34,9 | 35,1 | 35,6 | 35,8 | 36,2 |
| 37,3 | 37,8 | 38,1 | 39,5 | 39,8 | 39,9 | 40,1 | 40,2 | 41,4 | 41,8 |
| 41,9 | 42,3 | 42,5 | 43,1 | 43,7 | 44,5 | 44,8 | 45,2 | 45,3 | 45,5 |
| 45,8 | 45,9 | 46,1 | 46,3 | 46,5 | 47,3 | 47,8 | 47,9 | 48,1 | 48,4 |
| 48,7 | 48,9 | 49,2 | 49,6 | 49,7 | 49,8 | 50,1 | 50,3 | 51,8 | 51,9 |
| 52,0 | 52,3 | 52,5 | 52,8 | 53,2 | 53,6 | 53,8 | 54,1 | 55,2 | 55,6 |
| 55,9 | 56,1 | 56,3 | 57,4 | 57,6 | 57,8 | 58,1 | 58,7 | 58,9 | 59,3 |
| 59,5 | 60,4 | 61,7 | 61,9 | 62,1 | 62,4 | 62,5 | 63,2 | 64,9 | 65,1 |
| 65,7 | 66,1 | 67,5 | 68,6 | 69,8 | 70,1 | 70,3 | 70,4 | 71,5 | 78,0 |
В нашем случае каждое значение признака (варианта вариационного ряда) повторилось только один раз, т.е. значение частоты для всех вариант равно единице. Перейдем к интервальному вариационному ряду, так как интересующий нас признак принимает дробные, практически не повторяющиеся значения.
Для этого необходимо определить число интервалов (классов) и длину интервала (классного промежутка), после чего произвести разноску, т.е. подсчитать для каждого интервала число вариант, попавших в него.
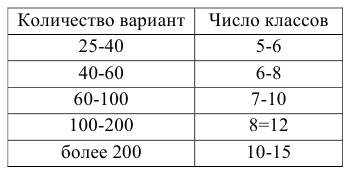
Количество классов устанавливают в зависимости от степени точности, с которой ведется обработка, и количества объектов в выборке. Считается удобным при объеме выборки (n) в пределах от 30 до 60 вариант распределять их на 6-7 классов, при n от 60 до 100 вариант — на 7-8 классов, при n от 100 и более вариант — на 9-17 классов.
Нужное количество групп также может быть ориентировочно вычислено по формуле Стерджесса:
![[k=1+3,322lgn]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-827d2afc3c23ef764fe96a262dc05464_l3.png "Rendered by QuickLaTeX.com")
где  — число групп (классов, интервалов) ряда распределения; n — объем выборки.
— число групп (классов, интервалов) ряда распределения; n — объем выборки.
Можно также использовать выражение:
![[k=sqrt{n}.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c751034bcfa1dc301e6aa8cc4c208523_l3.png "Rendered by QuickLaTeX.com")
При  они дают примерно одинаковые результаты.
они дают примерно одинаковые результаты.
В рассматриваемом примере о размере прибыли коммерческих банков, n=100. Применяя формулу Стерджесса, получим:
![[k=1+3,322lg100=1+3,322cdot 2=7,644approx 8.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c58a320e33430cf4c7533ebf191c3ab5_l3.png "Rendered by QuickLaTeX.com")
Однако  Таким образом, число интервалов может быть равно 8, 9, 10 и т.д.
Таким образом, число интервалов может быть равно 8, 9, 10 и т.д.
Нахождение нужного количества групп и их размеров часто бывает взаимообусловлено. Для того, чтобы как-то определиться с числом интервалов, найдем размах вариации — разность между наибольшей и наименьшей вариантой:
![[R=x_{max}-x_{min}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aafc593639af68dbf52da085dd4d8c8c_l3.png "Rendered by QuickLaTeX.com")
где  — размах вариации,
— размах вариации,
 — наибольшее значение варьирующего признака,
— наибольшее значение варьирующего признака,
 — наименьшее значение варьирующего признака.
— наименьшее значение варьирующего признака.
Найдем размах вариации для рассматриваемой задачи:
![[R=78,0-20,4=57,6]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-56080b6ec34bbf2f588d137e9eaf87cb_l3.png "Rendered by QuickLaTeX.com")
Для того, чтобы найти длину интервала (величину классового промежутка) необходимо разделить размах вариации на число классов и полученную величину округлить таким образом, чтобы было удобно производить сначала разноску, а затем и различные вычисления. Рекомендую округлять до единиц, до которых округлены варианты в исходной таблице, в нашем случае до десятых.
![[happrox frac{R}{k}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-3e0b8eaa452c3f09d2f7f8090a3d7e36_l3.png "Rendered by QuickLaTeX.com")
Согласно формуле получаем
![[happrox frac{57,6}{8}=7,2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-243ada79cae79e51927cddc6d6d38988_l3.png "Rendered by QuickLaTeX.com")
Теперь необходимо определиться с началом первого интервала. Для этого можно использовать формулу:
![[x_1approx x_{min}-frac{h}{2}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-5a6eab01e8fb5fc5d82b10533b954fc7_l3.png "Rendered by QuickLaTeX.com")
![[x_1approx 20,4-frac{7,2}{2}=16,8.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f9ce5df5c222c16a62501fec5810487b_l3.png "Rendered by QuickLaTeX.com")
Замечание. За начало первого интервала можно принять некоторое значение, несколько меньшее или само значение . Далее в табличном виде я покажу оба варианта.
Прибавив к началу первого интервала (нижней границе) шаг, получим верхнюю границу первого интервала и одновременно нижнюю границу второго интервала. Выполняя последовательно указанные действия, будем находить границы последующих интервалов до тех пор, пока не будет получено или перекрыто .
Таким образом, верхняя граница одного интервала одновременно является нижней границей другого интервала. Чтобы не возникало сомнений, в какой интервал отнести варианту, попавшую на границу, условимся относить ее к верхнему интервалу.
Составим теперь рабочую таблицу для построения интервального вариационного ряда и произведем подсчет частот вариант, попавших в тот или иной интервал.
Как и обещал покажу две таблицы построения ряда:
1. Отсчет ведем от , т.е. нижняя граница первого интервала совпадает с .
|
Группы банков по размеру прибыли (границы интервалов) |
Количество банков, принадлежащих данной группе (частоты, |
Накопленные частоты,
|
| 20,4 — 27,6 | 4 | 4 |
| 27,6 — 34,8 | 11 | 15 |
| 34,8 — 42 | 16 | 31 |
| 42 — 49,2 | 21 | 52 |
| 49,2 — 56,4 | 21 | 73 |
| 56,4 — 63,6 | 15 | 88 |
| 63,6 — 70,8 | 10 | 98 |
| 70,8 — 78 | 2 | 100 |

2. Начало первого интервала определяем с помощью формулы:  .
.
|
Группы банков по размеру прибыли (границы интервалов) |
Количество банков, принадлежащих данной группе (частоты, |
Накопленные частоты,
|
| 16,8 — 24 | 1 | 1 |
| 24 — 31,2 | 9 | 10 |
| 31,2 — 38,4 | 13 | 23 |
| 38,4 — 45,6 | 17 | 40 |
| 45,6 — 52,8 | 23 | 63 |
| 52,8 — 60 | 18 | 81 |
| 60 — 67,2 | 11 | 92 |
| 67,2 — 74,4 | 7 | 99 |
| 74,4 — 81,6 | 1 | 100 |
Как мы видим в 1-м случае у нас получилось восемь интервалов, что полностью совпадает с результатом, который нам дала формула Стерджесса. Во втором случае у нас получилось девять интервалов, так как при поиске начала первого интервала пользовались специальной формулой.
Для дальнейшего исследования я буду пользоваться результатами второй таблицы, так как там ярко выражен модальный интервал (одна мода) и медиана практически точно попадает на середину вариационного ряда.
Мы получили интервальный вариационный ряд — упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами попаданий в каждый из них значений величины.
II. Графическая интерпретация вариационных рядов.
| № п/п |
Границы интервалов,
|
Середины интервалов,
|
Частоты интервалов,
|
Относительные частоты
|
Плотность относит. частоты
|
Плотность частоты
|
| 1 | 16,8 — 24 | 20,4 | 1 | 0,01 | 0,001 | 0,139 |
| 2 | 24 — 31,2 | 27,6 | 9 | 0,09 | 0,013 | 1,250 |
| 3 | 31,2 — 38,4 | 34,8 | 13 | 0,13 | 0,018 | 1,806 |
| 4 | 38,4 — 45,6 | 42 | 17 | 0,17 | 0,024 | 2,361 |
| 5 | 45,6 — 52,8 | 49,2 | 23 | 0,23 | 0,032 | 3,194 |
| 6 | 52,8 — 60 | 56,4 | 18 | 0,18 | 0,025 | 2,500 |
| 7 | 60 — 67,2 | 63,6 | 11 | 0,11 | 0,015 | 1,528 |
| 8 | 67,2 — 74,4 | 70,8 | 7 | 0,07 | 0,010 | 0,972 |
| 9 | 74,4 — 81,6 | 78 | 1 | 0,01 | 0,001 | 0,139 |
 |
 |





Строим графики:





Далее найдем моду вариационного ряда:
![[M_o(X)=x_{M_o}+hfrac{(n_2-n_1)}{(n_2-n_1)+(n_2-n_3)}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-5618d73a38aaff5a278596c8af7758c8_l3.png "Rendered by QuickLaTeX.com")
где
 — начало модального интервала;
— начало модального интервала;
 — длина частичного интервала (шаг);
— длина частичного интервала (шаг);
 — частота предмодального интервала;
— частота предмодального интервала;
 — частота модального интервала;
— частота модального интервала;
 — частота послемодального интервала.
— частота послемодального интервала.
Определим модальный интервал — интервал, имеющий наибольшую частоту. Из таблицы видно, что модальным является интервал (45,6 — 52,8).
![[M_o(X)=45,6+7,2frac{(23-17)}{(23-17)+(23-18)}=]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-473f77b88c7bd6de3e31bd12541d8833_l3.png "Rendered by QuickLaTeX.com")
![[=45,6+7,2cdot frac{6}{6+5}=45,6+3,93=49,5]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-9122e42dfec05a0505617226d32d75df_l3.png "Rendered by QuickLaTeX.com")
Медиана
Для интервального ряда медиана находится по формуле:
![[M_e(X)=x_{M_e}+hfrac{0,5n-S_{M_{e}-1}}{n_{M_e}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c464daab40bab9748a191e3a00b95831_l3.png "Rendered by QuickLaTeX.com")
где
 — начало медианного интервала;
— начало медианного интервала;
— длина частичного интервала (шаг);
 — объем совокупности;
— объем совокупности;
 — накопленная частота интервала, предшествующая медианному;
— накопленная частота интервала, предшествующая медианному;
 — частота медианного интервала.
— частота медианного интервала.
Определим медианный интервал — интервал, в котором впервые накопленная частота превышает половину объема выборки.Так как объем выборки n=100, то n/2=50. По таблице найдем интервал, где впервые накопленные частоты превысят это значение. Таким является интервал (45,6 — 52,8).
Получаем,
![[M_e(X)=45,6+7,2frac{0,5cdot 100-40}{23}approx 48,7.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d820d343bc16acd48af9d431995a7222_l3.png "Rendered by QuickLaTeX.com")
III. Расчет сводных характеристик выборки.
Для определения  составим расчетную таблицу. Для начала определимся с ложным нулем С. В качестве ложного нуля можно принять любую варианту. Максимальная простота вычислений достигается, если выбрать в качестве ложного нуля варианту, которая расположена примерно в середине вариационного ряда (часто такая варианта имеет наибольшую частоту).
составим расчетную таблицу. Для начала определимся с ложным нулем С. В качестве ложного нуля можно принять любую варианту. Максимальная простота вычислений достигается, если выбрать в качестве ложного нуля варианту, которая расположена примерно в середине вариационного ряда (часто такая варианта имеет наибольшую частоту).
Варианте, которая принята в качестве ложного нуля, соответствует условная варианта, равная нулю. В нашем случае С=49,2.
Равноотстоящими называют варианты, которые образуют арифметическую прогрессию с разностью h.
Условными называют варианты, определяемые равенством:
![[U_i=frac{(x_i-C)}{h}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c6c24a440a025414d18ebe8781aa22b6_l3.png "Rendered by QuickLaTeX.com")
Произведем расчет условных вариант согласно формуле:
![[U_1=frac{20,4-49,2}{7,2}=-4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-159a490fe276ae2b2a6081e4f9647090_l3.png "Rendered by QuickLaTeX.com")
![[U_2=frac{27,6-49,2}{7,2}=-3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a3e4e66d8520f3a12aa6519c36e69ba1_l3.png "Rendered by QuickLaTeX.com")
![[U_3=frac{34,8-49,2}{7,2}=-2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-187afa35d11ed679a257edd766e3a0f1_l3.png "Rendered by QuickLaTeX.com")
![[U_4=frac{42-49,2}{7,2}=-1]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-929695d78c47d35b023c9dc2d11f5a3f_l3.png "Rendered by QuickLaTeX.com")
![[U_5=frac{49,2-49,2}{7,2}=0]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aa956af961d374361e948bd16a3e1317_l3.png "Rendered by QuickLaTeX.com")
![[U_6=frac{56,4-49,2}{7,2}=1]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-fb490f3a7e06599bee2c19bcc67e4b9f_l3.png "Rendered by QuickLaTeX.com")
![[U_7=frac{63,6-49,2}{7,2}=2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-8a98b7a3d0f9e4d9733242a9bf102866_l3.png "Rendered by QuickLaTeX.com")
![[U_8=frac{70,8-49,2}{7,2}=3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-e9d062cda3a1324da90f6286b5542af0_l3.png "Rendered by QuickLaTeX.com")
![[U_9=frac{78-49,2}{7,2}=4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aa53c7e67e340a81ca72c0b720d8ca36_l3.png "Rendered by QuickLaTeX.com")
| N п/п |
Середины интервалов,
|
Частоты интервалов,
|
Условные варианты,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
| 1 | 20,4 | 1 | -4 | -4 | 16 | -64 | 256 | 9 | 81 |
| 2 | 27,6 | 9 | -3 | -27 | 81 | -243 | 729 | 36 | 144 |
| 3 | 34,8 | 13 | -2 | -26 | 52 | -104 | 208 | 13 | 13 |
| 4 | 42 | 17 | -1 | -17 | 17 | -17 | 17 | 0 | 0 |
| 5 | 49,2 | 23 | 0 | 0 | 0 | 0 | 0 | 23 | 23 |
| 6 | 56,4 | 18 | 1 | 18 | 18 | 18 | 18 | 72 | 288 |
| 7 | 63,6 | 11 | 2 | 22 | 44 | 88 | 176 | 99 | 891 |
| 8 | 70,8 | 7 | 3 | 21 | 63 | 189 | 567 | 112 | 1792 |
| 9 | 78 | 1 | 4 | 4 | 16 | 64 | 256 | 25 | 625 |
|
 |
 |
 |
 |
 |
 |








Контроль:
![[sum n_i U_i^2 + 2sum n_iU_i+n=sum n_i{(U_i+1)}^2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-bfe916445efb3e33681b87967ff3ee72_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i U_i^2 + 2sum n_iU_i+n=307+2cdot (-9)+100=389]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c979f642509fc9a23d3107e2a82fc723_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i{(U_i+1)}^2=389]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-6b54236fb1d63f048c9dbec240de42d5_l3.png "Rendered by QuickLaTeX.com")
Контроль:
![[sum n_i U_i^4 + 4sum n_iU_i^3+6sum n_iU_i^2+4sum n_iU_i+n=sum n_i{(U_i+1)}^4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f07f4af98630f4642b04e2030e849232_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i U_i^4 + 4sum n_iU_i^3+6sum n_iU_i^2+4sum n_iU_i+n=]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-fb86aec2d3151a542084e9e4805ecb1f_l3.png "Rendered by QuickLaTeX.com")
![[=2227+4cdot (-69)+6 cdot 307+4cdot (-9)+100=3857]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-81abf9514098d32eca4d80dbef425404_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i{(U_i+1)}^4=3857]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-08ea4071bdd89be8534b6573048c6226_l3.png "Rendered by QuickLaTeX.com")
Равенство выполнено, следовательно вычисления произведены верно.
Вычислим условные моменты 1-го, 2-го, 3-го и 4-го порядков:
![[M_1^{*}=frac{sum n_iU_i}{n}=frac{-9}{100}=-0,09;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-20762ac62aef7ff58d3d5a21f72d97fc_l3.png "Rendered by QuickLaTeX.com")
![[M_2^{*}=frac{sum n_iU_i^2}{n}=frac{307}{100}=3,07;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-49fc1f9b0b295a1fc1aa27f267380093_l3.png "Rendered by QuickLaTeX.com")
![[M_3^{*}=frac{sum n_iU_i^3}{n}=frac{-69}{100}=-0,69;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-dd8d7a50c08c5c1dd7b8a871e2493bde_l3.png "Rendered by QuickLaTeX.com")
![[M_4^{*}=frac{sum n_iU_i^4}{n}=frac{2227}{100}=22,27.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-8513720d7a2df45aaa7d99686e4d4436_l3.png "Rendered by QuickLaTeX.com")
Найдем выборочные среднюю, дисперсию и среднее квадратическое отклонение :
![[x_{B}=M_1^{*}cdot h+C=-0,09cdot 7,2+49,2=48,552;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-01563ec6dda7fdedaa93513c74ff997e_l3.png "Rendered by QuickLaTeX.com")
![[D_{B}=(M_2^{*}-{(M_1^{*})}^2)h^2=(3,07-{(-0,09)}^2){7,2}^2approx 158,73.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-db67c404df7fbd10fcba1803dc1d9aef_l3.png "Rendered by QuickLaTeX.com")
![[sigma_{B}=sqrt{D_B}=sqrt{158,73}=12,6.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d8d05199c63db71062b09ee4969f6df5_l3.png "Rendered by QuickLaTeX.com")
Также для оценки отклонения эмпирического распределения от нормального используют такие характеристики, как асимметрия и эксцесс.
Асимметрией теоретического распределения называют отношение центрального момента третьего порядка к кубу среднего квадратического отклонения:
![[a_s=frac{m_3}{sigma_B^3}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-b4a9bc811679794242a602b480953ec6_l3.png "Rendered by QuickLaTeX.com")
Асимметрия положительна, если «длинная часть» кривой распределения расположена справа от математического ожидания; асимметрия отрицательна, если «длинная часть» кривой расположена слева от математического ожидания. Практически определяют знак асимметрии по расположению кривой распределения относительно моды (точки максимума дифференциальной функции): если «длинная часть» кривой расположена правее моды, то асимметрия положительна, если слева — отрицательна.
Эксцесс эмпирического распределения определяется равенством:
![[e_k=frac{m_4}{sigma_B^4}-3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-ebd36893c40d9e5760b22c5515404887_l3.png "Rendered by QuickLaTeX.com")
где  — центральный эмпирический момент четвертого порядка.
— центральный эмпирический момент четвертого порядка.
Для нормального распределения эксцесс равен нулю. Поэтому если эксцесс некоторого распределения отличен от нуля, то кривая этого распределения отличается от нормальной кривой: если эксцесс положительный, то кривая имеет более высокую и «острую» вершину, чем нормальная кривая; если эксцесс отрицательный, то сравниваемая кривая имеет более низкую и «плоскую» вершину, чем нормальная кривая. При этом предполагается, что нормальное и теоретическое распределения имеют одинаковые математические ожидания и дисперсии.
Вычисляем центральные эмпирические моменты третьего и четвертого порядков:
![[m_3=(M_3^*-3M_1^*M_2^*+2{(M_1^*)}^3)cdot h^3=51,3;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-35fa469c4f36b2aae7705925a013be5e_l3.png "Rendered by QuickLaTeX.com")
![[m_4=(M_4^*-4M_3^*M_1^*+6M_2^*{(M_1^*)}^2-3{(M_1^*)}^4)cdot h^4=59580,97;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f687774454962c3d0e3377e6df0573e8_l3.png "Rendered by QuickLaTeX.com")
Найдем асимметрию и эксцесс:
![[a_s=frac{51,3}{{12,6}^3}=0,026]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-3ea65f54fb9839acecf06e17f7a04d64_l3.png "Rendered by QuickLaTeX.com")
![[e_k=frac{59580,97}{{12,6}^4}-3=-0,635]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-0ed5e864eda55df96619480c0a06a254_l3.png "Rendered by QuickLaTeX.com")
IV. Проверка гипотезы о нормальном распределении генеральной совокупности. Критерий согласия Пирсона.
Проверим генеральную совокупность значений размера прибыли банков по критерию Пирсона 
Правило. Для того, чтобы при заданном уровне значимости проверить нулевую гипотезу  : генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
: генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
![[chi^2_{nabl}=sum frac{ {(n_i-n_i^{'})}^2}{n_i^{'}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-43685ed67e69272b6c950828a97acd89_l3.png "Rendered by QuickLaTeX.com")
и по таблице критических точек распределения , по заданному уровню значимости  и числу степеней свободы
и числу степеней свободы  найти критическую точку
найти критическую точку  , где s — количество интервалов.
, где s — количество интервалов.
Если  — нет оснований отвергнуть нулевую гипотезу.
— нет оснований отвергнуть нулевую гипотезу.
Если  — нулевую гипотезу отвергают.
— нулевую гипотезу отвергают.
Найдем теоретические частоты  , для этого составим следующую таблицу.
, для этого составим следующую таблицу.
|
Середины интервалов,
|
Частоты интервалов,
|
Произведем расчет,
|
Произведем расчет,
|
Значения функции Гаусса,
|
Произведем расчет,
|
Теоретические частоты,
|
| 20,4 | 1 | -28,152 | -2,23 | 0,0332 | 57 | 2 |
| 27,6 | 9 | -20,952 | -1,66 | 0,1006 | 57 | 6 |
| 34,8 | 13 | -13,752 | -1,09 | 0,2203 | 57 | 13 |
| 42 | 17 | -6,552 | -0,52 | 0,3485 | 57 | 20 |
| 49,2 | 23 | 0,648 | 0,05 | 0,3984 | 57 | 23 |
| 56,4 | 18 | 7,848 | 0,62 | 0,3292 | 57 | 19 |
| 63,6 | 11 | 15,048 | 1,19 | 0,1965 | 57 | 11 |
| 70,8 | 7 | 22,248 | 1,77 | 0,0833 | 57 | 5 |
| 78 | 1 | 29,448 | 2,34 | 0,0258 | 57 | 1 |
 |
 |





Вычислим  , для чего составим расчетную таблицу.
, для чего составим расчетную таблицу.
 |
 |
 |
 |
 |
 |
 |
 |
| 1 | 1 | 2 | -1 | 1 | 0,5 | 1 | 0,5 |
| 2 | 9 | 6 | 3 | 9 | 1,5 | 81 | 13,5 |
| 3 | 13 | 13 | 0 | 0 | 0 | 169 | 13 |
| 4 | 17 | 20 | -3 | 9 | 0,45 | 289 | 14,45 |
| 5 | 23 | 23 | 0 | 0 | 0 | 529 | 23 |
| 6 | 18 | 19 | -1 | 1 | 0,05 | 324 | 17,05 |
| 7 | 11 | 11 | 0 | 0 | 0 | 121 | 11 |
| 8 | 7 | 5 | 2 | 4 | 0,8 | 49 | 9,8 |
| 9 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
 |
100 | 100 |
Наблюдаемое значение критерия,
|
103,30 |

Контроль:
![[sumfrac{n_i^2}{n_i^{'}}-n=sum frac{{(n_i-n_i^{'})}^2}{n_i^'}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-6c32fcc2a5c6b3b4b603ae3d99533b4a_l3.png "Rendered by QuickLaTeX.com")
![[sumfrac{n_i^2}{n_i'}-n=103,3-100=3,3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a9fda2a1f7cb2dccff4e36db3eca149a_l3.png "Rendered by QuickLaTeX.com")
![[sum frac{{(n_i-n_i')}^2}{n_i'}=3,3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-008fc9e192109f46116930043ed491f9_l3.png "Rendered by QuickLaTeX.com")
Вычисления произведены правильно.
Найдем число степеней свободы, учитывая, что число групп выборки (число различных вариант) s=9;
![[k=s-3=9-3=6.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-591c6b21dce56f5cf0fa9cd47789d7b6_l3.png "Rendered by QuickLaTeX.com")
По таблице критических точек распределения по уровню значимости  и числу степеней свободы k=6 находим
и числу степеней свободы k=6 находим 
Так как — нет оснований отвергнуть нулевую гипотезу. Другими словами, расхождение эмпирических и теоретических частот незначительное. Следовательно, данные наблюдений согласуются с гипотезой о нормальном распределении генеральной совокупности.
На рисунке построены нормальная (теоретическая) кривая по теоретическим частотам (зеленый график) и полигон наблюдаемых частот (коричневый график). Сравнение графиков наглядно показывает, что построенная теоретическая кривая удовлетворительно отражает данные наблюдений.

V. Интервальные оценки.
Интервальной называют оценку, которая определяется двумя числами — концами интервала, покрывающего оцениваемый параметр.
Доверительным называют интервал, который с заданной надежностью  покрывает заданный параметр.
покрывает заданный параметр.
Интервальной оценкой (с надежностью ) математического ожидания (а) нормально распределенного количественного признака Х по выборочной средней  при известном среднем квадратическом отклонении
при известном среднем квадратическом отклонении  генеральной совокупности служит доверительный интервал
генеральной совокупности служит доверительный интервал
![[x_B-frac{tsigma}{sqrt{n}}<a<x_B+frac{tsigma}{sqrt{n}},]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-9750e199194b01ecfa06ba1601feab7d_l3.png "Rendered by QuickLaTeX.com")
где  — точность оценки, n — объем выборки, t — значение аргумента функции Лапласа
— точность оценки, n — объем выборки, t — значение аргумента функции Лапласа  (см. приложение 2), при котором
(см. приложение 2), при котором  ;
;
при неизвестном среднем квадратическом отклонении (и объеме выборки n<30)
![[x_B-frac{t_{gamma}cdot S}{sqrt{n}}<a<x_B+frac{t_{gamma}cdot S}{sqrt{n}},]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d9ee32ae620adb447d86d28cba84e871_l3.png "Rendered by QuickLaTeX.com")
![[S=sqrt{frac{n}{n-1}D_B}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-dfe89e1cead729b251b9981b9eac134b_l3.png "Rendered by QuickLaTeX.com")
где S — исправленное выборочное среднее квадратическое отклонение,  находят по таблице приложения по заданным n и .
находят по таблице приложения по заданным n и .
В нашем примере среднее квадратическое отклонение известно,  . А также
. А также  , ,
, ,  . Поэтому для поиска доверительного интервала используем первую формулу:
. Поэтому для поиска доверительного интервала используем первую формулу:
![[x_B-frac{tsigma}{sqrt{n}}<a<x_B+frac{tsigma}{sqrt{n}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-600f869b70725152f297f8ba0a2459fa_l3.png "Rendered by QuickLaTeX.com")
Все величины, кроме t, известны. Найдем t из соотношения  По таблице приложения находим t=1,96. Подставив t=1,96, , , в формулу, окончательно получим искомый доверительный интервал:
По таблице приложения находим t=1,96. Подставив t=1,96, , , в формулу, окончательно получим искомый доверительный интервал:
![[48,55-frac{1,96cdot 12,6}{10}<a<48,55+frac{1,96cdot 12,6}{10}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-18be4f2ab8257c8e7f50af9fdc1766fa_l3.png "Rendered by QuickLaTeX.com")
![[48,55-2,47<a<48,55+2,47]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-268428dac12802b423e852d51d9dd03d_l3.png "Rendered by QuickLaTeX.com")
![[46,08<a<51,02]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-45b72334d0171fd5dd4329bd36b155b3_l3.png "Rendered by QuickLaTeX.com")
Интервальной оценкой (с надежностью ) среднего квадратического отклонения нормально распределенного количественного признака Х по «исправленному» выборочному среднему квадратическому отклонению S служит доверительный интервал
 (при q<1), (*)
(при q<1), (*)
 (при q>1),
(при q>1),
где q — находят по таблице приложения по заданным n и .
По данным и n=100 по таблице приложения 4 найдем q=0,143. Так как q<1, то, подставив  в соотношение (*), получим доверительный интервал:
в соотношение (*), получим доверительный интервал:
![[12,66(1-0,143)<sigma<12,66(1+0,143)]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a4a65a9250ea6393a930f1b29215644f_l3.png "Rendered by QuickLaTeX.com")
![[10,85<sigma<14,47]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f3d033cb268eca08d52ccfbe86fecd99_l3.png "Rendered by QuickLaTeX.com")
Содержание:
Предмет математической статистики (МС) — любой объект, изучаемый с количественной стороны в целях более точной оценки его качественного состояния.
При этом имеются в виду групповые объекты, т.е. явления массовые, в сфере которых проявляют свое действие статистические законы.
Единица наблюдения — составной элемент или член группового объекта.
Статистическая совокупность — множество относительно однородных, но индивидуально различимых единиц, объединенных для совместного (группового) изучения. Например, недопустимо изучать показатели изменчивости человеческого организма, объединяя в одну совокупность людей разного возраста и пола.
Статистический комплекс слагается из разнородных групп, каждая из которых состоит из однородных элементов, для совместного (комплексного) изучения. Вопрос о форме объединения экспериментатор решает сам в зависимости от объекта и цели исследования.
Признак — свойство, проявлением которого один предмет отличается от другого.
Пример:
Исследуется признак 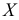
Характерное свойство признаков — варьирование величины признака в определенных пределах. Эти колебания величины одного и того же признака, наблюдаемые в массе однородных элементов статистической совокупности, называются вариациями, а отдельные числовые значения варьирующего признака называются вариантами.
Признаки делятся на качественные (атрибутивные) и количественные.
Качественные признаки не поддаются непосредственному измерению и учитываются по наличию их свойств у отдельных членов изучаемой группы.
Пример:
Признак 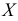
Количественные признаки поддаются непосредственному измерению или счету. Их делят на мерные и счетные.
Мерные признаки варьируют непрерывно, их величина может принимать в определенных пределах (от — до) любые числовые значения. Аналог мерного признака в теории вероятностей есть непрерывная случайная величина.
Счетные признаки варьируют прерывисто (дискретно), их числовые значения часто выражаются целыми числами (число зерен в колосьях и т.п.).
Аналогом счетного признака в теории вероятности является дискретная случайная величина.
Признаки обозначаем так же, как случайные величины: 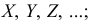 их варианты соответственно
их варианты соответственно 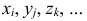
Признаки варьируют под влиянием различных, в том числе и случайных причин. Наряду с естественным варьированием на величине признака сказываются и ошибки, неизбежно возникающие при измерении изучаемых объектов.
Погрешность или ошибка — разница между результатами измерений и действительно существующими значениями измеряемого признака.
Технические ошибки — связаны с неточностью измерительных приборов и инструментов.
Личные ошибки возникают из-за личных качеств исследователя, его навыков и мастерства.
Случайные ошибки возникают из-за целого ряда других, не поддающихся регулированию и неустранимых причин.
Технические + личные ошибки = систематические ошибки. Их можно преодолеть соответствующими методами.
Случайные ошибки, как независимые от воли человека, остаются и сказываются на результатах наблюдений. Следовательно, варьирование признака складывается из естественной изменчивости признака и ошибок измерений.
При измерении количественного признака и при вычислении его характеристик применяются два вида округления:
- — округление с недостатком: если за последней сохраняемой цифрой следуют цифры 0, 1,2, 4, то они отбрасываются. Например, точность измерения
 т.е. последняя сохраняемая цифра — вторая после запятой. Тогда
т.е. последняя сохраняемая цифра — вторая после запятой. Тогда - — округление с избытком: если за последней сохраняемой цифрой следуют цифры 5, 6, 7, 8, 9, то последняя сохраняемая цифра увеличивается на единицу. Например,
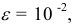 т.е. последняя сохраняемая цифра — вторая после запятой. Тогда
т.е. последняя сохраняемая цифра — вторая после запятой. Тогда 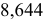
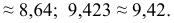
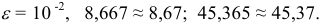
Наблюдения над объектами могут охватывать все члены изучаемой совокупности без единого исключения или ограничиваться обследованием лишь некоторой части данной совокупности.
В первом случае наблюдения полные или сплошные, во втором — частичные или выборочные.
Полное обследование совокупности позволяет получить исчерпывающую информацию об объекте, но требует больших затрат времени, труда, ресурсов и в некоторых случаях невозможно или нецелесообразно. Например, чтобы определить всхожесть партии семян, нецелесообразно высеивать всю партию. Невозможно учесть всех обитателей фитопланктона для небольшого водоема и т.п.
Определение. Генеральной совокупностью называется вся совокупность объектов для изучения.
Выборкой или выборочной совокупностью называется отобранная тем или иным способом часть генеральной совокупности.
Количество членов генеральной совокупности обозначается 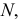 теоретически
теоретически 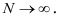 Объем выборки обозначается
Объем выборки обозначается 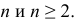
Чтобы выборка наиболее полно отображала структуру генеральной совокупности, необходимо, чтобы она была представительной (репрезентативной), т.е. для каждого элемента генеральной совокупности должна быть одинаковая возможность (вероятность) попасть в выборку, т.е. выборка должна быть случайной.
Отбор в выборку может быть повторный, если учтенная единица возвращается в генеральную совокупность и может попасть в выборку повторно.
Бесповторный отбор — учтенная единица не возвращается в генеральную совокупность, т.е. каждая отобранная единица регистрируется только один раз.
Таким образом, повторный отбор не влияет на состав генеральной совокупности и вероятность каждой единицы попасть в выборку не меняется. При бесповторном отборе вероятность единиц генеральной совокупности попасть в выборку изменяется, т.к. предшествующий отбор влияет на результаты последующего и на состав генеральной совокупности.
Идеальный случайный выбор производится по методу жеребьевки или лотереи, а также с помощью «случайных чисел». Существуют типический, серийный, механический и другие разновидности отборов.
Типический отбор используют тогда, когда генеральная совокупность расчленяется на отдельные типические группы. В таких случаях из каждой группы случайным образом отбирают одинаковое или пропорциональное число единиц. Затем вычисляют групповые характеристики, объединяемые далее в общую характеристику генеральной совокупности.
Серийный отбор используют, когда генеральная совокупность делится на серии обычно по территориальному принципу. Например, из 30 групп подростков намечено исследовать выборочно 6 групп, т.е. работают не с отдельными единицами, а с целыми сериями относительно однородных единиц.
Механический отбор используется, когда генеральную совокупность разбивают на несколько равных частей или групп. Затем из каждой группы отбирают по одной единице. Например, при исследовании посева ржи на урожайность намечено отобрать 100 растений, следовательно, поле должно быть разделено на 100 равных частей, из каждой части отбирается одна единица.
Отбор будет также механическим если из генеральной совокупности в выборку попадет каждая десятая, сотая и т.д. единица.
Систематизация наблюдений
Процесс систематизации результатов массовых наблюдений, объединения их в относительно однородные группы по некоторому признаку 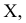 называется группировкой.
называется группировкой.
Наиболее распространенная форма группировки — статистические таблицы.
Особая форма группировки — статистические ряды, видное место среди них занимают вариационные ряды.
Определение. Вариационным рядом или рядом распределения называется двойной ряд чисел, показывающий как числовые значения признака (варианты) связаны с их повторяемостью в данной статистической совокупности.
Пример:
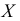 — количество изготовленных на станке деталей в смену. Количество смен
— количество изготовленных на станке деталей в смену. Количество смен 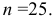

Число 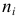 называется абсолютной частотой или просто частотой (или весом) варианты
называется абсолютной частотой или просто частотой (или весом) варианты 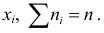 Относительная частота варианты
Относительная частота варианты 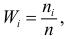 где
где 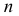 — объем выборки,
— объем выборки, 
Ранжированный вариационный ряд выстроен по возрастанию или убыванию членов ряда.
В примере имеем ранжированный вариационный ряд вида:

Вариационные ряды есть безынтервальные, если признак дискретный, и интервальные, если признак непрерывный. Если признак варьирует дискретно, но в широких границах, то по данным наблюдений можно построить интервальный вариационный ряд. Будем рассматривать равноинтервальные ряды. Если признак варьирует непрерывно, то из интервального ряда можно построить безынтервальный ряд, т.е. разделение на ряды (безынтервальные и интервальные) по типу признака (дискретный или непрерывный) не однозначное.
Для получения хорошо обозримого вариационного ряда и обеспечения достаточной точности вычисляемых по нему числовых характеристик следует разбить вариацию признака (в пределах от 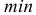 до
до 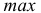 варианты) на такое число классов
варианты) на такое число классов 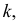 чтобы не искажались типичные черты варьирования и ряд получался не слишком растянутым:
чтобы не искажались типичные черты варьирования и ряд получался не слишком растянутым:
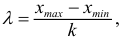 где
где 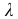 — ширина классового интервала,
— ширина классового интервала, 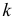 — число классов, на которые необходимо разбить вариацию признака.
— число классов, на которые необходимо разбить вариацию признака.
Существует формула Стерджеса 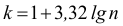 и при
и при 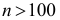 можно использовать формулу
можно использовать формулу 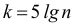 (Брукс, Карузерс). На практике можно руководствоваться следующими правилами:
(Брукс, Карузерс). На практике можно руководствоваться следующими правилами:
Техника построения вариационного ряда:
- Найдем
- Вычислим
- Значение должно попасть примерно в середину первого классового интервала, поэтому нижняя граница первого классового интервала будет Прибавив к число получим верхнюю границу первого классового интервала, затем найдем верхнюю границу второго классового интервала и т.д. до тех пор, пока не получим интервал, в который попадет
- Верхние границы интервалов уменьшаем на величину равную точности, принятой при измерении признака, для того, чтобы избежать момента, когда варианта совпадает с границей.
- Подсчитаем количество вариант попавших в каждый интервал.
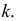
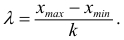
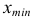 должно попасть примерно в середину первого классового интервала, поэтому нижняя граница
должно попасть примерно в середину первого классового интервала, поэтому нижняя граница 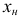 первого классового интервала будет
первого классового интервала будет 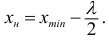 Прибавив к
Прибавив к 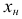 число
число 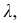 получим верхнюю границу первого классового интервала, затем найдем верхнюю границу второго классового интервала и т.д. до тех пор, пока не получим интервал, в который попадет
получим верхнюю границу первого классового интервала, затем найдем верхнюю границу второго классового интервала и т.д. до тех пор, пока не получим интервал, в который попадет 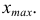
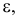 равную точности, принятой при измерении признака, для того, чтобы избежать момента, когда варианта совпадает с границей.
равную точности, принятой при измерении признака, для того, чтобы избежать момента, когда варианта совпадает с границей.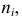 попавших в каждый интервал.
попавших в каждый интервал.Пример:
Наблюдается признак 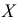 — количество пропусков занятий (лекций и практических) в семестре у 64 студентов.
— количество пропусков занятий (лекций и практических) в семестре у 64 студентов.
Выборка имеет вид: 8, 10, 6, 10, 8, 5, 11, 7, 10, 6, 9, 7, 8, 7, 9, 11, 8, 9, 10, 8, 7, 8, 11, 8, 7, 10, 8, 8, 5, 11, 8, 10, 12, 7, 5, 7, 9, 7, 10, 5, 8, 9, 7, 12, 8, 9, 6, 7, 8, 7, 11, 8, 6, 7,9, 10,6, 6,6,7,8, 10, И, 12.
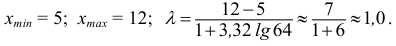
Если 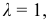 то ряд будет безынтервальным, классами данного ряда будут сами ранжированные варианты:
то ряд будет безынтервальным, классами данного ряда будут сами ранжированные варианты:

Полученный вариационный ряд выражает зависимость между отдельными вариантами и частотой (повторяемостью) вариант.
Пример:
Наблюдается признак 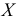 — среднегодовая температура в некотором населенном пункте Крыма в течение ста лет,
— среднегодовая температура в некотором населенном пункте Крыма в течение ста лет, 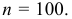
Выборка имеет вид:
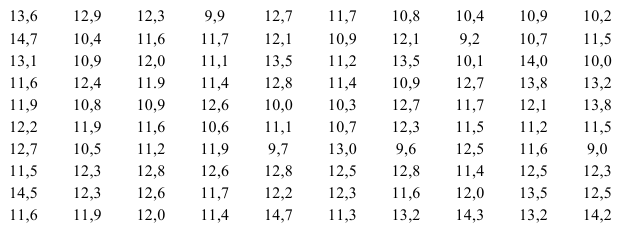
1) Лимиты выборки: 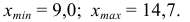
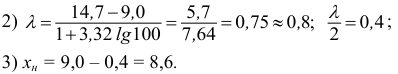
Классовые интервалы:
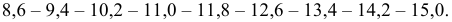
4) Уменьшаем верхние границы интервалов на величину точности, принятой при измерении, т.е. на величину 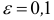 для подсчета
для подсчета 

Итак, интервальный вариационный ряд имеет вид:
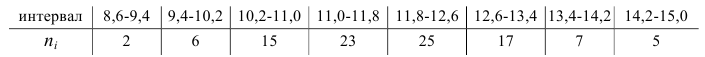
Соответствующий безынтервальный ряд, построенный по интервальным данным, будет иметь вид:

где 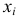 — серединное значение
— серединное значение 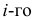 интервала, называется классовой вариантой, в отличии от варианты статистической совокупности.
интервала, называется классовой вариантой, в отличии от варианты статистической совокупности.
Графики вариационных рядов
Более наглядное изображение закономерности варьирования количественного признака — график вариационного ряда.
Полигон распределения
Полигон распределения (или многоугольник распределения) строится для безынтервального ряда: по оси 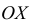 откладываем статистические варианты или классовые варианты
откладываем статистические варианты или классовые варианты 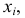 по оси
по оси 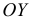 — частоты
— частоты  Полученные точки
Полученные точки 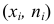 соединяем ломаной линией, которая называется вариационной кривой или кривой распределения. Полученная при этом плоская фигура называется полигон или многоугольник распределения.
соединяем ломаной линией, которая называется вариационной кривой или кривой распределения. Полученная при этом плоская фигура называется полигон или многоугольник распределения.

Гистограмма распределения частот
Гистограмма распределения частот  строится для интервального ряда: по
строится для интервального ряда: по  откладываем границы классовых интервалов, по
откладываем границы классовых интервалов, по 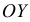 — соответствующие частоты
— соответствующие частоты 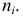 Гистограмма — клеточная диаграмма; ширина клетки равна
Гистограмма — клеточная диаграмма; ширина клетки равна 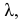 высота клетки равна
высота клетки равна 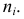 Площадь клетки
Площадь клетки 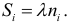 Площадь всей гистограммы
Площадь всей гистограммы 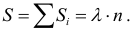
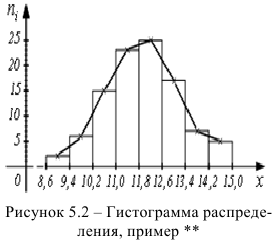
Пример:
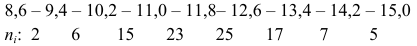
Гистограмма данного распределения изображена на рис. 5.2. Если на приведенной гистограмме верхнее основание клетки поделить пополам точкой, соединить полученные точки ломаной, то получим вариационную кривую.
Аналогично можно построить гистограмму относительных частот 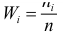 (высота клетки равна
(высота клетки равна 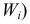 или гистограмму плотности частот
или гистограмму плотности частот 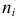 (при этом высота клетки равна
(при этом высота клетки равна 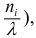 или гистограмму плотности относительных частот
или гистограмму плотности относительных частот 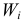 (высота клетки равна
(высота клетки равна 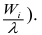
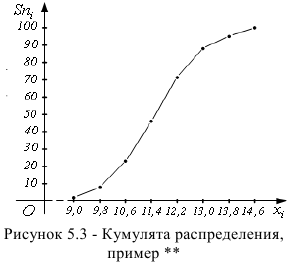
Кумулята
Кумулята (или график накопленных частот 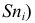 в отличие от вариационной кривой, имеющей куполообразную форму, имеет вид
в отличие от вариационной кривой, имеющей куполообразную форму, имеет вид  -образной кривой.
-образной кривой.
По оси 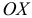 откладываем значения вариант
откладываем значения вариант 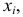 по оси
по оси 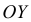 — накопленные частоты
— накопленные частоты 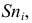 полученные точки соединяем ломаной, график которой называется кумулятой.
полученные точки соединяем ломаной, график которой называется кумулятой.
Пример:

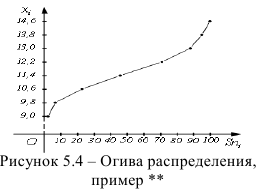
Огива
По оси 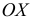 откладываем накопленные частоты
откладываем накопленные частоты 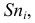 по оси
по оси 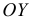 — значения вариант
— значения вариант 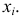 Полученные точки соединяем ломаной линией, график которой называется огива
Полученные точки соединяем ломаной линией, график которой называется огива
Пример:

Огива данного распределения приведена на рис. 5.4. Огива служит для сравнения вариационных рядов с разным количеством наблюдений.
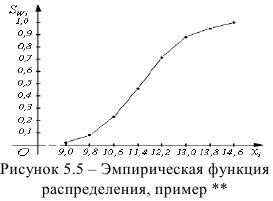
Эмпирическая функция распределения
Эмпирическая функция распределения 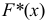 — накопленные относительные частоты
— накопленные относительные частоты  По оси
По оси 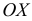 откладываем варианты
откладываем варианты 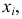 по оси
по оси 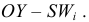 Полученные точки соединяем ломаной линией, график которой называется эмпирической функцией распределения
Полученные точки соединяем ломаной линией, график которой называется эмпирической функцией распределения 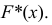
Пример:
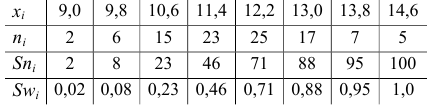
Эмпирическая функция данного распределения приведена на рис. 5.5.
Аналогом 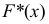 в теории вероятностей является функция распределения
в теории вероятностей является функция распределения 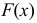 — накопленные вероятности.
— накопленные вероятности. 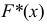 есть оценка теоретической функции распределения
есть оценка теоретической функции распределения 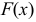 по данным наблюдений.
по данным наблюдений.
Основные характеристики варьирующих признаков
Средние величины:
Средние величины обладают способностью характеризовать целую группу однородных единиц одним (средним) числом. Например, средний рост, средняя продуктивность, средняя успеваемость и т.п.
Значение средних заключается в их свойстве аккумулировать или уравновешивать все индивидуальные отклонения, в результате чего проявляется то наиболее устойчивое и типичное, что характеризует качественное своеобразие варьирующего объекта, позволяет отличать один групповой объект от другого.
Средние величины могут характеризовать только однородную совокупность вариант, в противном случае средняя величина фиктивная. Средняя величина -это абстрактная величина, т.к. в действительности не существует, а иногда и не может существовать, но очень подходит для сравнения признаков.
При вычислении средних величин не обязательно группировать исходные данные в вариационный ряд.
Средняя арифметическая
Средняя арифметическая 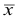 — центр распределения, около которого группируются все варианты статистической совокупности.
— центр распределения, около которого группируются все варианты статистической совокупности.
В случае, если выборка не сгруппированная, то 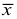 вычисляем по формуле:
вычисляем по формуле:
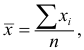 где
где 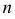 — объем выборки. При этом
— объем выборки. При этом 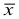 называется «простая арифметическая средняя». Если выборка сгруппированная, то
называется «простая арифметическая средняя». Если выборка сгруппированная, то 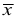 вычисляем по формуле:
вычисляем по формуле:
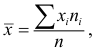 где
где 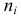 — частота варианты
— частота варианты 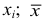 называется «взвешенная арифметическая средняя».
называется «взвешенная арифметическая средняя».
Свойства 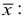
1) если каждую варианту 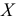 уменьшить или увеличить на одно и то же число
уменьшить или увеличить на одно и то же число 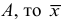 уменьшится или увеличится на это же число.
уменьшится или увеличится на это же число.
2) Если каждую варианту 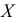 разделить или умножить на одно и то же постоянное число
разделить или умножить на одно и то же постоянное число 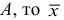 уменьшится или увеличится в
уменьшится или увеличится в 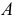 раз.
раз.
Средняя квадратическая
Средняя квадратическая 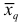 вычисляется по формуле
вычисляется по формуле 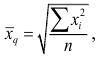 если выборка не сгруппирована, и по формуле
если выборка не сгруппирована, и по формуле 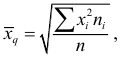 если выборка сгруппирована.
если выборка сгруппирована.
Пример:
Измерение диаметров нефтяных пятен при загрязнении водоема дало следующие результаты: 15, 20, 10, 25, 30 м.
Требуется определить средний диаметр нефтяного пятна. Применим формулу 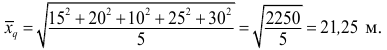
Средняя арифметическая диаметров 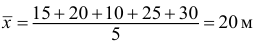 не дает верного результата. Проверим по правилу единства суммарного действия: общая
не дает верного результата. Проверим по правилу единства суммарного действия: общая
площадь всех пяти пятен равна 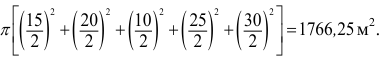 Если взять пять одинаковых кругов диаметром
Если взять пять одинаковых кругов диаметром 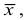 то общая площадь составит
то общая площадь составит 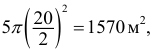 что гораздо меньше общей фактической площади. Если же взять пять одинаковых кругов диаметром
что гораздо меньше общей фактической площади. Если же взять пять одинаковых кругов диаметром 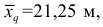 то , то общая площадь будет
то , то общая площадь будет 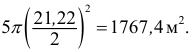
Средняя кубическая
Средняя кубическая 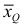 вычисляется по формуле
вычисляется по формуле 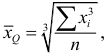 если выборка не сгруппирована, и по формуле
если выборка не сгруппирована, и по формуле 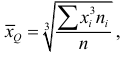 если выборка сгруппирована.
если выборка сгруппирована.
Средняя кубическая 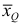 является характеристикой объемных признаков.
является характеристикой объемных признаков.
Средняя гармоническая
Средняя гармоническая 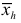 вычисляется по формуле
вычисляется по формуле 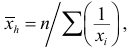 выборка не сгруппирована, и по формуле
выборка не сгруппирована, и по формуле 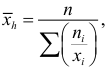 если выборка сгруппирована. Средняя гармоническая применяется при усреднении меняющихся скоростей.
если выборка сгруппирована. Средняя гармоническая применяется при усреднении меняющихся скоростей.
Пример:
Пять рабочих в течение одного часа (60 мин.) изготовили: первый — 10 деталей, второй — 20, третий — 25, четвертый — 30, пятый — 20. Всего за один час изготовлено 105 деталей. Средние количества деталей за один час 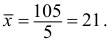 По
По 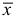 легко определяется общее количество деталей, изготовленных за 1 час пятью рабочими.
легко определяется общее количество деталей, изготовленных за 1 час пятью рабочими.
С помощью 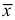 определим среднее время, затраченное одним рабочим на изготовление одной детали:
определим среднее время, затраченное одним рабочим на изготовление одной детали:
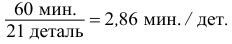
Найдем количество минут, затраченное на одну деталь каждым рабочим:
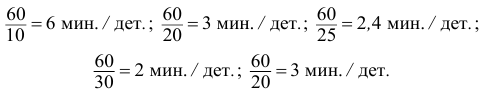
Найдем среднее время, затраченное на одну деталь одним рабочим:
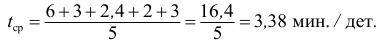
Количество деталей в среднем изготовленных за час будет:
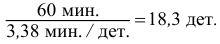
Аналогичный результат получим, если используем формулу среднего гармонического:
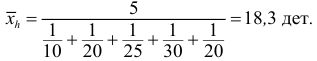
Следовательно, в случае усреднения меняющихся производительностей ил скоростей надо применять 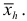
Показатели вариации
Лимиты и размах выборки:
Простейшими показателями вариации (показателями разнообразия) являются лимиты: 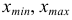 и размах выборки
и размах выборки 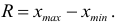
Пример:
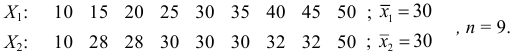
Признаки 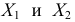 имеют одинаковые лимиты и размах, но степень разнообразия в группах явно различная. Размах
имеют одинаковые лимиты и размах, но степень разнообразия в группах явно различная. Размах 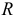 не отражает существенные черты варьирования. Но в некоторых случаях лимиты могут служить единственной характеристикои признака, например, при описании простеиших: кишечная амеба — 20-30 мк, инфузория толстых кишок — 30-150 мк.
не отражает существенные черты варьирования. Но в некоторых случаях лимиты могут служить единственной характеристикои признака, например, при описании простеиших: кишечная амеба — 20-30 мк, инфузория толстых кишок — 30-150 мк.
Среднее линейное отклонение
Среднее линейное отклонение 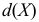 вычисляется по формуле
вычисляется по формуле 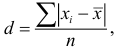 если выборка не сгруппирована, и по формуле
если выборка не сгруппирована, и по формуле 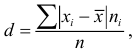 если выборка сгруппирована.
если выборка сгруппирована.
В условиях предыдущего примера линейные отклонения признаков:
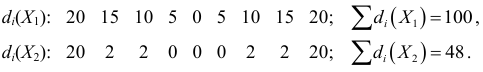
Отсюда 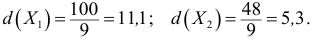
Следовательно, признак 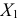 варьирует сильнее, чем признак
варьирует сильнее, чем признак 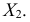
Дисперсия
Дисперсия 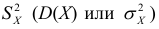 имеет наибольшее распространение по сравнению с другими показателями вариации (dispersio — рассеяние, лат.).
имеет наибольшее распространение по сравнению с другими показателями вариации (dispersio — рассеяние, лат.).
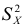 есть среднее арифметическое квадратов отклонений вариант от центра распределения
есть среднее арифметическое квадратов отклонений вариант от центра распределения 
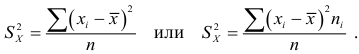
Расчетная формула дисперсии:
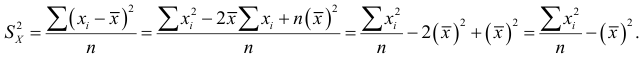
Таким образом, 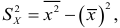 т.е. дисперсия равна среднему арифметическому
т.е. дисперсия равна среднему арифметическому
квадрата величины минус квадрат среднего арифметического.
Аналог в теории вероятностей — дисперсия 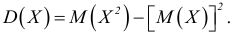 .
.
Свойства дисперсии:
1) если каждую варианту 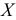 уменьшить или увеличить на одно и то же число
уменьшить или увеличить на одно и то же число 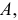 то дисперсия не изменится. Действительно
то дисперсия не изменится. Действительно
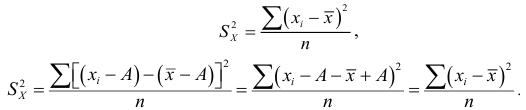
Следовательно, можно вычислять не только по 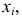 но и по их отклонениям
но и по их отклонениям 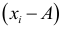 от постоянного
от постоянного 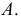
2) Если каждую варианту 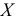 разделить или умножить на одно и то же постоянное число
разделить или умножить на одно и то же постоянное число 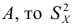 уменьшится или увеличится в
уменьшится или увеличится в 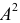 раз. Действительно
раз. Действительно
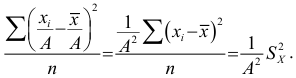
Следовательно, при наличии в совокупности многозначных вариант их можно сократить на некоторое постоянное число 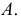 Полученный после вычисления результат надо умножить на
Полученный после вычисления результат надо умножить на 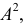 что и дает искомую величину дисперсии.
что и дает искомую величину дисперсии.
Свойства 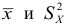 используются в методе «условных вариант» для расчета числовых характеристик выборки. Заметим, что
используются в методе «условных вариант» для расчета числовых характеристик выборки. Заметим, что 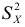 называется выборочной дисперсией и является смещенной оценкой генеральной дисперсии. Чтобы получить несмещенную оценку дисперсии, которую используют в прикладных расчетах и теоретических выкладках, необходимо «исправить» выборочную дисперсию
называется выборочной дисперсией и является смещенной оценкой генеральной дисперсии. Чтобы получить несмещенную оценку дисперсии, которую используют в прикладных расчетах и теоретических выкладках, необходимо «исправить» выборочную дисперсию 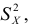 ввести в ее формулу поправку Бесселя — множитель на «смещенность»; полученная дисперсия называется исправленной:
ввести в ее формулу поправку Бесселя — множитель на «смещенность»; полученная дисперсия называется исправленной: 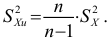
При 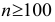 можно использовать
можно использовать 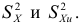
Пример:
Пусть признак 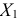 имеет распределение:
имеет распределение:
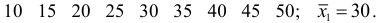
Обозначим сумму квадратов отклонений значений признака от центра 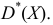 Тогда для признака
Тогда для признака 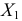
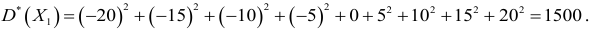
Дисперсия выборочная 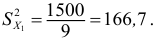
Дисперсия исправленная 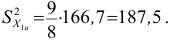
Пусть признак 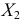 имеет распределение:
имеет распределение:
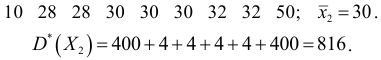
Дисперсия выборочная 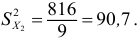
Дисперсия исправленная 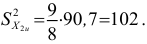
Среднее квадратическое отклонение
Среднее квадратическое отклонение (СКО) более удобная характеристика, чем дисперсия, т.к. выражается в тех же единицах, что 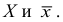 Среднее квадратическое отклонение равно корню квадратному из дисперсии. Существует СКО выборочное
Среднее квадратическое отклонение равно корню квадратному из дисперсии. Существует СКО выборочное 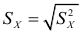 и СКО исправленное
и СКО исправленное 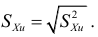
В условиях предыдущего примера
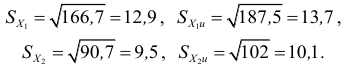
При одинаковых лимитах и размахе дисперсия и СКО не одинаковы. На их величине сказался различный характер варьирования признака.
Поправка Шеппарда.
При создании безынтервального вариационного ряда из интервального ряда частоты 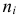 относят к средним значениям классовых интервалов без учета внутриклассового разнообразия. Но варианты внутри классов распределяются неравномерно, накапливаясь больше у тех границ, которые ближе к
относят к средним значениям классовых интервалов без учета внутриклассового разнообразия. Но варианты внутри классов распределяются неравномерно, накапливаясь больше у тех границ, которые ближе к 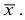 Следовательно, при вычислении обобщающих характеристик для непрерывно варьирующих признаков допускают систематическую погрешность. Чем шире классовый интервал, тем больше эта погрешность. Учитывая это, в 1898 г. В. Шеппард установил, что разность между фактической и расчетной величиной дисперсии составляет
Следовательно, при вычислении обобщающих характеристик для непрерывно варьирующих признаков допускают систематическую погрешность. Чем шире классовый интервал, тем больше эта погрешность. Учитывая это, в 1898 г. В. Шеппард установил, что разность между фактической и расчетной величиной дисперсии составляет 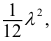 где
где 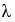 — ширина классового интервала, т.е. поправка Шеппарда должна вычитаться из величины
— ширина классового интервала, т.е. поправка Шеппарда должна вычитаться из величины 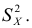 Обычно поправку применяют при требовании высокой точности расчетов или при большом числе наблюдений
Обычно поправку применяют при требовании высокой точности расчетов или при большом числе наблюдений 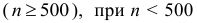 поправка не используется.
поправка не используется.
Пример:
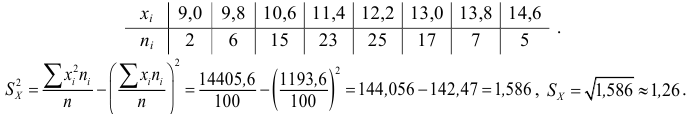
Введем поправку Шеппарда: 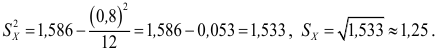
Анализируя результат, приходим к выводу, что в этом примере данную поправку можно не использовать.
Коэффициент вариации
Дисперсия 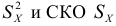 являются основными показателями разнообразия вариант в изучаемой группе. При этом СКО
являются основными показателями разнообразия вариант в изучаемой группе. При этом СКО 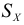 служит непосредственным показателем разнообразия только при соблюдении следующих условий: 1) сравниваются только одинаковые признаки;
служит непосредственным показателем разнообразия только при соблюдении следующих условий: 1) сравниваются только одинаковые признаки;
2) средние сравниваемых групп незначительно отличаются друг от друга. Если указанные условия не выполняются и необходимо сравнить разнообразие разных признаков или одинаковых при значительном различии средних, то СКО непосредственно не может быть использовано. В этих случаях используют не абсолютные, а относительные показатели вариации.
Коэффициент вариации  есть среднее квадратическое отклонение, выраженное в процентах от величины средней арифметической:
есть среднее квадратическое отклонение, выраженное в процентах от величины средней арифметической:
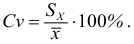
Примеры:
1) Сравнить два варьирующих признака. Для первого признака среднее 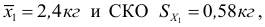 для второго
для второго 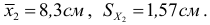 Следует ли отсюда, что
Следует ли отсюда, что 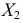 варьирует сильнее, чем
варьирует сильнее, чем 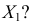
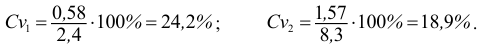
Следовательно, сильнее варьирует признак 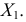
2) Средняя длина зеркального карпа в одном садке 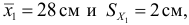 а во втором садке
а во втором садке 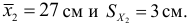 В данном случае вывод делаем по СКО: во
В данном случае вывод делаем по СКО: во
втором садке разнообразия больше и рыбы менее стандартны.
Отметим, варьирование признака 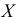 считается слабым, если
считается слабым, если 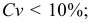 средним, если
средним, если 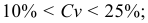 значительным, если
значительным, если 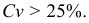
Структурные средние
На величину средней арифметической 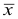 могут значительно влиять крайние члены ранжированного вариационного ряда, которые как раз и наименее характерны для данной совокупности. Структурные средние представляют собой конкретные варианты имеющейся совокупности, которые занимают особое место в ряду распределения.
могут значительно влиять крайние члены ранжированного вариационного ряда, которые как раз и наименее характерны для данной совокупности. Структурные средние представляют собой конкретные варианты имеющейся совокупности, которые занимают особое место в ряду распределения.
Медиана
Медиана 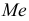 — средняя, которая делит ряд распределения на две равные части. По обе стороны от медианы располагается одинаковое число вариант.
— средняя, которая делит ряд распределения на две равные части. По обе стороны от медианы располагается одинаковое число вариант.
Если число вариант небольшое, то данные ранжируют и при нечетном 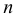 центральная варианта и есть медиана. Например,
центральная варианта и есть медиана. Например,
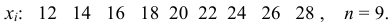
В данном случае медиана 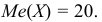
Если число вариант четное, то медиана равна полусумме его центральных членов. Например, 
В этом случае медиана 
Если имеем вариационный интервальный ряд, то медиану находим по формуле 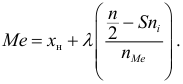
Вначале находим класс или интервал, к которому принадлежит медиана  обозначим его
обозначим его  -класс. Для этого частоты
-класс. Для этого частоты  ряда кумулируют (накапливают) в направлении от меньших к большим значениям классов до величины, превосходящей половину всех членов данной совокупности, т.е.
ряда кумулируют (накапливают) в направлении от меньших к большим значениям классов до величины, превосходящей половину всех членов данной совокупности, т.е. 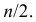 Первая величина в ряду накопленных частот, которая больше
Первая величина в ряду накопленных частот, которая больше 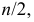 соответствует медианному классу; частота этого класса
соответствует медианному классу; частота этого класса 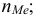 нижняя граница
нижняя граница 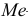 -класса обозначается
-класса обозначается 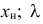 -величина классового интервала;
-величина классового интервала;  — накопленная частота класса, предшествующего
— накопленная частота класса, предшествующего  -классу.
-классу.
Пример:
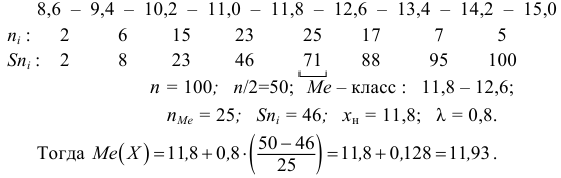
Если из интервального вариационного ряда сформирован безынтервальный вариационный ряд, то медиану находим по формуле 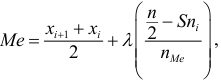
где  — классовая варианта предшествующего класса;
— классовая варианта предшествующего класса;  — классовая варианта
— классовая варианта  -класса .
-класса .
Пример:
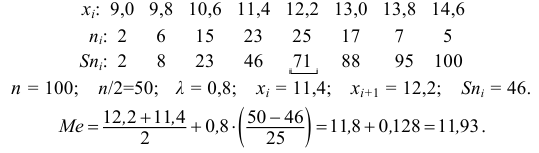
Пример:
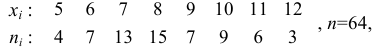
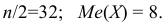
По предыдущей формуле: 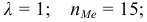
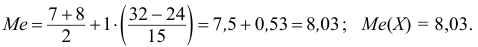
Мода
Мода 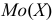 — значение, наиболее часто встречающееся в данной совокупности. Класс с наибольшей частотой называется модальным
— значение, наиболее часто встречающееся в данной совокупности. Класс с наибольшей частотой называется модальным 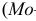 -класс).
-класс).
Если ряд безынтервальный, то 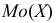 есть то значение
есть то значение 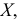 для которого частота будет наибольшей. В примере*
для которого частота будет наибольшей. В примере* 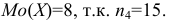
Если ряд интервальный, то моду находим по формуле
где  — нижняя граница
— нижняя граница 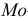 -класса, т.е. класса с наибольшей частотой
-класса, т.е. класса с наибольшей частотой 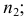
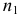 — частота класса, предшествующего -классу;
— частота класса, предшествующего -классу;
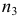 — частота класса, следующего за -классом;
— частота класса, следующего за -классом;
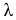 — ширина классового интервала.
— ширина классового интервала.
Пример:
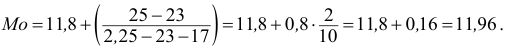
Квантили
Квантили — значения признака 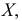 отсекающие в пределах статистического ряда определенную часть его членов.
отсекающие в пределах статистического ряда определенную часть его членов.
Квартили — три значения признака 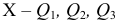 — делящие ранжированный вариационный ряд на четыре равные части.
— делящие ранжированный вариационный ряд на четыре равные части.
Децили — девять значений делят ряд на десять равных частей.
Перцентили — 99 значений делят ряд на 100 равных частей. Обозначают перцентили 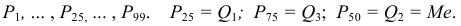
Точечные и интервальные оценки генеральных параметров
Числовые показатели, характеризующие генеральную совокупность, называются генеральными показателями. Например, математическое ожидание генеральной совокупности 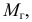 дисперсия
дисперсия 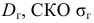 и т.д.
и т.д.
Числовые показатели, характеризующие выборку, называются выборочными характеристиками или статистиками. Например, 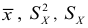 и т.д.
и т.д.
Выборочные характеристики — это величины случайные, варьирующие около своих генеральных параметров и являющиеся их приближенными оценками.
Пусть исследуется количественный признак 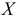 и из генеральной совокупности извлечено
и из генеральной совокупности извлечено 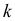 выборок по
выборок по 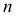 наблюдений:
наблюдений:
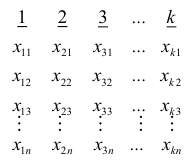
По каждой выборке подсчитаем некоторую статистику 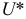 генерального параметра
генерального параметра 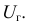 Получим ряд возможных значений случайной величины
Получим ряд возможных значений случайной величины 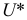 или ее выборочное распределение:
или ее выборочное распределение: 
В большинстве случаев средние характеристики имеют нормальный закон распределения.
Определение. Характеристики, вычисленные одним числом, называются точечными оценками генеральных параметров.
Такие оценки должны удовлетворять условиям:
- состоятельность, т.е. оценка стремится по вероятности к оцениваемому параметру
- эффективность, т.е. оценка должна иметь наименьшую дисперсию по сравнению с другими аналогичными оценками. Например, для трех показателей, описывающих положение центра нормального распределения признака — наиболее эффективной будет оценка наименее эффективной — Для дисперсий этих оценок характерно неравенство
- несмещенность оценки, т.е. математическое ожидание ее выборочного распределения совпадает со значением генерального параметра: При соблюдении этого условия оценка не содержит систематических ошибок в сторону занижения или завышения.
 стремится по вероятности к оцениваемому параметру
стремится по вероятности к оцениваемому параметру 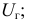
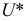 должна иметь наименьшую дисперсию по сравнению с другими аналогичными оценками. Например, для трех показателей, описывающих положение центра нормального распределения признака
должна иметь наименьшую дисперсию по сравнению с другими аналогичными оценками. Например, для трех показателей, описывающих положение центра нормального распределения признака 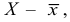
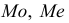 — наиболее эффективной будет оценка
— наиболее эффективной будет оценка 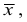 наименее эффективной —
наименее эффективной — 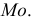 Для дисперсий этих оценок характерно неравенство
Для дисперсий этих оценок характерно неравенство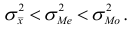
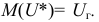 При соблюдении этого условия оценка не содержит систематических ошибок в сторону занижения или завышения.
При соблюдении этого условия оценка не содержит систематических ошибок в сторону занижения или завышения.Доказано, что наилучшими оценками для генеральных параметров 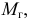 дисперсии
дисперсии 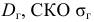 являются соответственно
являются соответственно 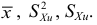
При выборке малого объема точечная оценка параметра может значительно отличаться от генерального значения. В таких случаях используют интервальные оценки. Интервальная оценка определяется двумя числами — границами интервала; такая оценка позволяет установить точность и надежность оценки.
Пусть по данным выборки подсчитана статистика 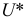 — оценка генерального параметра
— оценка генерального параметра 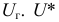 тем точнее определяет
тем точнее определяет 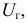 чем меньше
чем меньше 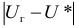 или при
или при 
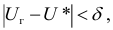 где
где 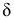 называется точностью оценки.
называется точностью оценки.
Так как работаем со статистическим материалом (массовыми однородными объектами), то категорически утверждать, что оценка 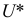 удовлетворяет неравенству
удовлетворяет неравенству 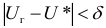 нельзя. Можно говорить лишь о вероятности
нельзя. Можно говорить лишь о вероятности 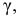 с которой это неравенство осуществляется.
с которой это неравенство осуществляется.
Определение. Доверительной вероятностью или надежностью называется вероятность 
На практике наиболее часто задают надежность  равную 0,9; 0,95; 0,99; 0,9999, в зависимости от объекта и целей исследования
равную 0,9; 0,95; 0,99; 0,9999, в зависимости от объекта и целей исследования  — вероятность практически достоверного события).
— вероятность практически достоверного события).
Противоположная вероятность 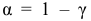 называется уровнем значимости
называется уровнем значимости  — вероятность практически невозможного события),
— вероятность практически невозможного события),  0,1; 0,05; 0,001; 0,0001. Интервал
0,1; 0,05; 0,001; 0,0001. Интервал 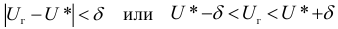 называется доверительным,
называется доверительным, 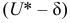 — нижняя граница,
— нижняя граница, 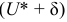 — верхняя граница интервала.
— верхняя граница интервала.
Говорим, что доверительный интервал заключает в себе  с вероятностью (надежностью)
с вероятностью (надежностью) 
Для любой выборочной характеристики по соответствующей методике можно найти доверительный интервал с надежностью 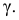
Например, пусть количественный признак 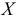 распределен нормально, причем
распределен нормально, причем 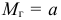 неизвестно, а
неизвестно, а 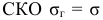 известно. Найдем доверительный интервал параметра
известно. Найдем доверительный интервал параметра 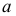 (по-другому,
(по-другому, 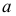 есть истинное значение случайного признака
есть истинное значение случайного признака  Будем оценивать неизвестное математическое ожидание признака
Будем оценивать неизвестное математическое ожидание признака 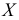 по выборочной средней
по выборочной средней 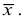 С одной стороны
С одной стороны 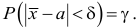 С другой стороны
С другой стороны
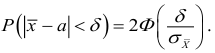 Для
Для 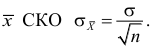 Тогда
Тогда 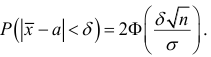
Обозначим 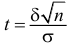 и найдем
и найдем 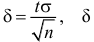 называется точностью оценки или ошибкой выборки. Необходимый объем выборки
называется точностью оценки или ошибкой выборки. Необходимый объем выборки 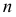 вычисляется по формуле .
вычисляется по формуле . 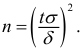 Следовательно,
Следовательно, 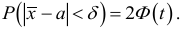 Итак, имеем
Итак, имеем 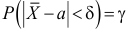 и
и 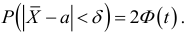 Отсюда
Отсюда 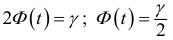 и значение
и значение 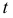 можно найти по таблице функции
можно найти по таблице функции 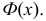
Таким образом, интервал 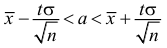 будет доверительным для параметра
будет доверительным для параметра 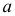 с надежностью
с надежностью 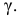
Пример:
Количественный признак 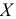 распределен нормально и
распределен нормально и 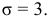 Найти доверительный интервал для параметра
Найти доверительный интервал для параметра 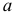 с надежностью
с надежностью 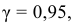 если проведено
если проведено 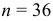 наблюдений и
наблюдений и 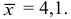
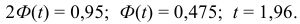
Точность оценки 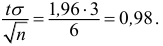
Доверительный интервал: 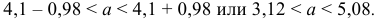
Надежность 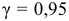 указывает, что, если будет произведено большое количество
указывает, что, если будет произведено большое количество 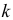 выборок, то в 95% из них параметр
выборок, то в 95% из них параметр 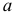 действительно заключен в этих границах; в 5% этих выборок параметр
действительно заключен в этих границах; в 5% этих выборок параметр 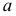 может выйти за эти границы, т.е. доверительная вероятность
может выйти за эти границы, т.е. доверительная вероятность 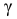 не связана с оцениваемым параметром, она связана с границами доверительного интервала, которые изменяются от выборки к выборке.
не связана с оцениваемым параметром, она связана с границами доверительного интервала, которые изменяются от выборки к выборке.
Рассмотрим случай, когда СКО 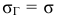 неизвестно и признак
неизвестно и признак 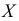 распределен нормально. Задача была решена английским статистиком В. Госсетом (псевдоним Стьюдент).
распределен нормально. Задача была решена английским статистиком В. Госсетом (псевдоним Стьюдент).
Случайная величина 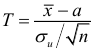 имеет закон распределения, который называется
имеет закон распределения, который называется  -распределением или распределением Стьюдента. Это распределение определяется параметром
-распределением или распределением Стьюдента. Это распределение определяется параметром 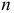 — объемом выборки и не зависит от
— объемом выборки и не зависит от 
Дифференциальная функция этого распределения (плотность вероятности) обозначается 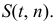 Тогда
Тогда 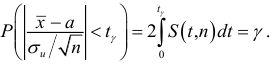
Доверительный интервал: 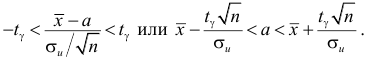
Величина 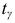 табулирована при любых
табулирована при любых 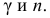
Пример:
Количественный признак  генеральной совокупности распределен нормально. По выборке объемом
генеральной совокупности распределен нормально. По выборке объемом 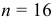 найдены
найдены 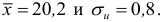 Требуется оценить неизвестное значение
Требуется оценить неизвестное значение 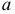 признака
признака 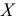 с помощью доверительного интервала при надежности
с помощью доверительного интервала при надежности 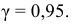
При 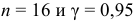 найдем по таблице значение
найдем по таблице значение 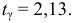
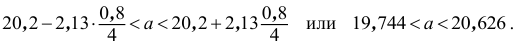
Замечание. Можно доказать, что при  -распределение стремится к нормальному распределению. Поэтому при оценке
-распределение стремится к нормальному распределению. Поэтому при оценке 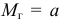 нормально распределенного признака при
нормально распределенного признака при 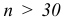 можно вместо
можно вместо 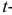 -распределения пользоваться нормальным распределением.
-распределения пользоваться нормальным распределением.
Построение нормальной кривой по опытным данным
Пусть признак  по предположению имеет нормальное распределение. Тогда плотность вероятности имеет вид:
по предположению имеет нормальное распределение. Тогда плотность вероятности имеет вид:
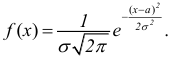
Если  то случайная величина
то случайная величина  называется нормальной нормированной случайной величиной, ее плотность вероятности
называется нормальной нормированной случайной величиной, ее плотность вероятности 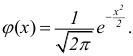 Изменим обозначение аргумента
Изменим обозначение аргумента 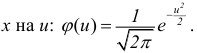 Положим,
Положим, 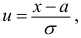 получим
получим
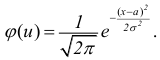
Сравниваем (5.1) и (5.2), получим: 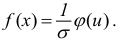
Если параметры 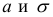 неизвестны, то в качестве их оценок принимаем
неизвестны, то в качестве их оценок принимаем  и СКО выборочное
и СКО выборочное  Тогда
Тогда 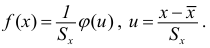
Пусть имеем безынтервальный вариационный ряд, где 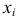 — середина интервала (класса) шириной
— середина интервала (класса) шириной 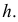 Тогда вероятность попадания случайной величины
Тогда вероятность попадания случайной величины 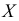 в этот интервал приближенно равна произведению
в этот интервал приближенно равна произведению 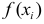 на длину интервала
на длину интервала 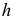
Величина  определяет теоретическую долю попавших в данный интервал
определяет теоретическую долю попавших в данный интервал
наблюдений выборки объемом  Отсюда теоретическая частота
Отсюда теоретическая частота 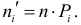
Один из способов построения нормальной кривой по данным наблюдений следующий:
1) поданным наблюдений вычислим параметры 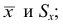
2) найдем выравнивающие (теоретические) частоты по формуле 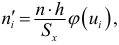
где 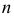 — сумма наблюдаемых частот (объем выборки),
— сумма наблюдаемых частот (объем выборки), 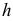 — разность между двумя соседними вариантами —
— разность между двумя соседними вариантами — дифференциальная функция Лапласа, табулированная;
дифференциальная функция Лапласа, табулированная;
3) строим точки 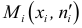 в прямоугольной системе координат и соединяем их плавной кривой. В этой же системе координат строим полигон распределения наблюдаемых частот.
в прямоугольной системе координат и соединяем их плавной кривой. В этой же системе координат строим полигон распределения наблюдаемых частот.
Пример:
Пусть статистическое распределение признака 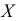 имеет вид:
имеет вид:
Найдем выравнивающие (теоретические) частоты  Данные сведем в расчетную таблицу.
Данные сведем в расчетную таблицу.
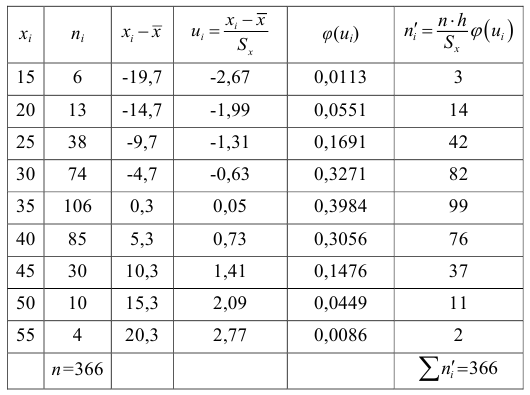
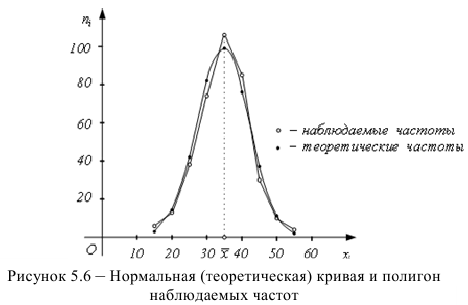
На рис.5.6 построены нормальная (теоретическая) кривая и полигон наблюдаемых частот. Сравнение графиков показывает, что построенная теоретическая кривая удовлетворительно отражает данные наблюдений.
Статистическая гипотеза
Статистическая проверка гипотез является вторым после статистического оценивания параметров распределения и в то же время важнейшим разделом математической статистики.
Методы математической статистики позволяют проверить предположения о законе распределения некоторой случайной величины (генеральной совокупности), о значениях параметров этого закона (например 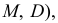 о наличии корреляционной зависимости между случайными величинами, определенными на множестве объектов одной и той же генеральной совокупности.
о наличии корреляционной зависимости между случайными величинами, определенными на множестве объектов одной и той же генеральной совокупности.
Пусть по некоторым данным имеются основания выдвинуть предположения о законе распределения или о параметре закона распределения случайной величины (или генеральной совокупности, на множестве объектов которой определена эта случайная величина). Задача заключается в том, чтобы подтвердить или опровергнуть это предположение, используя выборочные (экспериментальные) данные.
Проверить статистическую гипотезу — это значит проверить, согласуются ли данные, полученные из выборки с этой гипотезой. Проверка осуществляется с помощью статистического критерия.
Определение 1. Статистический критерий — правило, устанавливающее условия, по которым статистическая гипотеза принимается или отвергается.
Этот критерий называют еще критерием согласия (имеется в виду согласие принятой гипотезы с результатами, полученными из выборки).
Определение 2. Статистический критерий — это случайная величина  с известным законом распределения, которая служит для проверки гипотезы.
с известным законом распределения, которая служит для проверки гипотезы.
Гипотезу, выдвинутую для проверки ее согласия с выборочными данными, называют нулевой гипотезой и обозначают 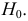 Вместе с гипотезой
Вместе с гипотезой 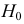 выдвигается альтернативная или конкурирующая гипотеза, которая обозначается
выдвигается альтернативная или конкурирующая гипотеза, которая обозначается 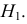 Например:
Например: 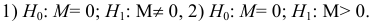
При проверке статистических гипотез можно допустить ошибку двух видов. Относительно гипотезы 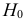 может быть два предположения: гипотеза верна или гипотеза ложна — и два действия: гипотеза отвергается или принимается.
может быть два предположения: гипотеза верна или гипотеза ложна — и два действия: гипотеза отвергается или принимается.
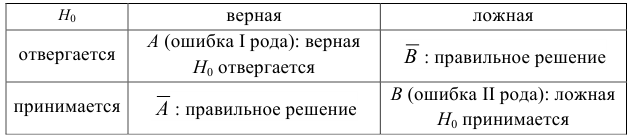
Определение. Уровнем значимости 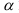 критерия называется вероятность
критерия называется вероятность 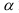 допустить ошибку I рода:
допустить ошибку I рода: 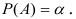
Чем меньше уровень значимости 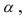 тем меньше вероятность отвергнуть правильную гипотезу. Поэтому
тем меньше вероятность отвергнуть правильную гипотезу. Поэтому 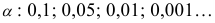
Тогда вероятность события  равная
равная 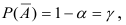 называется доверительной вероятностью или надежностью.
называется доверительной вероятностью или надежностью.
Определение. Критической областью 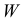 проверяемой гипотезы, называется множество тех значений характеристики
проверяемой гипотезы, называется множество тех значений характеристики 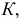 при которых
при которых 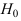 отвергается.
отвергается.
Критическая область 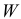 выбирается так, чтобы:
выбирается так, чтобы:
- вероятность попадания при условии справедливости была равна при минимальном
- вероятность попадания если справедлива должна быть такой, что вероятность ошибки II рода, т.е. должна быть минимальной. Вероятность не допуска ошибки II рода называется мощностью критерия эта величина должна быть максимальной.
- единственный способ одновременного уменьшения вероятностей ошибок I и II рода состоит в увеличении объема выборки.
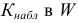 при условии справедливости
при условии справедливости 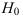 была равна
была равна 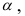 при минимальном
при минимальном 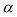
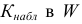 если справедлива
если справедлива 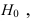 должна быть такой, что вероятность ошибки II рода, т.е.
должна быть такой, что вероятность ошибки II рода, т.е. 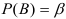 должна быть минимальной. Вероятность не допуска ошибки II рода
должна быть минимальной. Вероятность не допуска ошибки II рода 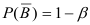 называется мощностью критерия
называется мощностью критерия 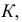 эта величина должна быть максимальной.
эта величина должна быть максимальной.Критерии согласия
Обычно эмпирические 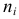 и теоретические
и теоретические 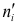 частоты различаются. Возможно, что расхождение случайно и связано с ограниченным числом наблюдений; возможно, что расхождение неслучайно (значимо) и объясняется тем, что для вычисления выравнивающих частот была выдвинута статистическая гипотеза о том, что генеральная совокупность распределена нормально, а в действительности это не так. Распределение генеральной совокупности, которое она имеет в силу выдвинутой гипотезы, назовем теоретическим.
частоты различаются. Возможно, что расхождение случайно и связано с ограниченным числом наблюдений; возможно, что расхождение неслучайно (значимо) и объясняется тем, что для вычисления выравнивающих частот была выдвинута статистическая гипотеза о том, что генеральная совокупность распределена нормально, а в действительности это не так. Распределение генеральной совокупности, которое она имеет в силу выдвинутой гипотезы, назовем теоретическим.
Возникает необходимость установить критерий (правило), который позволит судить, является ли расхождение между 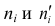 случайным или значимым.
случайным или значимым.
Если расхождение случайно, то говорим, что данные выборки согласуются с гипотезой о распределении генеральной совокупности и, следовательно, гипотезу можно принять. Если же расхождение значимо, то гипотезу следует отвергнуть.
Критерий согласия (критерий соответствия) — критерий, который позволяет судить о том, что расхождение эмпирического и теоретического распределений случайно или значимо (принимать гипотезу или отвергать).
Критерий «хи-квадрат» Пирсона
Критерий «хи-квадрат» Пирсона 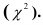
Пусть количественный признак  задан статистическим распределением в виде интервального или безинтервального вариационных рядов (эмпирическое распределение
задан статистическим распределением в виде интервального или безинтервального вариационных рядов (эмпирическое распределение 
Выдвигается нулевая гипотеза 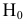 относительно закона распределения признака
относительно закона распределения признака  (теоретическое распределение
(теоретическое распределение 
Вычисляется статистическая характеристика:
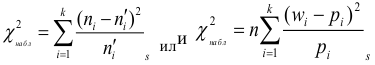
Критерий  позволяет судить, является ли расхождение между
позволяет судить, является ли расхождение между 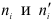 (или
(или 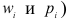 случайным (незначимым) или неслучайным (значимым). Чем больше согласуются теоретическое и эмпирическое распределения, тем меньше число
случайным (незначимым) или неслучайным (значимым). Чем больше согласуются теоретическое и эмпирическое распределения, тем меньше число  .
.
Величина 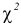 — случайная, ее дифференциальная функция распределения зависит только от числа
— случайная, ее дифференциальная функция распределения зависит только от числа 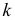 степенной свободы.
степенной свободы.
Число степеней свободы 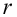 равно числу классов
равно числу классов 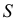 минус число независимых условий (связей), наложенных на частоты
минус число независимых условий (связей), наложенных на частоты 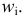 Примерами таких условий может быть:
Примерами таких условий может быть: 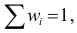 если мы требуем, чтобы
если мы требуем, чтобы 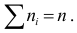 Это требование накладывается во всех случаях.
Это требование накладывается во всех случаях.
Если подбираем теоретическое распределение с тем условием, чтобы совпадали теоретическое и статистическое средние, то 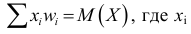 — классовая варианта. Если требуем совпадений теоретической и статистической дисперсий, то
— классовая варианта. Если требуем совпадений теоретической и статистической дисперсий, то 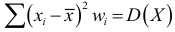 и т.д.
и т.д.
В случае, если признак 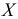 распределен нормально, то оценками
распределен нормально, то оценками 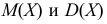 будут
будут 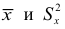 (дисперсия либо выборочная, либо исправленная), т.е. на выборку наблюдений наложены две независимых связи. Число степеней свободы в этом случае
(дисперсия либо выборочная, либо исправленная), т.е. на выборку наблюдений наложены две независимых связи. Число степеней свободы в этом случае 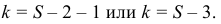
Если проверяем равномерный закон распределения, то его параметры 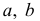 находим по значениям
находим по значениям 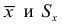 (две связи), тогда
(две связи), тогда 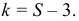
В случае закона Пуассона параметр 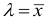 (одна связь) и
(одна связь) и 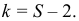
Если проверяем биномиальный закон распределения, то 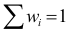 (обязательная связь) и
(обязательная связь) и 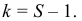
Если закон показательный, то его параметр 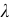 вычисляется через
вычисляется через 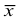 (одна связь) и
(одна связь) и 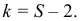
Вычисляем число степеней свободы 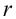 для данного теоретического закона распределения и задаем уровень значимости
для данного теоретического закона распределения и задаем уровень значимости 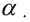
Итак, при проверке гипотезы о нормальном распределении 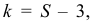 где
где 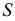 — число классов, на которые разбиты данные наблюдений. Далее, при выбранном уровне значимости
— число классов, на которые разбиты данные наблюдений. Далее, при выбранном уровне значимости 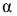 (или доверительной вероятности
(или доверительной вероятности 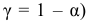 по таблице приложения найдем
по таблице приложения найдем 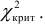 Если расхождение случайно, то
Если расхождение случайно, то 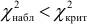 и гипотеза о нормальном распределении выборки принимается. Если расхождение значимо, то
и гипотеза о нормальном распределении выборки принимается. Если расхождение значимо, то 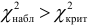 гипотеза отвергается.
гипотеза отвергается.
При использовании критерия «хи-квадрат» необходимо интервалы с числом 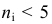 объединять в один интервал, после чего заново подсчитать окончательное число Sклассов.
объединять в один интервал, после чего заново подсчитать окончательное число Sклассов.
Пример:
Пусть количественный признак  задан статистическим распределением:
задан статистическим распределением:

Такое задание признака  называется безинтервальным рядом. По данному
называется безинтервальным рядом. По данному
вариационному ряду вычислим основные числовые характеристики:
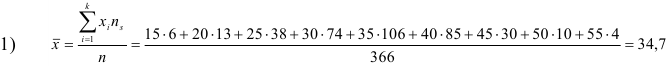
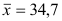 — центр распределения выборки
— центр распределения выборки
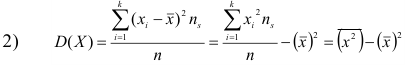
У нас 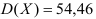 — мера разброса
— мера разброса  около
около 
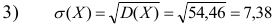 — мера разброса около
— мера разброса около
Выдвигаем нулевую гипотезу 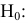 признак
признак 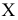 распределен нормально. Для вычисления
распределен нормально. Для вычисления 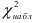 необходимо найти теоретические (выравнивающие) частоты
необходимо найти теоретические (выравнивающие) частоты
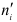 (или
(или 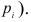 Напомним что
Напомним что 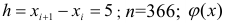 — четная, т.е.
— четная, т.е. 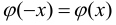
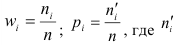 — теоретическая частота,
— теоретическая частота, 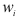 относительная частота.
относительная частота.
Приведем расчетную таблицу.
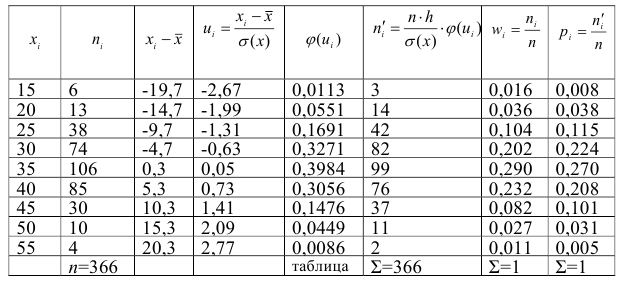
Сравниваем графы  (или
(или 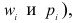 видим, что есть расхождение. Случайное оно или неслучайное?
видим, что есть расхождение. Случайное оно или неслучайное?
Вычисляем 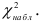 Дополним таблицу:
Дополним таблицу:
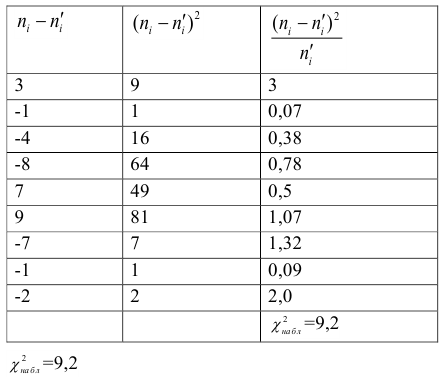
Вычисляем число степеней свободы 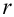 для нормального закона распределения:
для нормального закона распределения: 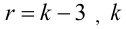 — число классов или групп в статистическом распределении, тогда
— число классов или групп в статистическом распределении, тогда 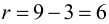 степеней свободы.
степеней свободы.
Задаем уровень значимости 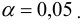 По таблице приложений
По таблице приложений 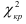 находим значение
находим значение 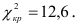
Вывод: 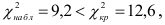 следовательно, расхождение
следовательно, расхождение 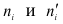 (или
(или 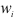 и
и  случайное (незначимое) и гипотеза о нормальном распределении признака
случайное (незначимое) и гипотеза о нормальном распределении признака  принимается.
принимается.
Критерий Романовского
Найдем величину (число) 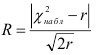
В примере 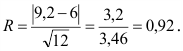
Если 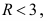 то расхождение между теоретическим (предполагаемым нормальным) и статистическим случайно или незначимо.
то расхождение между теоретическим (предполагаемым нормальным) и статистическим случайно или незначимо.
У нас: 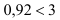 — гипотеза о нормальном распределении не отвергается.
— гипотеза о нормальном распределении не отвергается.
Если 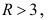 то гипотезу отвергаем.
то гипотезу отвергаем.
Критерий Колмогорова.
Этот критерий в расчетную таблицу требует еще три графы.
Графа 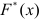 — накопленные
— накопленные  графа
графа  — накопленные
— накопленные 
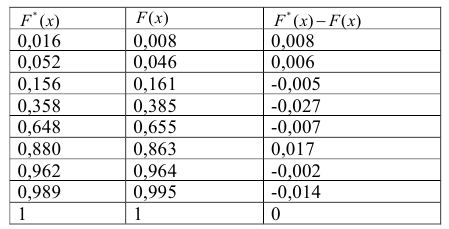
Найдем величину 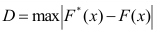
В примере 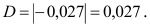
Вычислим 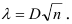 В примере
В примере 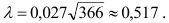
По таблице 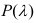 находим вероятность
находим вероятность 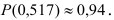
Вывод. Если 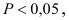 то гипотеза отвергается. Если
то гипотеза отвергается. Если 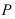 значительно больше 0,05, то гипотеза принимается.
значительно больше 0,05, то гипотеза принимается.
В примере: 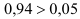 — гипотеза о нормальном распределении принимается.
— гипотеза о нормальном распределении принимается.
- Комбинаторика — правила, формулы и примеры
- Классическое определение вероятности
- Геометрические вероятности
- Теоремы сложения и умножения вероятностей
- Дисперсионный анализ
- Математическая обработка динамических рядов
- Корреляция — определение и вычисление
- Элементы теории ошибок